Mejores prácticas del programa BX
Contenidos de la página
Acerca de las mejores prácticas del programa BX
Programas BX Le permite realizar una valoración integral y continua de la salud de su marca/organización en comparación con sus principales competidores. Las encuestas BX crean los datos que se utilizan para generar el fuente de datos del rastreador de marca/organización, un conjunto de datos apilados que hace que las herramientas analíticas y el Tablero de BX sean más sólidos. Es importante programar su encuesta específicamente para que sea compatible con la creación de una fuente de datos de seguimiento de marca/organización .
Consejo Q: El Asistente de configuración lo guía a través de la creación de su programa BX y le proporciona una plantilla para la encuesta. Si personaliza la encuesta más allá de lo sugerido, tenga en cuenta que los campos de la encuesta son obligatorios para la BTDS Es posible que no se genere automáticamente.
Atención: Los programas BX son mucho más grandes y complejos que los proyectos de encuesta estándar. Recomendamos utilizar el enlace de vista previa para garantizar que todos los elementos funcionen correctamente. Además, recomendamos realizar un “lanzamiento suave” enviando el programa a una población pequeña (por ejemplo, el 10% del tamaño de su muestra ) y luego revisar sus datos.
Consejo Q: Los programas BX generalmente los lleva a cabo el equipo de implementaciones de Qualtrics o un socio de implementación externo. Si tiene preguntas sobre su implementación, comuníquese con su Gerente de éxito técnico.
Estructura de la Encuesta
Advertencia: Si está utilizando un estudio de BX creado por el equipo de implementación de Qualtrics o un equipo de implementación de terceros, no realice ningún cambio no autorizado en el generador de encuestas o el flujo de la encuesta, ya que esto puede invalidar los datos recopilados.
Mayoría Encuestas BX seguir la misma estructura básica diseñada para proporcionar respuestas confiables y medir métricas clave.
Consejo Q: Los datos demográficos se pueden utilizar para garantizar que la muestra de encuestados sea representativa de la población que desea estudiar.
Le recomendamos seguir estas prácticas recomendadas al editar el contenido y la estructura de su encuesta .
- Utilice el estándar tipos de preguntas (selección única, selección múltiple o entrada de texto) siempre que sea posible. Tenga un plan claro sobre cómo va a mapear los datos para cualquier otro tipo de preguntas.
- Evite configuraciones en las que los encuestados puedan responder el mismo contenedor de preguntas para diferentes contenidos. Por ejemplo, utilizar una pregunta para pedir a los encuestados que proporcionen contexto sobre una marca/organización seleccionada al azar.
- Considere qué filtros le gustaría usar en su Tablero e incluya formas de capturar esa información. Por ejemplo, si necesita filtro por grupos de edad, asegúrese de crear una variable de datos embebidos por grupos de edad.
- Considere qué rangos de fechas serán más relevantes en sus informes. Es común crear un campo de datos embebidos “wave_date” para capturar la información del período de campo más relevante con el fin de filtro o agrupar en los paneles. Consejo Q: Es posible que los períodos de campo no se alineen con los campos Fecha de registro o Fecha de finalización, por lo que el campo “wave_date” es útil para los informes. Por ejemplo, es posible que su ola de abril deba incluir algunos encuestados de principios de mayo.

- Considere cualquier variable personalizada que pueda ser necesaria y configúrela utilizando datos embebidos.
Consejo Q: Te recomendamos Agrupamiento de elementos en el flujo de la encuesta para mantener la lógica organizada y facilitar la resolución de problemas.
Principios de programación
Para generar una Fuente de datos de Marca/organización Tracker (BTDS) con su programa, se requieren ciertas consideraciones de programación adicionales:
Lista de opciones reutilizables
La lista completa de marca/organización para toda la encuesta debe ingresarse como Lista de Opción reutilizables. Los nombres de marca/organización que aparecen en el rest de la encuesta deben coincidir exactamente con los nombres ingresados en la Lista de Opción reutilizables. Para obtener más información, consulte la página de soporte vinculada.
Consejo Q: Opciones como “Otro”, “NA” o “Ninguno” no deben incluirse en la lista de opción reutilizables, pero pueden incluirse en las preguntas reales de la encuesta .
Atención: Las Marca/organización no pueden exceder los 35 caracteres.
Texto de preguntas y respuestas
Para las preguntas que se repiten para cada marca/organización (también conocidas como preguntas dirigidas por la marca), la etiqueta de la pregunta (por ejemplo, “NPS_brandX”) y el texto de la pregunta (por ejemplo, “¿Qué probabilidades hay de que recomiende [marca/organización X] a un amigo o colega?”) deben ser coherentes.
Para preguntas con marcas como opciones de respuesta, asegúrese de configurar la Nombre de la variable como la marca/organización en la lista de opción reutilizables si el texto de opción de respuesta es diferente del nombre de la marca/organización (por ejemplo, si hay HTML para una imagen o texto adicional).
Bloques de Encuesta paralelo
Un Bloque de Encuesta paralelo es cuando una serie de preguntas sobre una sola marca/organización se agrupan en un bloque de encuesta , y hay un bloque de encuesta para cada marca/organización. Cada nombre de bloque debe seguir el mismo patrón de nombres, lo que hará que las preguntas dentro de ellos se consideren paralelas. Qualtrics apilará preguntas paralelas.
Ejemplo: Digamos que quieres crear bloques que pregunten sobre las barreras a la hora de comprar marcas. Si nombra cada bloque “Barreras – [Nombre de la Marca/organización ]” (por ejemplo, “Barreras – El mejor desayuno”, “Barreras – Cereal saludable”), el algoritmo de la máquina considerará estos bloques paralelos y apilará las preguntas juntas. Si los bloques tienen diferentes convenciones de nombres (por ejemplo, “Barreras: el mejor desayuno”, “Barreras: cereales saludables (niños)”), el algoritmo de la máquina no Considere los bloques paralelos y no los apile.
Apilamiento de datos integrados
Por defecto, campos de datos embebidos No se apilarán. Sin embargo, a menudo es necesario apilar campos de datos embebidos para las variables de marca/organización personalizadas que calculan y miden datos de marca/organización .
Los campos de datos embebidos apilados deben agregarse en la parte superior de la flujo de la encuesta con el valor “0” y la siguiente convención de nombres:
gbt__v1__[Tipo de pila]__[Nombre de columna]__[Nombre de Marca/organización ] Ejemplo: Es posible que desee definir “consideración” como si un encuestado alguna vez usó la marca/organización o si la usaría si su marca preferida no estuviera disponible. La creación de una variable de datos embebidos apilada le permite combinar ambas condiciones en un campo que puede usar en los filtros y widgets de su Tablero .
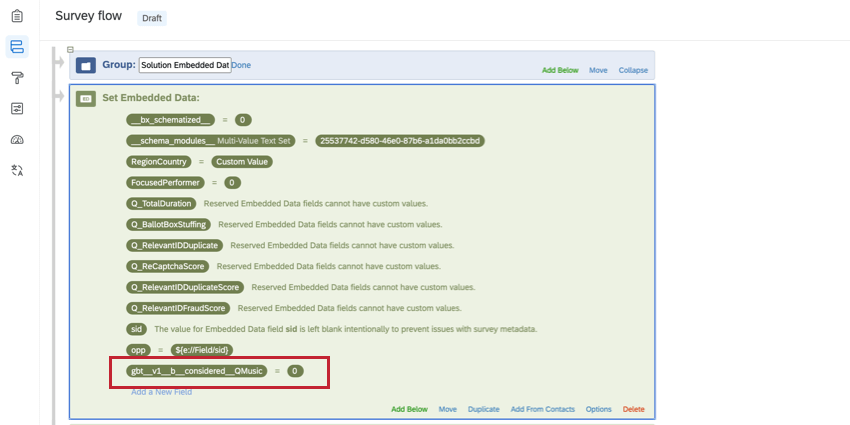
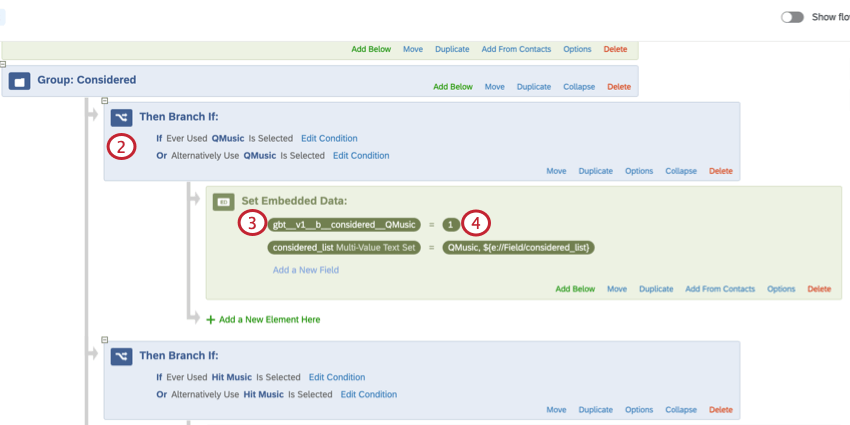
Consulte las secciones a continuación para obtener más información sobre cómo crear su variable de datos embebidos apilada.
Tipo de pila
El tipo de pila se refiere al tipo de variable a la que se hace referencia para estos datos integrados. Hay dos tipos de pila:
- Binario (b):La variable solo tiene dos valores potenciales. Por ejemplo, para la variable “Consideración”, una marca/organización se considera (1) o no se considera (0).
- Normal (n): La variable tiene un número ilimitado de opciones numéricas y contiene un valor calculado o el valor que el encuestado ha seleccionado para una pregunta.
| Tipo de pila | Formato de ejemplo | Ejemplos de casos de uso |
|---|---|---|
| b (binario) | gbt__v1__b__Consideración__QMusic | Favorito, Consideración Computada |
| n (normal) | gbt__v1__norte__Parte de la cartera__QMusic | Valor de Marca/organización , participación en la cartera |
Nombre de columna
El nombre de la columna es lo que desea que aparezca como variable de datos embebidos en el BTDS.
| Tipo de pila | Formato de ejemplo | Ejemplos de casos de uso |
|---|---|---|
| b (binario) | gbt__v1__b__Consideración__QMúsica | Favorito, Consideración Computada |
| n (normal) | gbt__v1__n__Participación en la cartera__QMúsica | Valor de Marca/organización , participación en la cartera |
Nombre de la marca
El nombre de la marca/organización indica a qué marca/organización se refieren los datos de la variable.
Atención: Los nombres de Marca/organización deben coincidir con la marca/organización correspondiente en el lista de opción reutilizable. Si los nombres de las marca/organización no coinciden completamente, los datos no se acumularán correctamente. Esto incluye caracteres especiales como espacios, apóstrofos, guiones, etc.
| Tipo de pila | Formato de ejemplo | Ejemplos de casos de uso |
|---|---|---|
| b (binario) | gbt__v1__b__Consideración__Música Q | Favorito, Consideración Computada |
| n (normal) | gbt__v1__n__Participación en la billetera__Música Q | Valor de Marca/organización , participación en la cartera |
Conciencia autocodificada sin ayuda
El conocimiento no asistida mide qué marcas vienen a la mente cuando mencionas una categoría específica (por ejemplo, “Cuando piensas en [categoría], ¿qué marca/organización te viene a la mente primero?”). La conciencia autocodificada sin ayuda (AUA) garantiza que se corrijan las variaciones en la ortografía, las mayúsculas o las siglas comunes para que podamos agrupar los datos correctamente. Esto se hace creando un Servicio web en el flujo de la encuesta.
Consejo Q: Si está interesado en configurar Autocoded Unaided Awareness, comuníquese con su socio de implementación.
El servicio web de AUA analiza los datos de texto abiertos ingresados y los compara con un Diccionario de Marca/organización que usted crea. Si la entrada es similar a una marca/organización con una pequeña diferencia de caracteres, el servicio web recodifica la entrada para que coincida con el Diccionario de Marca/organización .
Ejemplo: Digamos que tenemos una lista de marca/organización que contiene “ Qualtrics”. Con AUA habilitado, cualquier variación de Qualtrics (por ejemplo, “Quatrlics”) se registrará como “Qualtrics”. Sin embargo, si un encuestado ingresó “QXM”, esto no se incluiría ya que no es una variación de “Qualtrics”.
Consejo Q: ¿Por qué utilizar AUA en lugar de Text iQ?
- AUA se ocupa de nombres y sustantivos propios, mientras que Text iQ se centra en términos lingüísticos comunes y estructuras gramaticales en entradas de texto más largas.
- AUA recodifica las respuestas de texto en tiempo real durante la sesión de encuesta, por lo que no es necesario esperar ningún procesamiento para ver los valores. También puede utilizar los resultados en la lógica de la encuesta , si es necesario.
- Puede acumular resultados de AUA para aprovechar las pruebas de significancia y otras opciones analíticas en los análisis y paneles de Qualtrics.
DETALLES DE LA AUA
- Solo Idiomas admitidos por la plataforma Qualtrics son compatibles con AUA. No se admiten idiomas personalizados.
- Una marca/organización determinada puede tener varias entradas incluidas (por ejemplo, “Qualtrics” podría incluir entradas para “Qualtrics”, “Qualtrics Software”, “Qualtrics Research” y “Qualtrics XM” para garantizar que las variaciones de todas estas se registren simplemente como “Qualtrics”).
- La longitud del nombre de la marca/organización influye en qué tan lejos puede estar la ortografía del encuestado de una entrada de marca/organización en el Diccionario de Marca/organización .
- Las Respuestas que tengan 3 caracteres o menos no podrán presentar desviaciones y deben coincidir exactamente con la entrada de la Marca/organización . Por ejemplo, “Ivy” tendría que escribirse exactamente como “Ivy”.
- A las Respuestas de 4 caracteres se les permite una desviación. Por ejemplo, “QHub” aceptaría variaciones como “Qub” y “QHb”.
- Las Respuestas de 5 caracteres permiten dos desviaciones. Por ejemplo, “Flanel” aceptaría variaciones como “Flannel” o “Flnl”.
- Las Respuestas de 6 o más caracteres pueden tener tres desviaciones. Por ejemplo, “BeatDrop” aceptaría variaciones como “BeatD” o “BetDrp”.
Consejo Q: Si desea revisar o actualizar su Diccionario de Marca/organización , trabaje con su socio de implementación.
Valor de Marca/organización , participación en la cartera y brecha de oportunidades
Consejo Q: Si está interesado en configurar análisis de valor de Marca/organización , participación en la billetera o brecha de oportunidad, comuníquese con su socio de implementación.
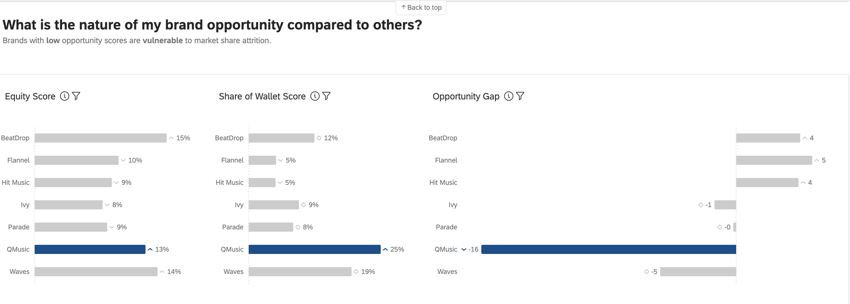
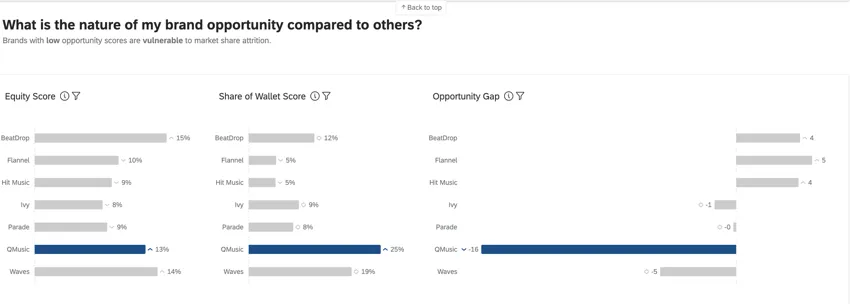
Las métricas de valor de Marca/organización , participación en la cartera y brecha de oportunidad se utilizan en Paneles de control de BX Proporcionar información avanzada sobre el rendimiento de la marca/organización .
{kind=link}
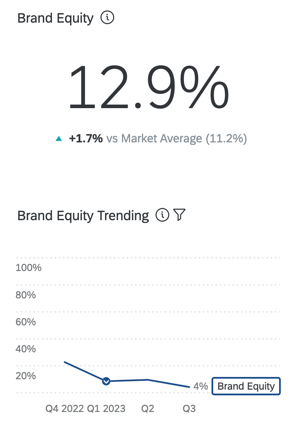
VALOR DE MARCA/ORGANIZACIÓN
El valor actitudinal de Marca/organización mide qué marca/organización elegirían los consumidores si no hubiera barreras para comprar o usar un producto. Cuando se considera en conjunto, el valor actitudinal de la marca/organización refleja la participación de mercado esperada de su marca/organización. Este es un porcentaje que debe sumar 100 (por ejemplo, el 75% de los consumidores comprarían mi marca/organización si pudieran, pero el 25% preferiría comprar la marca/organización[x]).
Su enfoque es simple y sólo requiere unas pocas preguntas (propiedad, consideración y calificación de marca/organización ). Las calificaciones relativas de marca/organización se transforman en “rangos” y luego en “cuota prevista”. Estas medidas tienen una fuerte correlación con los comportamientos.
{kind=link}
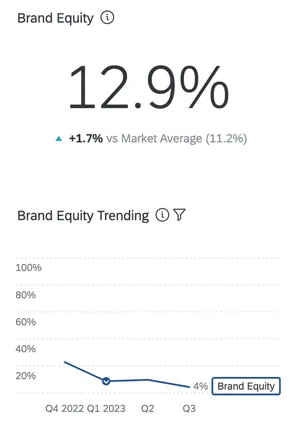
Consejo Q: El valor actitudinal de la Marca/organización se calcula en una encuesta BX mediante la creación de una Servicio web en el flujo de la encuesta.
Consejo Q: Existen muchas conceptualizaciones del valor de marca/organización , y el enfoque de Qualtrics se denomina valor actitudinal de marca/organización . Esta conceptualización está disponible en el dominio público y ha sido ampliamente validada.
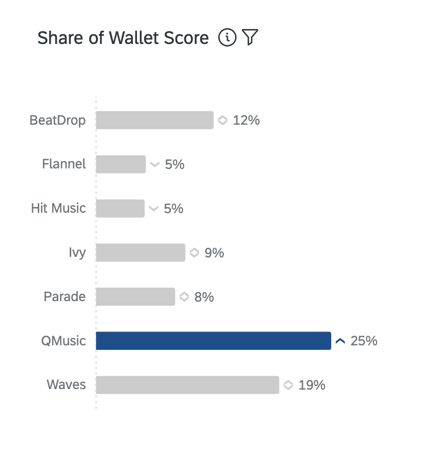
PARTICIPACIÓN DE CARTERA O PARTICIPACIÓN DE MERCADO ESTIMADA
La participación en la billetera, también conocida como “cuota de mercado estimada”, mide qué porcentaje del uso reciente de los encuestados se atribuye a cada marca/organización. Generalmente, este es un porcentaje que debe sumar 100 (por ejemplo, en los últimos 6 meses, el 75 % de mis compras de [categoría] fueron con la marca/organización [x] y el 25 % con la marca/organización[y]).
{kind=link}
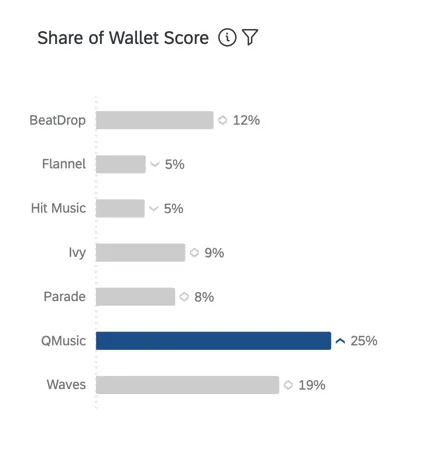
Consejo Q: La participación en la billetera se calcula en una encuesta de BX mediante la creación de una Operación matemática en el flujo de la encuesta.
BRECHA DE OPORTUNIDADES
La brecha de oportunidad es la diferencia entre el valor actitudinal de su marca/organización y su participación de mercado estimada; en otras palabras, la brecha entre el deseo por su marca/organización y el comportamiento de compra real. Existe oportunidad cuando el capital es mayor que la participación (puntajes positivos) y existe vulnerabilidad cuando el capital es menor que la participación (puntajes negativos).
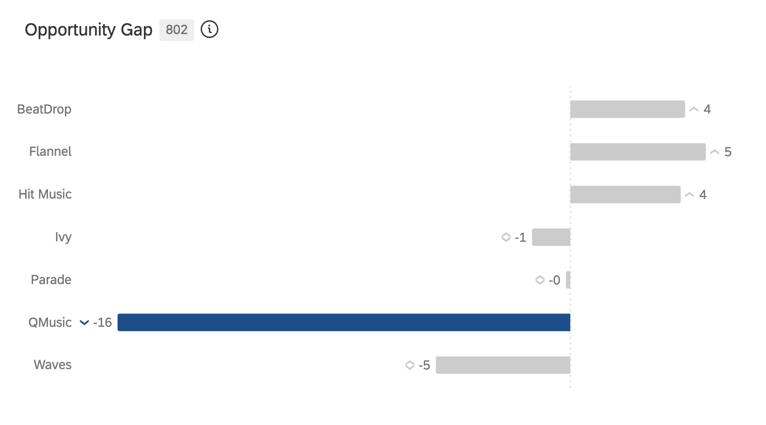{kind=link}
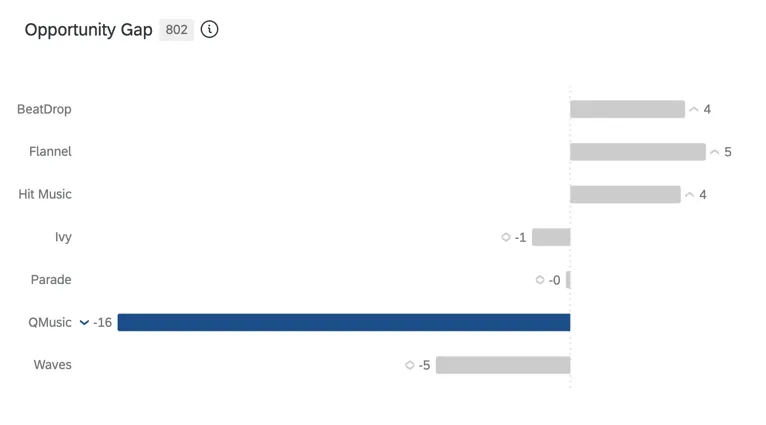
Consejo Q: La brecha de oportunidad se calcula en una encuesta BX creando una Operación matemática en el flujo de la encuesta.
¡Genial! ¡Gracias por tus comentarios!
¡Gracias por tus comentarios!