-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Le migliori pratiche del programma BX
Informazioni sulle migliori pratiche del programma BX
I programmi BX vi permettono di condurre un assessment completo e continuo sullo stato di salute del vostro brand rispetto ai vostri principali concorrenti. Le Origine del SONDAGGIO creano i dati utilizzati per generare l’origine dati del brand tracker, un set di dati sovrapposti che rende più robusti gli strumenti analitici e il dashboard di BX. È importante programmare il sondaggio in modo specifico, affinché sia compatibile con la creazione di un’origine dati del SONDAGGIO.
Struttura del sondaggio
La maggior parte dei sondaggi BX segue la stessa struttura di base, progettata per fornire risposte affidabili e misurare le metriche chiave.
- Introduzione e screener: Identifica i consumatori rilevanti dei brand/prodotti della vostra categoria.
- Consapevolezza: Misura la prontezza con cui il vostro brand viene ricordato quando si parla della vostra categoria.
- Utilizzo: Misura la frequenza con cui gli intervistati utilizzano o acquistano ciascun brand, storicamente e di recente, e aiuta a identificare gli utenti del brand che hanno perso di recente e le potenziali barriere all’uso o all’acquisto.
- Barriere: Identifica le principali barriere all’acquisto di ciascun brand.
- Metriche di sintesi: Fornisce una misura olistica dell’esperienza dei clienti col brand.
- Immagine: Misura la percezione del brand nella mente del cliente.
- Comunicazione: Determina la notorietà degli annunci, che valuta la capacità del brand di accedere alle memorie pubblicitarie.
- Dati demografici: Identifica i dati demografici chiave dei rispondenti, utilizzati per filtrare i dati, se necessario.
Consiglio Q: I dati demografici possono essere utilizzati per garantire che il campione di intervistati sia rappresentativo della popolazione che si desidera studiare.
Si consiglia di seguire queste best practice quando si modificano il contenuto e la struttura del sondaggio.
- Usare tipi di domande standard (a selezione singola, a selezione multipla o a immissione di testo) ogni volta che è possibile. Avere un piano chiaro su come mappare i dati per qualsiasi altro tipo di domanda.
- Evitate le configurazioni in cui i rispondenti possono rispondere allo stesso contenitore di domande per contenuti diversi. Ad esempio, utilizzando una domanda per chiedere agli intervistati di fornire un contesto su un brand selezionato a caso.
- Considerate quali filtri volete utilizzare nella vostra dashboard e includete i modi per catturare queste informazioni. Ad esempio, se si desidera filtrare per fasce d’età, è necessario creare una variabile dati integrata con la fascia d’età.
- Considerate quali sono gli intervalli di date più importanti per i vostri rapporti. È comune creare un campo dati INTEGRATI “wave_date” per catturare le informazioni più rilevanti sul periodo di campionamento, al fine di filtrare o raggruppare in dashboard.
Consiglio Q: I periodi di campionamento possono non coincidere con i campi Data di registrazione o Data di fine, per cui il campo “wave_date” è utile per i rapporti. Ad esempio, la vostra ondata di aprile potrebbe dover includere alcuni rispondenti dell’inizio di maggio.
- Considerare le variabili personalizzate che potrebbero essere necessarie e impostarle utilizzando dati integrati.
Principi di programmazione
Per generare un’Origine dati Brand Tracker (BTDS) con il vostro programma, sono necessarie alcune considerazioni di programmazione aggiuntive:
- I brand devono essere inseriti nella lista delle scelte riutilizzabili.
- Il testo della domanda e della risposta per i brand deve corrispondere esattamente alla lista delle scelte riutilizzabili.
- Le domande del sondaggio relative al brand devono essere organizzate in blocchi paralleli.
Lista scelte riutilizzabili
L’elenco completo dei brand per l’intero sondaggio deve essere inserito come Lista delle scelte riutilizzabili. I brand presenti nel resto del sondaggio devono corrispondere a quelli inseriti nella Lista delle scelte riutilizzabili. Per ulteriori informazioni, consultare la pagina di supporto collegata.
Testo della domanda e della risposta
Per le domande ripetute per ogni brand (note anche come domande guidate dal brand), l’etichetta della domanda (ad esempio, “NPS_brandX”) e il testo della domanda (ad esempio, “Quanto è probabile che raccomandi [brand X] a un amico o a un collega?”) devono essere coerenti.
Per le domande con marchi come opzioni di risposta, assicurarsi di impostare il Nome variabile come marchio nella lista delle scelte riutilizzabili se il testo dell’ opzione di risposta è diverso dal nome del marchio (ad esempio, se c’è HTML per un’immagine o un testo aggiuntivo).
Blocchi di sondaggio in parallelo
Un blocco di sondaggio parallelo è quello in cui una serie di domande su un singolo brand viene raggruppata in un blocco di sondaggio e c’è un blocco di sondaggio per ogni brand. Il nome di ciascun blocco deve seguire lo stesso schema di denominazione, in modo che le domande al suo interno siano considerate parallele. QUALTRICS impila le domande in parallelo.
Accatastamento di dati integrati
Per impostazione predefinita, i campi dati integrati non vengono sovrapposti. Tuttavia, l’impilamento dei campi dati integrati è spesso necessario per le variabili personalizzate del marchio che calcolano e misurano i dati del brand.
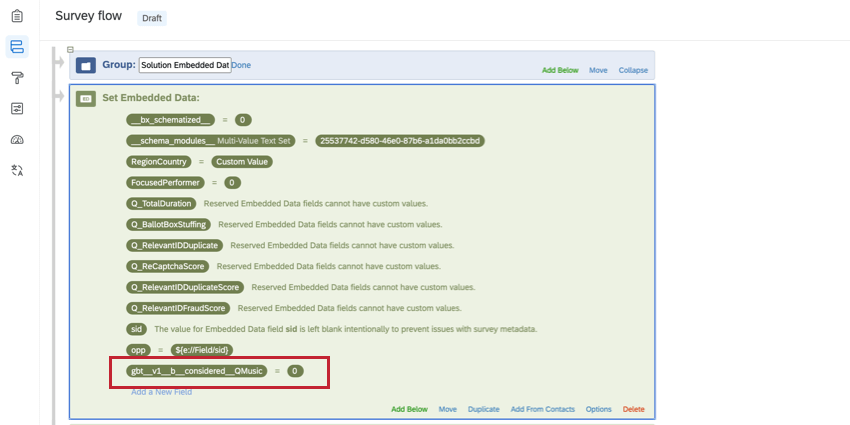
I campi dati integrati impilati devono essere aggiunti all’inizio del flusso del sondaggio con il valore “0” e la seguente convenzione di denominazione:
gbt__v1__[Tipo di pila]__[Nome della colonna]__[Brand]- Creare la variabile Dati integrati all’inizio del flusso del sondaggio.
- Aggiungere un elemento di Logica diramazione dopo la domanda da cui si vuole impostare il valore dei dati integrati.
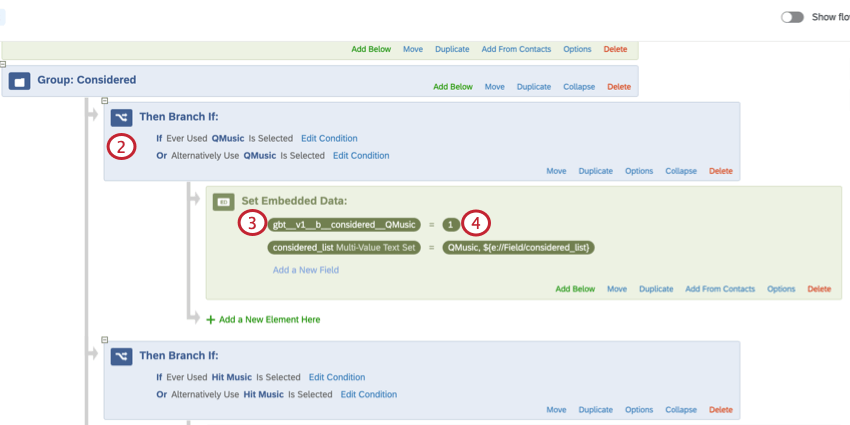
- Aggiungere un dato integrato all’interno di questa diramazione.
- Impostare la variabile Dati integrati uguale a 1.
- Assicurarsi di fare clic su Applica per salvare il flusso del sondaggio, quindi pubblicare il sondaggio.
Per ulteriori informazioni sulla creazione della variabile Dati integrati impilati, vedere le sezioni seguenti.
Tipo di pila
Il tipo di pila si riferisce al tipo di variabile a cui si fa riferimento per questi Dati integrati. Esistono due tipi di pila:
- Binario (b): la variabile ha solo due valori potenziali. Ad esempio, per la variabile “Considerazione”, un brand viene considerato (1) o non viene considerato (0).
- Normale (n): la variabile ha un numero illimitato di opzioni numeriche e contiene un valore calcolato o il valore che un rispondente ha selezionato per una domanda.
| Tipo di pila | Formato di esempio | Casi d’uso esemplificativi |
| b (binario) | gbt__v1__b__Considerazione__QMusica | Preferito, Considerazione calcolata |
| n (normale) | gbt__v1__n__Condivisione del portafoglio__QMusic | Equità del brand, quota di portafoglio |
Nome della colonna
Il nome della colonna è quello che si vuole far apparire come variabile dati integrata nel DATI INTEGRATI.
| Tipo di pila | Formato di esempio | Casi d’uso esemplificativi |
| b (binario) | gbt__v1__b__Considerazione__QMusica | Preferito, Considerazione calcolata |
| n (normale) | gbt__v1__n__Condivisionedel portafoglio__QMusic | Equità del brand, quota di portafoglio |
Nome del brand
Il nome del brand indica a quale marchio si riferiscono i dati della variabile.
| Tipo di pila | Formato di esempio | Casi d’uso esemplificativi |
| b (binario) | gbt__v1__b__Considerazione__QMusica | Preferito, Considerazione calcolata |
| n (normale) | gbt__v1__n__Condivisione del portafoglio__QMusic | Equità del brand, quota di portafoglio |
Consapevolezza non assistita autocodificata
La Consapevolezza non guidata misura quali brand vengono in mente quando si nomina una categoria specifica (ad esempio, “Quando pensa a [categoria], quale brand le viene in mente per primo?”). L’Autocoded Unaided Awareness (AUA) assicura che le variazioni di ortografia, capitalizzazione o acronimi comuni siano corrette in modo da poter raggruppare correttamente i dati. A tal fine, si crea un servizio web nel flusso del sondaggio.
Il servizio web AUA esamina i dati di testo aperto inseriti e li confronta con un dizionario dei brand creato dall’utente. Se la voce è simile al nome di un brand con un numero limitato di caratteri di scarto, il servizio web ricodifica la voce per farla corrispondere al Brand Dictionary.
Consiglio Q: Perché usare AUA invece di Text iQ?
- AUA si occupa di nomi e nomi propri, mentre Text IQ si concentra sui termini del linguaggio comune e sulle strutture grammaticali nelle immissioni di testo più lunghe.
- AUA ricodifica le risposte in tempo reale durante la sessione di sondaggio, quindi non è necessario attendere l’elaborazione per vedere i valori. Se necessario, è possibile utilizzare i risultati nella logica del sondaggio.
- È possibile impilare i risultati AUA per sfruttare i test di significatività e altre opzioni analitiche nelle analisi e nei dashboard di Qualtrics.
DETTAGLI AUA
- Solo le lingue supportate dalla piattaforma QUALTRICS sono compatibili con AUA. Le lingue personalizzate non sono supportate.
- Un dato brand può avere più voci incluse (ad esempio, “QUALTRrics” potrebbe includere le voci “Qualtrics”, “Qualtrics Software”, “Qualtrics Research” e “Qualtrics XM” per garantire che le variazioni di tutte queste voci siano ricodificate come “Qualtrics”).
- La lunghezza del nome del brand influenza la distanza tra l’ortografia dell’intervistato e la voce del Brand Dictionary.
- Le risposte di 3 o meno caratteri non possono subire deviazioni e devono corrispondere esattamente alla voce del Brand. Ad esempio, “Ivy” deve essere scritto esattamente come “Ivy”.
- Alle risposte di 4 caratteri è consentito uno scarto. Ad esempio, “QHub” accetterebbe varianti come “Qub” e “QHb”.
- Alle risposte di 5 caratteri sono consentite due deviazioni. Ad esempio, “Flanel” accetterebbe varianti come “Flannel” o “Flnl”.
- Alle risposte di oltre 6 caratteri sono consentite tre deviazioni. Ad esempio, “BeatDrop” accetterebbe varianti come “BeatD” o “BetDrp”.
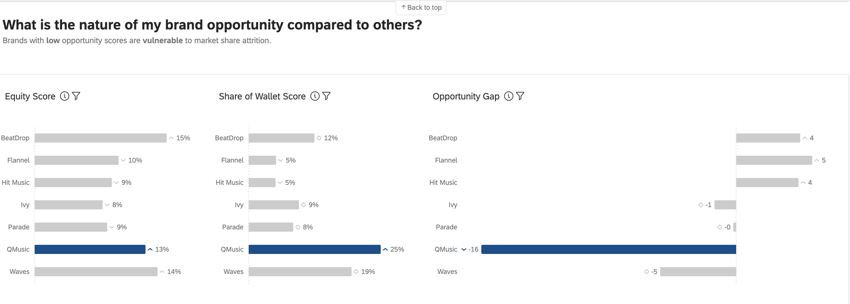
Equità del brand, quota di portafoglio e divario di opportunità
Le metriche di Brand Equità, Share of Wallet e Opportunity Gap sono utilizzate nelle Dashboard di BX per fornire informazioni avanzate sulle performance del brand.
EQUITÀ DEL BRAND
L’equità attitudinale del brand misura quale marchio i consumatori sceglierebbero se non ci fossero barriere all’acquisto o all’uso di un prodotto. Se considerata in modo aggregato, l’equità attitudinale del brand riflette la quota di mercato prevista per il vostro marchio. Si tratta di una percentuale che dovrebbe essere pari a 100 (ad esempio, il 75% dei consumatori acquisterebbe il mio brand se potesse, ma il 25% preferirebbe acquistare il marchio [x]).
Il suo approccio è semplice e richiede solo poche domande (proprietà, considerazione e valutazione del brand). Le valutazioni relative dei brand vengono trasformate in “ranghi” e quindi in “quote previste” Queste misure hanno una forte correlazione con i comportamenti.
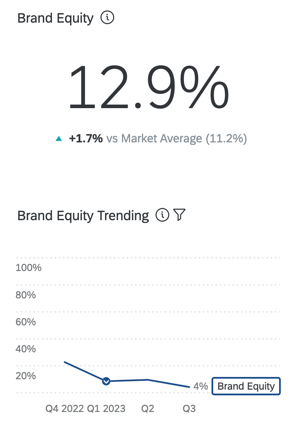
QUOTA DI PORTAFOGLIO O QUOTA DI MERCATO STIMATA
La share of wallet, nota anche come “quota di mercato stimata”, misura la percentuale di utilizzo recente degli intervistati attribuita a ciascun brand. In genere si tratta di una percentuale che dovrebbe essere pari a 100 (ad esempio, negli ultimi 6 mesi, il 75% dei miei acquisti di [categoria] sono stati effettuati con [x] brand e il 25% con [y] brand).
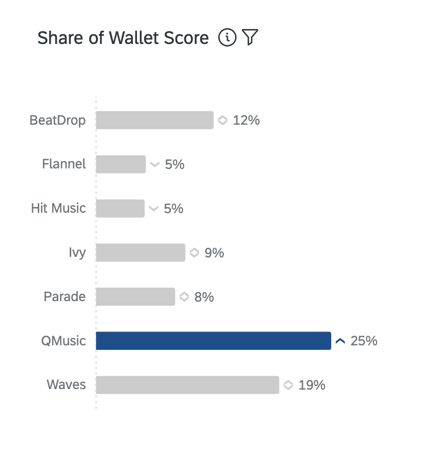
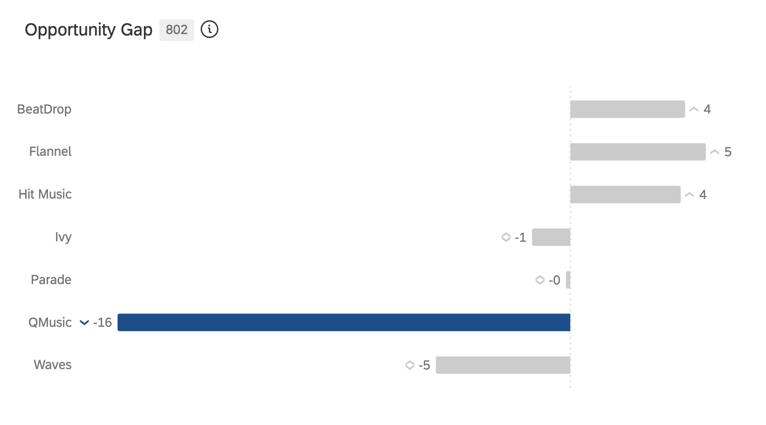
GAP DI OPPORTUNITÀ
L’Opportunity gap è la differenza tra l’equità attitudinale del brand e la quota di mercato stimata; in altre parole, il divario tra il desiderio del brand e l’effettivo comportamento di acquisto. L’opportunità esiste quando l’equità è maggiore della quota (punteggi positivi) e la vulnerabilità è presente quando l’equità è inferiore alla quota (punteggi negativi).