-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Carregador de dados (Designer)
Sobre o Data Loader
O carregador de dados é usado para importar dados para seus projetos no XM Discover por meio de um serviço de API em tempo real. Para acessar o carregador de dados, vá para a página Admin, selecione seu projeto e, em seguida, vá para a guia Data Loader.
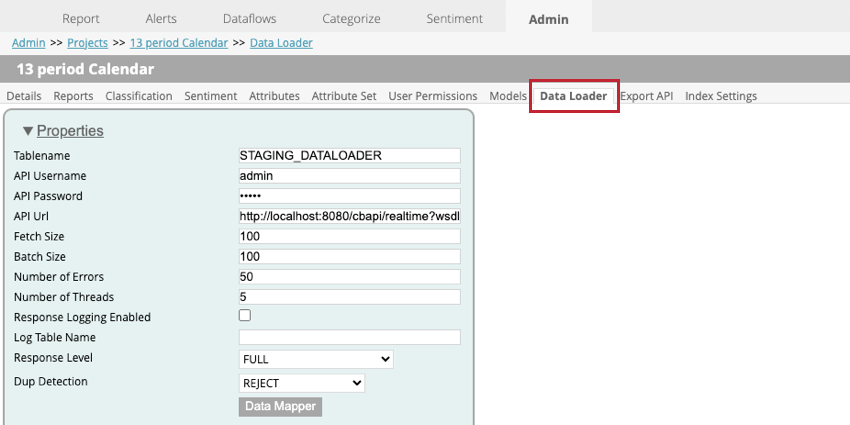
Configurações do carregador de dados
As seguintes configurações estão disponíveis ao configurar o carregador de dados em um projeto:
- Tablename: Digite o nome da tabela de preparação que contém os dados a serem importados para o XM Discover.
- Nome de usuário da API: digite o nome de usuário do usuário API que pode executar a chamada de API.
- Senha API. Digite o nome de usuário para o usuário API.
- URL API: Digite o URL do serviço de API usado para buscar os dados.
- Tamanho da busca: Especifique o número de linhas que devem ser importadas.
- Tamanho do lote: Especifique o número de linhas que devem ser importadas em um lote. Se o tamanho do lote for maior do que o tamanho da busca, serão realizadas várias chamadas até que todos os dados sejam importados.
- Número de erros: Se a importação falhar devido a erros, você poderá especificar quantas vezes a chamada será tentada novamente.
- Número de threads: Insira o número máximo de threads que devem ser executados em uma única instância do transformador.
- Registro de respostas ativado: Quando ativada, essa opção permite criar um registro dos resultados do processamento de documentos.
- Nome da tabela de registro: Se estiver registrando seus resultados, uma nova tabela será criada para você. Digite um nome para a tabela nesse campo.
Qdica: Você só precisa especificar algo para esse campo se a opção Registro de respostas ativado estiver selecionada.
- Nível resposta: Essa opção deve ser definida como SAVE ONLY (salvar apenas).
- Detecção de duplicatas: Escolha como as duplicatas são tratadas. Suas opções incluem:
- NONE (NENHUM): As duplicatas são importadas.
- REJECT (REJEITAR): As duplicatas são rejeitadas.
- ATUALIZAR ATRIBUTOS: Somente atributos estruturados são atualizados para duplicatas.
- Mapeador de dados: O mapeador de dados é usado para escolher quais campos são extraídos da tabela de preparação para serem usados no XM Discover. Consulte a subseção Mapeador de dados abaixo para obter mais informações.
Mapeador de dados
O mapeador de dados é usado para extrair dados de sua tabela de preparação para uso no XM Discover. O mapeador de dados incluirá apenas os campos que estão em sua tabela de preparação.
- Nas configurações do carregador de dados, clique em Data Mapper.
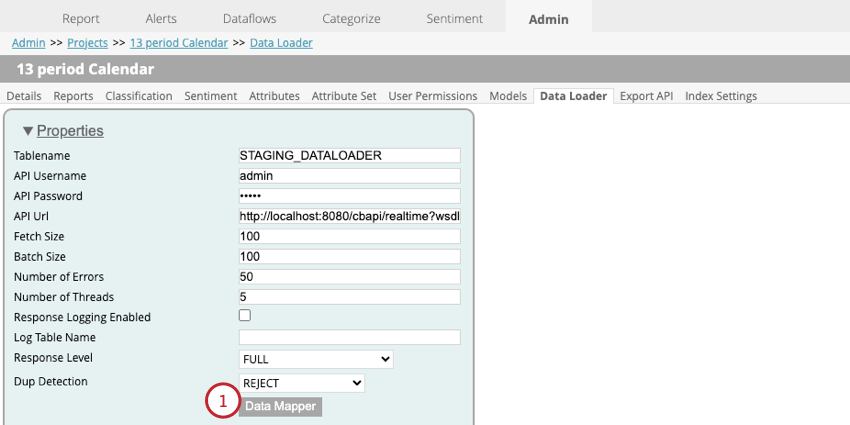
- Selecione o campo que indica a fonte dos dados.
- Clique em Seguinte.
- Escolha o campo a ser usado como chave natural e, em seguida, clique na seta para a direita ( > ). Você pode selecionar vários campos e a chave natural será uma concatenação dos campos na ordem em que você os selecionou.
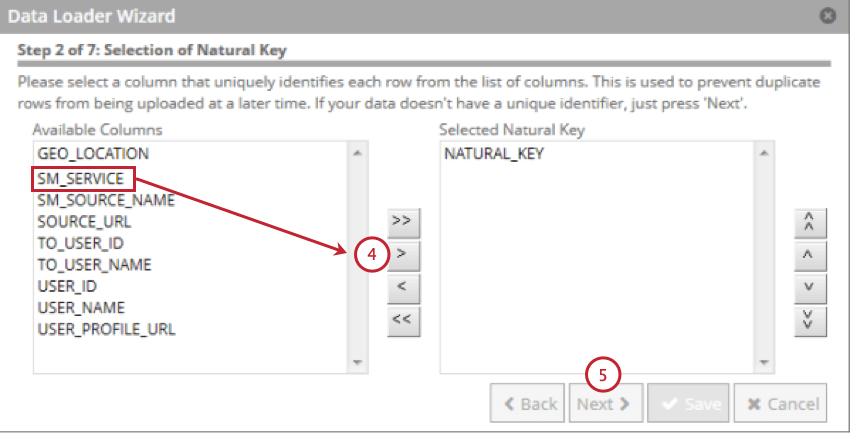 Qdica: os campos com mais de 256 caracteres são excluídos. As chaves naturais são truncadas em 256 caracteres.
Qdica: os campos com mais de 256 caracteres são excluídos. As chaves naturais são truncadas em 256 caracteres. - Clique em Seguinte.
- Selecione o campo que contém os verbatims do cliente e clique na seta para a direita ( > ).
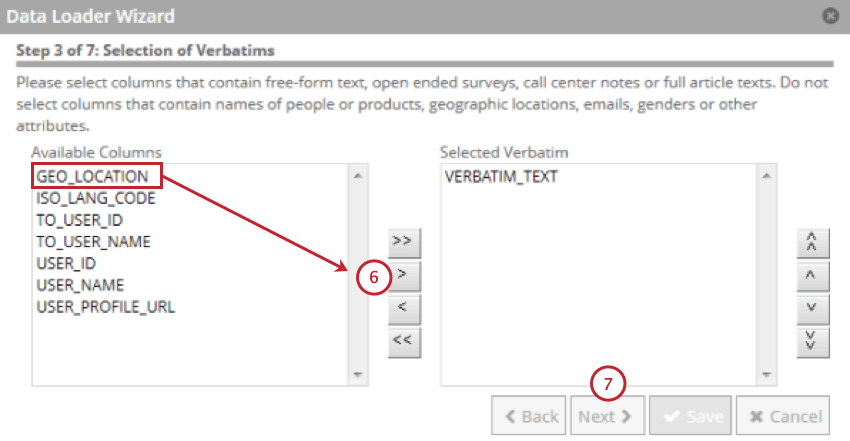
- Clique em Seguinte.
- Selecione os campos que contêm seus atributos estruturados e, em seguida, clique na seta para a direita ( > ). Você pode selecionar até 500 atributos estruturados.
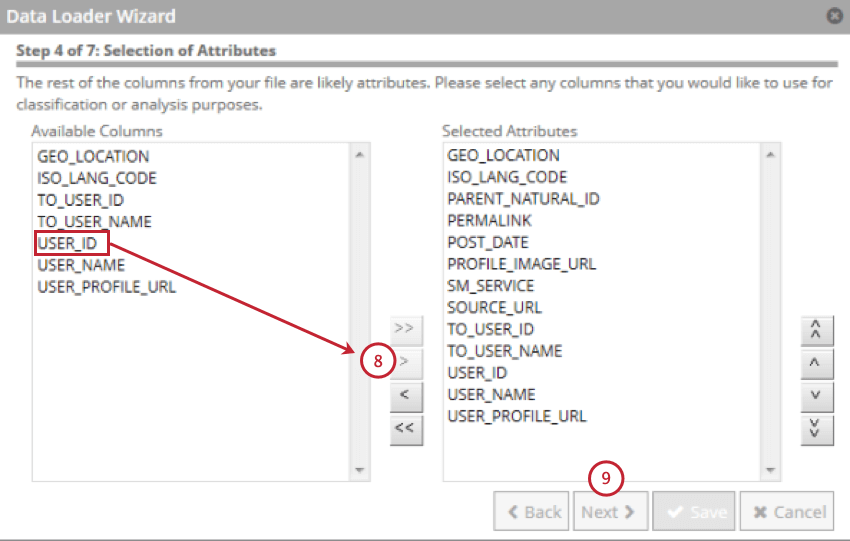
- Clique em Seguinte.
- Revise seus atributos e faça alterações conforme necessário. Você pode alterar o nome de exibição do atributo, o tipo, a disponibilidade do relatório e indicar se o campo é um e-mail.
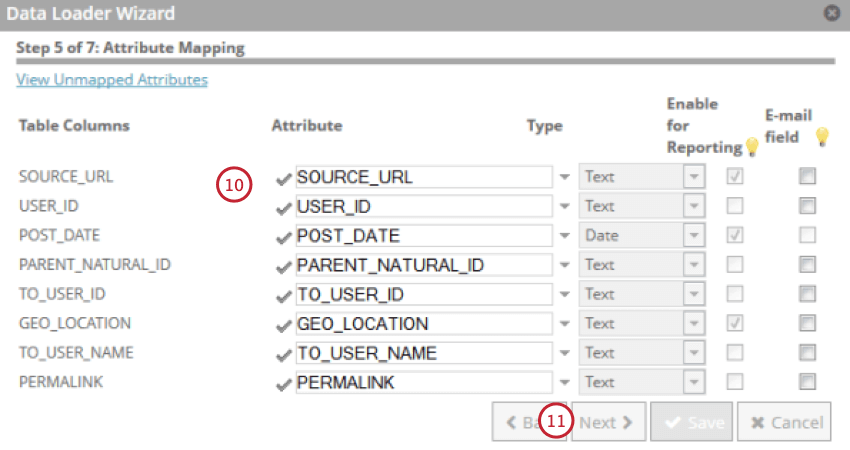
- Clique em Seguinte.
- Selecione o campo que contém a data em que o documento foi criado. Essa será usada como a data de registro no XM Discover.
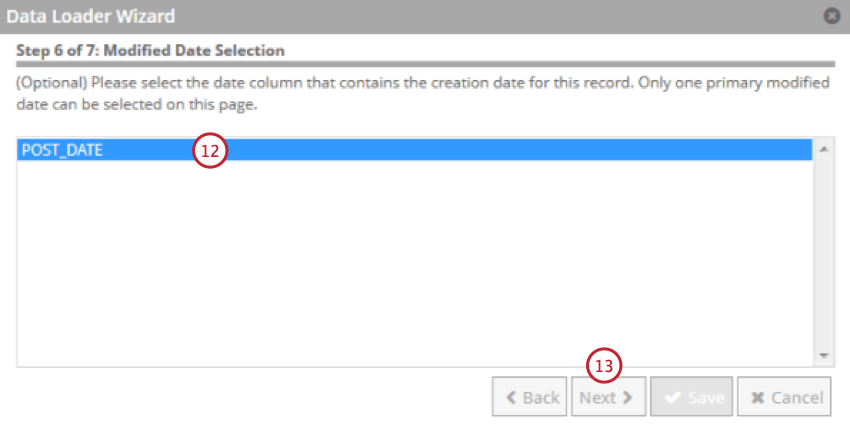
- Clique em Seguinte.
- Selecione o campo que contém o idioma do documento.
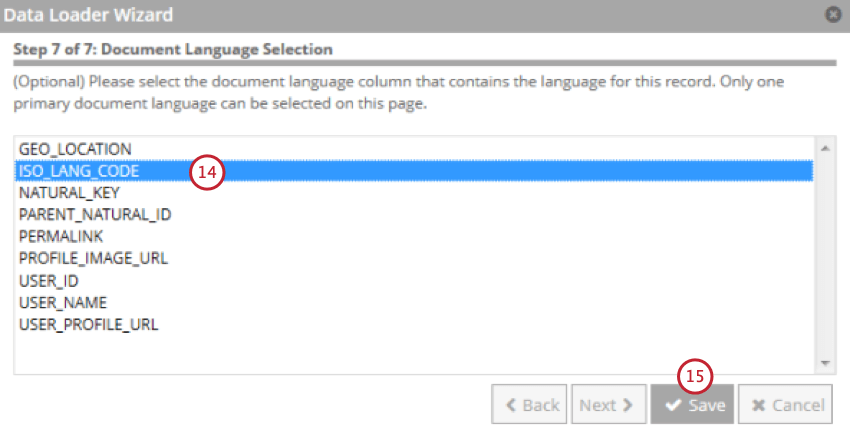
- Clique em Salvar.
Importação de dados com o Data Loader
Depois que os dados forem carregados em uma tabela de preparação por meio do carregador de dados, você poderá processar esses dados para usá-los no XM Discover. Esta seção aborda como configurar um processo de carregamento de dados automatizado para que seus dados sejam mantidos atualizados.
- Vá para a guia Fluxos de dados .
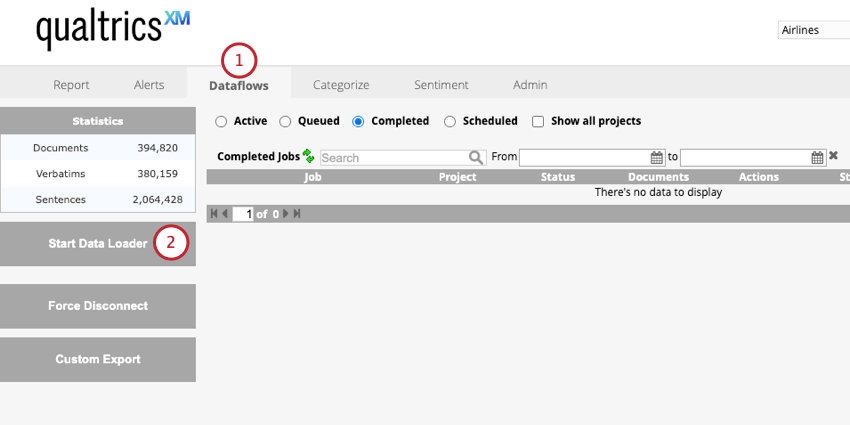
- Clique em Start Data Loader.
- Navegue até a seção Scheduled (Programado ) de Dataflows.
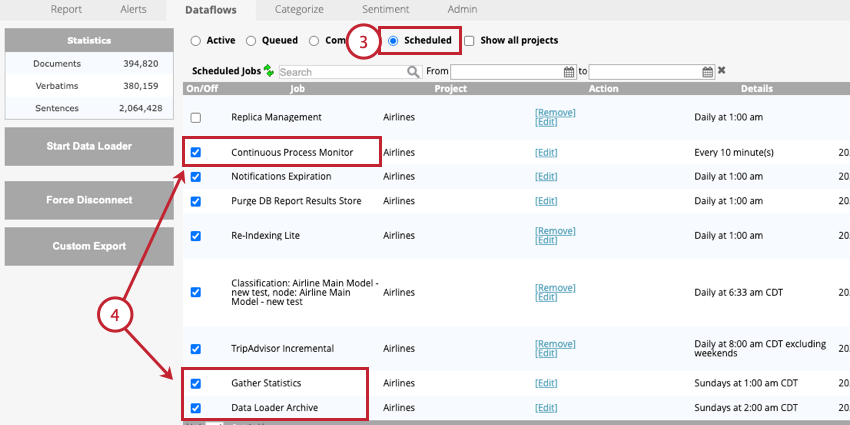
- Habilite os seguintes trabalhos:
- Monitor de processo contínuo: Este trabalho é obrigatório. Esse fluxo de dados executa periodicamente o downstream em tempo real para finalizar o processamento de dados.
- Arquivo do carregador de dados: Esse trabalho é opcional, mas altamente recomendado. Esse fluxo de dados arquiva registros que são processados pelo carregador de dados. Você deve atualizar a frequência desse trabalho para que corresponda à frequência do seu carregador de dados.
- Reunir estatísticas: Esse trabalho é opcional. Recomendamos a execução desse trabalho uma vez por semana. Esse fluxo de dados atualiza as seguintes estatísticas do projeto:
- O número total de documentos, verbatims e sentenças exibidos na guia Fluxos de dados.
- O número total de ocorrências de palavras exibidas na guia Sentimento.
Opções do carregador de dados
Depois que o carregador de dados for iniciado, você poderá gerenciar o trabalho com as seguintes opções: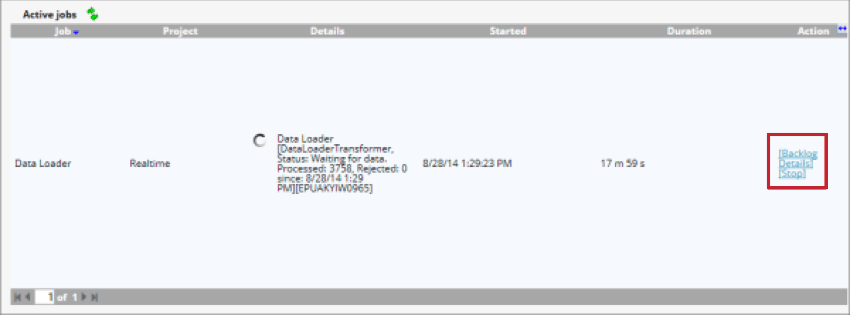
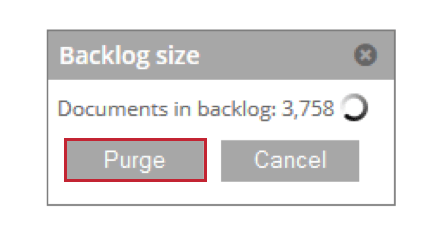
- Atraso: Mostra o número de documentos que estão esperando para serem processados. Você pode clicar em Purgar para remover esses documentos da tabela de preparação.
- Detalhes: Exibir detalhes sobre os documentos que foram ignorados devido às configurações de duplicação.
- Stop: Interrompe o processamento de dados com o carregador de dados.
Exclusão de dados do projeto
Você pode excluir os dados do seu projeto. Isso inclui verbatims e valores atributo estruturados. Ao excluir os dados do projeto, você pode excluir todos os dados carregados durante uma determinada sessão ou excluir todos os dados do projeto.
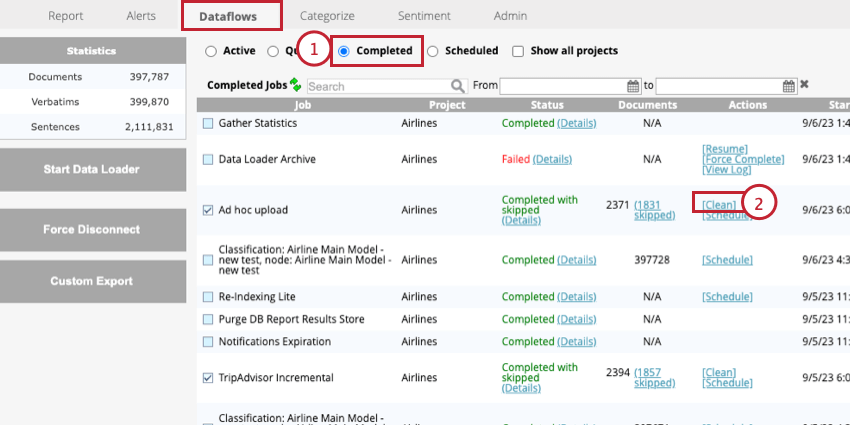
- Vá para a seção Concluído da guia Fluxos de dados.
- Clique em Limpar avançar do trabalho de upload ad hoc.
Isso excluirá todos os dados adicionados durante o upload selecionado.