-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Conector de entrada do Twitter
Sobre o Twitter Inbound Connector
Você pode usar o conector de entrada do Twitter para carregar tweets públicos e menções do Twitter no XM Discover.
Configuração de um trabalho de entrada no Twitter
Qdica: a permissão “Manage Jobs” (Gerenciar trabalhos) é necessária para usar esse característica.
- Na página Jobs, clique em New Job (Novo trabalho).
- Selecione Twitter.

- Dê um nome ao seu trabalho para que você possa identificá-lo.
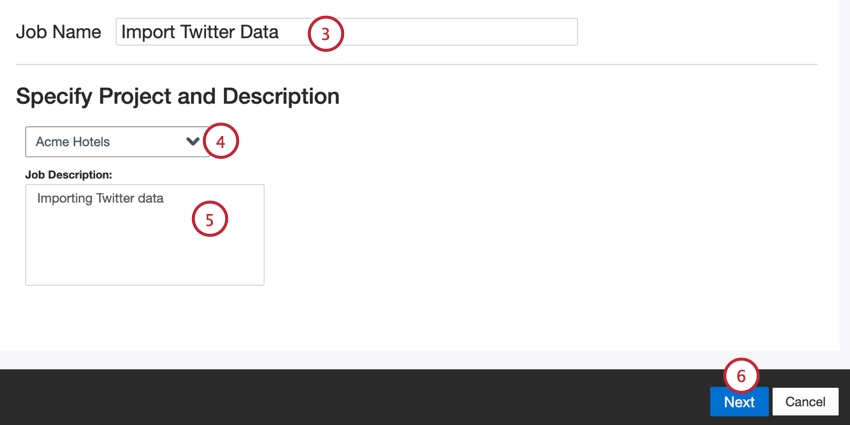
- Escolha o projeto para carregar os dados.
- Faça uma descrição do seu trabalho para que você saiba o propósito dele.
- Clique em Seguinte.
- Insira uma consulta do Twitter, que pode ser criada usando as consultas de pesquisa avançada do Twitter. XM Discover recuperará tweets e menções públicas que correspondam aos seus critérios de pesquisa.
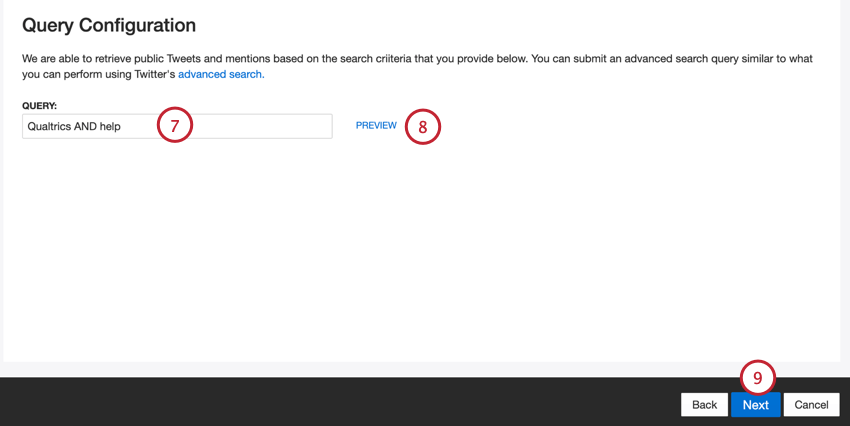
- Clique em Preview para testar sua consulta. Isso abrirá os resultados da pesquisa em uma nova guia do navegador.
- Clique em Seguinte.
- Se necessário, ajuste seus mapeamentos de dados. Consulte a página de suporte do Mapeamento de dados para obter informações detalhadas sobre o mapeamento de campos no XM Discover. A seção Mapeamento de dados padrão contém informações sobre os campos específicos desse conector.
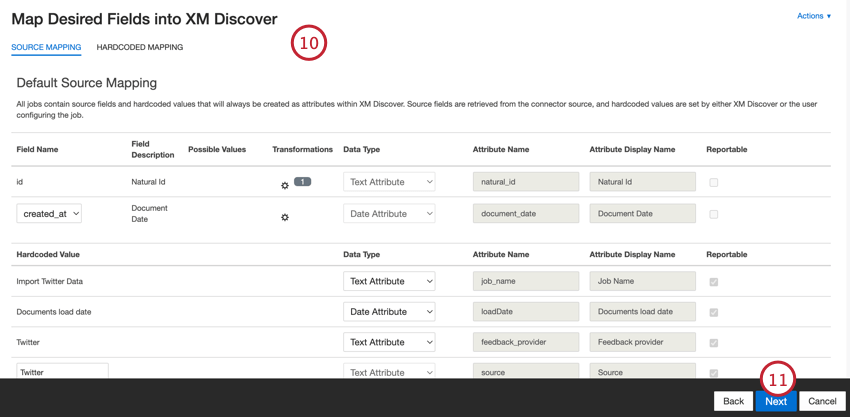
- Clique em Avançar.
- Se desejar, você pode adicionar regras de substituição e redação de dados para ocultar dados confidenciais ou substituir automaticamente determinadas palavras e frases no feedback e nas interações do cliente. Consulte a página de suporte de Substituição e Redação de Dados.
 Qdica: clique em Download Amostra Data (Baixar dados de amostra ) para baixar um arquivo Excel com dados amostra para seu computador.
Qdica: clique em Download Amostra Data (Baixar dados de amostra ) para baixar um arquivo Excel com dados amostra para seu computador. - Clique em Seguinte.
- Se desejar, você pode adicionar um filtro de conector para filtro os dados de entrada e limitar os dados importados.
- Também é possível limitar o número de registros importados em um único trabalho inserindo um número na caixa Specify Record Limit (Especificar limite de registros ). Digite “All” se quiser importar todos os registros.
- Clique em Seguinte.
- Escolha quando você gostaria de ser notificado. Consulte Notificações de trabalho para obter mais informações.

- Clique em Seguinte.
- Escolha como os documentos duplicar são tratados. Consulte Tratamento de Duplicar para obter mais informações.
- Selecione Schedule Incremental Runs (Agendar execuções incrementais ) se quiser que o trabalho seja executado periodicamente em uma programação ou Set Up One-Time Pull (Configurar execução única ) se quiser que o trabalho seja executado apenas uma vez. Consulte Agendamento de trabalhos para obter mais informações.
- Clique em Seguinte.
- Revise sua configuração. Se você precisar alterar uma configuração específica, clique no botão Edit (Editar ) para ser levado a essa etapa na configuração do conector.
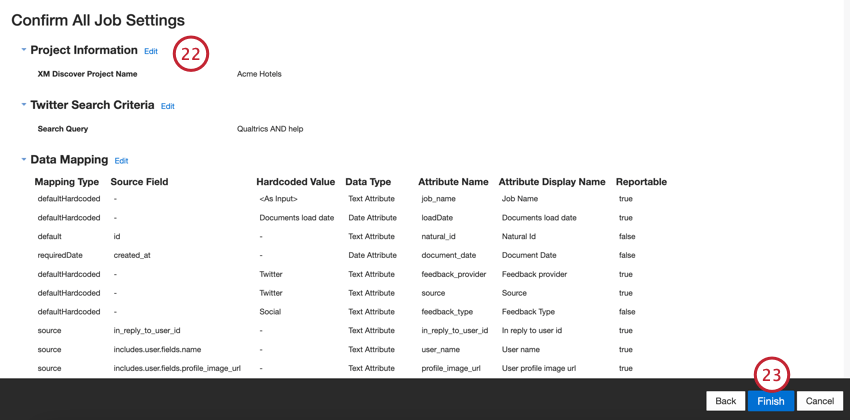
- Clique em Finish (Concluir ) para salvar o trabalho.
Mapeamento de dados padrão
Esta seção contém informações sobre os campos padrão dos trabalhos de entrada do Twitter.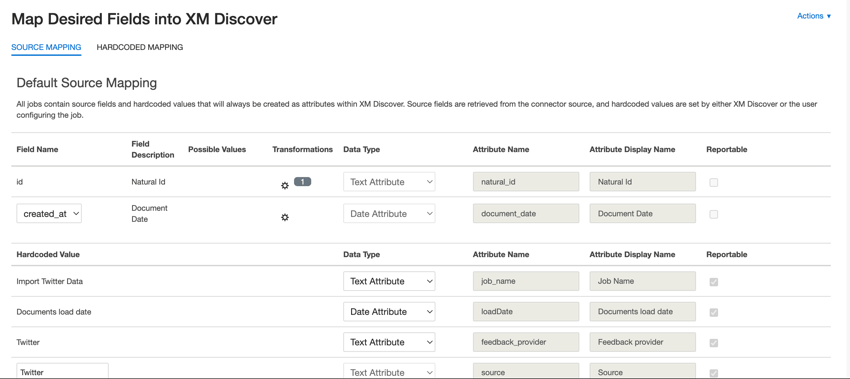
- natural_id: Um identificador exclusivo de um documento. É altamente recomendável ter um ID exclusivo para cada documento para processar as duplicatas corretamente. Para Natural ID, você pode selecionar qualquer campo de texto ou numérico de seus dados. Como alternativa, você pode gerar IDs automaticamente adicionando um campo personalizado.
- tweet_id: Um identificador exclusivo para um tweet no serviço do Twitter. Esses IDs podem ser usados para rastrear o tweet original para diversas finalidades, incluindo a possibilidade de responder às menções de sua organização por meio do Qualtrics Social Connect.
- document_date: o campo de data primária associado a um documento. Essa data é usada nos relatórios, tendências e alertas XM Discover, entre outros. Por padrão, isso é mapeado para a data em que o tweet foi criado. Você pode escolher uma das seguintes opções:
- created_at (padrão): A data e a hora em que o tweet foi criado.
- created_at: A data e a hora em que a conta do usuário foi criada no Twitter.
- Você também pode definir uma data específica para o documento.
- feedback_provider: Identifica os dados obtidos de um provedor específico. Para tweets, o valor desse atributo é definido como “Twitter” e não pode ser alterado.
- source_value: Identifica os dados obtidos de uma fonte específica. Isso pode ser qualquer coisa que descreva a origem dos dados, como o nome de uma pesquisa ou de uma campanha de marketing móvel. Por padrão, o valor desse atributo é definido como “Twitter” Use transformações personalizadas para definir um valor personalizado, definir uma expressão ou mapeá-lo para outro campo.
- feedback_type: Identifica os dados com base em seu tipo. Isso é útil para a geração de relatórios quando o seu projeto contém diferentes tipos de dados (por exemplo, pesquisas e feedback de mídia social). Por padrão, o valor desse atributo é definido como “Social”. Use transformações personalizadas para definir um valor personalizado, definir uma expressão ou mapeá-lo para outro campo.
- job_name: Identifica os dados com base no nome do trabalho usado para carregá-los. Você pode modificar o valor desse atributo durante a configuração por meio do campo Job Name (Nome do trabalho ), exibido na parte superior de cada página durante a configuração.
- loadDate: indica quando um documento foi carregado no XM Discover. Esse campo é definido automaticamente e não pode ser alterado.