Best Practices für BX-Programm
Was finden Sie hier?
Best Practices für das BX-Programm
BX-Programme Mit können Sie eine umfassende, kontinuierliche Bewertung der Gesundheit Ihrer Instanz im Vergleich zu Ihren wichtigsten Wettbewerbern durchführen. Die Umfragen von BX erstellen die Datenquelle für den Brand Tracker, einen gestapelten Datensatz, der die BX-Analyse-Tools und das Dashboard robuster macht. It ist es wichtig, Ihre Umfrage so zu programmieren, dass sie mit der Erstellung einer Datenquelle für den Marken-Tracker kompatibel ist.
Tipp: Der Setup-Assistent führt Sie durch die Erstellung Ihres BX-Programms und stellt eine Vorlage für die Umfrage bereit. Wenn Sie die Umfrage über die vorgeschlagenen Werte hinaus anpassen, beachten Sie, dass Umfrage für die BTDS darf nicht automatisch generiert werden.
Achtung: ! BX-Programme sind wesentlich umfangreicher und komplexer als normale Umfrage-Projekte. Wir empfehlen die Verwendung der Vorschau-Link um sicherzustellen, dass alle Elemente ordnungsgemäß funktionieren. Darüber hinaus empfehlen wir, einen „Soft Launch“ durchzuführen, indem Sie das Programm an eine kleine Population senden (z. B. 10 % Ihrer Stichprobe) und dann Ihre Daten überprüfen.
TIPP: BX-Programme werden in der Regel vom Qualtrics-Implementierungsteam oder einem externen Implementierungspartner durchgeführt. Wenn Sie Fragen zu Ihrer Implementierung haben, wenden Sie sich bitte an Ihre Technical Success Manager:IN.
Umfrage
Warnung: Wenn Sie eine BX-Studie verwenden, die vom Qualtrics oder einem Implementierungsteam eines Drittanbieters erstellt wurde, nehmen Sie keine unberechtigten Änderungen am vor. Umfragen-Builder oder die Umfragenverlauf, da dies die gesammelten Daten invalidieren kann.
Meiste BX-Umfragen folgen derselben Grundstruktur, die für zuverlässige Antworten und Messgrößen entwickelt wurde.
Tipp: Demografiedaten können verwendet werden, um sicherzustellen, dass die Stichprobe der Befragten repräsentativ für die Population ist, die Sie untersuchen möchten.
Wir empfehlen, diese Best Practices zu befolgen, wenn Sie Ihre Umfrage und -struktur bearbeiten.
- Standard verwenden Fragetypen (Einfachauswahl, Mehrfachauswahl oder Texteingabe), wenn möglich. Verschaffen Sie sich einen klaren Plan, wie Sie die Daten für andere Arten von Fragen zuordnen.
- Vermeiden Sie Setups, bei denen Umfrageteilnehmer denselben Fragencontainer für verschiedene Inhalte beantworten können. Beispiel: Verwenden einer Frage, um Umfrageteilnehmer zu bitten, Kontext für eine zufällig ausgewählte Instanz bereitzustellen.
- Überlegen Sie, welche Filter Sie auf Ihrem Dashboard verwenden möchten, und fügen Sie Möglichkeiten zur Erfassung dieser Informationen hinzu. Wenn Sie beispielsweise nach Altersgruppen filtern müssen, stellen Sie sicher, dass Sie eine eingebettete Daten für Altersgruppen anlegen.
- Überlegen Sie, welche Datumsbereiche in Ihrem Reporting am relevantesten sind. Es ist üblich, ein eingebettete Daten zu erstellen, um die relevantesten Feldperiodeninformationen zu erfassen, um in Dashboards zu filtern oder zu buggen. Tipp: Feldperioden stimmen möglicherweise nicht mit den Feldern Erfassungsdatum oder Enddatum überein, weshalb das Feld „wave_date“ für die Berichterstellung hilfreich ist. Beispiel: Ihre April-Welle muss möglicherweise einige Umfrageteilnehmer von Anfang Mai einbeziehen.

- Berücksichtigen Sie alle benutzerdefinierten Variablen, die möglicherweise benötigt werden, und richten Sie sie mithilfe von eingebettete Daten.
Tipp: Wir empfehlen Gruppieren von Elementen im Umfragenverlauf um die Logik zu organisieren und die Fehlerbehebung zu vereinfachen.
Programmierprinzipien
Um eine Instanz (BTDS) mit Ihrem Programm sind bestimmte zusätzliche Programmierhinweise erforderlich:
Wiederverwendbare Referenzliste
Die vollständige Instanz für die gesamte Umfrage sollte als Wiederverwendbare Antwortmöglichkeit. Die Instanz im rest der Umfrage müssen mit den in der wiederverwendbaren Antwortmöglichkeit eingegebenen Namen übereinstimmen. Weitere Informationen finden Sie auf der verlinkten Supportseite.
Tipp: Optionen wie „Andere“, „Nicht zutreffend“ oder „Keine“ sollten nicht in der wiederverwendbaren Antwortmöglichkeit enthalten sein, können jedoch in tatsächliche Umfrage aufgenommen werden.
Achtung: Instanz dürfen nicht länger als 35 Zeichen sein.
Frage- und Antworttext
Für Fragen, die für jede Instanz wiederholt werden (auch als markengeführte Fragen bezeichnet), die Fragenbezeichnung (z. B. „NPS_brandX“) und Fragetext (z. B. „Wie wahrscheinlich ist es, dass Sie [Instanz X] einem Freund oder Kollegen empfehlen?“) sollte konsistent sein.
Stellen Sie bei Fragen mit Marken als Antwortmöglichkeiten sicher, dass Sie Folgendes festlegen: Variablenname als Instanz in der Liste der wiederverwendbaren Antwortmöglichkeit, wenn die Antwortmöglichkeit unterscheidet sich vom Instanz (z.B. wenn HTML für ein Bild oder zusätzlichen Text vorhanden ist).
Parallele Umfrage
Ein paralleler Umfrage ist der Fall, wenn eine Reihe von Fragen zu einer einzelnen Instanz in einem Umfrage zusammengefasst wird und es für jede Instanz einen Umfrage gibt. Jeder Blockname sollte demselben Namensmuster folgen, was dazu führt, dass die Fragen in ihnen als parallel betrachtet werden. Qualtrics stellt parallele Fragen zusammen.
Beispiel: Angenommen, Sie möchten Blöcke erstellen, die nach Hindernissen beim Kauf von Marken fragen. Benennen Sie jeden Block „Barrieren – [Instanz]“ (z. „Barrieren – Bestes Frühstück“, „Barrieren – Gesundes Getreide“), berücksichtigt der Maschinenalgorithmus diese Blöcke parallel und stapelt Fragen zusammen. Wenn Blöcke unterschiedliche Namenskonventionen haben (z.B. “Barrieren – Bestes Frühstück”, “Barrieren – Gesundes Getreide (Kinder)”), wird der Maschinenalgorithmus nicht Berücksichtigen Sie die Blöcke parallel und stapeln Sie sie möglicherweise nicht.
Eingebettete Daten stapeln
Standardmäßig eingebettete Daten wird nicht gestapelt. Das Stapeln eingebettete Daten ist jedoch häufig für benutzerdefinierte Instanz erforderlich, die Instanz berechnen und messen.
Gestapelte eingebettete Daten sollten oben in der Umfragenverlauf mit dem Wert “0” und folgender Namenskonvention:
gbt__v1__[Stack-Typ]__[Spaltenname]__[Instanz] Beispiel: Sie können festlegen, ob ein Befragte:r die Instanz jemals verwendet hat oder ob er die Instanz nicht verfügbar ist. Durch das Erstellen einer Variablen für gestapelte eingebettete Daten können Sie beide Bedingungen in einem Feld kombinieren, das Sie in Ihren Dashboard und Widgets verwenden können.
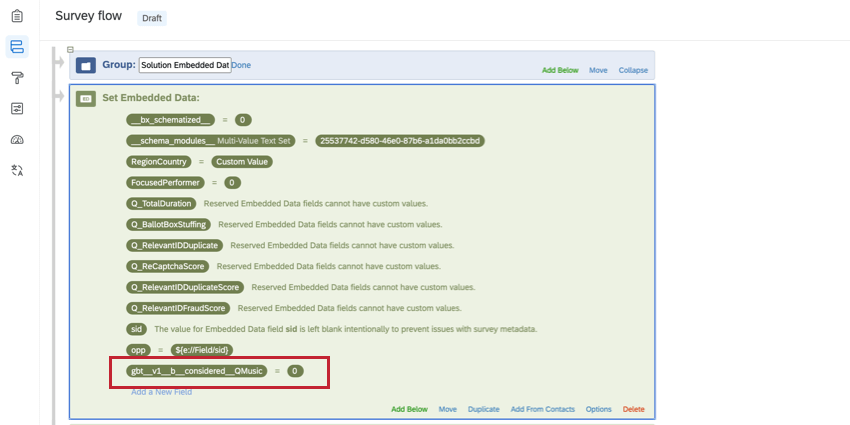
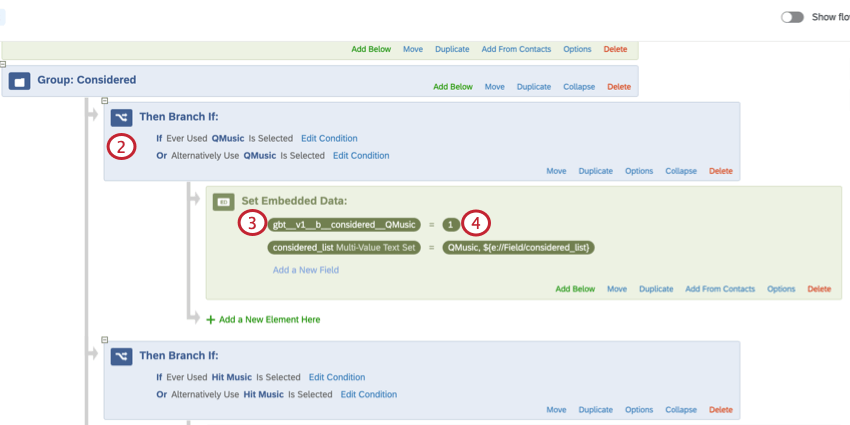
In den folgenden Abschnitten finden Sie weitere Informationen zum Anlegen Ihrer gestapelten eingebettete Daten.
Stapelart
Der Stack-Typ bezieht sich auf den Variablentyp, der für diese eingebetteten Daten referenziert wird. Es gibt zwei Stack-Typen:
- Binär (b): Die Variable hat nur zwei mögliche Werte. Beispielsweise wird für die Variable „Berücksichtigung“ eine Instanz entweder als (1) oder nicht (0) betrachtet.
- Normal (n): Die Variable hat eine unbegrenzte Anzahl numerischer Optionen und enthält entweder einen berechneten Wert oder den Wert, den ein Befragte:r für eine Frage ausgewählt hat.
| Stapelart | Beispielformat | Beispiele für Anwendungsfälle |
|---|---|---|
| b (binär) | gbt__v1__b__Übersicht__QMusik | Favorit, berechnete Berücksichtigung |
| n (normal) | gbt__v1__n__Anteil von Wallet__QMusic | Instanz, Anteil an Brieftasche |
Spaltenname
Der Spaltenname soll als eingebettete Daten im angezeigt werden. BTDS.
| Stapelart | Beispielformat | Beispiele für Anwendungsfälle |
|---|---|---|
| b (binär) | gbt__v1__b__Berücksichtigung__QMusik | Favorit, berechnete Berücksichtigung |
| n (normal) | gbt__v1__n__Anteil an Brieftasche__QMusik | Instanz, Anteil an Brieftasche |
Markenname
Der Instanz gibt an, auf welche Instanz sich die Daten in der Variable beziehen.
Achtung: Instanz müssen mit der entsprechenden Instanz in der übereinstimmen Wiederverwendbare Antwortmöglichkeit. Wenn die Instanz nicht vollständig übereinstimmen, werden die Daten nicht korrekt gestapelt. Dazu gehören Sonderzeichen wie Leerzeichen, Apostrophe, Bindestriche usw.
| Stapelart | Beispielformat | Beispiele für Anwendungsfälle |
|---|---|---|
| b (binär) | gbt__v1__b__Berücksichtigung__QMusic | Favorit, berechnete Berücksichtigung |
| n (normal) | gbt__v1__n__Anteil an Wallet__QMusic | Instanz, Anteil an Brieftasche |
Automatisch kodierte nicht bekannte Sensibilisierung
Nicht bekannte Kennzahlen, auf welche Marken es ankommt, wenn Sie eine bestimmte Kategorie erwähnen (z. B. „Wenn Sie an [Kategorie] denken, welche Instanz fällt zuerst in den Sinn?“). Autocoded Unaided Awareness (AUA) stellt sicher, dass Rechtschreib-, Groß- und Kleinschreibungsschwankungen oder häufige Akronyme korrigiert werden, sodass die Daten richtig gruppiert werden können. Dies geschieht durch das Anlegen einer Webdienst im Umfragenverlauf.
Tipp: Wenn Sie daran interessiert sind, eine nicht automatisch kodierte Sensibilisierung einzurichten, wenden Sie sich an Ihren Implementierungspartner.
Der AUA-Webdienst betrachtet die eingegebenen Freitextdaten und vergleicht sie mit einem Instanz, das Sie erstellen. Wenn der Eintrag einem Instanz innerhalb einer kleinen Anzahl von Zeichenabweichungen ähnelt, kodiert der Web-Service den Eintrag so um, dass er mit dem Instanz übereinstimmt.
Beispiel: Angenommen, wir haben eine Instanz, die “Qualtrics” enthält. Wenn AUA aktiviert ist, werden alle Variationen von Qualtrics (z. B. „Quatrlics“) als “Qualtrics” kodiert. Wenn ein Befragte:r jedoch „QXM“ eingegeben hat, wird dies nicht berücksichtigt, da es sich nicht um eine Variante von “Qualtrics” handelt.
Tipp: Warum AUA anstelle von Text iQ verwenden?
- AUA behandelt die richtigen Substantive und Namen, während Text iQ sich auf allgemeine Sprachbegriffe und grammatikalische Strukturen in längeren Texteinträgen konzentriert.
- AUA kodiert Antworten während der Umfragensitzung in Echtzeit um, sodass Sie nicht auf eine Verarbeitung warten müssen, um die Werte anzuzeigen. Sie können die Ergebnisse bei Bedarf auch in der Umfrage verwenden.
- Sie können Ergebnisse stapeln, um Signifikanztests und andere Analyseoptionen in den Analysen und Dashboards von Qualtrics zu nutzen.
AUA-DETAILS
- Nur von der Qualtrics unterstützte Sprachen sind mit AUA kompatibel. Benutzerdefinierte Sprachen werden nicht unterstützt.
- Eine bestimmte Instanz kann mehrere Einträge enthalten (z. B. könnte “Qualtrics” Einträge für “Qualtrics”, „Qualtrics Software“, „Qualtrics Research“ und „Qualtrics XM“ enthalten, um sicherzustellen, dass Variationen all dieser Elemente als nur “Qualtrics” klassifiziert werden).
- Die Länge des Instanz beeinflusst, wie weit die Schreibweise des Befragte:r von einem Instanz im Instanz abweichen kann.
- Antworten mit maximal 3 Zeichen sind nicht zulässig und müssen genau mit dem Eintrag Instanz übereinstimmen. Beispielsweise müsste „Ivy“ genau als „Ivy“ geschrieben werden.
- Antworten mit 4 Zeichen sind zulässig, eine Abweichung. Beispiel: „QHub“ akzeptiert Variationen wie „Qub“ und „QHb“.
- Antworten, die aus 5 Zeichen bestehen, sind zwei zulässige Abweichungen. Beispiel: „Flanel“ akzeptiert Variationen wie „Flanell“ oder „Flnl“.
- Antworten mit mehr als 6 Zeichen sind drei zulässige Abweichungen. Beispiel: „BeatDrop“ akzeptiert Variationen wie „BeatD“ oder „BetDrp“.
Tipp: Wenn Sie Ihr Instanz überprüfen oder aktualisieren möchten, arbeiten Sie mit Ihrem Implementierungspartner zusammen.
Instanz Equity, Anteil am Wallet und Opportunity Gap
Tipp: Wenn Sie daran interessiert sind, Instanz Equity, Share of Wallet oder die Opportunity-Gap-Analysen einzurichten, wenden Sie sich an Ihren Implementierungspartner.
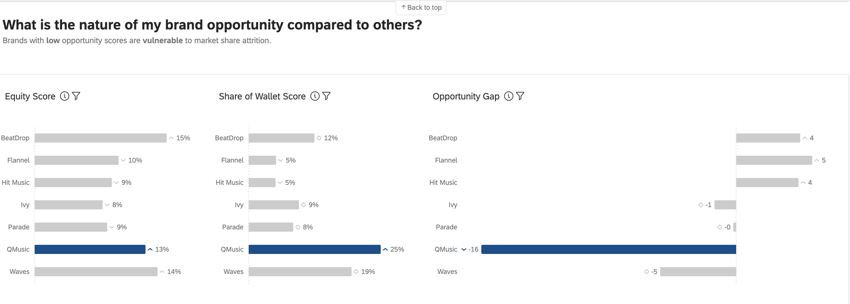
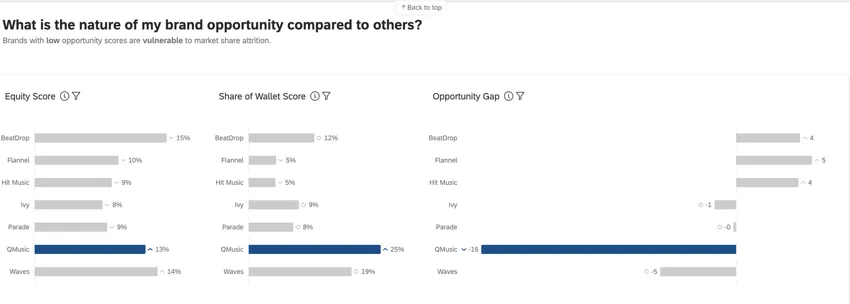
In den BX Dashboards werden die Metriken Instanz Equity, Share of Wallet und Opportunity Gap verwendet, um erweiterte Erkenntnisse über die Leistungen der Instanzen zu liefern.
{kind=link}
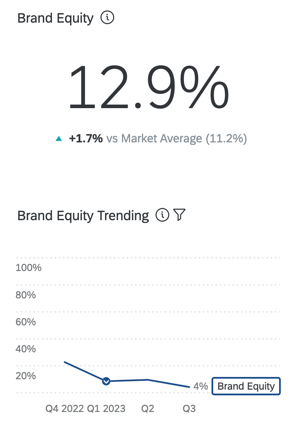
INSTANZ EQUITÄT
Instanz gibt an, welche Instanz wählen würden, wenn es keine Hemmnisse für den Kauf oder die Verwendung eines Produkts gäbe. Bei einer aggregierten Betrachtung spiegelt Instanz den erwarteten Marktanteil Ihrer Instanz wider. Dies ist ein Prozentsatz, der insgesamt 100 beträgt (z. B. würden 75 % der Verbraucher meine Instanz kaufen, wenn dies möglich wäre, aber 25 % würden es vorziehen, [x] Instanz zu kaufen).
Der Ansatz ist einfach und erfordert nur wenige Fragen (Verantwortlichkeit, Berücksichtigung und Instanz). Relative Instanz werden in „Ränge“ und dann in „prognostizierte Anteile“ umgewandelt. Diese Maßnahmen weisen eine starke Korrelation mit Verhaltensweisen auf.
{kind=link}
Tipp: Instanz wird in einer Umfrage berechnet, indem ein Webdienst im Umfragenverlauf.
Tipp: Es gibt viele Konzeptionen für Instanz, und der Qualtrics wird als Instanz bezeichnet. Diese Konzeption ist im öffentlichen Bereich verfügbar und wurde umfassend validiert.
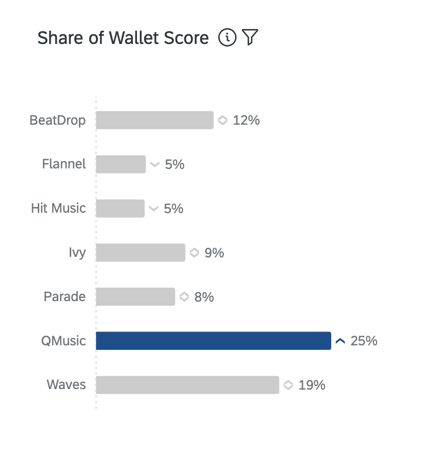
ANTEIL VON WALLET, ODER GESCHÄTZTER MARKTTEIL
Der Anteil der Brieftasche, auch bekannt als „geschätzter Marktanteil“, misst, wie viel der jüngsten Nutzung der Befragten jeder Instanz zugeschrieben wird. Dies ist in der Regel ein Prozentsatz, der insgesamt 100 betragen sollte (z. B. haben 75 % meiner [Kategorie] Einkäufe mit [x] Instanz und 25 % mit [y] Instanz).
{kind=link}
Tipp: Der Anteil des Wallet wird in einer Umfrage berechnet, indem ein mathematischer Vorgang im Umfragenverlauf.
OPPORTUNITY GAP
Opportunity-Gap ist der Unterschied zwischen Ihrer Instanz und dem geschätzten Marktanteil – mit anderen Worten, die Lücke zwischen dem Wunsch nach Ihrer Instanz und dem tatsächlichen Kaufverhalten. Eine Opportunity besteht, wenn das Eigenkapital größer als der Anteil ist (positive Bewertungen) und eine Schwachstelle vorhanden ist, wenn das Eigenkapital kleiner als der Anteil ist (negative Scores).
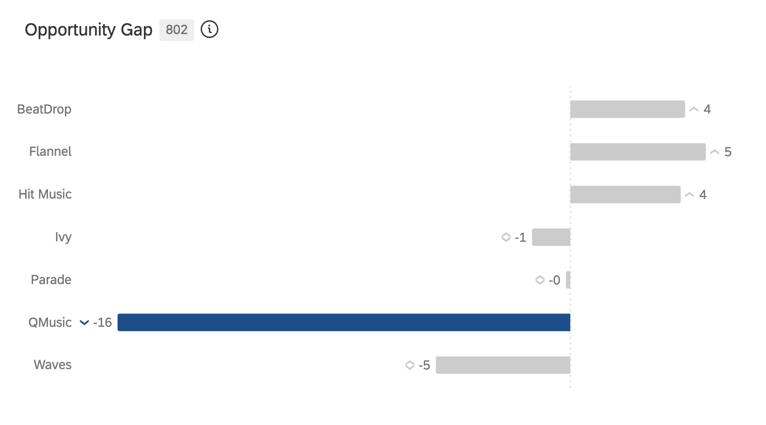{kind=link}
Tipp: Opportunity-Lücke wird in einer Umfrage berechnet, indem ein mathematischer Vorgang im Umfragenverlauf.
Großartig! Vielen Dank für die Rückmeldung!
Vielen Dank für die Rückmeldung!