-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Conector de entrada de arquivos
Sobre o conector de entrada de arquivos
Você pode usar o conector de entrada de arquivos para carregar os dados do cliente por meio de um upload de arquivo. Esses trabalhos podem ser programados para serem repetidos em um cronograma definido por você ou configurados para serem uma única extração de dados.
Os trabalhos de entrada de arquivos permitem que você carregue dados nos seguintes formatos:
- Arquivos de texto plano delimitado (CSV, TSV, etc.)
- XLS ou XLSX
- JSON
- WebVTT
Configuração de um trabalho de entrada de arquivos
- Na página Jobs, clique em New Job (Novo trabalho).
- Selecione Arquivos.
- Dê um nome ao seu trabalho para que você possa identificá-lo.
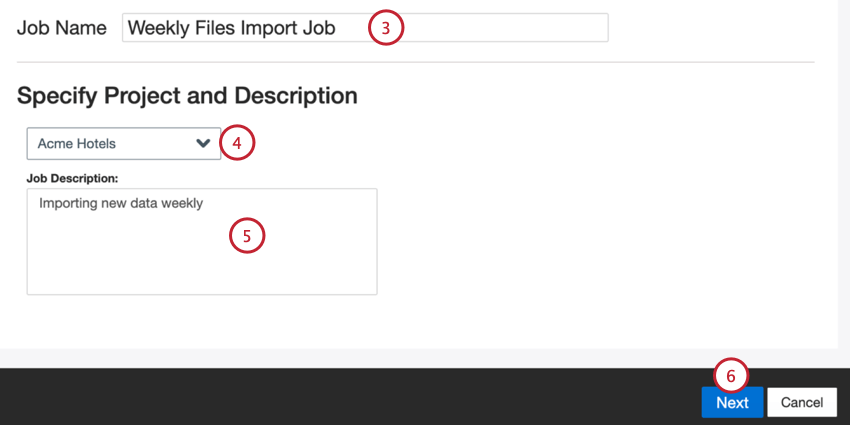
- Escolha o projeto para carregar os dados.
- Faça uma descrição do seu trabalho para que você saiba o propósito dele.
- Clique em Seguinte.
- Escolha uma conta SFTP a ser usada ou selecione Add New (Adicionar nova ) para adicionar uma nova conta.
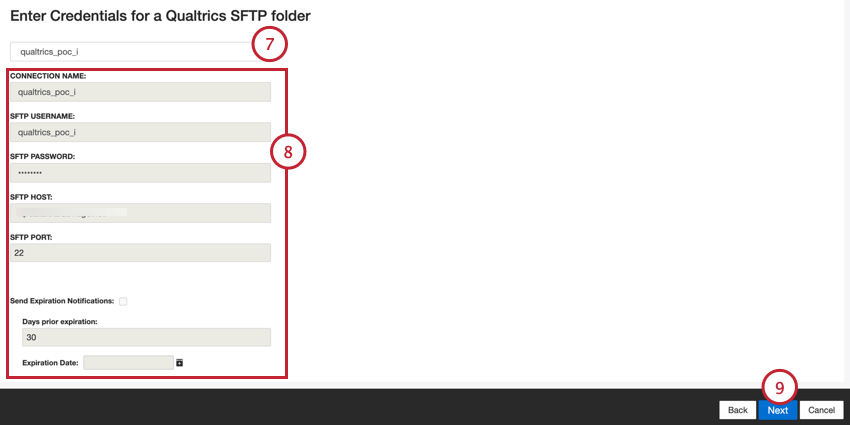
- Se estiver adicionando uma nova conta, insira as seguintes informações para sua conta SFTP:
- Nome da conexão: Dê um nome à conexão para que você possa reconhecê-la mais tarde.
- SFTP Username (Nome de usuário SFTP): Digite o nome de usuário para se conectar ao seu servidor SFTP.
- SFTP Password (Senha SFTP): Digite a senha para se conectar ao seu servidor SFTP.
- Host SFTP: Digite o URL do host do servidor SFTP.
- Porta SFTP: digite sua porta SFTP. Geralmente são 22.
- Enviar notificações de expiração: Se você quiser que suas credenciais SFTP expirem após um determinado período de tempo, selecione essa opção.
- Dias antes da expiração: Se estiver ativando as notificações de expiração, insira quantos dias você gostaria de ser notificado antes da expiração. Você pode inserir um valor entre 1 e 100 dias.
- Data de expiração: Defina a data em que as credenciais expirarão. Clique na caixa para abrir um calendário e escolher a data.
- Clique em Seguinte.
- Escolha o tipo de arquivo que deseja carregar:
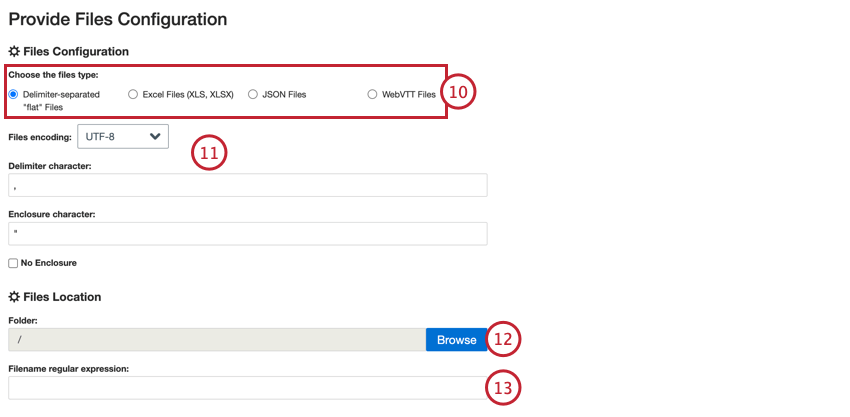
- Arquivos “planos” separados por delimitadores
- Arquivos do Excel (XLS, XLSX)
- Arquivos JSON
- Arquivos WebVTT
- Dependendo do tipo de arquivo selecionado, há configurações adicionais para você escolher:
- Arquivos simples separados por delimitadores: Para arquivos separados por delimitadores, escolha o seguinte:
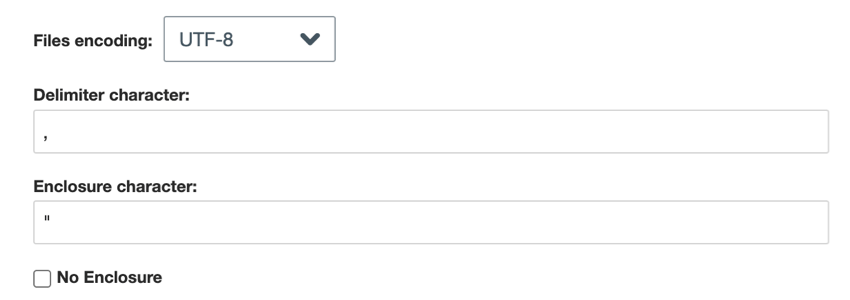
- Codificação do arquivo: Escolha o sistema de codificação do arquivo (UTF-8, ASCII, etc.)
- Caractere delimitador: Digite o caractere usado para delimitar as entradas de dados. Por padrão, é uma vírgula para arquivos CSV.
- Caractere de fechamento: Digite o caractere que envolve a entrada de dados. Deixe esse campo em branco se a opção Nenhum compartimento for selecionada.
- No enclosure: ative essa opção se o seu arquivo não contiver caracteres de delimitação.
- JSON: insira o caminho JSON que contém os dados do documento que você deseja carregar no XM Discover. Deixe esse campo em branco se seus documentos estiverem no nível raiz.

- Pule para a avançar etapa no caso do Excel e do WebVTT.
- Arquivos simples separados por delimitadores: Para arquivos separados por delimitadores, escolha o seguinte:
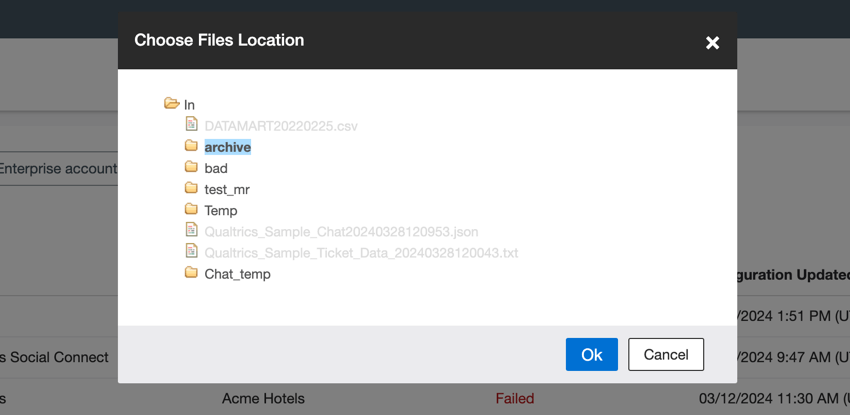
- Clique em Browse e escolha o caminho da pasta em seu servidor SFTP que contém o arquivo que você deseja carregar.
Qdica: ao escolher um caminho de pasta, você pode clicar no ícone de uma pasta para expandi-la. Clique no nome da pasta para selecioná-la e, em seguida, clique em Ok quando terminar.
- Digite a expressão regular de nome de arquivo que corresponde aos arquivos que você deseja carregar.
- Se seus arquivos estiverem compactados, ative Descompactar arquivo(s) e insira a expressão regular Zipped Filename que corresponde aos arquivos que devem ser descompactados.
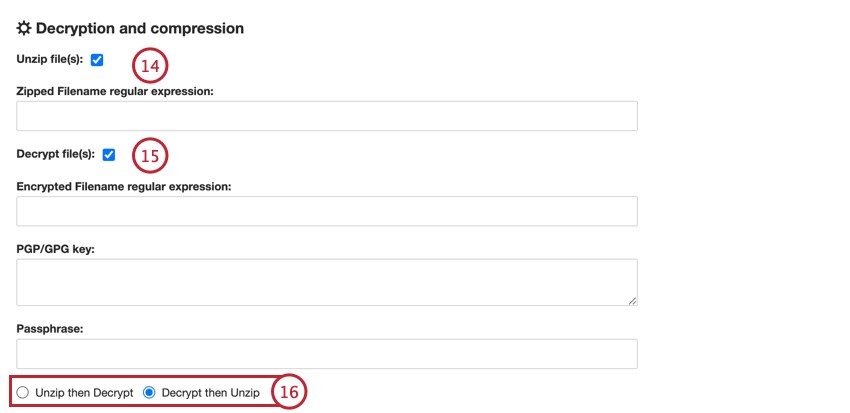
- Se seus arquivos estiverem descriptografados, ative a opção Decrypt file(s) e digite o seguinte:
- Expressão regular de nome de arquivo criptografado: Digite a expressão regular do nome do arquivo para os arquivos que devem ser descriptografados.
- Chave PGP/GPG: Digite a chave PGP/GPG usada para criptografia.
- Passphrase (Senha): Digite a frase secreta para descriptografia.
- Se seus arquivos estiverem compactados e criptografados, você deverá escolher o que deve acontecer primeiro:
- Descompacte e depois descriptografe: Os arquivos são descompactados e depois descriptografados.
- Descriptografar e depois descompactar: Os arquivos são descriptografados e depois descompactados.
- Escolha o tipo de dados que você deseja importar:
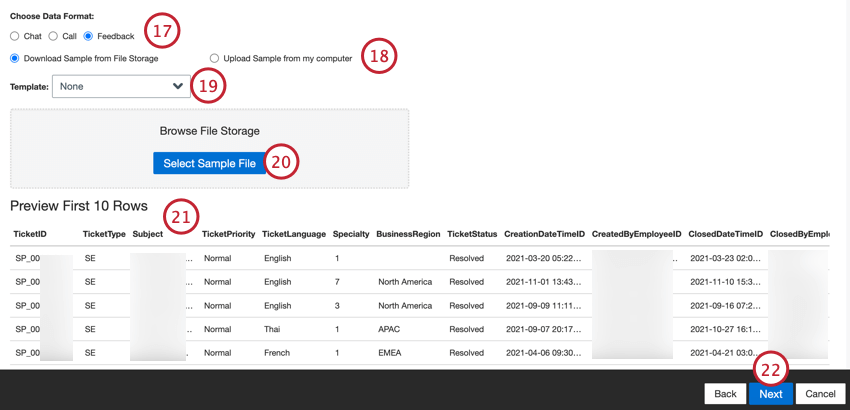
- Bate-papo: Interações digitais com várias linhas de diálogo entre dois ou mais participantes.
- Chamada: Transcrições de chamadas com várias linhas de diálogo entre dois ou mais participantes.
- Comentários: Documentos apresentados como objetos de uma única linha ou “planos”.
Qdica: dependendo do tipo de arquivo, alguns tipos de dados não são compatíveis. Por exemplo, os arquivos WebVTT só podem ser usados para carregar transcrições de chamadas.
- Você deve fornecer um arquivo amostra, que pode ser salvo em seu computador ou em seu servidor SFTP:
- Selecione Download Amostra from File Storage (Baixar amostra do armazenamento de arquivos) se o arquivo amostra estiver salvo em seu servidor SFTP.
- Selecione Carregar amostra do meu computador se a amostra estiver salva em seu computador.
- Se necessário, você pode selecionar um arquivo de modelo para download. Clique no link aqui para fazer o download do modelo selecionado. Use esse arquivo para adicionar os dados que você deseja importar para o XM Discover. Consulte a página de suporte XM Discover Data Formats para obter informações específicas sobre a formatação de cada arquivo e tipo de dados.
- Clique no botão Select Amostra File (Selecionar arquivo de amostra ) e escolha o arquivo amostra em seu computador ou em seu servidor SFTP.
- Será exibida uma visualização do arquivo. Se você vir uma mensagem de erro ou o conteúdo do arquivo bruto em vez da visualização, pode haver um problema com as opções de formato de dados que você selecionou. Consulte a página Erros do arquivo Amostrapara obter ajuda na solução de problemas do arquivo.
- Clique em Seguinte.
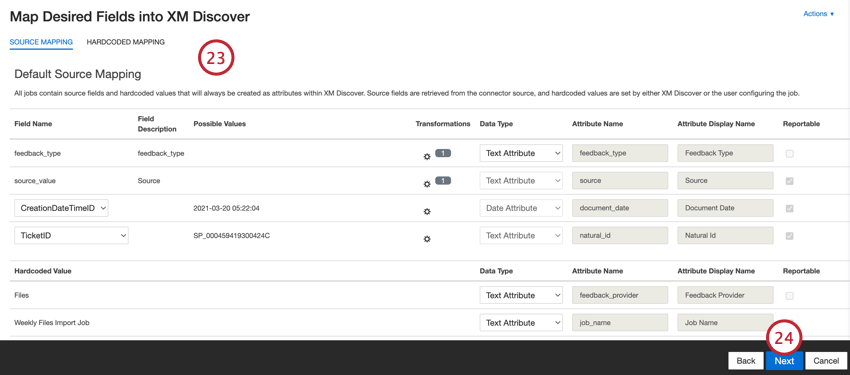
- Se necessário, ajuste seus mapeamentos de dados. Consulte a página de suporte do Mapeamento de dados para obter informações detalhadas sobre o mapeamento de campos no XM Discover. A seção Default Data Mapping (Mapeamento de dados padrão ) contém informações sobre os campos específicos desse conector e a seção Mapping Conversational Fields (Mapeamento de campos de conversação) aborda como mapear dados para dados de conversação.
- Clique em Seguinte.
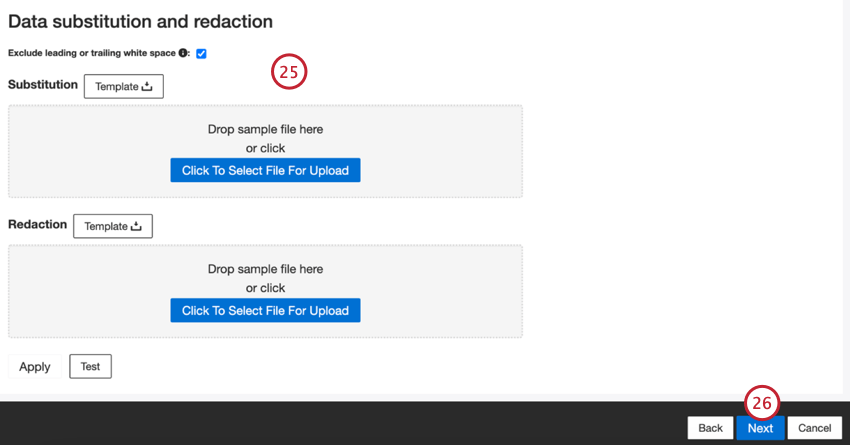
- Se desejar, você pode adicionar regras de substituição e redação de dados para ocultar dados confidenciais ou substituir automaticamente determinadas palavras e frases no feedback e nas interações do cliente. Consulte a página de suporte de Substituição e Redação de Dados para obter mais informações.
- Clique em Seguinte.
- Se desejar, você pode adicionar um filtro de conector para filtro os dados de entrada e limitar os dados importados.
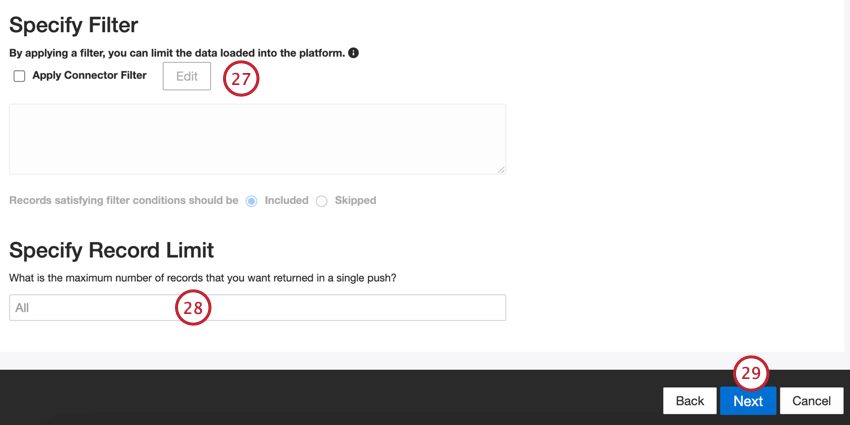
- Também é possível limitar o número de registros importados em um único trabalho inserindo um número na caixa Specify Record Limit (Especificar limite de registros ). Digite “All” se quiser importar todos os registros.
Qdica: para dados de conversação, o limite é aplicado com base em conversações e não em linhas.
- Clique em Seguinte.
- Escolha quando você gostaria de ser notificado. Consulte Notificações de trabalho para obter mais informações.

- Clique em Seguinte.
- Escolha como os documentos duplicar são tratados. Consulte Tratamento de Duplicar para obter mais informações.
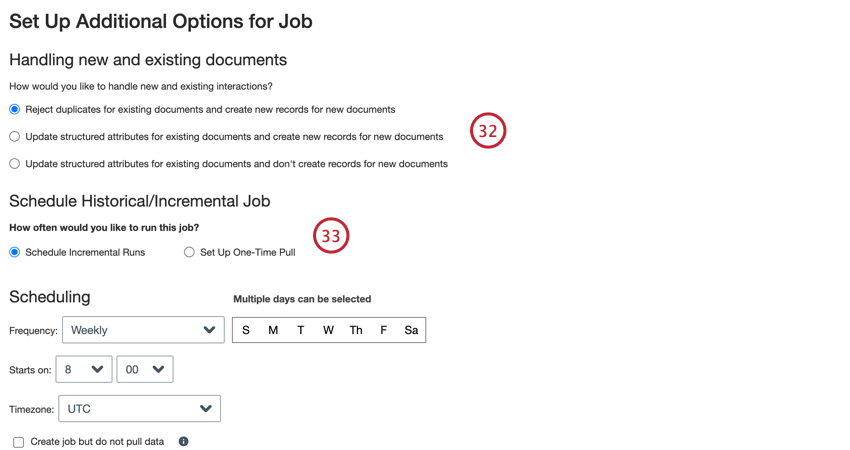
- Selecione Schedule Incremental Runs (Agendar execuções incrementais ) se quiser que o trabalho seja executado periodicamente em uma programação ou Set Up One-Time Pull (Configurar execução única ) se quiser que o trabalho seja executado apenas uma vez. Consulte Agendamento de trabalhos para obter mais informações.
- Escolha um período de retenção para arquivos processados. Os arquivos são excluídos após o período definido.
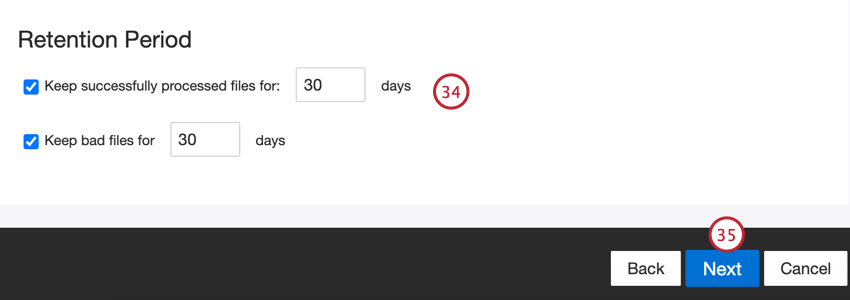
- Clique em Seguinte.
- Revise sua configuração. Se você precisar alterar uma configuração específica, clique no botão Edit (Editar ) para ser levado a essa etapa na configuração do conector.
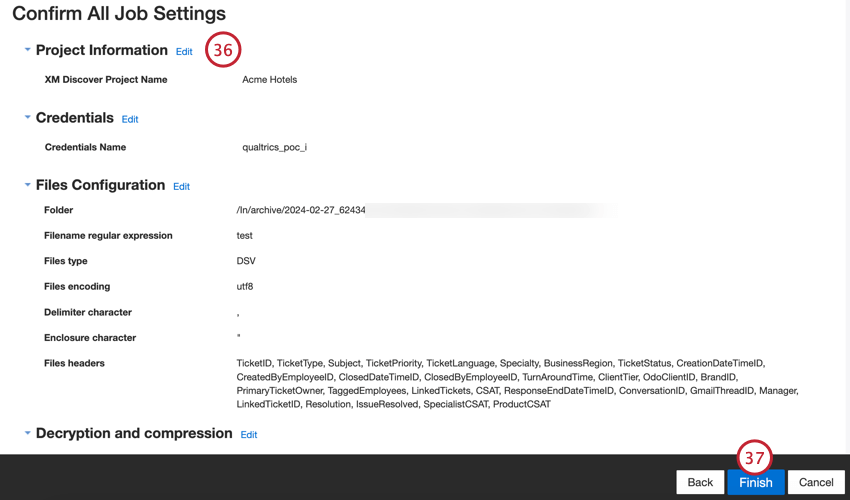
- Clique em Finish (Concluir ) para salvar o trabalho.
Mapeamento de dados padrão
Esta seção contém informações sobre os campos padrão para trabalhos de entrada de arquivos.
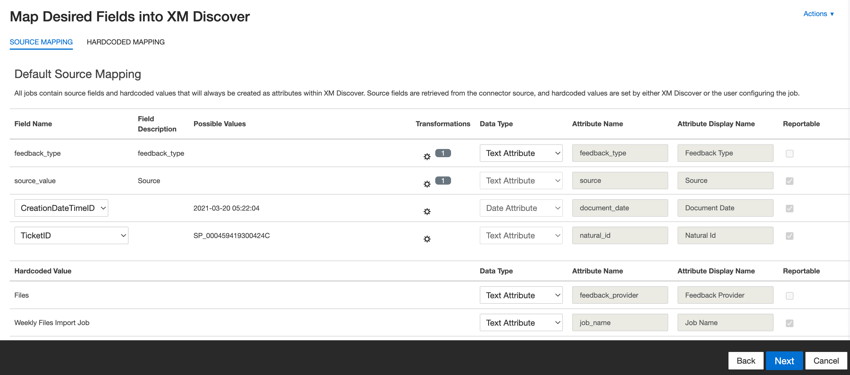
- feedback_type: Identifica os dados com base em seu tipo. Isso é útil para a geração de relatórios quando o seu projeto contém diferentes tipos de dados (por exemplo, pesquisas e feedback de mídia social). Por padrão, o valor desse atributo é definido como “call” para transcrições de chamadas, “chat” para interações digitais ou “feedback” para feedback individual. Use transformações personalizadas para definir um valor personalizado, definir uma expressão ou mapeá-lo para outro campo.
- source_value: Identifica os dados obtidos de uma fonte específica. Isso pode ser qualquer coisa que descreva a origem dos dados, como o nome de uma pesquisa ou de uma campanha de marketing móvel. Por padrão, o valor desse atributo é definido como “Files” Use transformações personalizadas para definir um valor personalizado, definir uma expressão ou mapeá-lo para outro campo.
- document_date: o campo de data primária associado a um documento. Essa data é usada nos relatórios, tendências e alertas XM Discover, entre outros. Você pode usar qualquer campo de data em seu conjunto de dados para a data do documento. Você também pode definir uma data específica para o documento.
- natural_id: Um identificador exclusivo de um documento. É altamente recomendável ter um ID exclusivo para cada documento para processar as duplicatas corretamente. Para Natural ID, você pode selecionar qualquer campo de texto ou numérico de seus dados. Como alternativa, você pode gerar IDs automaticamente adicionando um campo personalizado.
- feedback_provider: Identifica os dados obtidos de um provedor específico. Para uploads de arquivos, o valor desse atributo é definido como “Files” e não pode ser alterado.
- job_name: Identifica os dados com base no nome do trabalho usado para carregá-los. Você pode modificar o valor desse atributo durante a configuração por meio do campo Job Name (Nome do trabalho ), exibido na parte superior de cada página durante a configuração.
- loadDate: indica quando um documento foi carregado no XM Discover. Esse campo é definido automaticamente e não pode ser alterado.
Atualização da configuração Amostra
Os conectores de entrada de arquivos exigem um arquivo amostra para gerar mapeamentos de dados. Se você quiser alterar os mapeamentos de dados depois de criar um trabalho, faça o seguinte:
- Desmapeie os campos que não estão presentes no novo arquivo amostra.
- Atualize a configuração amostra fazendo upload de um novo arquivo amostra com um novo conjunto de campos. As etapas para atualizar a configuração amostra estão abaixo.
- Atualize os mapeamentos de dados de acordo com o novo arquivo amostra.
Atualização da configuração amostra
- No menu de opções do trabalho, selecione Update Amostra Configuration (Atualizar configuração de amostra ) para um trabalho de arquivos existente.
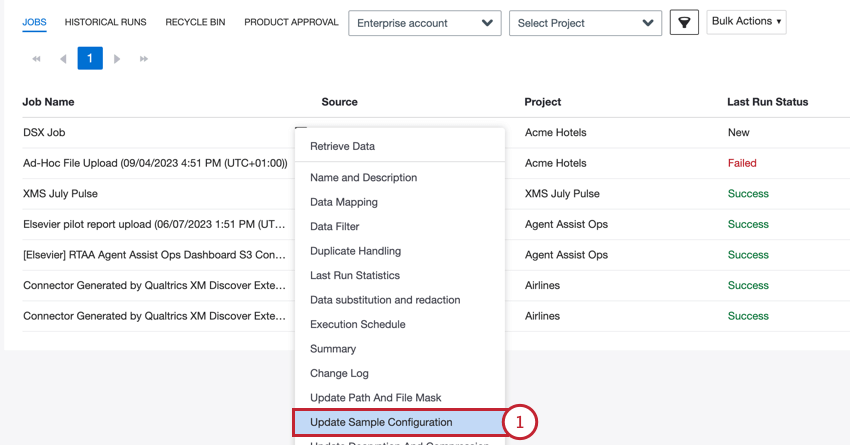
- Selecione Click To Select File For Upload e escolha o arquivo amostra salvo em seu computador.
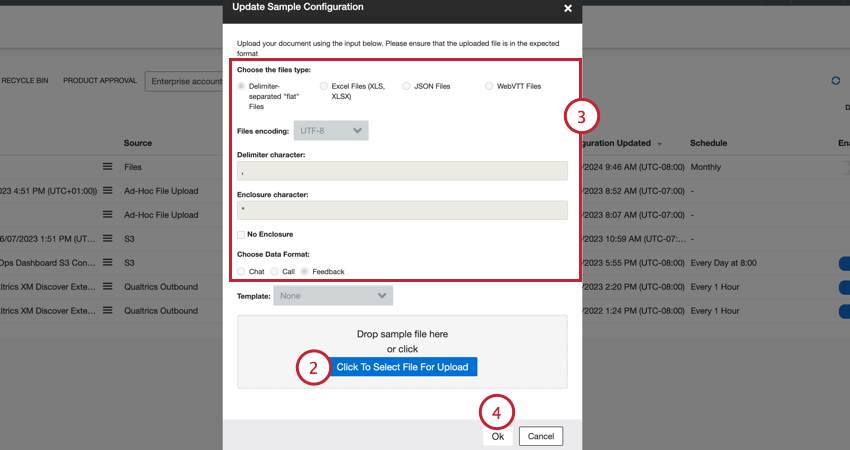 Qdica: se o arquivo contiver campos que não estão no mapeamento de dados, você receberá um erro. Para corrigir esse problema, edite o mapeamento de dados para que ele tenha os mesmos campos do arquivo amostra.
Qdica: se o arquivo contiver campos que não estão no mapeamento de dados, você receberá um erro. Para corrigir esse problema, edite o mapeamento de dados para que ele tenha os mesmos campos do arquivo amostra. - Verifique novamente suas configurações de arquivo. Consulte a página do conector de entrada de arquivos para obter mais informações sobre as configurações amostra arquivos de amostra.
- Clique em Ok.
Atualização do caminho e da máscara de arquivo
Os conectores de entrada de arquivos exigem um caminho e uma máscara de arquivo (expressão regular de nome de arquivo) para encontrar os arquivos certos a serem importados. Você pode atualizar o caminho e a máscara de arquivo para qualquer trabalho de arquivo existente.
- No menu de opções de trabalho, selecione Atualizar caminho e máscara de arquivo para um trabalho de arquivos existente.
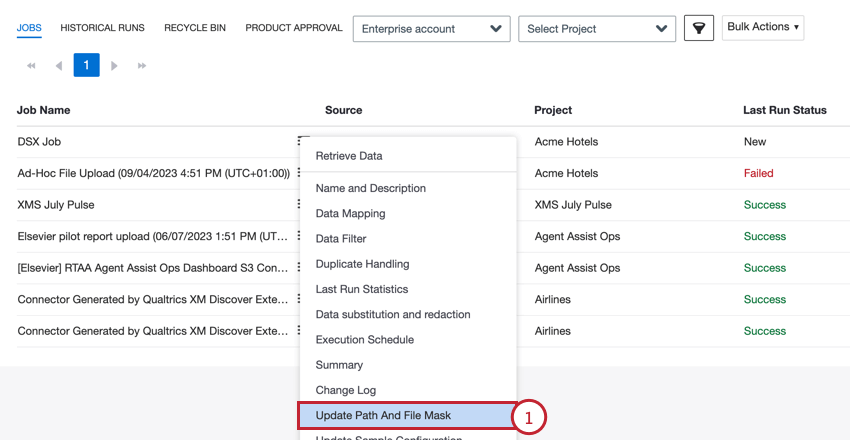
- Clique em Browse.
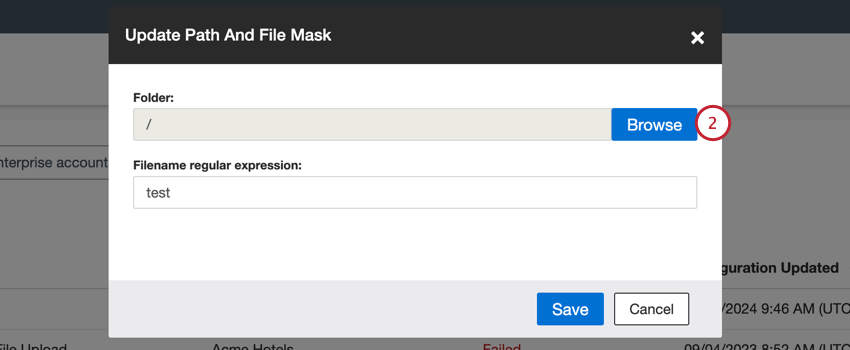
- Selecione a pasta onde os arquivos estão armazenados.
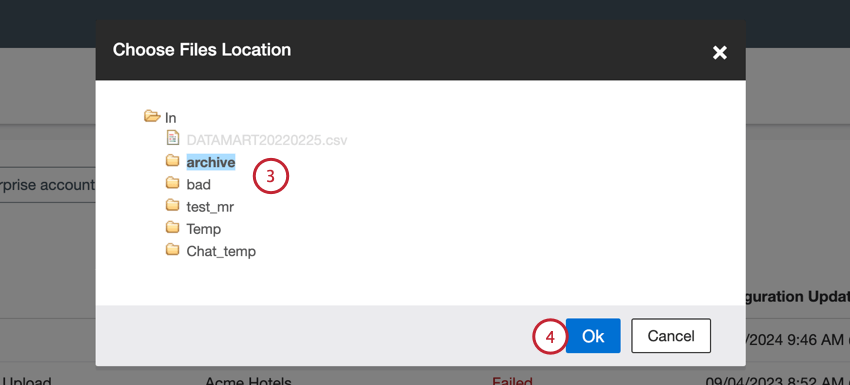 Atenção: Somente os arquivos da pasta selecionada são processados; as subpastas precisam ser processadas separadamente.
Atenção: Somente os arquivos da pasta selecionada são processados; as subpastas precisam ser processadas separadamente. - Clique em Ok.
- No campo Filename regular expression(Expressão regular de nome de arquivo), digite a máscara de arquivo (expressão regular de nome de arquivo) que corresponde aos arquivos que você gostaria de importar.
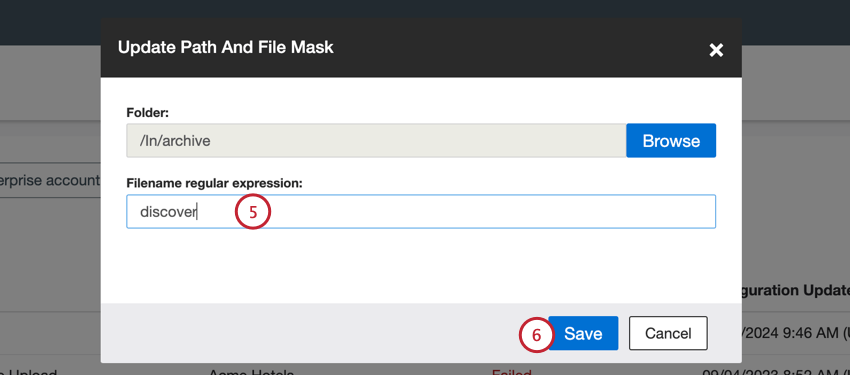
- Clique em Salvar.
Cifras de troca de chaves compatíveis com o XM Discover
A conexão a um servidor SFTP requer uma série de handshakes SSH para coordenar a criptografia usada entre o servidor e a automação. Para estabelecer uma conexão, o servidor SFTP precisará ter pelo menos uma cifra para cada tipo de cifra que corresponda a uma cifra suportada por automações. Abaixo está a lista de cifras suportadas por automações agrupadas pelo tipo de cifra.
Aqui está uma lista de cifras de troca de chaves suportadas pelos servidores SFTP XM Discover:
- diffie-hellman-group14-sha256
- diffie-hellman-group18-sha512
- ecdh-sha2-nistp256
- ecdh-sha2-nistp384
- ecdh-sha2-nistp521
- curve25519-sha256
- curve25519-sha256@libssh.org
- diffie-hellman-group16-sha512
- ecdh-nistp256-kyber-512r3-sha256-d00@openquantumsafe.org
- ecdh-nistp384-kyber-768r3-sha384-d00@openquantumsafe.org
- ecdh-nistp521-kyber-1024r3-sha512-d00@openquantumsafe.org
- x25519-kyber-512r3-sha256-d00@amazon.com