-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Données intégrées
À propos des données intégrées
Les données intégrées représentent toutes les informations supplémentaires que vous pourriez vouloir enregistrer dans vos données d’enquête en plus des réponses à vos questions. Elles peuvent être utilisées pour conserver des informations comme :
- Données démographiques et autres informations dont vous disposiez au préalable sur les répondants et enregistrées dans la liste de contacts.
- Le site de réseaux sociaux à partir duquel le répondant a accédé à l’enquête.
- La condition attribuée à un répondant dans une étude.
Les données intégrées consistent en un champ et une valeur. Le champ est le nom de votre variable (par ex., Genre, État, Âge). La valeur est l’élément sur lequel votre champ sera défini dans vos données. Tout comme une question peut avoir plusieurs réponses possibles, un champ de données intégrées peut avoir plusieurs valeurs possibles (par ex., un champ appelé Pays peut avoir la valeur États-Unis, Mexique ou Canada).
La valeur de votre champ de données intégrées peut être tirée des données que vous avez téléchargées dans une liste de contacts, des informations ajoutées au lien de l’enquête de la personne interrogée, des champs intégrés fournis par Qualtrics ou des valeurs définies dans le flux de l’enquête.
Utiliser des données intégrées dans votre enquête
Une fois que les données intégrées ont été ajoutées à votre enquête, vous pouvez les utiliser de différentes manières, notamment sous forme de :
- Texte inséré pour afficher des données intégrées dans les questions de votre enquête.
- Logique de branche pour déterminer les sections d’une enquête auxquelles votre répondant doit répondre.
- Logique d’affichage pour déterminer si un répondant doit voir une question.
- Quotas pour déterminer si quelqu’un remplit les conditions requises pour l’augmenter.
- Tâches e-mail et déclencheurs d’e-mail pour déterminer si un e-mail doit être automatiquement envoyé à la fin d’une enquête.
- Déclencheurs de liste de contacts pour déterminer si un répondant doit être ajouté à une liste de contacts.
- Extension Salesforce pour aider le système à déterminer ce qu’il doit communiquer à Salesforce.
- Données et analyse et Rapports dans le cadre de votre analyse.
Création d’un élément de données intégrées
- Dans l’onglet Enquête, cliquez sur Flux d’enquête.
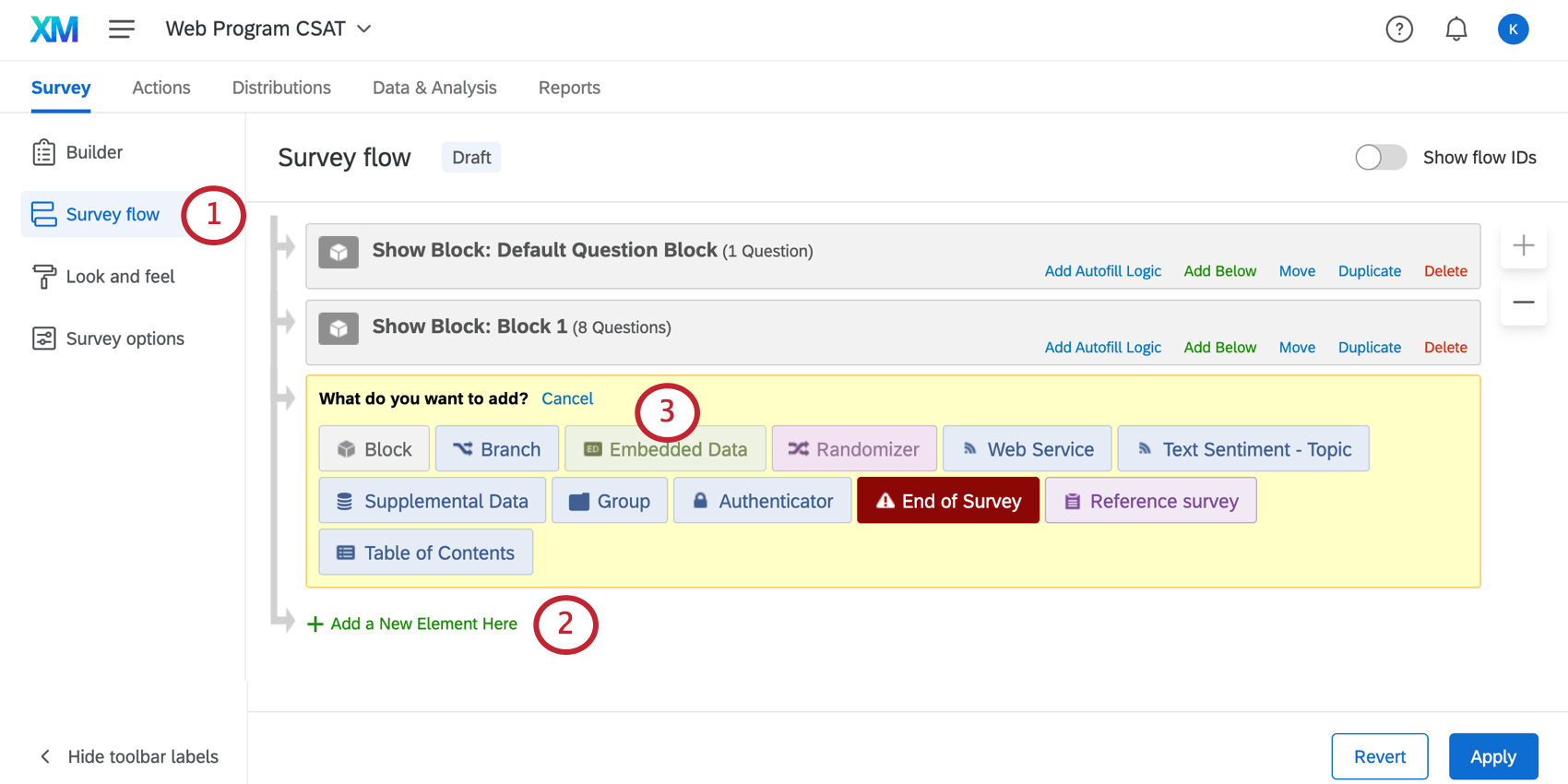
- Cliquez sur Ajouter un nouvel élément ici.
Astuce Qualtrics : souhaitez-vous placer vos données intégrées sous un élément ? Cliquez sur Ajouter ci-dessous sur cet élément.
- Sélectionnez Données intégrées.
- Cliquez sur Créer un nouveau champ ou Sélectionner dans le menu déroulant et saisissez le nom de votre champ, ou sélectionnez un champ existant dans la liste déroulante.
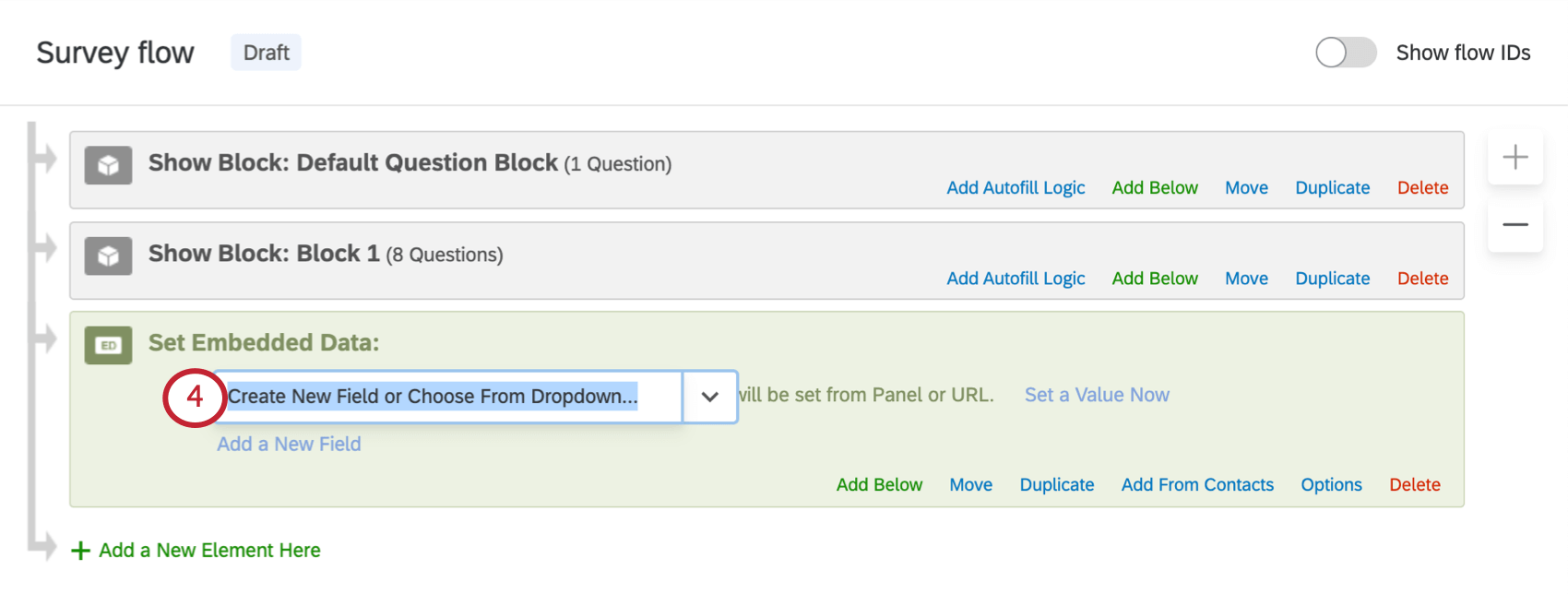 Astuce Qualtrics : essayez d’éviter les caractères spéciaux tels que les émojis, les points (.) et les hashtags (#) lorsque vous nommez vos données intégrées. En outre, le nom de champ RID (ou rid) est un champ Qualtrics réservé utilisé pour les processus de plateforme back-end. Vous ne devez jamais donner ce nom à aucun de vos champs de données intégrées.
Astuce Qualtrics : essayez d’éviter les caractères spéciaux tels que les émojis, les points (.) et les hashtags (#) lorsque vous nommez vos données intégrées. En outre, le nom de champ RID (ou rid) est un champ Qualtrics réservé utilisé pour les processus de plateforme back-end. Vous ne devez jamais donner ce nom à aucun de vos champs de données intégrées. - Si vous le souhaitez, définissez une valeur en cliquant sur le texte bleu Définir une valeur maintenant.
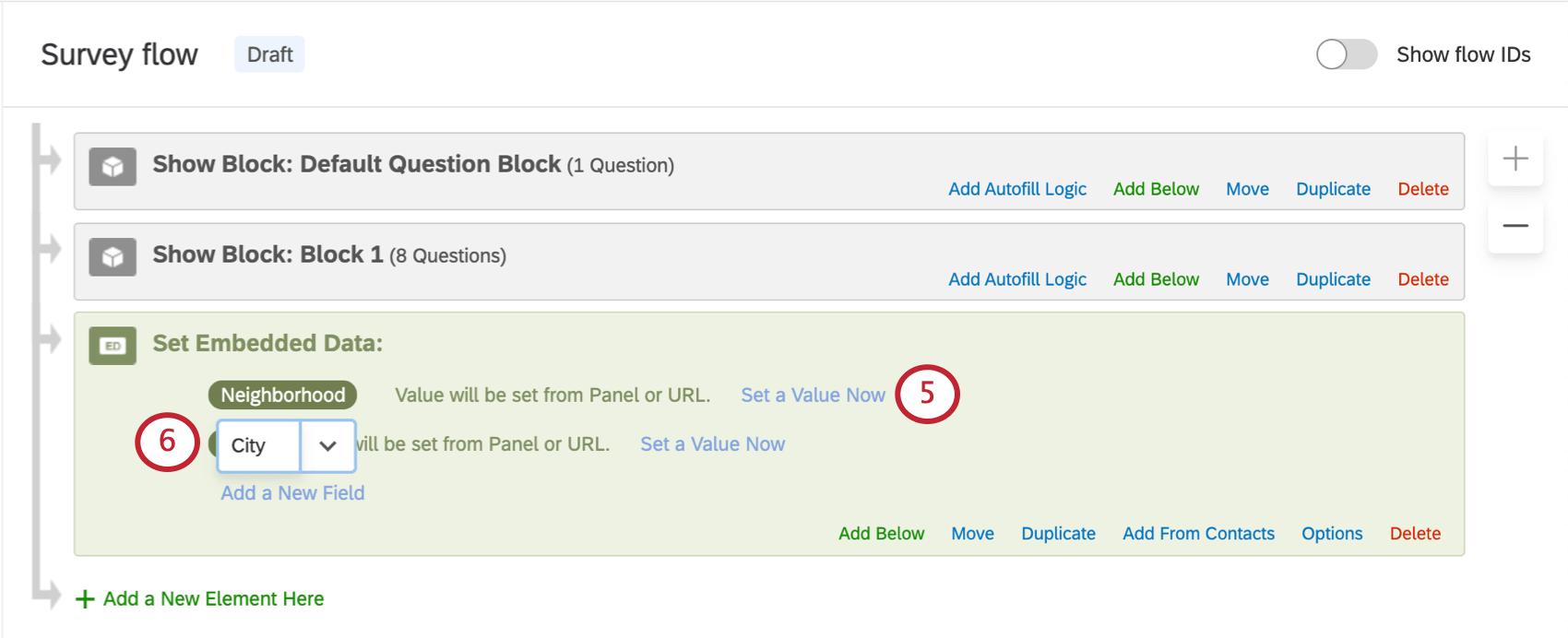
- Si vous le souhaitez, cliquez sur Ajouter un nouveau champ pour ajouter plusieurs champs à l’élément.
Astuce Qualtrics : si l’emplacement de votre élément de données intégrées ne vous convient pas, cliquez sur Déplacer et maintenez-le enfoncé pour faire glisser l’élément ailleurs dans le flux.
Sélectionner dans une liste déroulante
Lorsque vous attribuez un nom à des données intégrées, cliquez sur la flèche déroulante bleue pour les afficher et consulter les options intégrées supplémentaires.
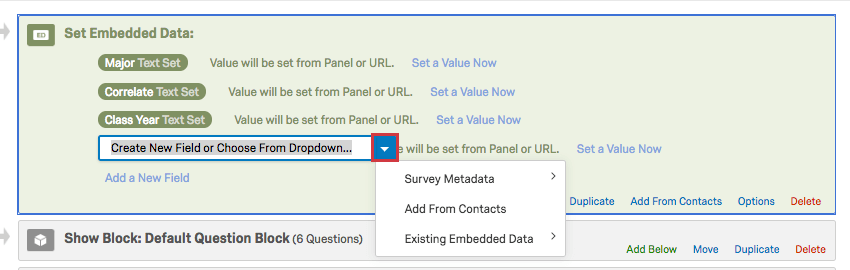
- Métadonnées de l’enquête : cette option inclut un certain nombre de données intégrées agrégées à Qualtrics. Consultez la section associée pour en savoir plus sur ce que cela inclut.
- Ajouter à partir des contacts : ajoutez l’une des données intégrées que vous avez enregistrées dans votre liste de contacts. Consultez cette section pour savoir comment extraire simultanément chacune de ces données intégrées.
- Données intégrées existantes : cela vous permet de sélectionner des données intégrées qui sont déjà dans votre flux d’enquête. Par exemple, si deux branches différentes obtiennent deux valeurs différentes à partir des mêmes données intégrées. C’est vraiment utile pour éviter les fautes de frappe et ainsi s’assurer que toutes les données se trouvent dans le même champ.
Attention : Si vous créez vos propres variables de données intégrées, voici quelques champs par défaut pour lesquels vous ne devez jamais donner de nom à un champ de données intégrées (pas de distinction entre majuscules et minuscules) :
- SID (signification : identifiant de l’enquête)
- RID (signification : éliminer)
- Auditable (signification : vérifiable)
- EndDate (signification : date de fin)
- RecordedDate (signification : date d’enregistrement)
- StartDate (signification : date de début)
- Status (signification : statut)
- Points : il s’agit d’un champ réservé dans le Répertoire XM.
Si vous attribuez l’un de ces noms à un champ de données intégrées, le message suivant apparaîtra : « La valeur du champ de données intégrées X est laissée vide intentionnellement pour éviter des problèmes avec les métadonnées de l’enquête », et aucune donnée ne sera enregistrée pour ce champ. En outre, voici une liste des données intégrées existantes que vous pouvez utiliser, mais pour lesquelles vous ne pouvez pas définir de valeurs personnalisées.
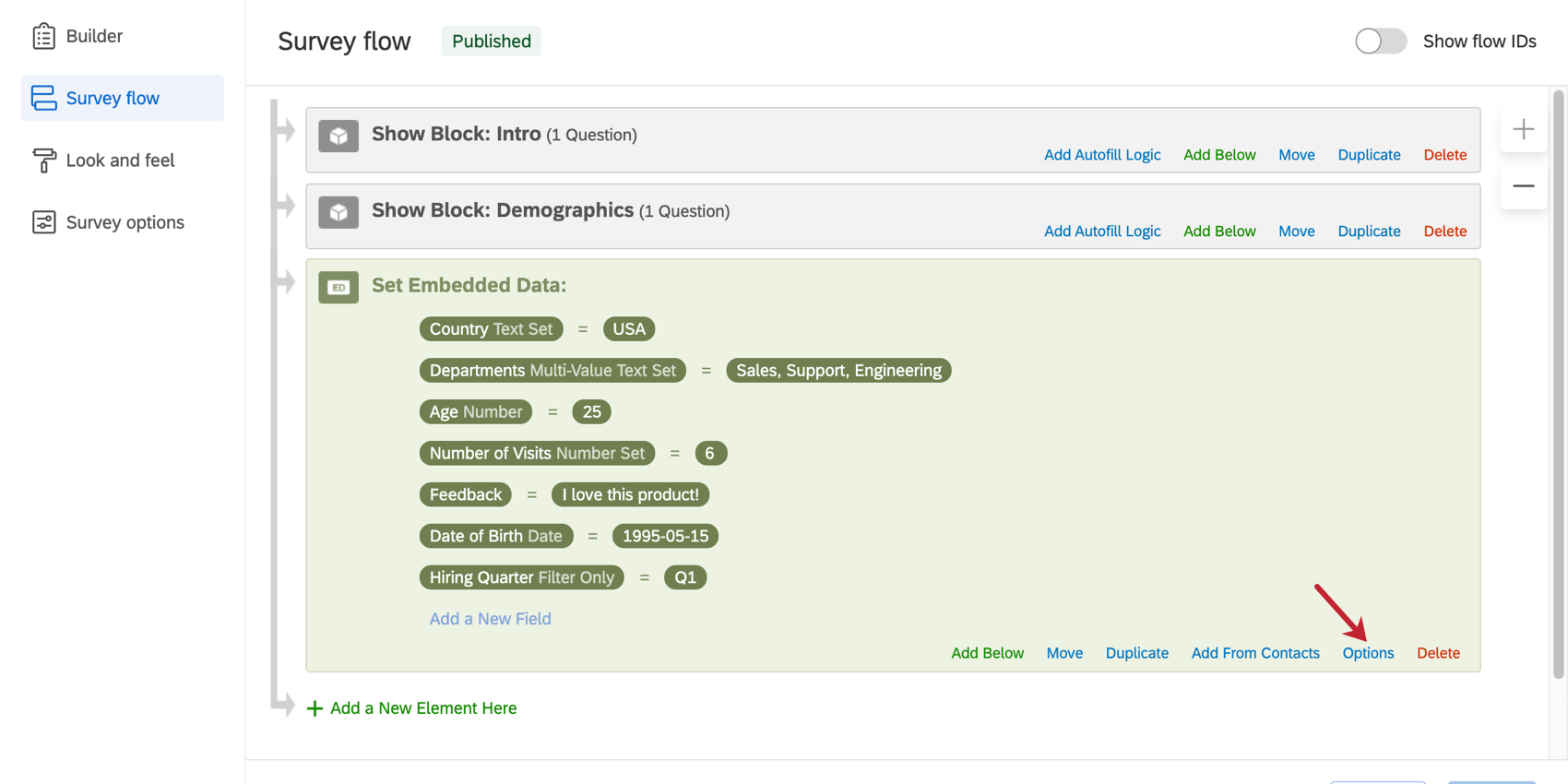
Options de données intégrées
Les options relatives aux données intégrées vous permettent de déterminer quelles données intégrées sont éligibles pour l’analyse sémantique, ainsi que de modifier le type de variable de chaque donnée intégrée.
Si vous souhaitez ventiler vos rapports en fonction de l’âge du participant ou si vous devez affecter plusieurs services à une personne en fonction d’une variable de données intégrées, vous devrez peut-être modifier le type de variable. Modifier le type de variable de vos données intégrées peut permettre d’assouplir les méthodes d’enregistrement de vos données.
- Cliquez sur Options dans le coin inférieur droit de votre élément de données intégrées.
- Pour chaque champ de données intégrées, choisissez un type de variable dans la liste déroulante. Consultez notre section ci-dessous pour obtenir une explication complète sur chaque type de variable.
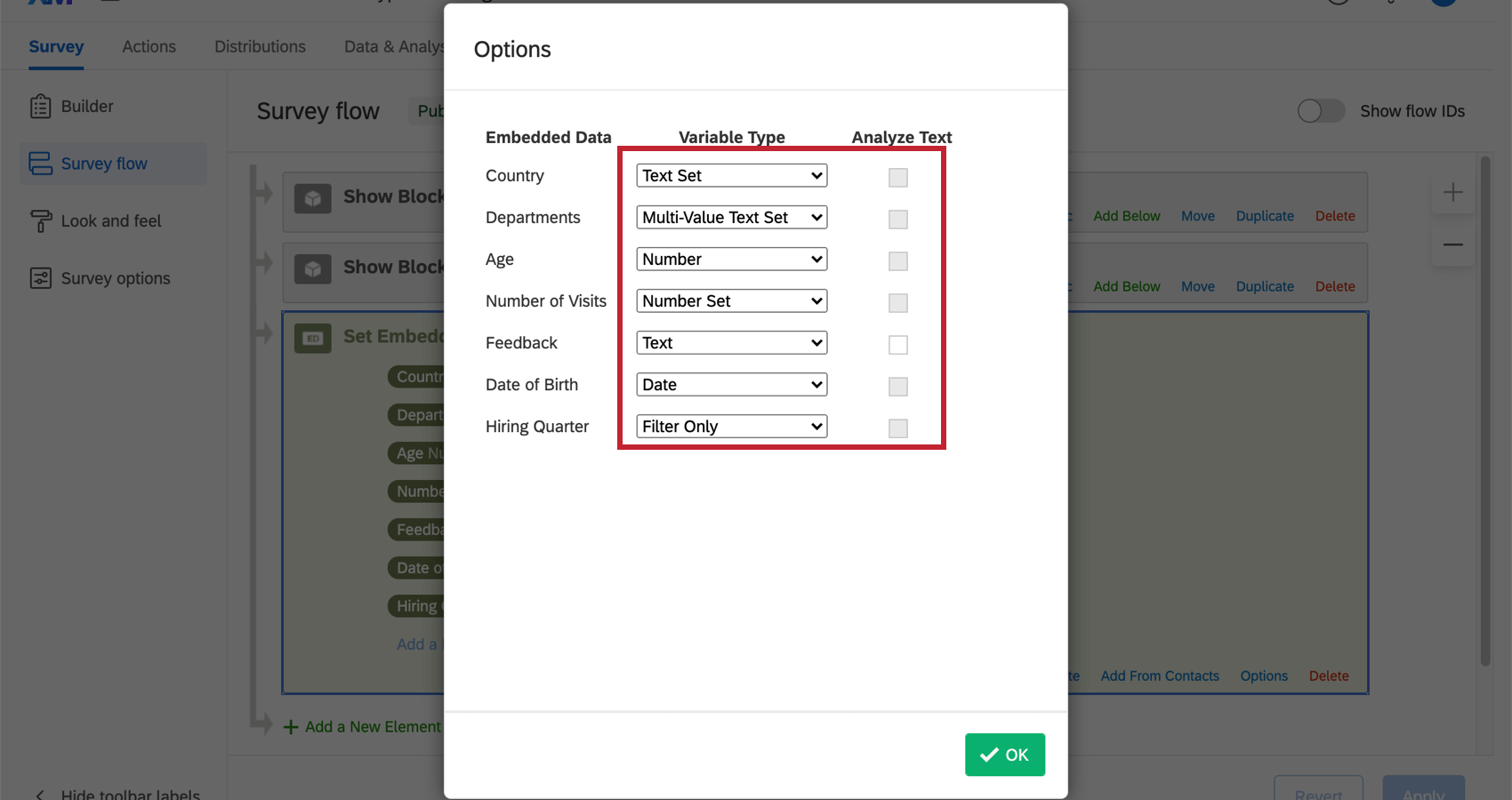
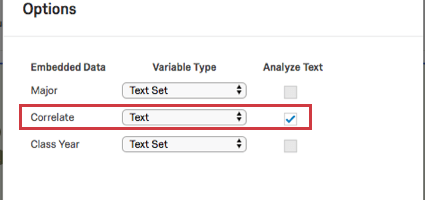
- Si le type de variable est Type de texte, vous pouvez également sélectionner Analyser le texte pour inclure les données intégrées dans l’analyse de texte.
- Cliquez sur OK.
Types de variables de données intégrées
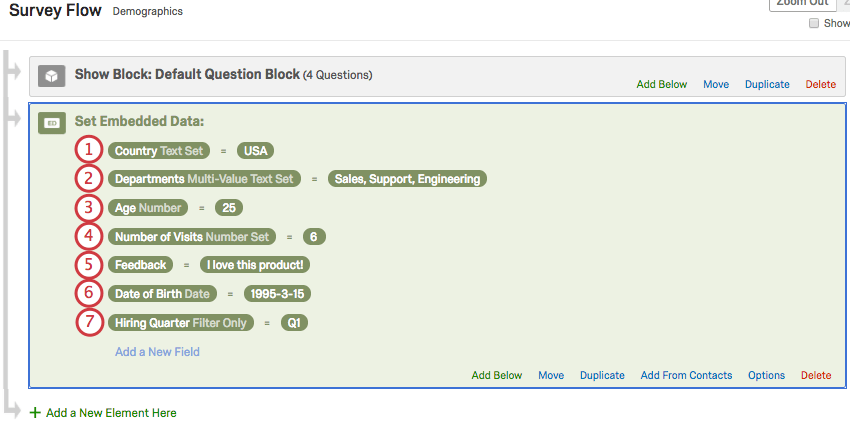
- Ensemble de texte : cette variable autorise les valeurs discrètes contenant des lettres, des chiffres ou des caractères spéciaux. Une seule valeur peut être affectée à une variable d’ensemble de texte à la fois. Cette fonctionnalité fonctionne bien avec les découpages dans les rapports.
- Ensemble de texte à valeurs multiples : cette variable fonctionne de la même manière que l’ensemble de texte, mais elle permet d’affecter plusieurs valeurs séparées par des virgules au lieu d’une seule à la fois.
- Nombre : il s’agit d’un type de variable continue. Les valeurs doivent être au format numérique et les rapports peuvent déterminer à la fois les valeurs statistiques et le nombre de réponses individuelles fournies. Par exemple, vous pouvez utiliser une donnée intégrée sous forme de chiffre pour calculer l’âge moyen, mais également pour créer un tableau indiquant le nombre de personnes âgées de 18 ans qui participent à votre étude. Ce type n’est pas compatible avec les découpages.
- Ensemble de nombres : il s’agit d’une variable ordinale. Les valeurs doivent être au format numérique et peuvent être utilisées en tant que valeurs discrètes pour rechercher des comptes ou effectuer des répartitions.
- Texte : comme il s’agit du type de variable par défaut, le libellé est souvent omis dans l’élément de données intégrées. Ce type de variable est compatible avec les visualisations de rapports spécifiques au texte, telles que les tableaux de questions et les nuages de mots. Elle peut également être analysée avec la fonction Text iQ, mais uniquement si vous sélectionnez Analyser le texte lors de sa création (voir les étapes ci-dessus).
- Date : lorsque les valeurs sont enregistrées au format AAAA-MM-JJ, ce type de variable vous permet d’accéder à des filtres spéciaux en fonction de la période.
Astuce: Pour que la date s’affiche correctement lorsque vous utilisez le champ Données intégrées, assurez-vous que la date est dans l’un des formats suivants :
- AAAA-MM-JJ
- AAAAMMJJ
- AAAAMMJJ:HHMMSS
- AAAA-MM-JJ HH:MM:SS
- AAAA-MM-JJ’T’HH:MM:SS.sss’Z’
- Filtre uniquement : ce type de variable est similaire à un type Ensemble de texte, mais vous permet de filtrer vos données en fonction du texte contenu dans les valeurs, et pas seulement de valeurs exactes et de vides. Par exemple, vous pouvez filtrer tous les départements contenant le nom « Ventes », et pas uniquement les Ventes au sens strict.
Définir des valeurs dans le flux d’enquête
Souvent, la valeur de vos données intégrées est conservée en dehors de l’enquête, par exemple dans une liste de contacts, ou ajoutée à la fin du lien vers une enquête du répondant. Vous pouvez toutefois également définir la valeur manuellement dans le flux d’enquête.
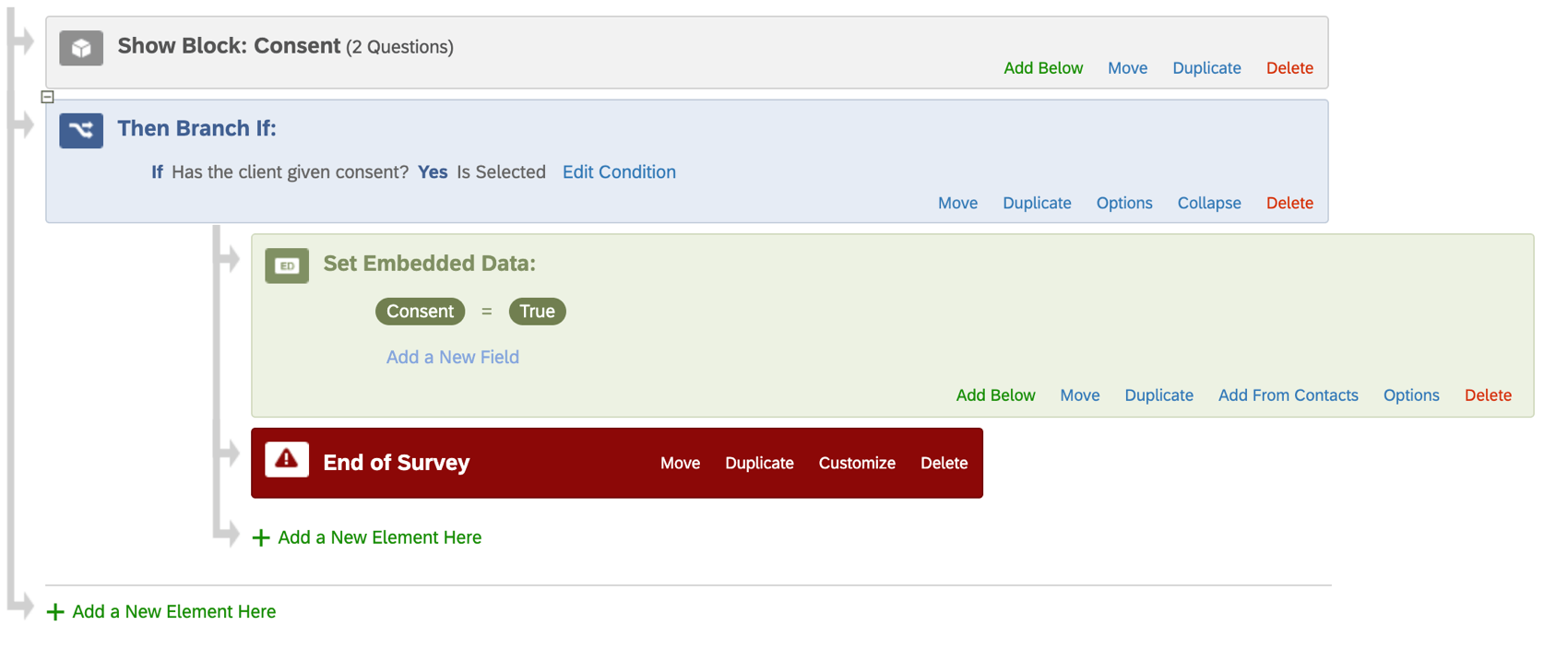 Chaque répondant qui remplit cette condition de branche verra sa réponse marquée avec un champ de données intégrées appelé Consentement défini sur une valeur de Vrai.
Chaque répondant qui remplit cette condition de branche verra sa réponse marquée avec un champ de données intégrées appelé Consentement défini sur une valeur de Vrai.
Pour définir une valeur dans le flux d’enquête
- Ajoutez un élément de données intégrées à votre flux d’enquête.
- Cliquez sur Saisir le nom du champ de données intégrées ici et saisissez votre nom de champ.
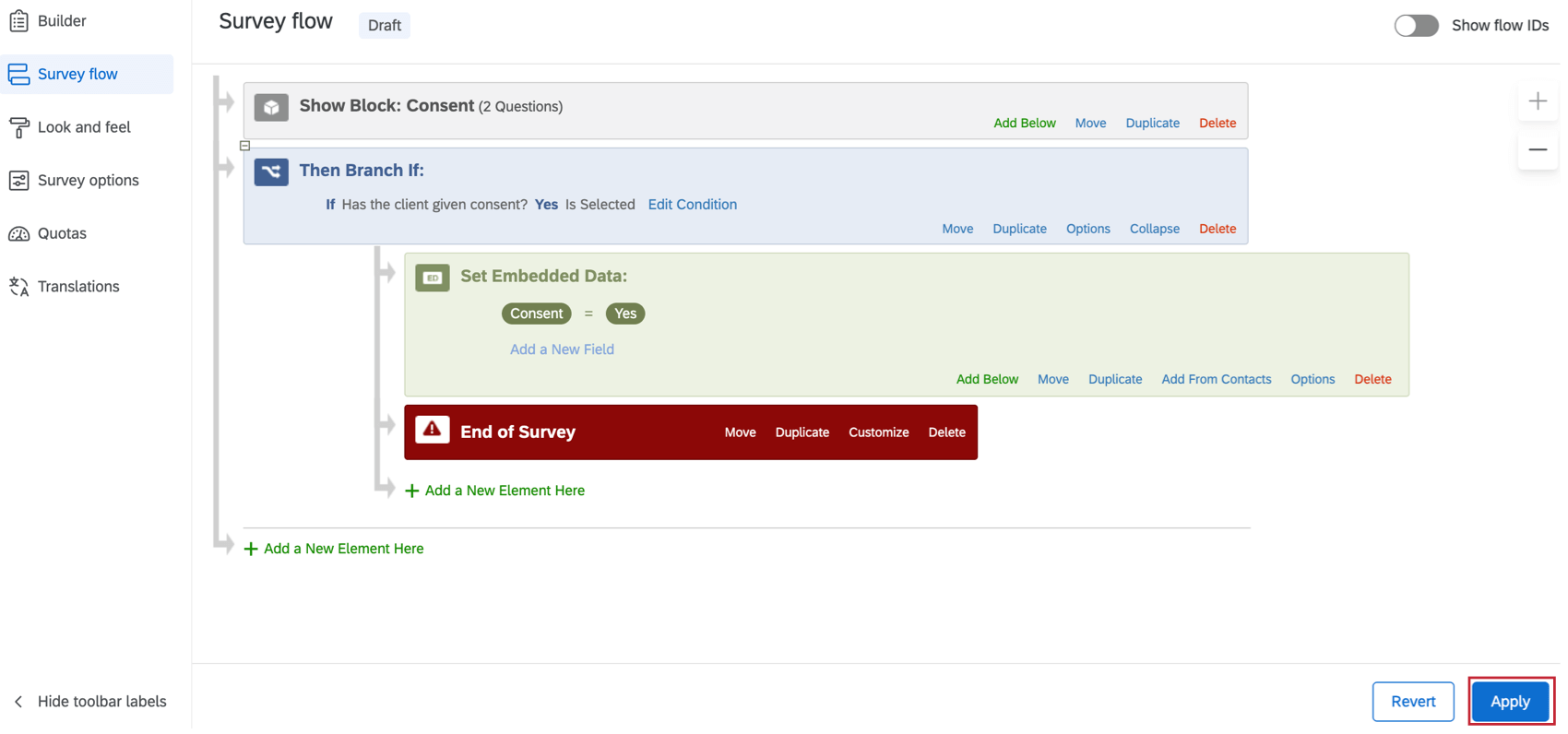
- Cliquez sur Définir une valeur maintenant.
- Saisissez la valeur appropriée ou cliquez sur le menu déroulant bleu pour insérer le texte inséré.
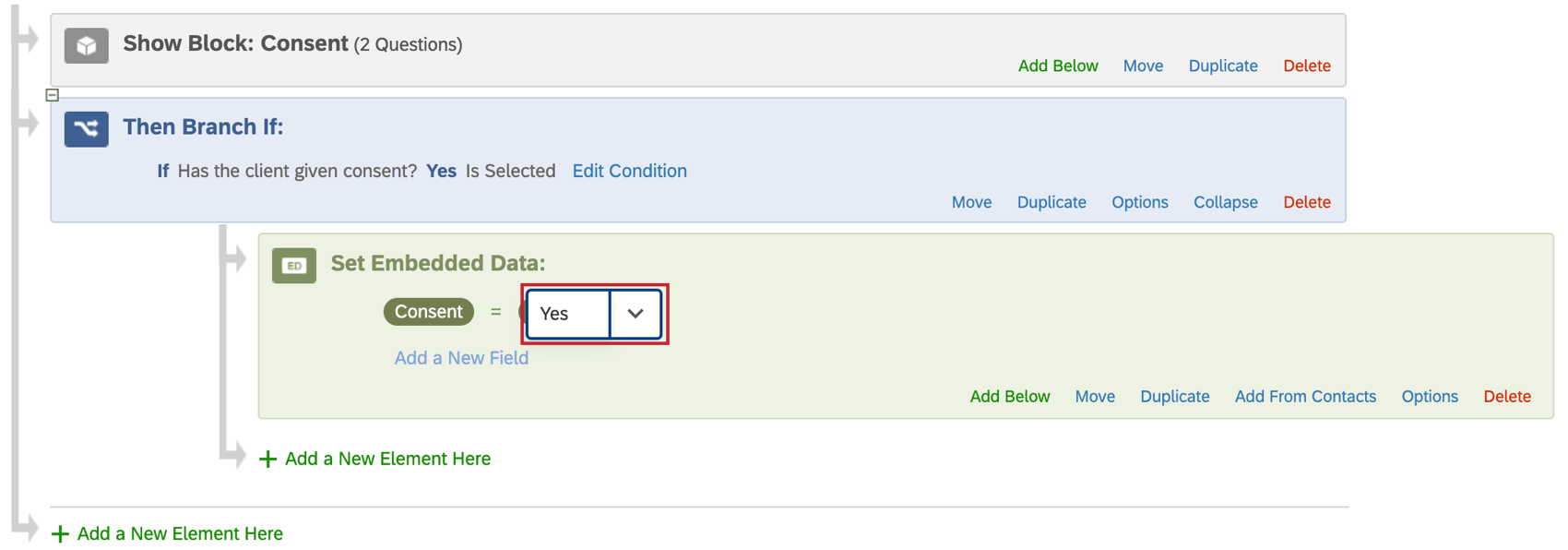 Astuce Qualtrics : l’utilisation du texte inséré comme valeur de vos données intégrées permet à cette valeur de changer dynamiquement pour chaque répondant en fonction de ses réponses aux questions ou d’autres critères.
Astuce Qualtrics : l’utilisation du texte inséré comme valeur de vos données intégrées permet à cette valeur de changer dynamiquement pour chaque répondant en fonction de ses réponses aux questions ou d’autres critères. - Cliquez sur Appliquer lorsque vous avez terminé.
Définir les valeurs d’une liste de distribution
Une liste de distribution est une liste de distribution utilisée pour distribuer des enquêtes de différentes manières sur Qualtrics, notamment par : e-mail, liens unique et distributions par SMS (messages textes). En plus d’inclure les noms et les adresses e-mail de chaque destinataire de cette liste, vous pouvez inclure toutes les données démographiques ou uniques que vous souhaitez dans une liste de distribution. Par exemple, en plus du nom et de l’e-mail, la liste de distribution dans la capture d’écran ci-dessous inclut les champs de données intégrées Poste, État et Numéro de projet. Tout ce que nous avons eu à faire pour inclure ces informations dans la liste de contacts a été d’ajouter ces colonnes de données à notre fichier de contacts avant de l’importer.

Cependant, ce n’est pas parce que les données intégrées se trouvent dans notre liste de contacts qu’elles sont automatiquement incluses dans les données de l’enquête. En ajoutant un élément de données intégrées dans votre flux d’enquête, vous pouvez enregistrer ces informations dans vos résultats pour les utiliser dans votre analyse.
Pour inclure des informations de votre liste de contacts à vos données d’enquête
- Ajoutez un élément de données intégrées à votre flux d’enquête.
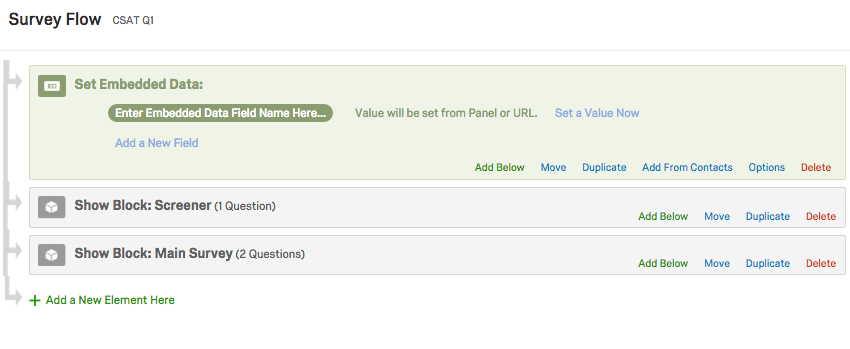 Astuce Qualtrics : bien que cet élément puisse être placé n’importe où dans le flux d’enquête, il est préférable de placer ces éléments de données intégrées au début de votre enquête.
Astuce Qualtrics : bien que cet élément puisse être placé n’importe où dans le flux d’enquête, il est préférable de placer ces éléments de données intégrées au début de votre enquête. - Cliquez sur Ajouter à partir des contacts.
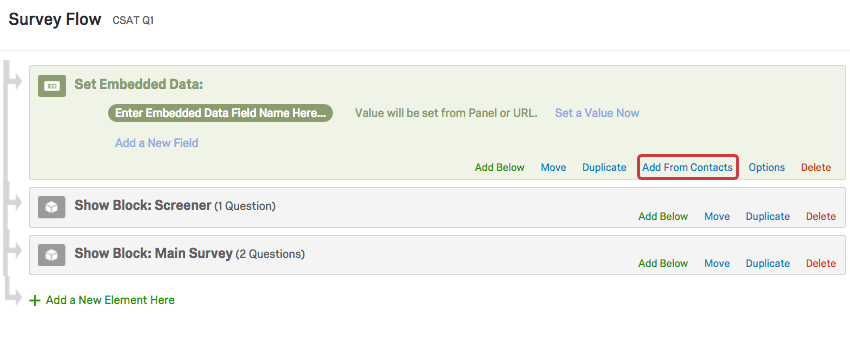
- Sélectionnez la liste de contacts à partir de laquelle vous souhaitez extraire les données intégrées et cliquez sur OK.
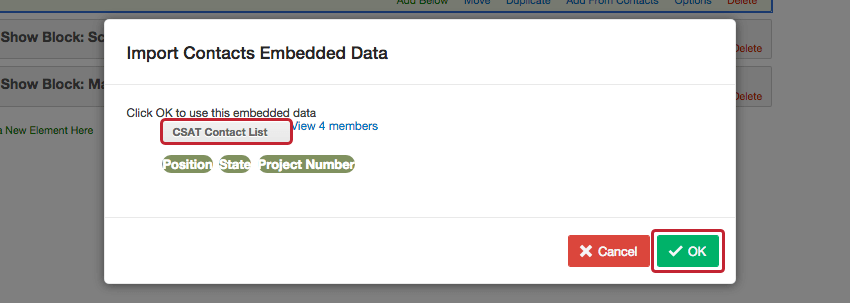
- Ajoutez d’autres champs de données intégrées en cliquant sur Ajouter un nouveau champ et en saisissant le nom de votre champ.
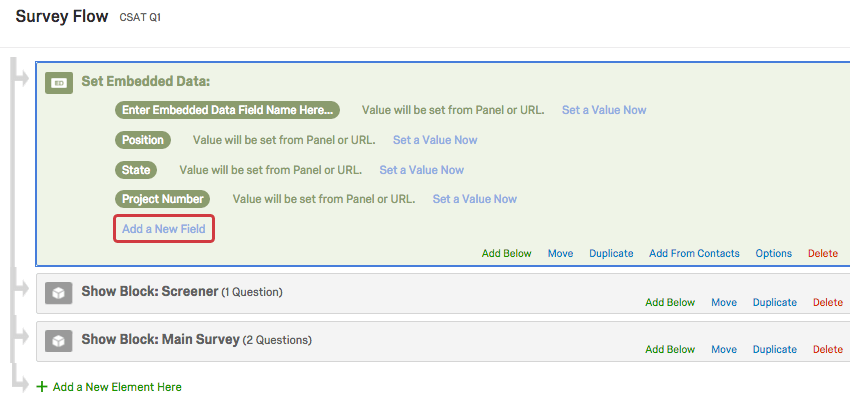
Définir des valeurs à partir de l’URL de l’enquête
Si vous ne distribuez pas votre enquête à une liste de contacts, vous pouvez toujours importer des données intégrées dans l’enquête pour chaque répondant en ajoutant les noms et valeurs de vos champs de données intégrées à la fin du lien vers l’enquête.

Supposons que nous préparions deux versions de notre lien anonyme: une qui indique que la source du répondant est Facebook et une autre qui indique que la source est Twitter. Ces liens anonymes amèneront les répondants vers la même enquête. La seule différence est la « Source » du réseau social ajoutée à la fin. Une fois prêt à être distribué, il ne nous restera qu’à publier le lien Facebook sur Facebook et le lien Twitter sur Twitter. Lorsqu’un répondant accède au lien vers une enquête, Qualtrics lit son lien d’enquête et sait de quelle « source » il provient.
Les données intégrées peuvent être ajoutées à n’importe quel type de lien d’enquête et vous pouvez ajouter différentes données intégrées à un seul et même lien. Pour en savoir plus sur les instructions étape par étape, consultez la page de support Transmission d’informations via des chaînes de requête.
Définir des valeurs avec des champs intégrés de données intégrées
En plus de créer vos propres variables de données intégrées ou de les extraire d’autres sources, vous avez également accès à certaines variables intégrées que Qualtrics enregistre pour chaque réponse. Ces éléments peuvent être ajoutés au flux d’enquête avant ou après avoir collecté les réponses en suivant les étapes décrites dans la section Créer un élément de données intégrées . Vous n’aurez pas besoin de définir une valeur lorsque vous utiliserez ces champs, car chacun d’entre eux remplit une fonction particulière dans les réponses (décrites ci-dessous) et l’utilise pour déterminer la valeur. Veuillez noter que de ce fait, vous ne pourrez pas définir de valeurs personnalisées pour ces champs dans le flux d’enquête.
Les champs de données intégrées suivants peuvent être ajoutés à votre enquête :
| Nom du champ | Description |
| AnonymizeResponse | Cet élément est défini par le système pour indiquer si la réponse a été rendue anonyme ou non. 1 = anonyme, 0 = non anonyme. |
| ContactID (ID de contact) | Cet élément vous fournit l’ID de contact associé à la personne qui a répondu à votre enquête. Notez que cette zone est vide si vous effectuez une distribution via une méthode de distribution anonyme. |
| ContactSegmentIDs | Cet élément vous fournit les ID de segment du Contact, qui identifient tous les segments dont le répondant est membre au moment où l’enquête a été réalisée. Voir cette page pour plus d’informations sur l’utilisation des segments dans le Répertoire XM. Ce champ sera vide si vous effectuez une distribution anonyme. |
| IdentifiantAppareil | Lors de l’utilisation de l’application hors ligne, cet élément enregistre quel appareil a été utilisé pour enregistrer la réponse. Ce champ doit être défini dans votre application hors ligne et peut être mis à jour à tout moment en cliquant sur l’icône d’engrenage située en haut à droite de l’application, mais cela n’aura d’impact sur DeviceIdentifier que pour les réponses à venir. Pour plus d’informations, consultez la page de support Configurer l’application hors ligne. |
| ExternalDataReference (Référence externe de données) | Cet élément vous permet de voir le champ Référence externe de données de la liste de contacts. Cela peut être utile si la liste de contacts a été supprimée. |
| Terminé | Les enquêtes que les répondants ont terminées jusqu’à ce qu’ils aient cliqué sur le dernier bouton Suivant sont VRAIES. Les réponses en cours qui n’ont jamais été soumises et qui ont finalement été enregistrées ou clôturées sont FAUSSES. |
| PanelID (Identifiant du panel) | Cet élément vous donnera l’identifiant de la liste de contacts (c’est-à-dire du panel) à laquelle appartient chaque répondant. Les identifiants de panel correspondants sont disponibles dans la section ID Qualtrics des Paramètres du compte. |
| PanelMemberID | Cet élément vous fournit l’identifiant du membre du panel (identique au RID) associé au répondant qui a participé à votre enquête. Notez que cette zone est vide si vous effectuez une distribution via une méthode de distribution anonyme. |
| Aperçu | Cet élément est défini par le système pour identifier si la réponse est un aperçu ou non. Enquête = aperçu de l’enquête, 0 = pas d’aperçu. Une valeur vide signifie qu’il s’agit d’une réponse test. |
| Q_BallotBoxStuffing | Le champ de détection de fraude qui enregistre quand la fonction Empêcher les envois multiples est définie pour continuer l’enquête et définir un champ de données intégrées. Un champ True/False (Vrai/Faux) dans lequel True signifie que le répondant est un doublon. |
| Q_CHL | Cet élément vous indique le canal de distribution d’où provient la réponse. Il s’agit d’un outil utile pour diagnostiquer la manière dont la personne interrogée a accédé à l’enquête. |
| Q_DataPolicyError | Un champ True/False (Vrai/Faux) associé aux paramètres de politique concernant les données sensibles. Défini sur True (Vrai) en cas d’erreur lors de la vérification de cette réponse concernant les violations de données privées. |
| Q_DataPolicyViolations | Champ multitexte séparé par des virgules associé à la politique concernant les données sensibles. Liste des politiques relatives aux données personnelles enfreintes dans la réponse, de type « numéro de sécurité sociale, numéro de carte de crédit, date de naissance, blasphème ». |
| Q_DL | Cet élément de lien de distribution permet de relier la réponse à la liste de contacts. La technologie de l’information est formatée par l’identifiant de distribution, l’identifiant d’enquête et l’identifiant de recherche de contact. |
| Q_EED | Cet ensemble d’éléments dans votre flux d’enquête vous permet de transmettre des informations codées par le biais de chaînes de requête. |
| Q_EMD | Cet élément vous permet de voir l’e-mail, le lien unique ou l’ID de distribution SMS dans lequel le lien de l’enquête a été envoyé. |
| Q_FILE_NAME | Cet élément enregistre le nom du fichier source lorsque les enquêtes sont distribuées par le biais d’automatismes. |
| Q_Language | Cet élément vous permet de suivre dans quelle langue un répondant participe à l’enquête. Ces informations sont consignées dans les données de l’enquête à l’aide d’un code de langue à deux lettres, comme indiqué dans la section Codes de langue disponibles de la page Traduire l’enquête. |
| Q_LastModified | Chronomètre l’heure Unix en UTC pour la version de l’enquête dans laquelle la réponse a été prise. |
| Q_PopulateResponse | Cela peut être utilisé comme paramètre d’URL pour prérenseigner les réponses à l’enquête. Par exemple, si vous souhaitez poser une question de l’enquête dans un e-mail, l’image associée à chaque choix de réponse transmet une valeur différente et lorsque le répondant accède à l’enquête complète, la réponse a déjà une valeur, prête à être validée ou modifiée par le répondant qui peut ensuite poursuivre son enquête. Pour plus d’informations, voir Comment utiliser Q_PopulateResponse. |
| Q_Preview | Cet élément est défini par le système pour identifier si la réponse était un aperçu ou non. 1 = aperçu, blanc = pas d’aperçu |
| Q_R | Cet élément enregistre l’ID de la Réponse enregistrée lors de l’utilisation d’un lien de resoumettre la réponse. |
| Q_RD | Cet élément est l’ID de rappel de distribution inclus dans un lien vers une enquête envoyé à un destinataire pour lui rappeler de participer à une enquête. |
| Q_R_DEL | Cet élément est défini par le système pour indiquer si la réponse originale du lien de resoumettre a été supprimée ou non. 1 = supprimée, blanc = non supprimée. |
| Q_RecaptchaScore | Champ de détection de fraude qui enregistre lorsque la détection des bots est activée. Score renvoyé avec la technologie reCaptcha v3. Un score de 0,0 signifie que le répondant est probablement un bot. Un score de 1,0 signifie qu’il est probablement humain. |
| Q_RecipientPhoneNumber | Ces données intégrées enregistrent le numéro de téléphone d’une personne participant à une enquête par SMS entrant. Q_RecipientPhoneNumber est rétroactif. |
| Q_RelevantIDDupliquer | Détection de fraude qui enregistre quand RelevantID est activé. Un champ True/False (Vrai/Faux) dans lequel « True » (Vrai) signifie que la réponse est probablement un doublon. |
| Q_RelevantIDDuplicateScore | Détection de fraude qui enregistre quand RelevantID est activé. Nombre de 0 à 100. Indique le degré de certitude de RelevantID concernant le fait que le répondant soit un doublon. Plus le score est élevé, plus le degré de certitude est élevé. |
| Q_RelevantIDFraudScore | Détection de fraude qui enregistre quand RelevantID est activé. Nombre de 0 à 130. Mesure de probabilité que le répondant soit frauduleux. Un score de 130 signifie que le répondant est très probablement frauduleux. |
| Q_RelevantIDLastStartDate | Le champ Détection de fraude enregistre lorsque RelevantID est activée. Si Q_RelevantIDDuplicate est vrai (1), ce champ indiquera la dernière date à laquelle l’enquête a débuté. |
| Q_SMSAccessCode | Capture le code d’accès utilisé pour entrer dans une enquête par SMS. |
| Q_SurveyVersionID | Cet élément vous donne l’identifiant de la version de l’enquête d’où provient la réponse à l’aperçu. |
| Q_TerminateFlag | Marque les réponses comme Exclues ou QuotaMet (Quota Atteint). Pour plus de détails, consultez la page Option Marquer la réponse. |
| Q_TotalDuration | Cet élément vous permet de consulter la durée totale (en secondes) de la réponse à l’enquête. Cela inclut le temps pendant lequel l’enquête est ouverte et le temps passé hors de l’enquête si l’utilisateur ferme l’enquête et y retourne. Cette fonction est disponible depuis le 16 juillet 2012 et n’est pas disponible pour les réponses enregistrées avant cette date.
Pour l’instant, Q_TotalDuration ne fonctionne pas avec l’application hors ligne. |
| Q_URL | Cet élément vous permet d’afficher la première URL utilisée pour accéder à l’enquête. Veuillez noter qu’il omet l’URL de base, affichant uniquement le chemin et les données d’URL supplémentaires. C’est un outil utile pour diagnostiquer les problèmes dans lesquels les paramètres d’URL ne sont pas enregistrés comme prévu. |
| Q(State/City)_ExportTag_suffix | Lorsque vous utilisez la validation du contenu du code postal pour une question contenant un champ avec saisie du texte, vous pouvez utiliser Q(State/City)_ExportTag_suffix en tant que données intégrées pour enregistrer la ville ou l’état indiqué par un code postal. Par exemple, si votre deuxième question demande le code postal et que vous souhaitez connaître l’état, vous appellerez la donnée intégrée QState_Q2. Si Q2 est un formulaire demandant le nom, le numéro de téléphone et enfin le code postal, il s’agira de QState_Q2_3, car le code postal est le troisième champ de texte. Pour plus d’informations, consultez la section étape par étape de la page de support Validation. |
| RecipientEmail (E-mail du destinataire) | Cet élément vous permet de voir le champ PrimaryEmail (E-mail principal) de la liste de contacts. Cela peut être utile si la liste de contacts a été supprimée. |
| RecipientFirstName (Prénom du destinataire) | Cet élément vous permet de voir le champ FirstName (Prénom) de la liste de contacts. Cela peut être utile si la liste de contacts a été supprimée. |
| RecipientID (Identifiant du destinataire) | Cet élément vous permet de voir l’identifiant du destinataire du contact, depuis son panel. |
| Langue du destinataire | L’ajout de cet élément de données intégrées dans le flux d’enquête renverra la langue associée au contact du répondant dans le Répertoire XM. Contrairement à Q_Language et Q_lang, il ne reflète pas nécessairement la langue dans laquelle l’enquête a été remplie. |
| RecipientLastName (Nom du destinataire) | Cet élément vous permet de voir le champ LastName (Nom) de la liste de contacts. Cela peut être utile si la liste de contacts a été supprimée. |
| Numéro de téléphone du destinataire | L’ajout de ce champ au Flux d’Enquête dans un compte avec Répertoire XM capturera la valeur du champ Numéro de téléphone réservé dans la liste de distribution. |
| Referer (Référent) | Cet élément indique la page sur laquelle se trouvait le répondant lorsqu’il a cliqué sur le lien vers une enquête. Dans la plupart des enquêtes envoyées par e-mail, vous verrez une URL pour le prestataire de messagerie. Si l’enquête est reliée à une redirection automatique, telle qu’une redirection par URL à la fin d’une autre enquête, aucune valeur n’est enregistrée. |
| ResponseID (Identifiant de la réponse) | Cet élément vous fournira l’identifiant de réponse attribué par Qualtrics pour cette réponse. Cet identifiant peut être utilisé dans les services Web, les appels API et d’autres applications. Ce champ n’est pas disponible pour les réponses importées. Cependant, un ResponseID est toujours affecté aux réponses importées lors de l’importation, et cet ID est disponible dans la section Informations sur le répondant de votre ensemble de données. |
| SessionID (Identifiant de la session) | L’ID associé à une réponse en cours avant qu’elle soit envoyée et qu’un ID de réponse lui soit affecté. Ce champ est utilisé dans les appels d’API. |
| SurveyID (ID d’enquête) | Cet élément vous fournira l’identifiant d’enquête attribué par Qualtrics à l’enquête à laquelle la personne a répondu. Cet identifiant peut être utilisé dans les services Web, les appels API et d’autres applications.
Il existe un champ similaire de données intégrées nommé sid ou SID, qui n’extrait l’ID d’enquête qu’après la fin de la session d’enquête. |
| UserAgent (Agent utilisateur) | Cet élément fournit des informations sur le système d’exploitation et le navigateur du répondant. Pour une version plus facile à lire de cette question, envisagez d’ajouter une question méta-informations masquée à votre enquête. |
Définir des valeurs à partir d’autres sources
En plus d’utiliser des données intégrées à partir d’une liste de contacts ou de l’URL du lien d’enquête, vous pouvez également extraire des données intégrées à partir d’autres sources.
Données intégrées dans un service Web
Un service Web vous permet d’extraire des données d’un site Web externe dans votre enquête. Par exemple, si vous voulez extraire le grand titre du jour de CNN ou les coordonnées du client à partir de votre propre base de données interne. Les informations extraites d’un service Web sont enregistrées en tant que données intégrées. Pour en savoir plus sur l’utilisation d’un service Web pour extraire des données intégrées d’un autre site Web, consultez notre page Service Web .
Données intégrées avec Salesforce
Si votre compte Qualtrics inclut les Intégrations de l’extension Salesforcevous pouvez intégrer des données intégrées à votre enquête à partir de Salesforce à l’aide de la fonction Déclencher et envoyer l’enquête par e-mail.
Données intégrées dans les avis sur un site Web
Voir Données intégrées avec retour d’information sur le site web.
Données intégrées dans le Répertoire XM
Le comportement des données intégrées dans le Répertoire XM est presque exactement le même que celui décrit sur cette page. L’une des principales différences, cependant, est la possibilité de gérer les données intégrées au niveau du répertoire. Pour plus de détails, voir Manager les données intégrées.
Données transactionnelles
Les
transactions vous permettent d’enregistrer les données d’interaction relatives aux événements associés à vos contacts en représentant une interaction spécifique à un moment donné. Vous pouvez définir des données intégrées à l’enquête en fonction des données de transaction.
- Ajoutez un élément de données intégrées à votre flux d’enquête.
Astuce Qualtrics : bien que cet élément puisse être placé n’importe où dans le flux d’enquête, il est préférable de placer ces éléments de données intégrées au début de votre enquête. - S’il est indiqué Saisir le nom du champ de données intégrées ici, saisissez le nom de votre champ de transaction.
Astuce Qualtrics : il se peut que vous ne puissiez pas sélectionner ce champ dans la liste des champs existants. Veillez à saisir le nom du champ exactement de la même manière qu’il apparaît dans votre répertoire, en respectant l’orthographe, l’espacement, la ponctuation et la capitalisation.
- Ne définissez pas de valeur. Cela permet d’extraire les données de la liste de contacts.
Supprimer des données intégrées
Dans cette section, nous allons découvrir plusieurs façons de supprimer des données intégrées. Veuillez porter une attention particulière aux avertissements associés à chacune des instructions suivantes.
Supprimer des champs de données intégrées
Vous pouvez supprimer des champs entiers de données intégrées dans le flux d’enquête. Cela signifie qu’il faut supprimer le champ lui-même et toutes les données qui lui sont associées.
Pour supprimer toutes les données intégrées dans un élément, cliquez sur Supprimer en bas à droite de l’élément.
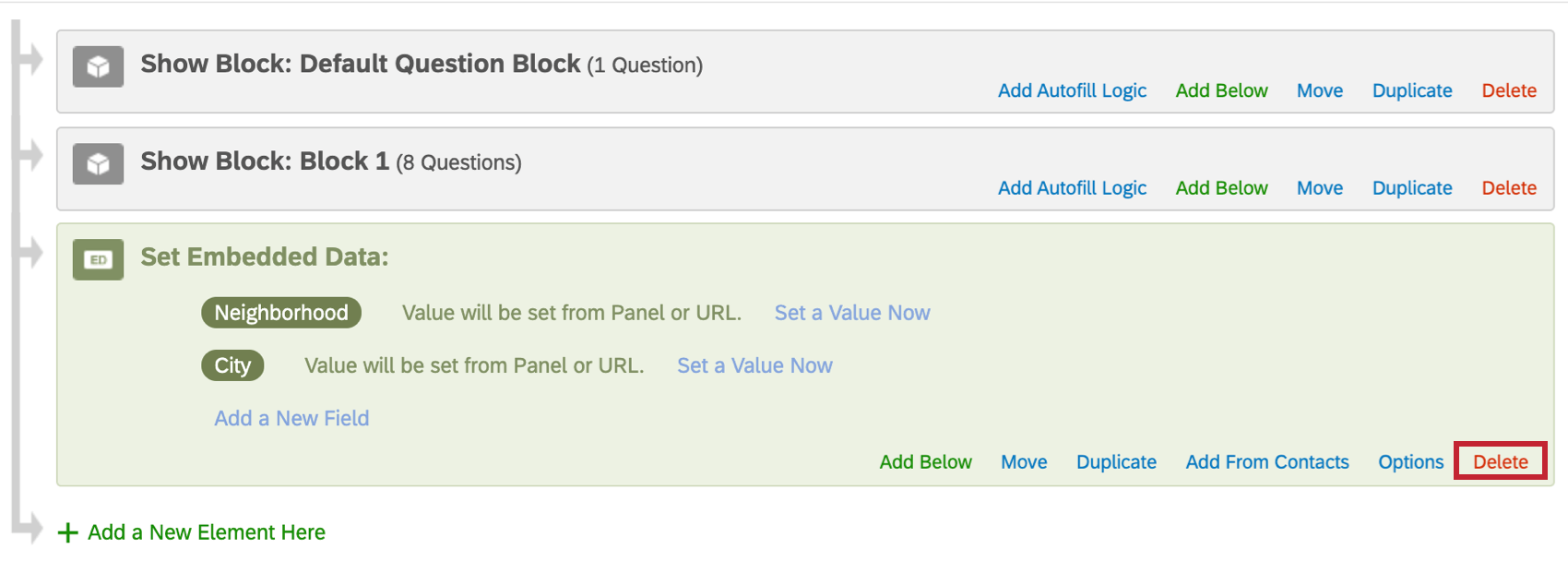
Vous pouvez également supprimer une zone d’un élément à la fois. Dans l’exemple ci-dessous, nous voulons supprimer Ville, mais pas Quartier.
- Cliquez sur le nom du champ que vous souhaitez supprimer.
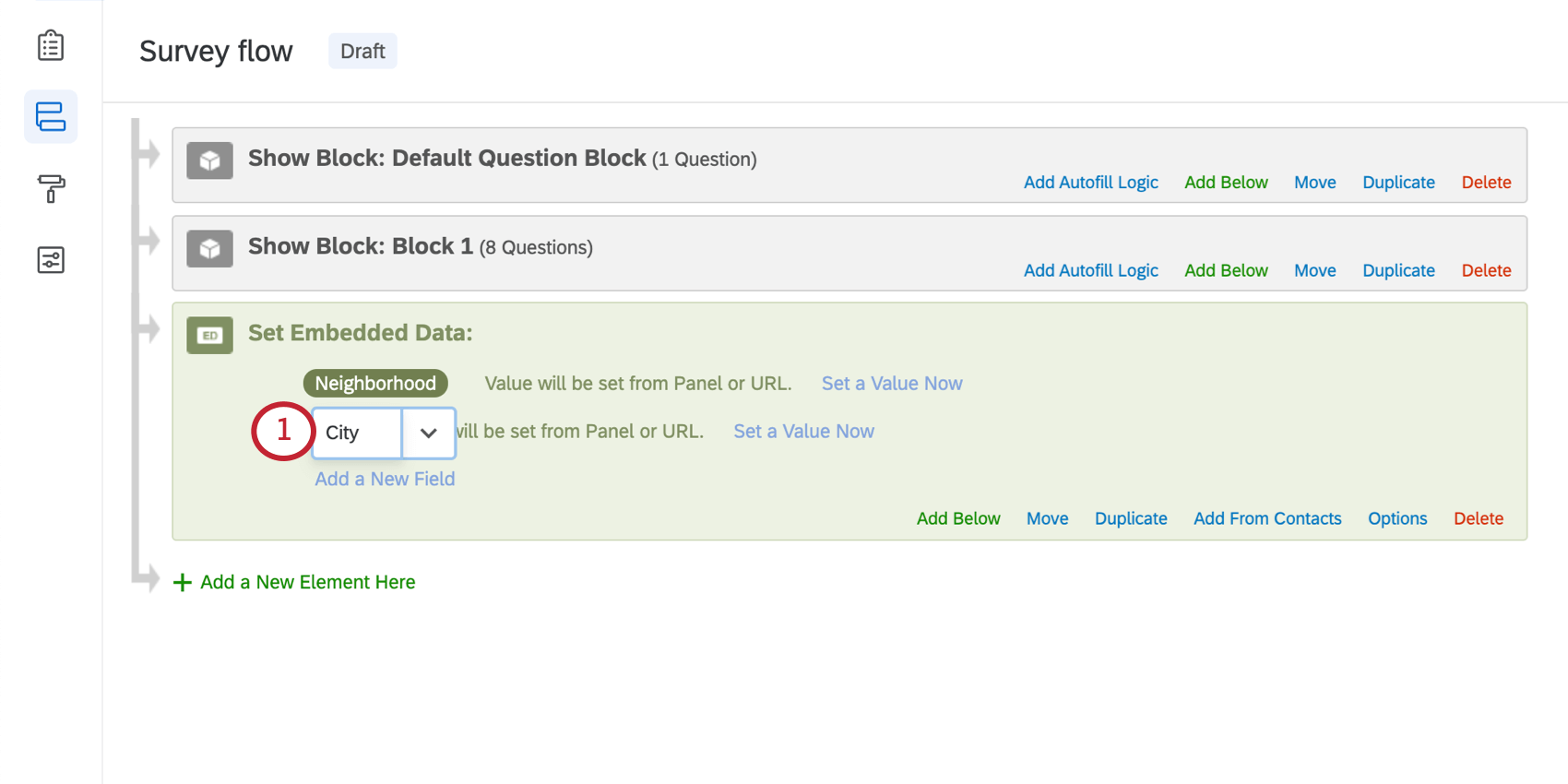
- Supprimez le nom du champ en cliquant sur la touche Supprimer ou Retour arrière de votre clavier. Ce champ doit devenir rouge s’il est entièrement vide.
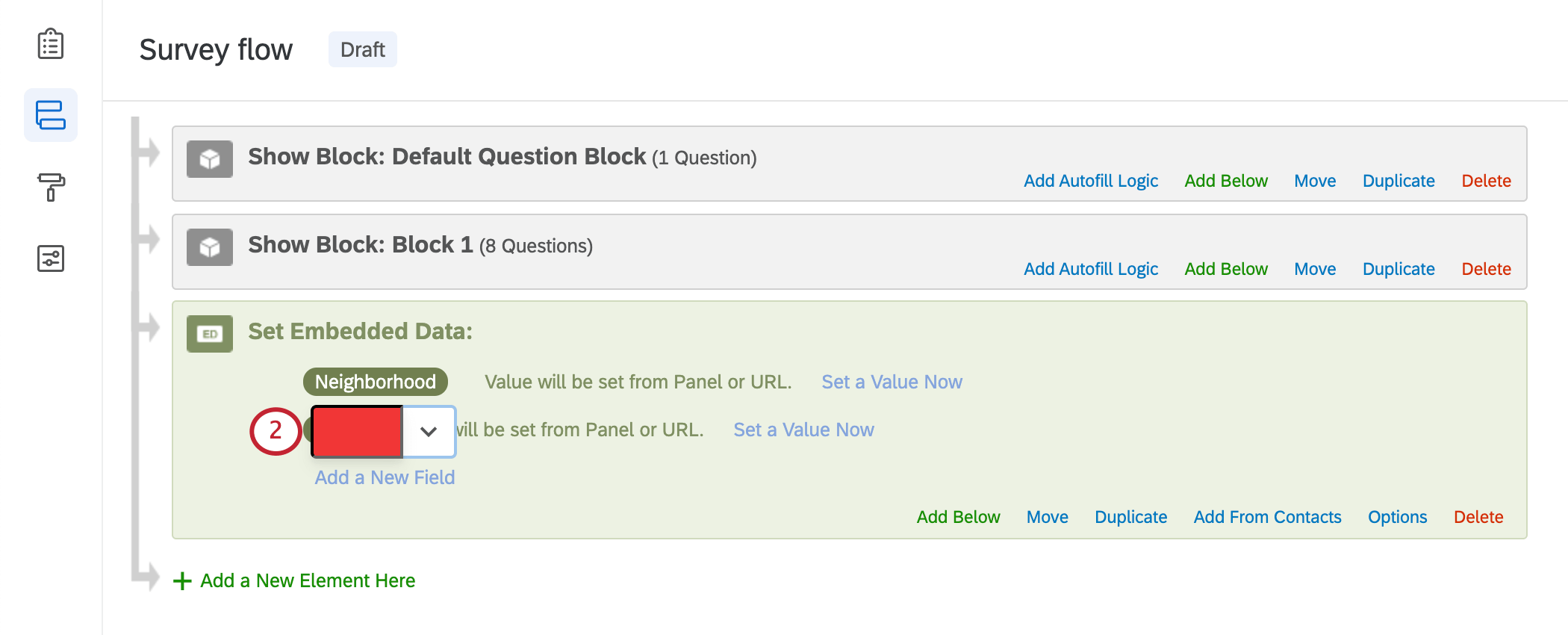
- Cliquez hors du champ.
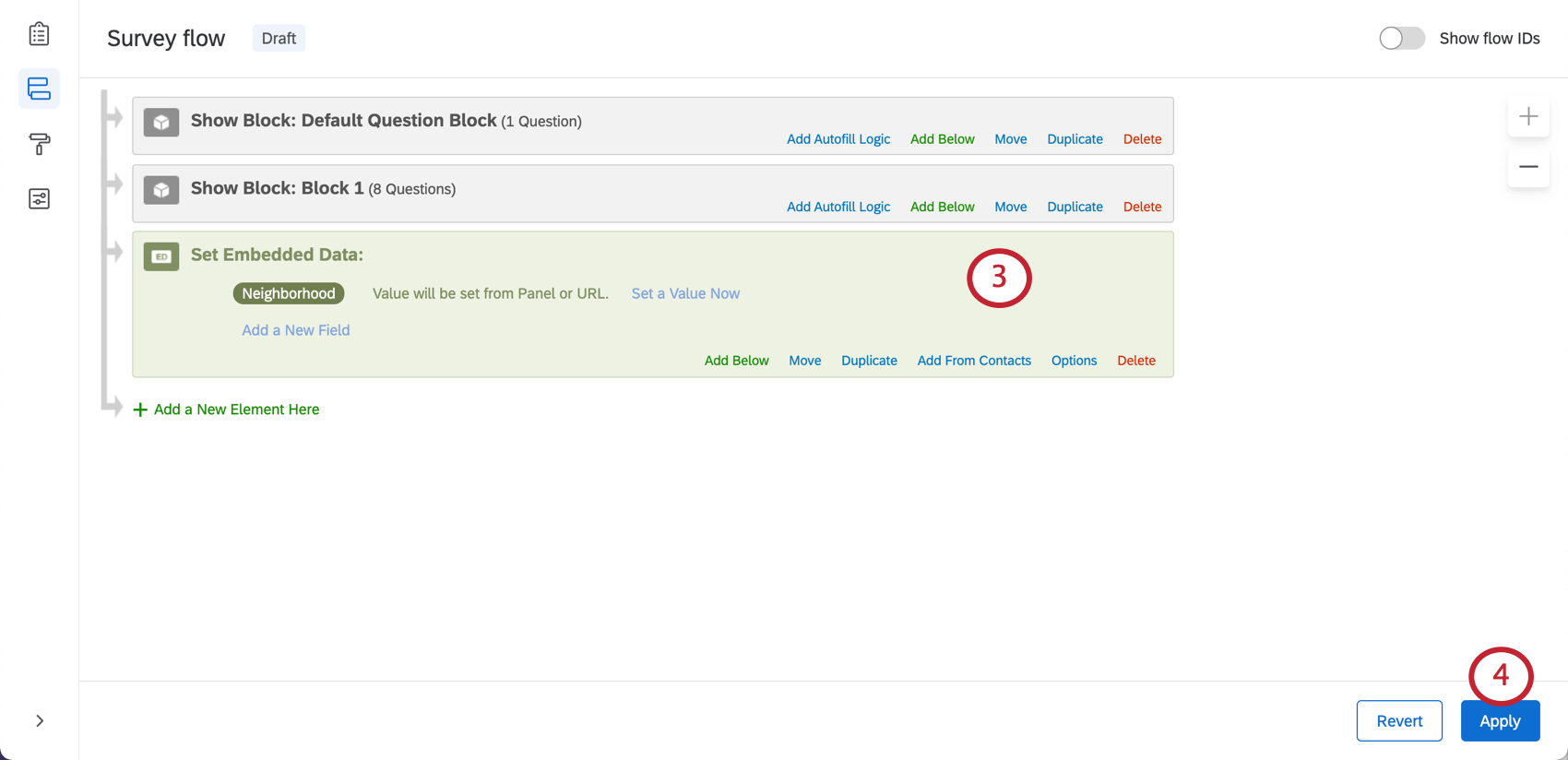
- Cliquez sur Appliquer).
Supprimer des données intégrées d’un répondant
Si vous devez supprimer la valeur des données intégrées d’une seule personne interrogée (ou la remplacer par une nouvelle valeur), vous devez modifier la réponse dans Données et analyse.
- Utilisez les filtres ou la navigation dans la page pour rechercher le répondant que vous voulez modifier.
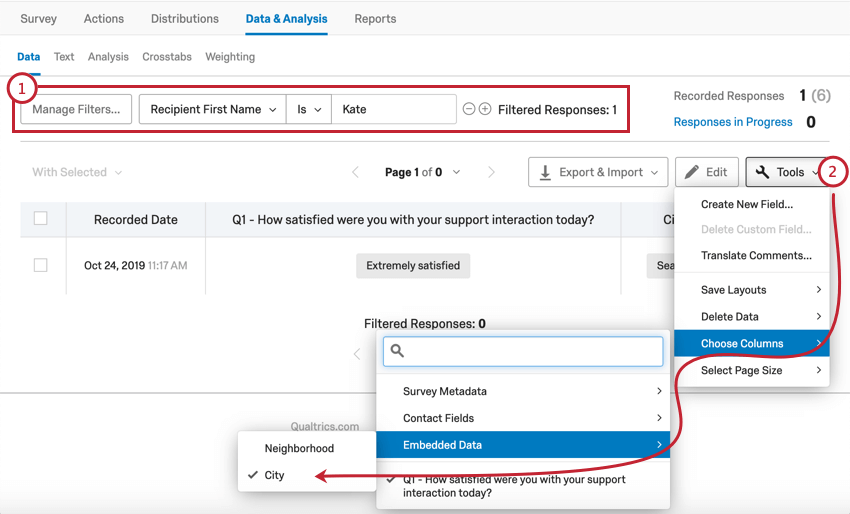
- Sélectionnez cette option pour afficher la colonne de données intégrées que vous devez modifier.
- Cliquez sur Modifier
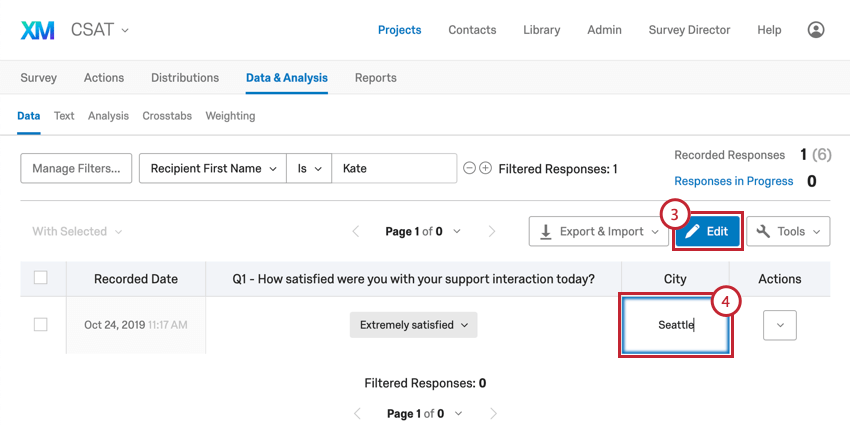
- Cliquez sur le champ pour effacer ou modifier la valeur de données intégrées.
Meilleures pratiques et dépannage des données intégrées
Attribuer un nom aux champs
- Les noms ne doivent jamais dépasser 200 caractères.
- Évitez d’utiliser des caractères inhabituels tels que les émoticônes, les points (.), les signes de dollar ($) et les hashtags (#) lorsque vous attribuez un nom à vos données intégrées.
- Lorsque vous vous référez au même champ, assurez-vous d’utiliser les mêmes orthographes, majuscules, espaces et caractères spéciaux dans Qualtrics. Par exemple, si vous créez la liste de contacts en utilisant Adresse principale comme données intégrées stockant l’adresse de vos contacts, n’utilisez pas AdresseAccueil ou simplement Adresse dans le flux d’enquête.
- Si vous prévoyez d’utiliser des chaînes de requête, supprimez les espaces dans les noms et les valeurs des données intégrées que vous utilisez, ou utilisez des traits de soulignement pour éviter de devoir encoder des espaces dans l’URL. Par exemple, « StoreID » et « Store_ID » peuvent être plus faciles à utiliser avec une chaîne de requête que « Store ID ».
Astuce : si vos noms ou valeurs de champs comportent des espaces, assurez-vous d’utiliser un encodeur d’URL comme celui-ci.
- Si votre liste de données intégrées est longue ou implique un système de dénomination complexe, conservez un document avec la liste de toutes vos données intégrées et leur utilisation. De cette façon, vous pouvez toujours vérifier l’orthographe, les majuscules et les espaces, en plus de l’objet du champ. Ces documents peuvent également vous aider, ainsi que vos collaborateurs et les agents du support client avec lesquels vous travaillez, à résoudre les problèmes en cas de questions.
- Ne nommez pas vos champs de la manière suivante :
- SID
- RID
- Auditable (signification : Vérifiable)
- Date de fin
- Adresse IP
- Date d’enregistrement
- Date de début
- Status (signification : statut)
Définir les valeurs
- Chaque valeur d’un champ de données intégrées ne doit jamais dépasser 20 Ko (20 000 octets). Le nombre d’octets dans un caractère donné dépend du caractère. Par exemple, les caractères en anglais font 1 octet, tandis que les caractères dans d’autres langues telles que le chinois ou l’hébreu peuvent occuper plusieurs octets par caractère. Si vous n’êtes pas sûr de cette limite, utilisez un compteur d’octets pour voir combien d’octets composent votre valeur de données intégrées.
- Si vous utilisez des champs de données intégrées, vous pouvez enregistrer les champs dans un élément de données intégrées du flux d’enquête, comme illustré ci-dessous. Toutefois, vous ne pouvez pas définir de valeurs pour ces champs, car la façon dont les répondants répondent à l’enquête déterminera les valeurs de ces champs.
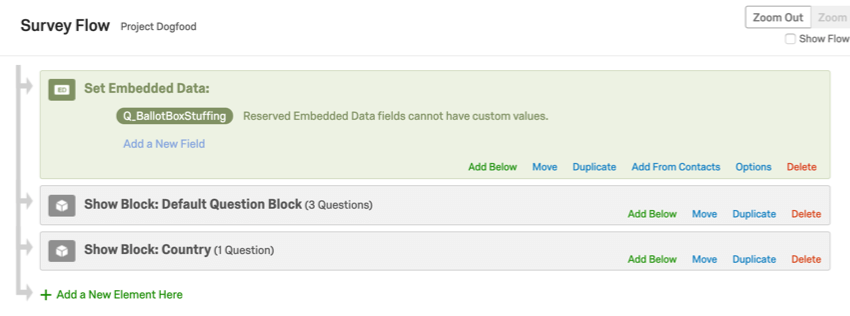
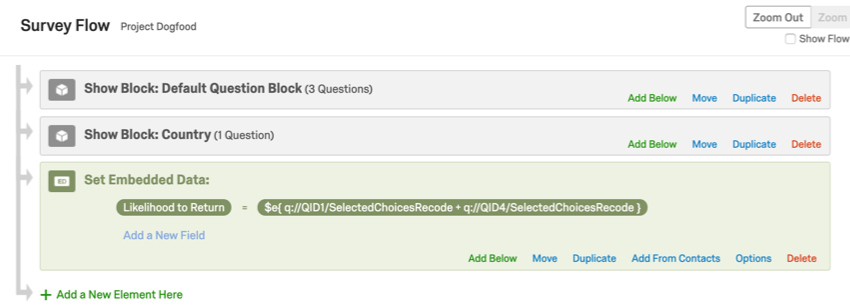
- Si vous utilisez des opérations mathématiques dans votre enquête, définissez-les dans un champ de données intégrées afin que les résultats soient enregistrés avec les données de votre enquête, comme ceci :
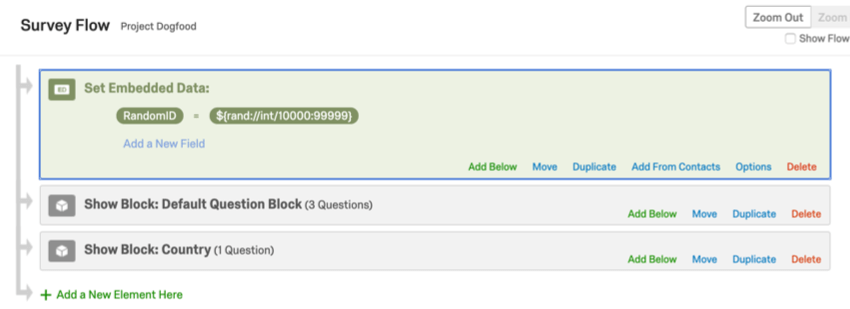
- Si vous utilisez du texte inséré pour présenter un nombre aléatoire à un répondant, définissez ce paramètre dans un champ de données intégrées afin que les résultats soient enregistrés avec vos données d’enquête. Consultez la page de support Attribuer des ID randomisés aux répondants.
Supposons que vous souhaitiez ajouter des valeurs pour suivre certains utilisateurs. C’est ce que l’on appelle un compteur. Les compteurs sont souvent utilisés lorsque vous avez de nombreuses branches auxquelles les répondants peuvent accéder. Pour compter le nombre total de branches par lesquelles passe un répondant, un compteur se trouve en dessous de chaque branche. Assurez-vous que tous les compteurs ont le même nom de champ pour que cette configuration fonctionne correctement. Si vous avez [nom du champ] = [nom du champ] + 1, et que cette valeur est définie plusieurs fois dans votre flux d’enquête à l’aide d’opérations mathématiques, votre valeur ne sera pas écrasée. Dans ce cas, le champ augmentera effectivement au cours de l’enquête.
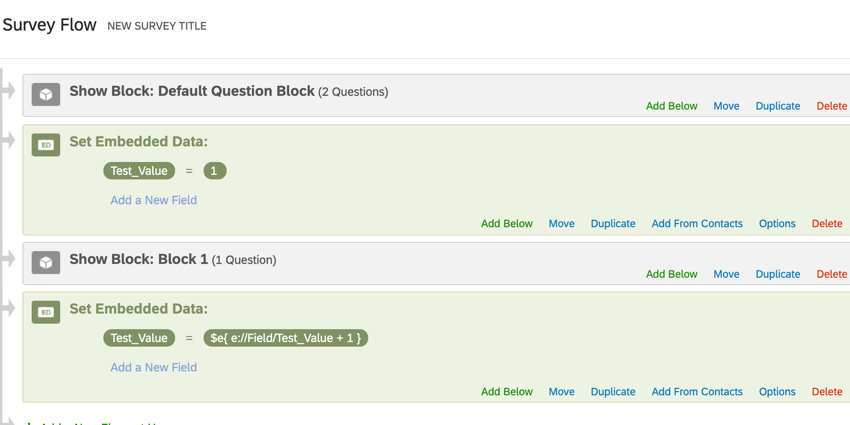
Dans cet exemple, “Valeur_test” sera égale à 2 lorsque la personne interrogée soumettra l’enquête parce que nous avons utilisé un compteur, l’opération mathématique de $e{ e:/Field/Test_Value + 1 }, pour incrémenter “Valeur_test” de 1.
Organiser les éléments dans le flux d’enquête
Vous arrive-t-il de vous demander où votre donnée intégrée est censée se trouver dans le flux d’enquête ? Voici quelques conseils :
- la valeur du champ de données intégrées dépend-elle de la réponse du répondant à certaines questions ? Assurez-vous que l’élément de données intégrées se trouve après le bloc qui contient ces questions.
- Définissez-vous des valeurs différentes pour vos données intégrées en fonction des différentes conditions de votre flux d’enquête ? Si c’est le cas, veillez à ce que les champs soient correctement indentés pour vous assurer que vos valeurs ne s’écraseront pas les unes les autres.
Exemple : par exemple, dans ce flux d’enquête, même si un répondant a un champ de données intégrées Snack initialement défini sur Bon, la valeur sera remplacée par Mauvais car les données intégrées secondaires ne sont pas imbriquées correctement dans la logique de branche.
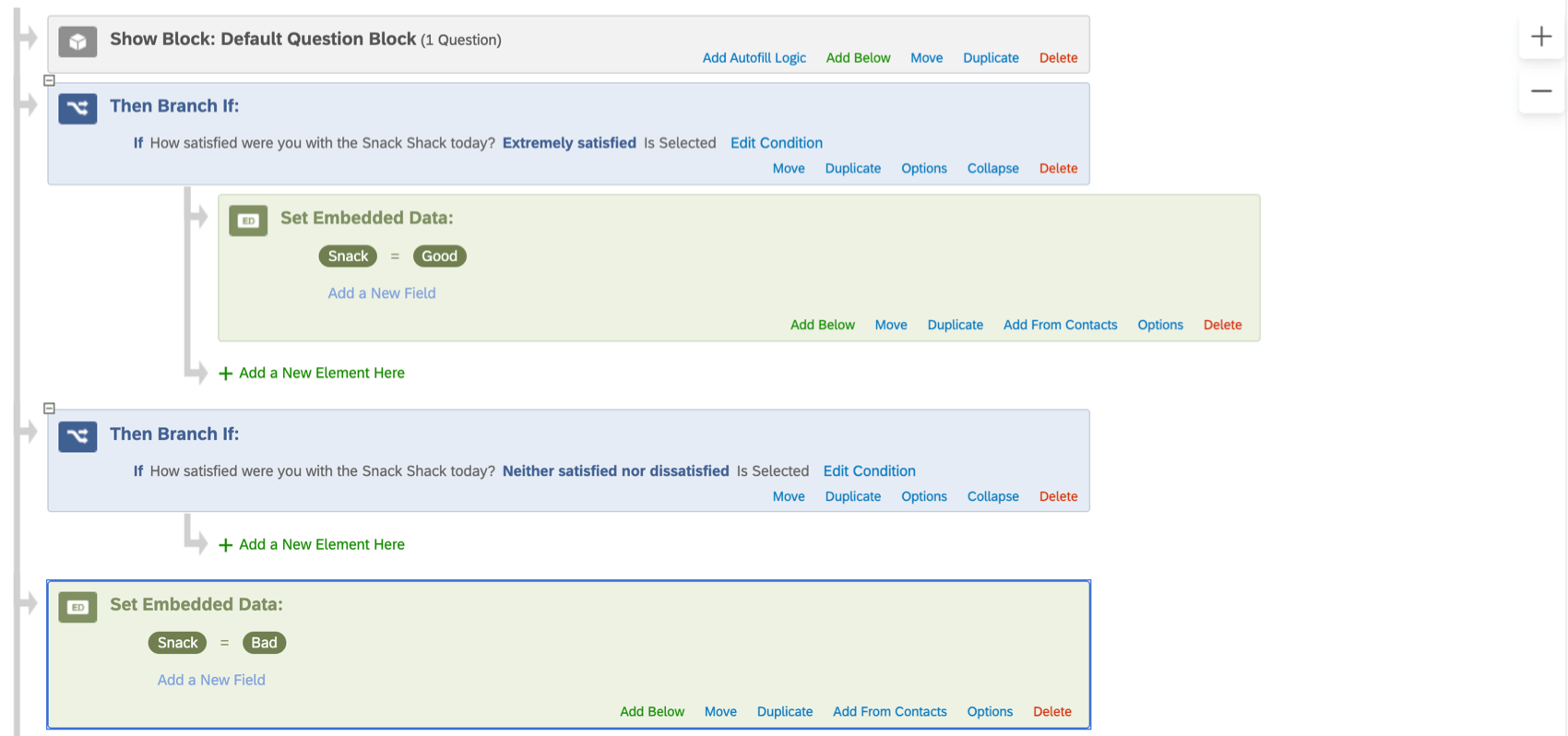
- La valeur des données intégrées change-t-elle de logique d’affichage ou de logique de branche dans l’enquête ? (En d’autres termes, le contenu de l’enquête du répondant dépend-il de la valeur de ces données intégrées ?) Assurez-vous que l’élément de données intégrées apparaît au-dessus des blocs où différents chemins existent.
Exemple:
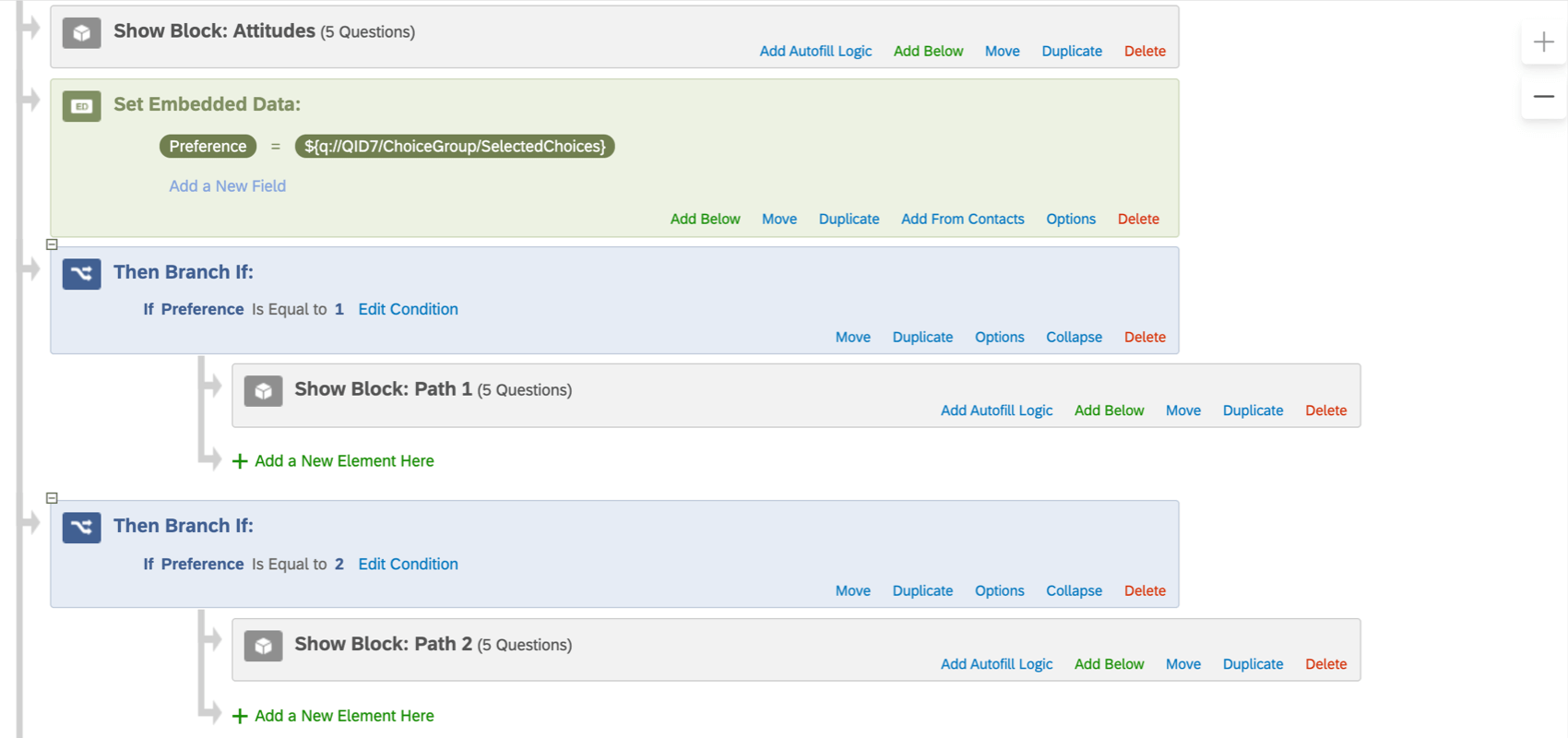
Dans cet exemple, le champ de données intégrées “Préférence” enregistre la réponse de la personne interrogée à une question. Nous utiliserons ensuite ce champ de données intégrées pour insérer le texte de la question dans l’ensemble de questions suivant, qui se trouvent dans le bloc « Contenu dépendant de la valeur des données intégrées du répondant ».
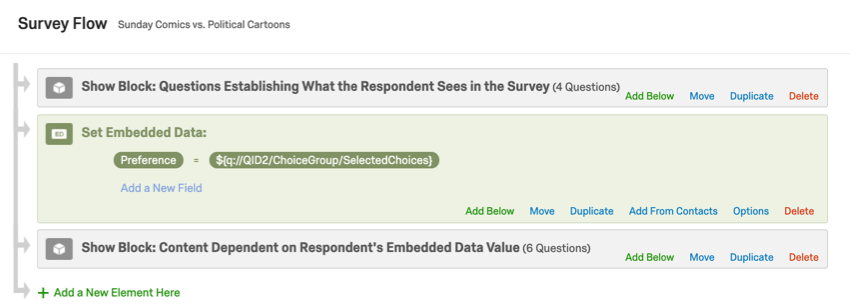
Exemple:
Dans cet exemple, le champ de données intégrées “Préférence” enregistre la réponse de la personne interrogée à une question. Selon la réponse du répondant, ce dernier est orienté vers différents parcours de branche de l’enquête.