-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Filtragem por dados estruturados (Designer)
Sobre a filtragem por dados estruturados
Use atributos de dados estruturados para filtro o feedback em modelos que categorizam e exibem as informações mais relevantes de seu conjunto de dados. Para obter informações sobre como criar e editar filtros, consulte Filtragem de dados (Designer).
Filtragem por Sentimento
XM Discover usa análise de sentimento para determinar o sentimento geral do feedback. Sentimento está disponível como um atributo do sistema com faixas predefinidas:
- Sentimento negativo : Feedback com uma pontuação de sentimento de -5,0 a -1,0
- Sentimento neutro : Feedback com uma pontuação de sentimento de -0,99 a 0,99
- Sentimento positivo : Feedback com uma pontuação de sentimento de 1 a 5,0
Filtragem por idioma
Use os seguintes atributos do sistema de discover para filtro por tipo de dados:
- CB Auto-detected Language ( _languagedetected ): O feedback sobre o idioma foi enviado se o seu projeto usa detecção automática de idioma.
- CB Processed Language ( _language ): O feedback do idioma foi enviado em. Se o idioma não for compatível com o XM Discover, ele será marcado como “OUTRO”.
XM Discover é capaz de reconhecer e marcar dados em mais de 150 idiomas usando o característica detecção automática de idioma. Sem a detecção automática de idioma, os seguintes idiomas estão disponíveis:
- Árabe
- Bengali
- Chinês (simplificado e tradicional)
- Holandês
- Inglês
- Francês
- Alemão
- Hindu
- Bahasa Indonésia
- Italiano
- Japonês
- Coreano
- Polonês
- Português
- Romeno
- Russo
- Espanhol
- Sueco
- Tagalog
- Tailandês
- Turco
- Vietnamita
Filtragem por tipo de dados
Para filtro o feedback pelo tipo de dados que foi enviado, use os seguintes atributos do sistema:
- ID da fonte ( _id_source ): A fonte de dados das sentenças.
- Verbatim Type ( _verbatimtype ): O nome do campo literal pelo qual você gostaria de filtro. Isso é útil se você tiver várias colunas verbatim.
Filtragem por tipo de conteúdo
Para projetos com detecção de tipo de conteúdo ativada, use os seguintes atributos do sistema para filtro o feedback de anúncios, spam e outros dados não acionáveis:
- Tipo de conteúdo CB ( cb_content_type ): Se os documentos são marcados como com conteúdo, o que significa que eles contêm conteúdo, ou sem conteúdo.
- Subtipo de conteúdo CB ( cb_content_subtype ): Agrupa documentos marcados como sem conteúdo em anúncios, cupons, links de artigos ou “indefinido”.
Filtragem por tipo de sentença
XM Discover usa análise semântica para identificar a intenção que é relevante para sua análise. Essas categorias são usadas no atributo do sistema em nível de sentença: CB Sentence Type ( cb_sentence_type ). Analisar o tipo de intenção usado em seus dados pode ajudar a entender como a experiência de cliente, Customer Experience pode ser aprimorada.
Clique nos seguintes tipos de frases para ver o que é identificado usando o atributo de tipo de frase:
- Sentenças acionáveis
- Sugestões e recomendações sobre como melhorar experiência de cliente, Customer Experience, bem como problemas que exigem atenção imediata.
- Churn: Ameaça de perda de clientes.
- Clamar por ajuda: Solicita ajuda e assistência.
- Solicitação: Contém uma solicitação implícita ou explícita, como uma chamada para ação ou informação.
- Sugestão: Contém uma sugestão implícita ou explícita para mudar algo.
- Permanência: Há quanto tempo um cliente usa um serviço ou produto.
- Cancelamento: Contém uma ameaça ou intenção de cancelar sua associação, serviço ou outra transação. Esse tipo também captura a não renovação, o cancelamento da inscrição ou a rescisão.
- Sentenças relacionadas à sentença
- Identifica o sentimento das sentenças que não possuem recomendações acionáveis.
- Apático: Não expressa interesse ou preocupação.
- Negativo genérico: sentimento negativo que não tem um destino específico.
- Elogio genérico: sentimento positivo que não tem um destino específico.
- Recomendar: Recomenda a experiência desse cliente.
- Não recomendo: Desaconselha a experiência desse cliente.
- Sentenças de pergunta/resposta
- Tipos de feedback das respostas às perguntas pesquisa.
- Apologia: Contém um pedido de desculpas explícito.
- Referência cruzada: Faz referência a um comentário anterior ou a uma resposta.
- Não sei: O feedback não é capaz de fornecer uma resposta. Por exemplo, “I wish I know” (Eu gostaria de saber).
- Tudo: Respostas que abrangem todas as opções sugeridas.
- Lista: Contém uma lista de itens.
- Sem comentários: O respondente se recusa a comentar ou deixar uma resposta. Por exemplo, “N/A”.
- Sim: contém afirmações genéricas.
- Frases de observações sociais
- Feedback relacionado aos aspectos sociais da interação com o cliente, como cumprimentos, risos e gratidão.
- Hello/Bye: Saudações e despedidas.
- Risos: Expressões de riso, seja verbalmente ou pelo uso de emojis. Por exemplo, “Haha! xD”.
- Agradecimentos: Expressões de gratidão.
- Sentenças de divulgação legal
- Feedback que contém divulgações legais.
- Divulgação: Contém declarações de divulgação. Por exemplo, “Esta chamada pode ser monitorada ou gravada”
- Mini-Miranda: Aplicável nos Estados Unidos, contém um aviso legal de Mini-Miranda. Por exemplo, “O objetivo da comunicação é cobrar uma dívida”
- Sentenças específicas de conversação
- Feedback específico para as conversas do contato center. Esses tipos de frases só estão disponíveis com dados de conversação.
- Empatia: a empatia é expressa, por exemplo, ao pedir desculpas, demonstrar interesse ou reconhecer dificuldades.
- Em espera: Os clientes são colocados em espera.
- Transferência: Os clientes pedem para ser transferidos ou os representantes transferem um cliente.
Filtragem por contagem de palavras
Use os atributos de contagem de palavras da frase ou de contagem de palavras do documento para filtro os dados pelo número de palavras na frase ou no registro. O intervalo definido nesses atributos inclui valores. Se a contagem de palavras for zero, a frase/registro não tem texto ou foi carregada antes de o característica ser ativado.
- CB Sentence Word Count ( cb_sentence_word_count ): atributo em nível de frase permite filtro os dados pelo número de palavras em uma frase.
Qdica: Para visualizar frases com 10 palavras ou menos, use o intervalo cb_sentence_word_count: [1 TO 10].
- CB Document Word Count ( cb_document_word_count ): atributo em nível de registro que permite filtro dados pelo número de palavras em um registro. Essa também é a soma de todas as contagens de palavras das frases.
Qdica: Para visualizar registros com 50 palavras ou mais, use cb_document_word_count: [50 TO 200].
Filtragem por quartil de sentença
O atributo CB Sentence Quartile ( cb_sentence_quartile ) identifica a parte do verbatim em que uma frase se encontra. Os valores são de 1 a 4, sendo que cada seção representa 25% do comprimento do verbatim. Se um registro tiver vários verbatims, haverá quartis para cada verbatim no registro.
Aplicação do quartil de sentenças
Se seus dados históricos não contiverem dados de quartil de sentença, você poderá adicioná-los aos seus dados.
- Navegue até a guia Categorizar de seu projeto.
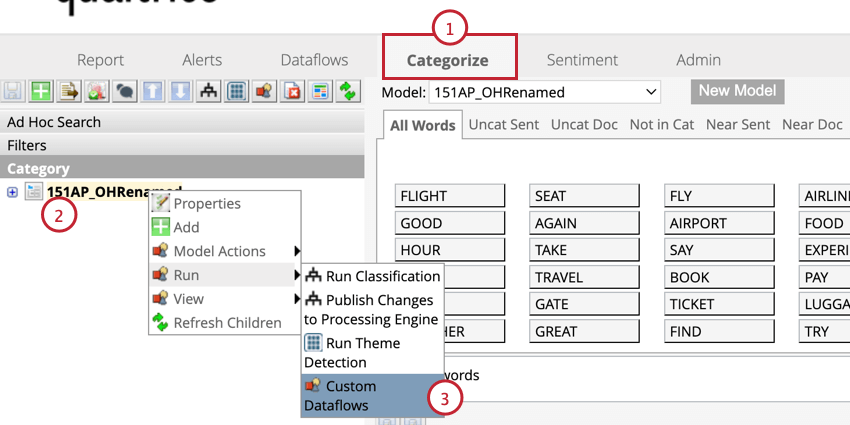
- Clique com o botão direito do mouse em um modelo de categoria.
- Passe o mouse sobre Run (Executar ) e selecione Custom Dataflows (Fluxos de dados personalizados).
- Selecione Reprocessar atributos derivados da linguagem.
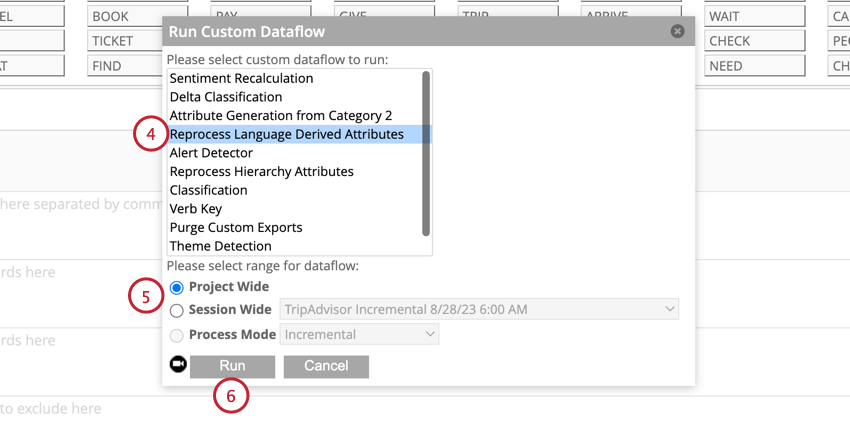
- Selecione se deseja processar todos os dados do projeto ou os dados de uma sessão específica.
- Clique em Run.
Filtragem por esforço
O CB Effort mede o nível de esforço expresso pelos clientes durante sua experiência. Esse atributo está disponível no nível da frase em uma escala de -5 a 5, sendo que -5 indica a experiência mais difícil e 5 indica a experiência mais fácil. O intervalo inclui os valores.
Filtragem por tempo de fidelidade
O CB Loyalty Tenure permite que você filtro os dados pelo período de tempo, em anos, em que um cliente usou um serviço ou teve um produto. Esse atributo está disponível no nível da frase em frases com o tipo de frase tenure. O intervalo inclui os valores.
Filtragem por tipo de interação
CB Interaction Type ( cb_interaction_type ) define os dados pelo tipo de interação XM, o que permite distinguir o feedback regular dos dados de conversação. Esse atributo está disponível nos níveis de documento, literal e de frase.
O tipo de interação pode ter os seguintes valores:
- Bate-papo: Dados de conversação de canais digitais.
- Feedback: Dados de feedback regulares (como menções on-line, avaliações e assim por diante).
- Pesquisa: Dados de resposta de uma pesquisa.
- Voz: Dados conversacionais de conversas transcritas em áudio.