-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Agrupamento de dados (Studio)
Sobre o agrupamento de dados no Studio
Ao criar um dashboard no Studio, você pode especificar quais dados deseja incluir no dashboard. Você pode limitar os dados em um relatório agrupando, classificando ou filtrando seus dados.
Há uma variedade de agrupamentos que você pode usar para seus dados. Esta página aborda como agrupar seus dados de acordo com esses diferentes agrupamentos.
Agrupamento de dados em um Widget
Você pode agrupar dados em tipos widget compatíveis. Para agrupar os dados em seu widget:
- Ao editar o dashboard, clique em Editar no menu de opções de widget para o widget que você deseja agrupar dados.
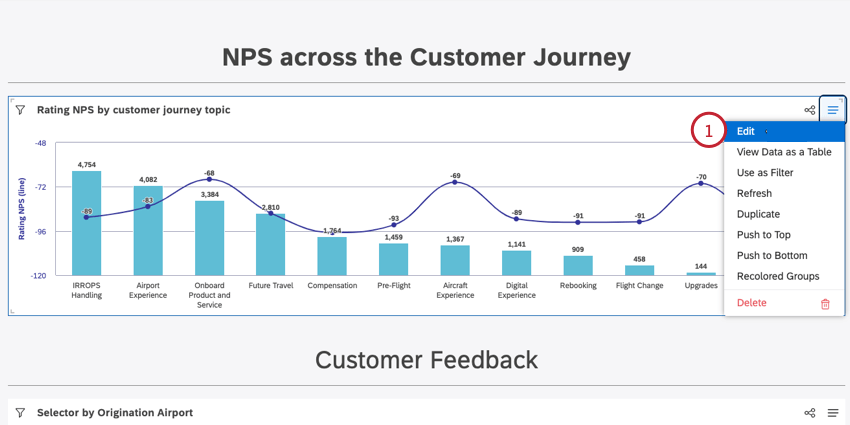
- Na guia “Visualização”, use o menu suspenso Agrupar por para escolher um agrupamento de dados. Consulte as seções abaixo para obter mais informações sobre cada opção desse menu suspenso.
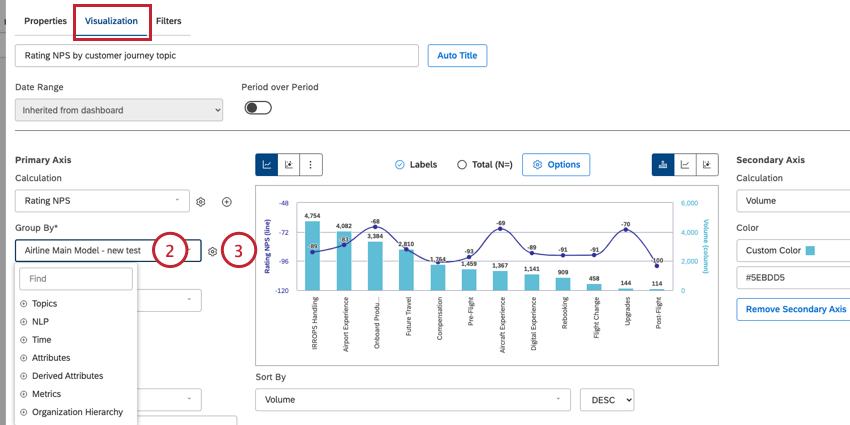 Qdica: se estiver usando um widget de tabela, essa opção será chamada de “Agrupamentos”. Se estiver usando um widget de mapa de calor, essa opção será chamada de “Boxes” (Caixas). Se estiver usando um widget de rede, essa opção será chamada de “Nodes” (Nós).
Qdica: se estiver usando um widget de tabela, essa opção será chamada de “Agrupamentos”. Se estiver usando um widget de mapa de calor, essa opção será chamada de “Boxes” (Caixas). Se estiver usando um widget de rede, essa opção será chamada de “Nodes” (Nós). - Se desejar, você pode editar as configurações de agrupamento do widget clicando no ícone de engrenagem avançar do menu suspenso “Group By” (Agrupar por). Consulte Configurações de agrupamento para obter mais informações sobre essas configurações.
Tópicos
A seleção de Tópicos permite que você agrupe os dados por categorias derivadas do feedback do cliente. Isso lhe dá uma visão geral do que seus clientes estão falando.
Depois de escolher seu modelo de categoria, abra as configurações de agrupamento para selecionar quais tópicos serão incluídos no widget. Consulte Personalização de agrupamentos de modelos de categoria para obter mais informações.
Ao agrupar dados por tópicos, você pode optar por gerar relatórios em diferentes níveis em seu modelo de categoria. Para obter uma visão geral de alto nível sobre o que seus clientes estão falando, agrupe os dados por tópicos Nível 1. Para monitorar temas mais específicos no feedback do cliente, agrupe os dados por tópicos Nível 2 ou inferior (dependendo do seu modelo). Para obter o relatório mais granular em todos os níveis, agrupe os dados usando a opção Folha, que permite que você se concentre em folhas de tópicos ou categorias que não tenham subcategorias.
PNL
A seleção de NLP permite que você agrupe dados por critérios criados automaticamente pelo mecanismo de processamento de linguagem natural do XM Discover. Esses critérios são criados a partir de feedback não estruturado que é processado pelo XM Discover. Há vários subgrupos disponíveis para você escolher:
Palavras
Os agrupamentos Words NLP permitem que você agrupe dados por palavras ou tipos específicos de palavras mencionadas no feedback do cliente. Os seguintes agrupamentos estão disponíveis:
- Todas as palavras: Agrupar dados por palavras regulares. Isso lhe dará uma ideia dos termos mais comuns que os clientes estão usando ao falar sobre seu produto ou serviço.
- Marca CB: agrupa dados por menções marca.
- Empresa CB: Dados do grupo por menções da empresa.
- Endereço de e-mail CB: Agrupar dados por endereços de e-mail mencionados no feedback.
- Emoticon CB: Agrupa dados por emojis e emoticons usados no feedback.
- Evento CB : Agrupe dados em torno de feriados padrão (como Ano Novo ou Halloween), eventos da vida (como casamento ou formatura) e eventos culturais comuns (como o Super Bowl) mencionados no feedback.
- Setor CB: Agrupar dados por setor relacionado.
- Pessoa CB: Agrupar dados por nomes de pessoas mencionadas no feedback.
- Número de telefone CB: Agrupa dados por números de telefone mencionados no feedback.
- Produto CB: Agrupar dados por menções de produtos.
- Profanidade CB: Agrupa dados por palavras profanas de um conjunto predeterminado.
Palavras Associadas
O agrupamento de palavras associadas permite que você agrupe dados por pares de palavras que são mencionadas em conexão umas com as outras no feedback do cliente. Isso permite que você veja os tópicos e temas mais comuns no feedback do cliente, independentemente da categorização do tópico.
As palavras associadas são apresentadas no seguinte formato: palavra 1 → palavra 2.
Hashtags
O agrupamento Hashtags permite que você agrupe dados por frases de hashtags (palavras ou frases prefixadas com o símbolo # ). As hashtags geralmente são usadas em publicações de mídia social para ajudar a identificar e categorizar o indivíduo da publicação.
Enriquecimento
Os agrupamentos de Enriquecimento permitem que você agrupe os dados pelos tipos de conteúdo incluídos no feedback do cliente. Os seguintes agrupamentos estão disponíveis:
- Capítulos CB: Agrupar dados por capítulos de conversação que representam segmentos semanticamente relacionados da conversa (como abertura, necessidade, verificação, etapa de solução e fechamento).
- Subtipo de conteúdo CB: Agrupe ainda mais os dados sem conteúdo por seus subtipos (como anúncios, cupons, links de artigos ou tipo “indefinido”). Observe que, para registros com conteúdo, o subtipo também é sempre com conteúdo.
- Tipo de conteúdo CB: Agrupa os dados de acordo com seu conteúdo ou não conteúdo, conforme identificado automaticamente pelo XM Discover.
- Recursos detectados por CB: Agrupa os dados por tipos de recursos de NLP detectados (por exemplo, dados que contêm menções ao setor ou marca ).
- CB Emotion (Emoção CB): Agrupar dados por tipos de emoção detectados pelo mecanismo de PNL (como raiva, confusão, decepção, constrangimento, medo, frustração, ciúme, alegria, amor, tristeza, surpresa, gratidão, confiança ou outros).
- CB Medical Condição médica CB): Agrupa os dados por condições médicas mencionadas no texto (por exemplo, “covid” ou “meningite”).
- CB Procedimento médico: Agrupa dados por procedimentos médicos mencionados no texto (por exemplo, “mamografia” ou “cirurgia na coluna”).
- Pontuação de empatia Participante do CB: Agrupa os dados de conversação de acordo com o fato de os representantes demonstrarem ou não empatia em suas interações com os clientes. 0 significa que o representante não demonstrou empatia, enquanto 1 significa que o representante demonstrou empatia.
- Motivo CB: Agrupa dados por motivos para um evento de conversa específico (por exemplo, motivo para contato ou motivo para empatia).
- CB Rx: agrupa dados por nomes de medicamentos mencionados no texto (por exemplo, “acetaminofeno” ou “tylenol”).
- Tipo de frase CB: Agrupe os dados pelo tipo de frase ou intenção (por exemplo, “pedido de ajuda” ou “sugestão”).
Idioma
Os agrupamentos de idiomas permitem que você agrupe os dados pelo idioma em que o feedback foi deixado. Os seguintes agrupamentos estão disponíveis:
- CB Idioma detectado automaticamente: Agrupa dados por idiomas detectados automaticamente (se a detecção automática de idioma estiver ativada para um projeto).
- CB Idioma processado: Agrupe os dados por idiomas nos quais o feedback foi realmente processado. Os idiomas não compatíveis com a detecção de idioma XM Discover são marcados como “outros”
Conversação
Os agrupamentos de conversas permitem que você agrupe dados por vários enriquecimentos de conversas. Observe que esses agrupamentos só estão disponíveis para dados de conversação (chamadas e bate-papos processados usando o formato de conversação do Qualtrics). Os seguintes agrupamentos estão disponíveis:
- CB % Silêncio: Agrupa os dados de acordo com a porcentagem de silêncio em uma chamada.
- Duração da conversa CB: Agrupa os dados de acordo com a duração de uma conversa em milissegundos. Para chamadas, esse é o período de tempo entre o início da primeira frase e o final da última frase. O silêncio inicial e final não é contado. Para bate-papos, esse é o tempo entre a primeira e a última frase.
- CB Kind of Participante (Tipo de participante): Agrupa os dados pelo tipo de participante. Os valores possíveis incluem:
- Chat_bot é um chatbot.
- IVR é um bot de resposta interativa de voz.
- Humano é uma pessoa.
- Tipo Participante CB: Agrupar dados pelo tipo de participante. Os valores possíveis incluem:
- o agente é um representante da empresa ou um chatbot.
- cliente é um cliente.
- type_unknown é um participante não identificado como agente ou cliente.
- Duração da frase CB: Agrupa dados pela duração de uma frase em uma chamada em milissegundos.
- CB Sentence Start Time (Hora de início da sentença CB): Agrupa os dados pelo registro de data e hora do início da sentença. Para chamadas, esse é o tempo em milissegundos desde o início audível da primeira palavra na primeira frase. Para bate-papos, esse é o tempo em milissegundos desde que a primeira mensagem foi enviada.
Qdica: o tempo de início da primeira mensagem de bate-papo será sempre 0 ms para esse atributo.
- CB Total Dead Air: Agrupa dados pelo total de ar morto em uma chamada em milissegundos. Nas chamadas, o ar morto é uma longa pausa entre os alto-falantes.
- Hesitação total do CB: Agrupa os dados pela hesitação total (do agente e do cliente) em uma chamada, em milissegundos. Em chamadas, a hesitação é uma longa pausa feita por um locutor.
- CB Total Overtalk: Agrupa dados pela duração acumulada de frases sobrepostas em uma chamada em milissegundos. Em chamadas, a conversa excessiva é qualquer momento em que dois ou mais locutores estão falando simultaneamente e as marcas de tempo de suas frases se sobrepõem.
- CB Silêncio total: Agrupa os dados pela duração acumulada de todos os silêncios maiores ou iguais a 2 segundos entre as frases de todos os participantes em uma chamada, em milissegundos.
Hora
A seleção de Time permite agrupar dados por períodos de tempo. Você pode usar agrupamentos atributo de tempo para criar um relatório de tendências, o que lhe permite visualizar como seus cálculos e métricas mudam ao longo do tempo.
Atributos
A seleção de atributos permite que você agrupe dados pelos valores de um atributo estruturado selecionado. Um atributo estruturado é qualquer campo numérico ou de cadeia de caracteres presente em um registro que não seja o feedback textual real. Os atributos estruturados geralmente contêm dados discretos com um alto grau de organização (como a idade de uma pessoa ou o nome do produto que ela usa). Os atributos disponíveis para agrupamento dependem da fonte de feedback e geralmente variam de um conjunto de dados para outro.
Métricas
A seleção de métricas permite que você agrupe dados por valores discretos ou faixas de determinados cálculos padrão e métricas derivadas. Em outras palavras, você pode organizar os dados por uma métrica e medi-los por uma métrica diferente. Os seguintes agrupamentos estão disponíveis:
- Sentimento (3 faixas): Agrupa dados por 3 faixas sentimento (Negativo, Neutro, Positivo). Consulte Agrupamento por Sentimento para obter mais informações.
- Sentimento (5 faixas): Agrupa dados por 5 faixas de sentimento (fortemente negativo, negativo, neutro, positivo, fortemente positivo). Consulte Agrupamento por Sentimento para obter mais informações.
- Esforço (3 faixas): Agrupe os dados em 3 faixas de esforço (Difícil, Neutro, Fácil). Ao agrupar por esforço, os valores nulos são incluídos por padrão.
- Esforço (5 faixas): Agrupe os dados em 5 faixas de esforço (Muito Difícil, Difícil, Neutro, Fácil, Muito Fácil). Ao agrupar por esforço, os valores nulos são incluídos por padrão.
- Intensidade emocional: Agrupe os dados em 3 faixas de intensidade emocional (Baixa, Média, Alta).
- Contagem de palavras do documento CB: Agrupa dados pelo número de palavras em um documento.
- Duração da fidelidade CB: Agrupe os dados pelo tempo de fidelidade do cliente (em anos).
- Quartil da sentença CB: Agrupa os dados de acordo com o quarto do verbatim em que a sentença se enquadra (1, 2, 3 ou 4). Isso pode ajudá-lo a entender quais tópicos estão sendo discutidos e em quais momentos da conversa.
- Contagem de palavras da sentença CB: Agrupa os dados pelo número de palavras em uma frase.
Além disso, você pode definir suas próprias métricas de caixa superior, caixa inferior e satisfação, pelas quais pode agrupar os dados. Isso permite que você determine se o feedback vem de um promotor, de um detrator ou de um cliente neutro. Os seguintes agrupamentos estão disponíveis:
- Top Box: Agrupar dados por faixas de top box (promotores e outros).
- Caixa inferior: Agrupar dados por faixas da caixa inferior (detratores e outros).
- Satisfação: Agrupe os dados por faixas de satisfação (detratores, neutros, promotores).
Motivadores
A seleção de Drivers permite agrupar os dados pelos drivers que você criou em sua conta. Você pode usar esses drivers para encontrar atributos e tópicos que levam a um determinado resultado.
Hierarquia de organização
A seleção de Hierarquia Organização permite agrupar os dados de acordo com os diferentes níveis da hierarquia organização selecionada .
Custo de agrupamento
Ao executar relatórios com vários agrupamentos, você pode receber a seguinte mensagem de erro:
“Oops! aplicar um custo estimado a cada agrupamento, e a soma dos custos não pode exceder o orçamento do guardrail de [10,5]. (Os agrupamentos de alta cardinalidade custam mais.) Remova ou escolha agrupamentos diferentes com base nos custos listados abaixo para garantir que o widget tenha um custo total dentro do orçamento:lista de agrupamentos e seus custos] Custo total atual: [total de todos os custos]”
O custo de cada agrupamento depende do número de valores exclusivos no grupo (essa medida é chamada de cardinalidade). Por padrão, a maioria dos widgets retorna os 10 principais itens por volume. Se houver 100 itens no total, esse cálculo geralmente é muito rápido. Se houver 1.000.000 de itens, será necessário mais tempo para calcular quais deles são os 10 principais. Em geral, ter mais itens exclusivos resultados em um cálculo mais caro em termos de desempenho. Esse custo pode se multiplicar rapidamente para widgets que retornam vários níveis de dados e pode resultar na exibição da mensagem de erro acima.
Se você receber o erro acima ao usar agrupamentos em um relatório, deverá remover um ou mais dos agrupamentos listados para que o custo total não exceda o orçamento. A mensagem de erro exibirá os custos estimados de cada agrupamento para ajudá-lo a decidir qual agrupamento remover.