Visão geral básica dos atributos
O que há nesta página
Sobre os atributos Visão geral básica
Um atributo é uma propriedade de um documento que o caracteriza de alguma forma. Exemplos comuns de atributos incluem o nome do autor e data de criação.
Você pode criar atributos personalizados para seus projetos. Há também uma variedade de atributos do sistema para você usar. Você também pode configurar entidades inteligentes que detectam automaticamente atributos com base no texto do documento (por exemplo, quando uma marca ou um produto é mencionado no feedback de um cliente).
Depois de adicionar atributos, é possível criar atributos derivados adicionais para entender melhor seus dados. Você também pode organizar seus atributos em conjuntos de atributo, facilitando a geração de relatórios sobre esses atributos.
Tipos de campos de Atributo
Os seguintes tipos de campo são compatíveis com os atributos:
- Texto
- Número
- Data
Acesso a atributos
Os atributos são gerenciados em um nível projeto. Para acessar os atributos de um projeto:
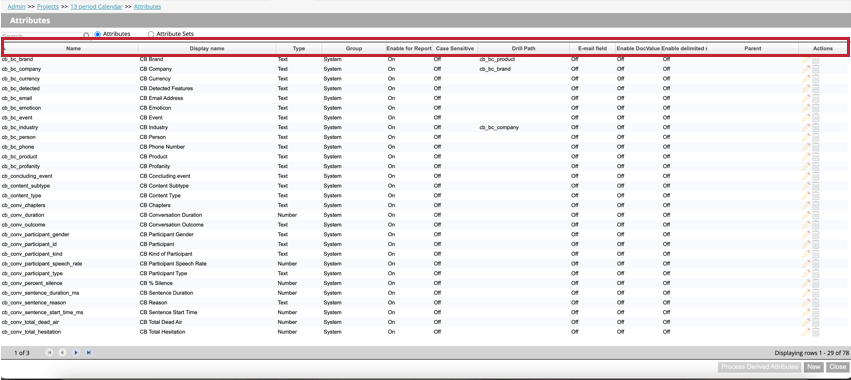
Isso abre a tabela de atributos que contém as seguintes informações sobre cada atributo do projeto:
{kind=link}
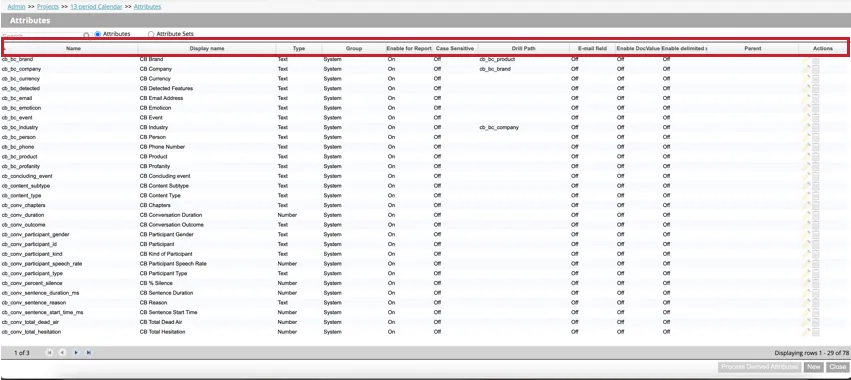
- Nome: O nome do sistema do atributo. Consulte Nomenclatura Atributo para obter informações sobre os requisitos de nomenclatura.
- Nome de exibição: O nome de exibição do atributo, que aparece em relatórios, filtros, etc. Consulte Nomenclatura Atributo para obter informações sobre os requisitos de nomenclatura.
- Tipo: O tipo do atributo. Para atributos padrão, os valores podem ser Texto, Número ou Data. Para atributos derivados, os valores podem ser Dimensional Lookup, Range Rollup, Satisfaction Score ou Derived From Category.
- Grupo: O grupo do atributo que representa sua origem e uso pretendido. Os valores são um dos seguintes:
- Derivado de categoria: atributos derivados de modelos ou categorias.
- Sistema: atributos do sistema.
- Definido pelo cliente: todos os atributos personalizados disponíveis na fonte de dados de sua opção de resposta (incluindo pesquisas dimensionais, roll-ups de intervalo e índices de satisfação).
- Tabela de pontuação: atributos usados na pontuação inteligente.
- Ativar para relatórios: Mostra se um atributo está habilitado para relatório (On) ou não (Off).
- Sensível a maiúsculas e minúsculas: Mostra se um atributo está marcado como sensível a maiúsculas e minúsculas ao exibir valores no Document Explorer, no Destacador de código-fonte, na Exportação personalizada e na exportação de visualização de sentenças.
- Drill Path (Caminho de perfuração): Mostra o caminho de perfuração personalizado, se ele tiver sido definido. Se não houver um caminho de perfuração personalizado, esse campo ficará em branco.
- Campo E-mail: Mostra se um atributo contém um endereço de e-mail.
- Habilitar DocValue: Mostra se os valores de documento do ElasticSearch são usados para esse atributo.
- Ativar multivalor delimitado: Mostra se vários valores estão ativados para esse atributo.
- Pai: se o atributo for um atributo derivado, esse campo exibirá “pai” Esse campo ficará em branco para atributos personalizados e padrão.
- Ações: Execute as seguintes ações no atributo:
- Editar o atributo
- Criar um atributo derivado
- Excluir o atributo
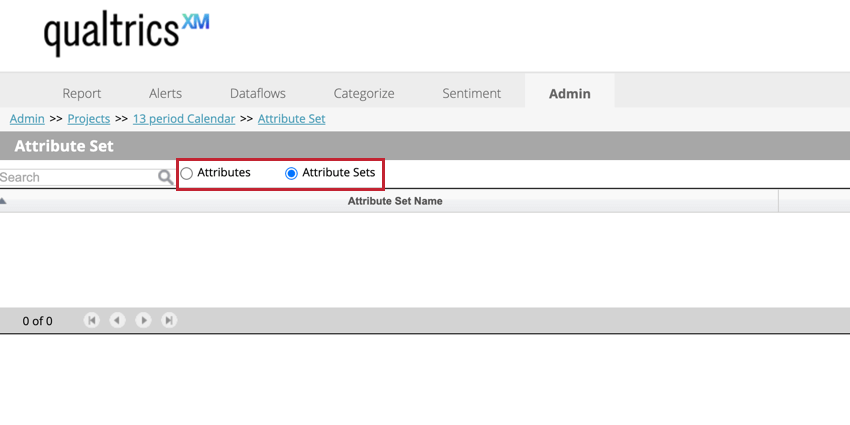
Gerenciamento de conjuntos Atributo
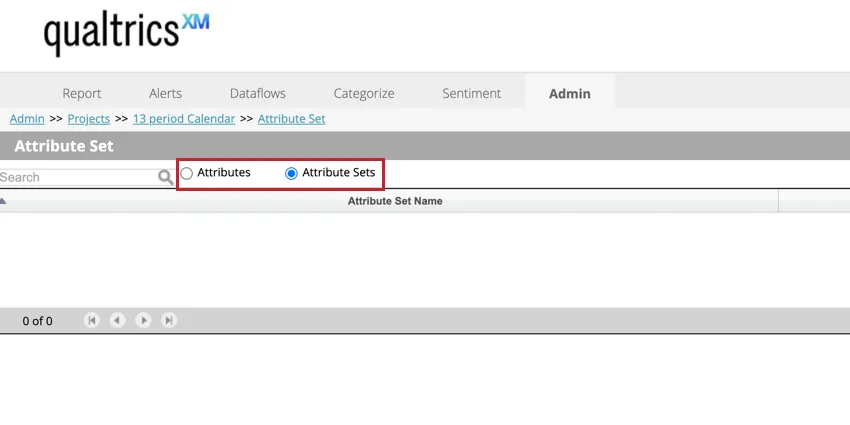
Use o botão de alternância Conjuntos Atributo na parte superior da página para visualizar seus conjuntos de atributo. Isso permite que você crie novos conjuntos de atributo e exclua os existentes. Selecione Attributes (Atributos ) para visualizar seus atributos individuais.
{kind=link}
Atributos do sistema
Há vários atributos do sistema, como Data do Documento e ID da Fonte, que são aplicados automaticamente a cada documento carregado no XM Discover. Esses atributos o ajudam a gerenciar o feedback no XM Discover, além de enriquecê-lo com dados XM derivados do mecanismo de NLP.
Abaixo está uma tabela dos diferentes atributos do sistema, agrupados pelas diferentes categorias de atributos. Essa tabela contém as seguintes informações sobre cada atributo:
- Nome: O nome atributo que aparece em relatórios, filtros, etc.
- Nome do sistema: O nome do sistema do atributo que você usa para consultar ou filtro seus dados.
- Type (Tipo): O tipo atributo.
- Descrição: Uma breve descrição do significado e da finalidade do atributo.
- Granularidade: O nível de granularidade de dados associado a um atributo. Por exemplo, a Contagem de palavras da frase só é relevante em nível frase, enquanto a Data do documento está disponível tanto para um documento quanto para cada frase desse documento.
IDs e referências
| Nome | Nome do sistema | Tipo | Descrição | Granularidade |
|---|---|---|---|---|
| ID do documento | _id_document | número | O ID exclusivo do sistema do documento. Ao contrário da ID natural, a ID do documento é gerada automaticamente pelo XM Discover. | documento e sentença |
| ID natural | natural_id | texto | A ID natural exclusiva do documento. Ao contrário do ID do documento, o ID natural é gerado a partir dos campos especificados quando você carrega um documento. A ID natural é usada na detecção de duplicar e também pode ser útil ao rastrear o documento até sua origem fora do XM Discover. | documento e sentença |
| ID da sentença | _id_sentence | número | O ID exclusivo da sentença. Essa ID é gerada automaticamente. | sentença |
| ID de sessão | _id_batch | número | O ID exclusivo da sessão de upload durante a qual o documento foi carregado no XM Discover. Essa ID é gerada automaticamente. | documento e sentença |
| ID da fonte | _id_source | texto | O nome da fonte de dados. Dependendo da fonte de dados, ele pode ser gerado automaticamente ou a partir dos campos especificados quando você faz o upload do documento. | documento e sentença |
| ID literal | _id_verbatim | número | A ID exclusiva do verbatim. Essa ID é gerada automaticamente. | literalmente e na sentença |
| Tipo Verbatim | _verbatimtype | texto | O nome do campo verbatim. Esse atributo permite distinguir sentenças por diferentes campos literais em seus dados. | literalmente e na sentença |
Data e hora
| Nome | Nome do sistema | Tipo | Descrição | Granularidade |
|---|---|---|---|---|
| CB Data de criação | cb_date_created_utc | data, hora da época em milissegundos | A data em que o documento foi adicionado ao XM Discover. Essa data é gerada automaticamente. | documento e sentença |
| Data de atualização do CB | cb_date_updated | data, hora da época em milissegundos | A data em que o documento foi atualizado pela última vez. As atualizações não incluem alterações de categorização. Essa data é gerada automaticamente. | documento |
| Data do documento | _doc_time | data, ISO 8601 em segundos | A data principal do documento. A data do documento é usada em relatórios, relatórios de tendências, alertas, etc. Essa data é gerada a partir dos campos especificados quando você faz o upload do documento. | documento e sentença |
| Data do documento sem hora | _doc_date | data, formato aaaa-mm-dd | A data do documento sem o registro de data e hora. Essa data é gerada a partir dos campos especificados quando você faz o upload do documento. | documento e sentença |
| Hora do dia | time_of_day | texto, formato hh:mm | A hora do documento, com rolagem até a hora. Por exemplo, os comentários postados às 9:09 e às 9:59 serão transferidos para as 9:00. Esse atributo é gerado automaticamente. | documento e sentença |
Contagem de palavras e posição
| Nome | Nome do sistema | Tipo | Descrição | Granularidade |
|---|---|---|---|---|
| Contagem de palavras do documento CB | cb_document_word_count | número | O número de palavras em um documento. A contagem de palavras do documento é a soma de todas as contagens de palavras das frases. | documento e sentença |
| Quartil da Sentença CB | cb_sentence_quartile | número | A parte do verbatim em que uma frase se enquadra. Esse atributo pode ter um dos seguintes valores: 1, 2, 3 ou 4. Cada seção representa 25% do comprimento total do verbatim. | sentença |
| CB Sentença Contagem de palavras | cb_sentence_word_count | número | O número de palavras em uma frase. | sentença |
Isso é ótimo! Obrigado pelo seu feedback!
Obrigado pelo seu feedback!