Predict iQ
O que há nesta página
Atenção: Você está lendo sobre um característica ao qual nem todos os usuários têm acesso. Se estiver interessado nesse característica, contato o Executivo Conta para verificar se está qualificado.
Sobre a Predict iQ
Quando os clientes deixam uma empresa, geralmente somos pegos de surpresa. Se soubéssemos que esse cliente estava em risco, talvez pudéssemos ter entrado em contato com ele antes que perdesse totalmente a confiança em nós. Se ao menos houvesse uma maneira de prever a probabilidade de um cliente se desligar (deixar a empresa).
Predict iQ aprende com as respostas dos entrevistados pesquisa e com dados integrados para prever se o entrevistado acabará cancelando. Então, quando novas respostas pesquisa forem recebidas, Predict iQ poderá prever a probabilidade de esses respondentes pesquisa mudarem de marca no futuro. Para prever se um cliente vai cancelar, Predict iQ usa Redes Neurais (um subconjunto delas é chamado de Deep Learning) e Regressão para criar modelos candidatos. Ele experimenta variações desses modelos diferentes para cada conjunto de dados e, em seguida, escolhe o modelo que melhor se ajusta aos dados.
Preparando seus dados
Antes de criar um modelo de previsão de rotatividade, você precisa ter certeza de que seus dados estão prontos.
Predict iQ funciona melhor quando você tem pelo menos 500 entrevistados que mudaram de empresa. No entanto, 5.000 respondentes agitados ou mais lhe trarão os melhores resultados.
Configuração de uma variável de rotatividade
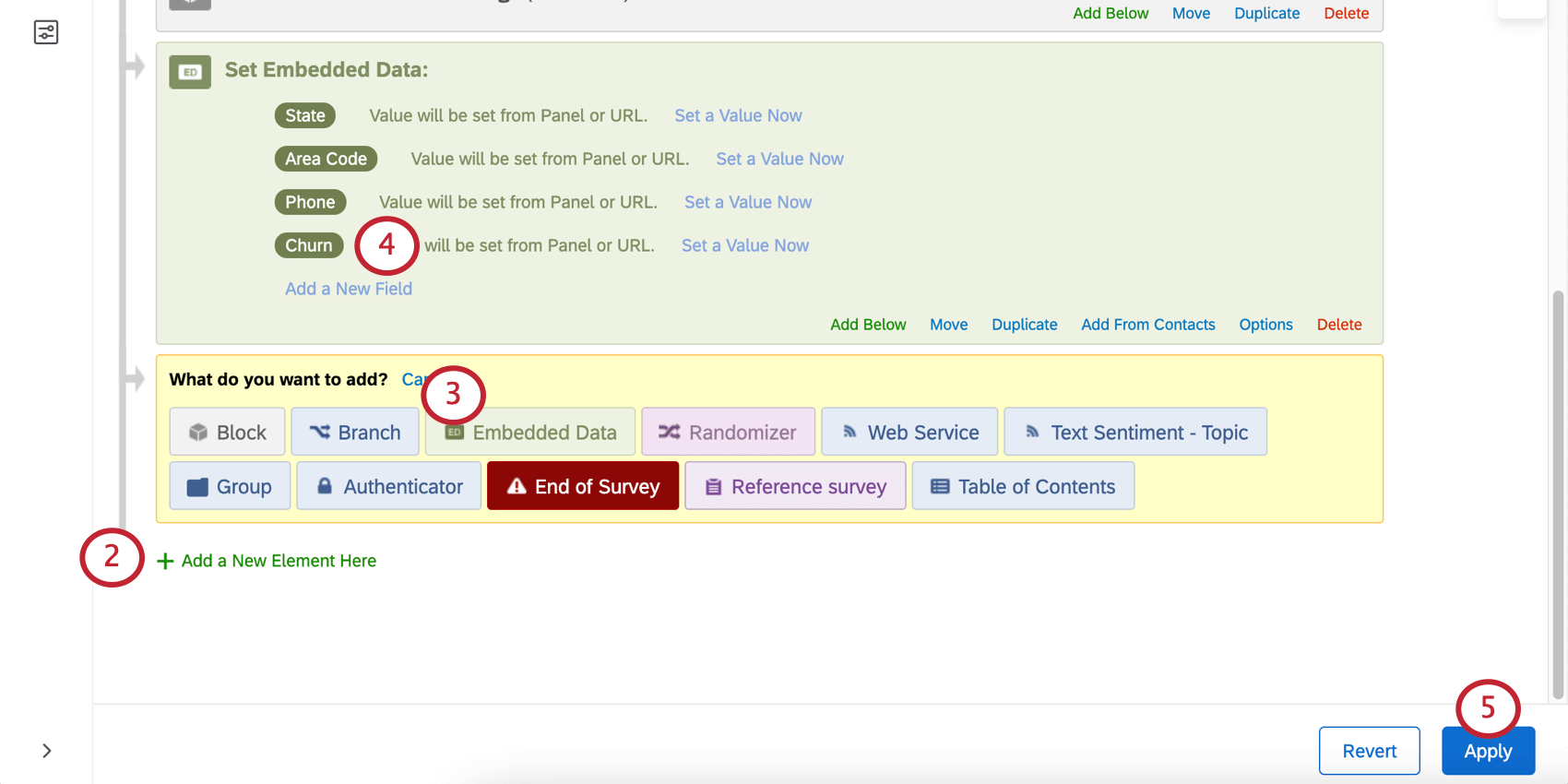
Registro de dados
Depois de ter uma variável de rotatividade, é possível importar dados históricos para o seu pesquisa, incluindo uma coluna para rotatividade, na qual você indica com Sim ou Não se o cliente cancelou.
Criação de um modelo de previsão de rotatividade
Depois que sua variável de rotatividade estiver configurada e você tiver dados suficientes, estará pronto para abrir o Predict iQ.
Qdica: Predict iQ só prevê resultados que tenham duas opções possíveis, como Sim/Não ou Verdadeiro/Falso. Ele não prevê resultados numéricos (por exemplo, uma escala de 1 a 7) ou resultados categóricos com mais de dois valores (por exemplo, Sim, Talvez, Não).
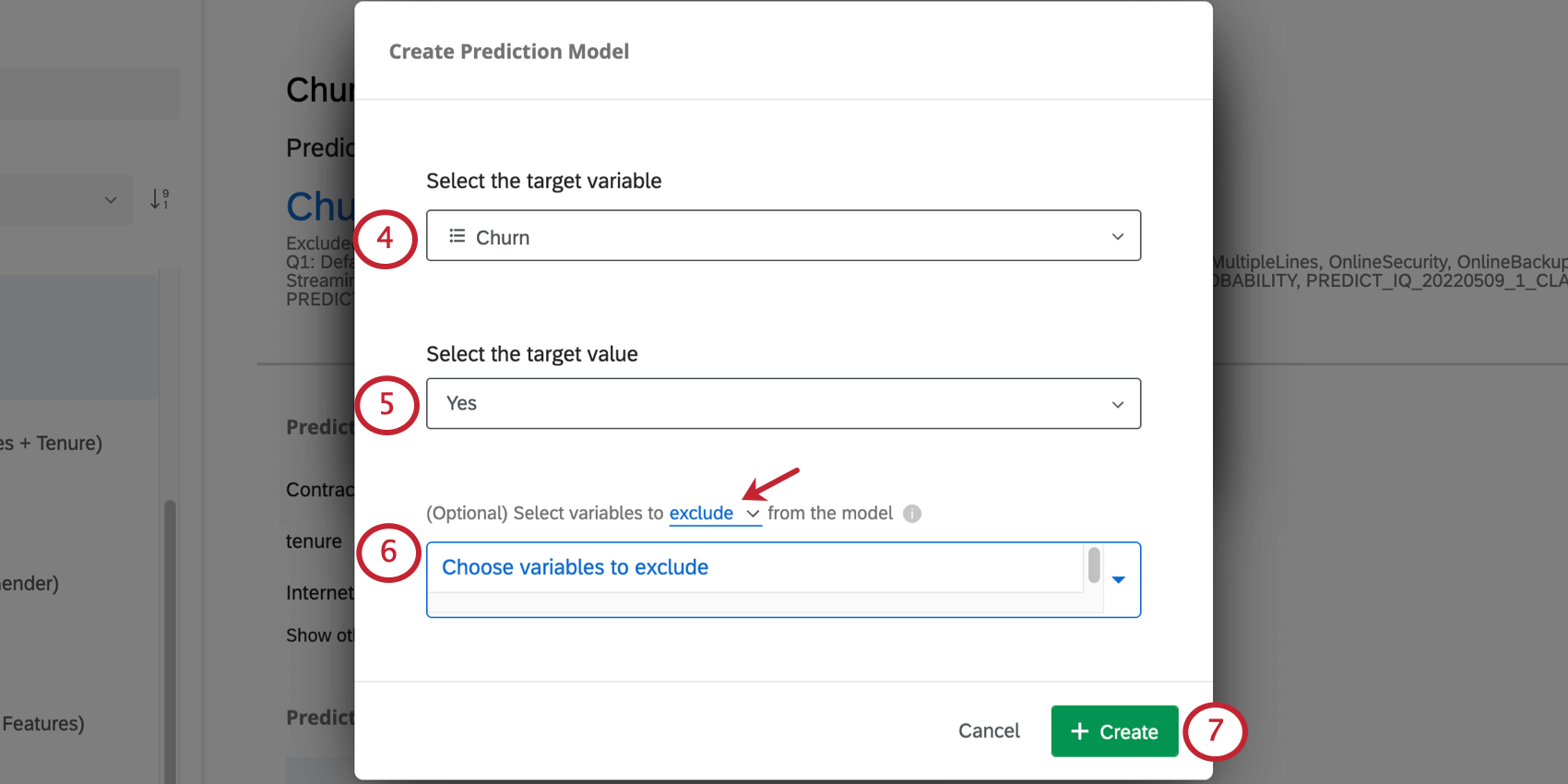
Exemplo: Como neste exemplo nossa variável é denominada Churn, alguém com Churn igual a Yes fez churn. Mas digamos que, em vez disso, você tenha nomeado sua variável como Staying with our company. Nesse caso, o “Não” indicaria que a pessoa não estava permanecendo na empresa e que se afastou.
- Excluir: Por exemplo, se você tiver uma variável que mede “Motivo da rotatividade” em seus dados históricos, talvez queira excluí-la da análise, pois ela não estará disponível para novos respondentes quando a previsão estiver sendo feita. Qdica: você pode excluir várias variáveis. Clique no X avançar de uma variável para removê-la da lista de variáveis excluídas.


- Incluir: Selecione as variáveis a serem incluídas no modelo; todas as outras serão ignoradas.

Qdica: seu modelo preditivo de rotatividade pode levar algum tempo para concluir o cálculo. Você pode navegar para fora da página para trabalhar em outros projetos ou sites sem perder seu progresso.
Quando seu modelo de previsão estiver concluído, a página Predict iQ será substituída por informações sobre o modelo de previsão de rotatividade que você acabou de criar.
{kind=link}

Como seu conjunto de dados é dividido para o treinamento do modelo?
No processo de treinamento do modelo, o conjunto de dados é dividido em dados de treinamento, validação e teste. 80% dos dados são usados para treinamento. 10% de seus dados são usados para validação e 10% de seus dados são usados para teste.
Informações sobre variáveis
A seção resultados e configuração do modelo de previsão fornece o nome da variável dados integrados Churn e o valor que indica a probabilidade de um cliente se desligar. Essa seção também lista as variáveis excluídas.
{kind=link}

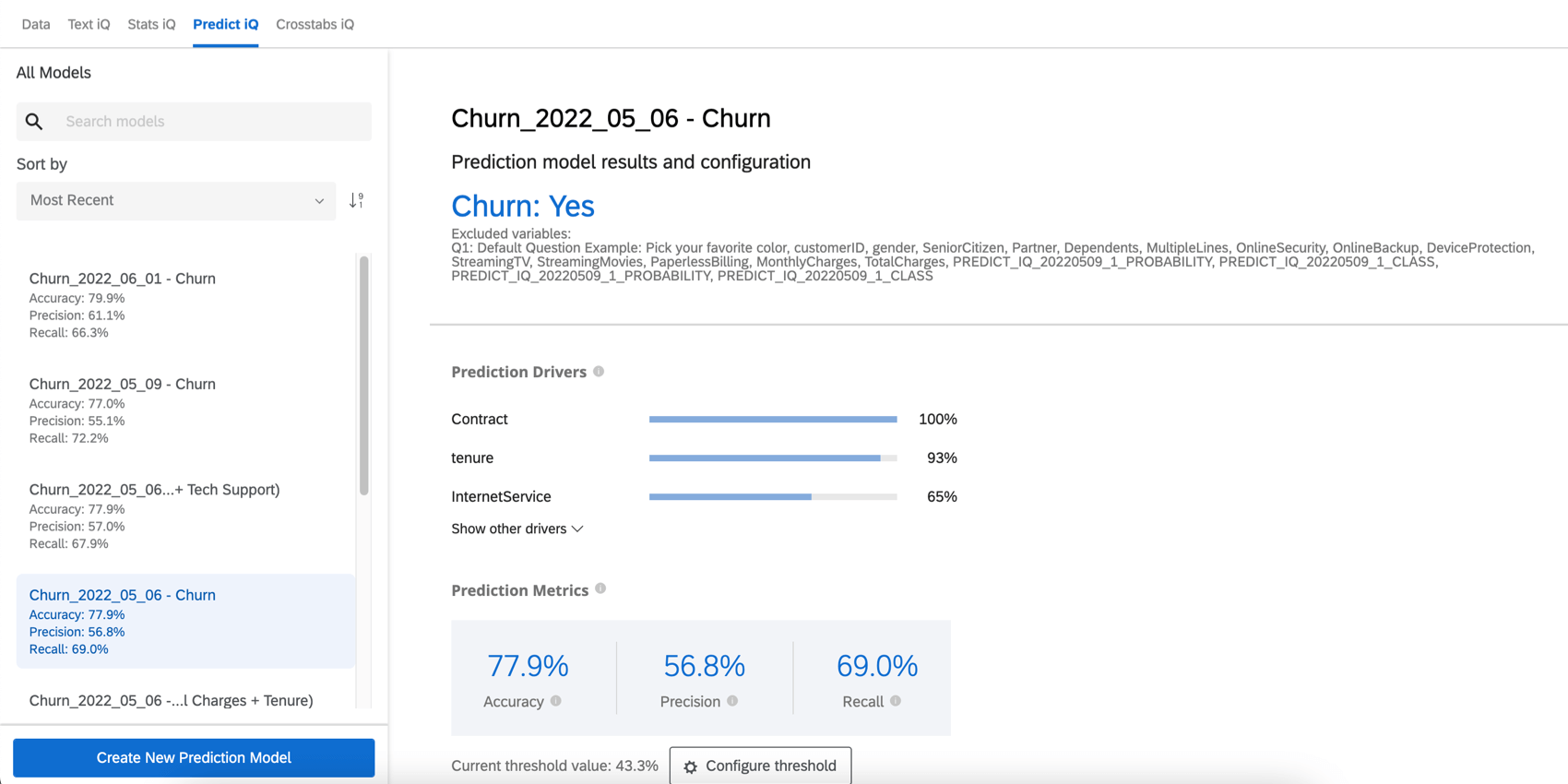
Motivadores da previsão
Os drivers de previsão são as variáveis que foram analisadas para criar seu modelo de previsão, ordenadas por sua importância na previsão da rotatividade. Isso inclui qualquer variável que não tenha sido excluída da análise. No exemplo abaixo, as pontuações do NPS e as classificações de Confiabilidade orientam a previsão de rotatividade.
{kind=link}

Clique em Mostrar outros drivers para expandir a lista.
Qdica: para criar esse gráfico, cada variável é executada em uma regressão logística simples em relação à variável de rotatividade. O valor r-quadrado mais alto é definido como 1, e os valores das outras variáveis são escalonados de acordo. Por exemplo, se o r-quadrado mais alto for 0,5, então o comprimento da barra de cada variável será r-quadrado * 2, em que o comprimento da barra é 1.
O gráfico é, portanto, um indicador da força relativa das variáveis na previsão da rotatividade e não é de natureza multivariada. A classificação do impacto de cada variável no resultado de um modelo baseado em algoritmo de aprendizagem profunda é uma área de pesquisa acadêmica ativa, sem nenhuma prática recomendada aceita até o momento.
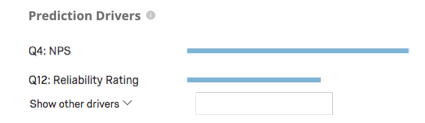
Métricas de previsão
Predict iQ “retém” (deixa de lado) 10% dos dados antes de criar o modelo. Depois que o modelo é criado, ele cria previsões para esses 10%. Em seguida, ele compara suas previsões com o que realmente aconteceu, se esses clientes realmente mudaram. Esses resultados são usados para alimentar as métricas de precisão abaixo. Observe que, embora esse seja um método eficaz de melhores práticas para estimar a precisão do modelo, ele não é uma garantia da precisão futura do modelo.
{kind=link}

- Precisão: A proporção das previsões do modelo que serão precisas.
- Precisão: A proporção de clientes com previsão de cancelamento que realmente o farão.
- Recuperação: A proporção de pessoas que de fato se movimentaram e que o modelo previu antecipadamente que o fariam.
Exemplo: Nesta captura de tela, as previsões do modelo serão precisas em 88,9% das vezes. É suficientemente preciso que 82,4% dos clientes previstos para a rotatividade serão cancelados. A métrica de recall indica que o modelo identificará corretamente uma estimativa de 29,8% dos clientes que de fato cancelarão.
Predict iQ calculará o valor ideal do limite maximizando a pontuação F1. Seu modelo será definido com o limite ideal por padrão, mas você pode ajustá-lo; consulte Configurar limite abaixo.
Clique em Advanced output (Saída avançada ) abaixo da tabela Predictive Metrics (Métricas de previsão) para revelar as tabelas Confusion Matriz de confusão) e Advanced Prediction Metrics (Métricas de previsão avançada).
Precisão e recuperação
A precisão e a recuperação são as métricas de previsão mais importantes. Eles têm uma relação inversa e, por isso, muitas vezes é preciso pensar no compromisso entre saber exatamente quais clientes irão cancelar e saber que você identificou todos ou a maioria dos clientes com probabilidade de cancelamento.
Exemplo: Imagine se você acompanhasse cada um dos clientes. Sem dúvida, você entraria em contato com todos os que se recusam a sair (100% de recall), mas desperdiçaria muitos recursos e tempo com clientes que nunca pensaram em sair (baixa precisão). Por outro lado, se você só fizer o acompanhamento de um único indivíduo com maior probabilidade de cancelamento, provavelmente terá 100% de precisão, mas perderá muitos clientes que acabarão cancelando (recall muito baixo).
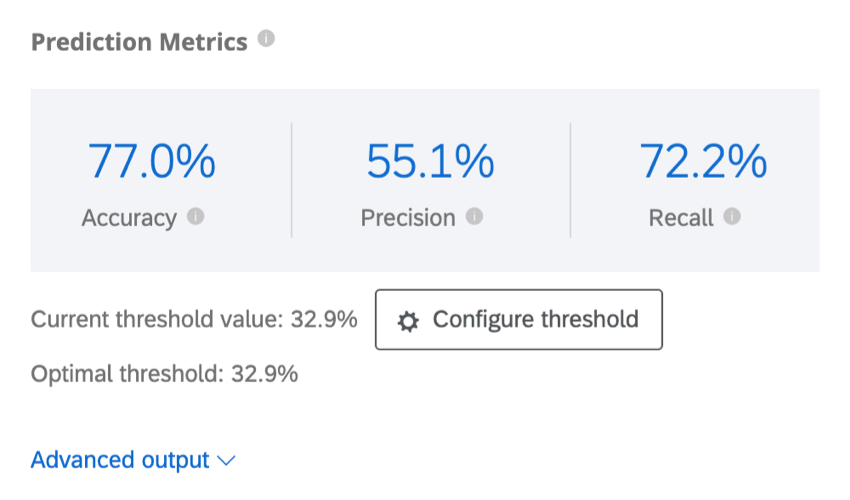
Configurar o limite
Clique em Configure threshold (Configurar limite ) para definir um limite para quando um cliente deve ser rotulado como provável de rotatividade. Essa porcentagem limite é a probabilidade individual de rotatividade.
Exemplo: O modelo produz uma estimativa da probabilidade de rotatividade de um cliente qualquer. Imagine que há três clientes com probabilidade de rotatividade de 10%, 40% e 75%. Se o limite for definido em 30%, tanto os clientes de 40% quanto os de 75% serão marcados como propensos a cancelar e, portanto, receberão um e-mail ou uma ligação telefônica. No entanto, se o limite for definido em 50%, somente o cliente com 75% será marcado como provável de cancelar.
{kind=link}

Clique e arraste o ponto no gráfico para ajustar o limite ou digite uma % de limite e observe como o gráfico muda. Quando terminar, clique em Set Threshold (Definir limite ) para salvar as alterações. Você também pode cancelar as alterações clicando em Cancelar, no canto inferior direito, ou no X, no canto superior direito.
O ajuste do limite ajusta a precisão ao longo do eixo y e a recuperação ao longo do eixo x. Essas métricas têm uma relação inversa. Quanto mais precisas forem suas medidas, menor será o recall, e vice-versa.
Qdica: o ajuste do limite altera a forma como os dados futuros são coletados quando a opção Criar uma previsão sempre que um novo respondente concluir este pesquisa estiver selecionada na seção Previsões de fluxo, na parte inferior da página Predict iQ. Para substituir os dados de rotatividade do seu modelo anterior, você precisará excluir a variável de rotatividade e adicionar uma nova variável. Os limites não afetam a variável Churn Probability (Probabilidade de rotatividade), apenas o binário Yes/No (Sim/Não).
Matriz de confusão
Quando Predict iQ cria um modelo de previsão, ele “retém” (ou deixa de lado) 10% dos dados. Para verificar a precisão do modelo gerado, os dados do novo modelo são executados em comparação com a retenção de 10%. Isso serve como uma comparação o que foi previsto e o que “realmente aconteceu”
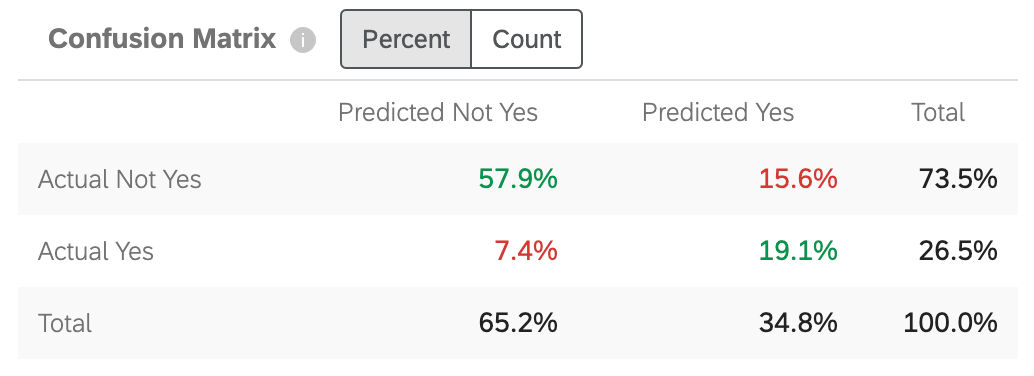{kind=link}

“Sim” nesse gráfico será substituído pelo valor que você indicou como destino na etapa 5 da configuração.
- Não Sim Real / Não Sim Previsto: a porcentagem de clientes que o modelo previu que não iriam cancelar e que realmente não cancelaram.
- Sim real / Não sim previsto: a porcentagem de clientes que o modelo previu que não iriam cancelar e que, ao contrário, cancelaram.
- Não sim real / Sim previsto: a porcentagem de clientes que o modelo previu que iriam cancelar e que, por outro lado, não cancelaram.
- Sim real / Sim previsto: a porcentagem de clientes que o modelo previu que iriam cancelar e que realmente cancelaram.
Os números são verdes para indicar que você deseja que esses números sejam os mais altos possíveis, pois eles refletem palpites corretos. Os números são vermelhos para indicar que você deseja que esses números sejam baixos, pois refletem palpites incorretos.
Você pode ajustar a matriz para exibir porcentagem ou contagem. Essa contagem inclui os 10% de seus dados mantidos fora, não o conjunto completo de dados.
Métricas avançadas de previsão
Essa tabela exibe métricas de previsão adicionais.
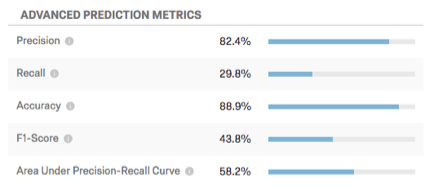{kind=link}

- Precisão: A proporção de clientes com previsão de cancelamento que realmente o farão.
- Recuperação: A proporção de pessoas que de fato se movimentaram e que o modelo previu antecipadamente que o fariam.
- Precisão: A proporção das previsões do modelo que serão precisas.
- Pontuação F1: A pontuação F1 é usada para selecionar um limite que equilibre a precisão com a recuperação. Uma pontuação F1 mais alta geralmente é melhor, embora o local correto para definir o limite deva ser determinado por suas metas comerciais.
- Área sob a curva de recuperação de precisão: A curva Precision-Recall é a curva que você observa no gráfico quando clica em Configurar limite. A área total sob a curva é uma medida da precisão geral do modelo (independentemente de onde você definiu o limite). Uma área sob a curva de 50% é igual à chance aleatória; 100% é perfeitamente preciso.
Fazer previsões
Previsão de lote (CSV)
Além de analisar as respostas coletadas em seu pesquisa, também é possível carregar um arquivo de dados específico que você deseja que Predict iQ avalie.
{kind=link}
Para obter um modelo de arquivo, clique em Batch prediction template for this model (Modelo de previsão em lote para este modelo).
Quando terminar de editar o arquivo no Excel e estiver pronto para reenviá-lo, clique em Choose File (Escolher arquivo ) para selecionar o arquivo. Em seguida, clique em Make predictions (Fazer previsões) para iniciar a análise.
Qdica: Está tendo problemas com seu arquivo de modelo? Consulte a página Problemas de upload de CSV/TSV.
Previsões de fluxo
As previsões de fluxo são atualizadas à medida que os dados chegam à pesquisa. Nessa seção, você pode decidir quando essas atualizações de previsão ocorrerão.
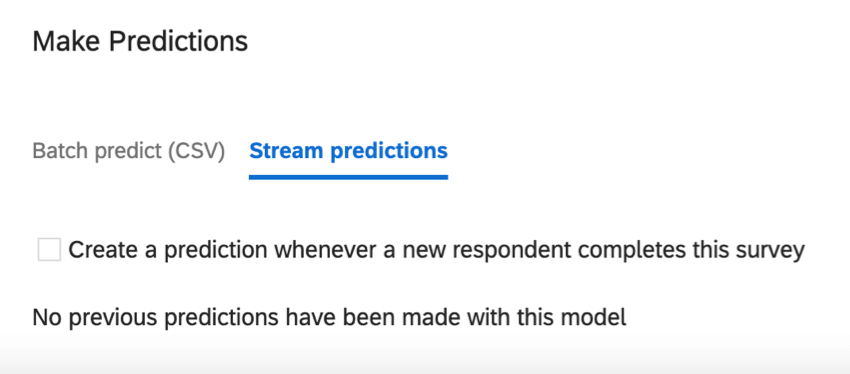{kind=link}

Crie uma previsão sempre que um novo respondente concluir o pesquisa: Essa configuração permite previsões em tempo real. Você terá mais duas colunas em seus dados: Churn Probability (Probabilidade de rotatividade), a probabilidade de rotatividade em um formato decimal; e Churn Prediction (Previsão de rotatividade), uma variável Sim/Não. A previsão de rotatividade é baseada no limite configurado.
Qdica: Se os seus dados incluírem dados integrados extraídos de uma fonte não pertencente ao questionário, os dados podem não chegar ao Qualtrics imediatamente após a conclusão do pesquisa. Se esses dados forem importantes para as previsões, talvez você queira esperar até que eles sejam carregados para que possam ser incluídos.
Gerenciando modelos
No lado esquerdo da página, você verá um menu no qual poderá rolar e selecionar modelos de previsão criados anteriormente.
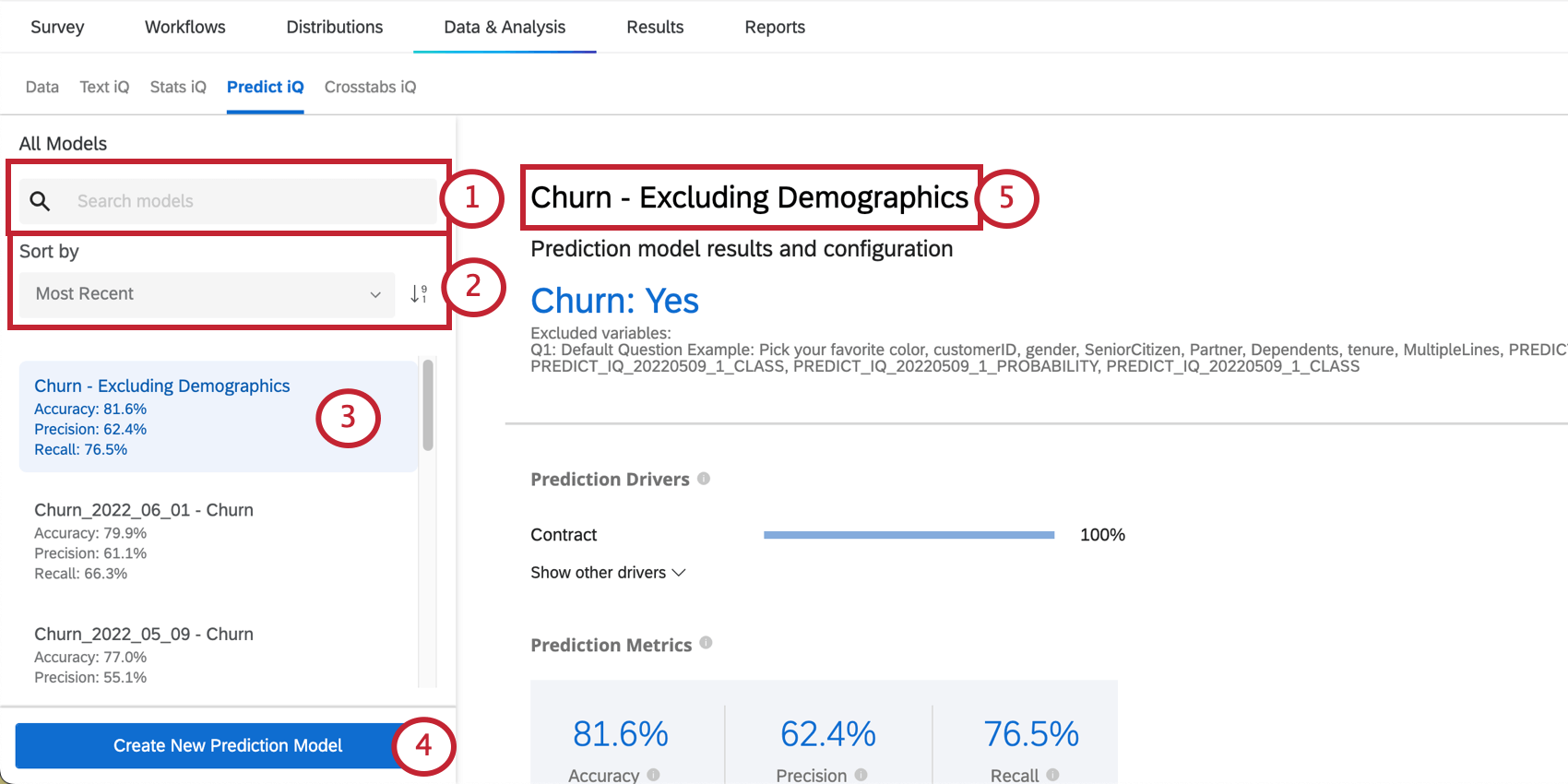{kind=link}
Dados de rotatividade
Na seção Data (Dados) da guia Data & Analysis (Dados e amp; Análise), é possível exportar seus dados como uma planilha conveniente. Depois que seu modelo de previsão for carregado, você terá colunas adicionais para dados de rotatividade nessa página.
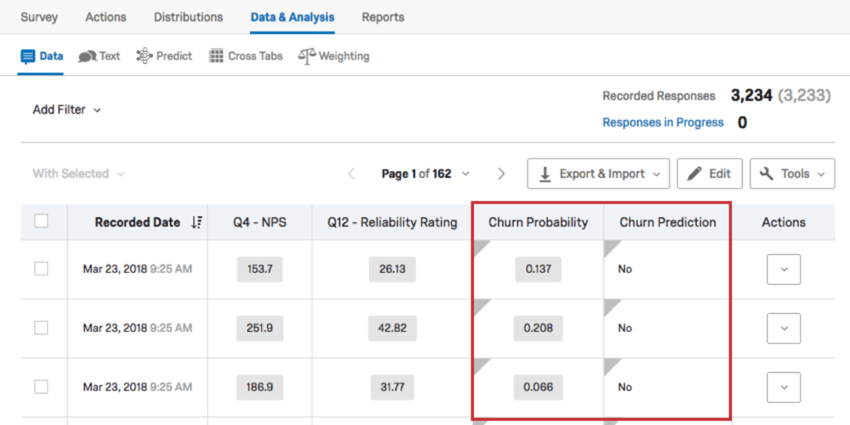{kind=link}
- Probabilidade de rotatividade: A probabilidade de rotatividade em um formato decimal. Aparece quando a previsão de fluxo foi ativada e se baseia no limite definido. Se você não vir a coluna Churn Probability (Probabilidade de rotatividade), também poderá procurar uma coluna de dados chamada “[campo de rotatividade selecionado]_PROBABILITY_PREDICT_IQ”.
- Previsão de rotatividade: Uma variável Sim/Não que confirma ou nega a rotatividade com base no limite definido. Aparece quando a previsão de fluxo está ativada. Se você não vir a coluna Previsão de rotatividade, também poderá procurar uma coluna de dados chamada “[campo de rotatividade selecionado]_CLASS_PREDICT_IQ”.
Exemplo: Se o campo de rotatividade que você selecionou ao criar o modelo de previsão de rotatividade for denominado “CustomerChurnFlag”, as colunas de dados de rotatividade poderão ter a aparência de CustomerChurnFlag_CLASS_PREDICT_IQ e CustomerChurnFlag_PROBABILITY_PREDICT_IQ.
Os nomes das colunas também incluirão a data em que o modelo foi treinado no formato MMDDYYYY. Por exemplo, 14 de janeiro de 2022 seria representado no nome da coluna como 01142022.
Observe que as probabilidades e previsões de rotatividade são aplicadas somente a novos resultados pesquisa. respostas existentes anteriormente não terão probabilidades e previsões de rotatividade adicionadas a elas.
Qdica: depois que você criar essas variáveis, elas poderão ser analisadas usando Results-Reports ou Advanced-Reports, como qualquer outra variável.
Limpeza automática de dados
Ao treinar o modelo, Predict iQ ignorará automaticamente certos tipos de variáveis que não serão úteis para as previsões, enquanto transforma automaticamente outras variáveis.
Variáveis de alta cardinalidade
Se uma variável tiver mais de 50 valores exclusivos ou mais de 20% dos valores registrados forem exclusivos, ela será ignorada durante o treinamento do modelo. As variáveis com muitos valores exclusivos não são boas colunas de característica para previsões.
Exemplo: Por exemplo, se você tiver uma variável que seja County – USA, essa variável seria ignorada durante o treinamento do modelo porque há mais de 3.000 condados nos Estados Unidos em todos os 50 estados.
Exemplo: Como outro exemplo, considere uma variável como Sabor de sorvete favorito e suponha que você tenha 100 linhas de dados para essa variável. Entre essas 100 linhas, você discover que há 21 valores exclusivos para o sabor do sorvete. Essa variável é ignorada durante o treinamento do modelo porque mais de 20% de seus valores registrados são exclusivos.
Valores ausentes para colunas numéricas
Para variáveis numéricas incluídas no modelo, os valores ausentes são sempre imputados como 0 (zero).
Codificação de categóricos em um único ponto
As variáveis categóricas serão codificadas em um ponto se a variável não for recodificada ou se a variável não tiver uma relação ordinal para suas categorias.
Qdica: Predict iQ carrega as mesmas configurações de variáveis usadas no Stats iQ.
Variáveis invariantes
Qualquer variável que não tenha variação em seus valores registrados será ignorada para o treinamento do modelo. Isso significa que, se você tiver uma variável que tenha apenas um único valor exclusivo, ela não fará parte do modelo. As variáveis que são úteis para a previsão atingirão um bom equilíbrio entre ter poucos valores exclusivos e ter muitos valores exclusivos. Consulte “Variáveis de alta cardinalidade” acima.
Se alguma variável invariante for excluída durante a limpeza de dados, ela será listada na seção resultados e configuração do modelo de previsão.
Projetos em que você pode usar Predict iQ
Predict iQ não está incluído em todas as licenças. No entanto, se você tiver esse característica, ele poderá ser acessado em alguns tipos diferentes de projetos:
Predict iQ também pode aparecer em projetos de Engajamento e Ciclo de Vida, mas com base na natureza dos dados normalmente coletados por esses tipos de projeto, o conjunto de dados não seria necessariamente o melhor para o Predict iQ.
Embora Predict iQ apareça no Conjoint e no MaxDiff, não recomendamos usá-los juntos. O conteúdo específico do Conjoint e do MaxDiff não é compatível com o Predict iQ, portanto, você só pode analisar dados demográficos.
Não há suporte para outros tipos de projeto.
Qdica: os projetos listados nesta seção não estão disponíveis em todas as licenças.
Isso é ótimo! Obrigado pelo seu feedback!
Obrigado pelo seu feedback!