Entendendo seu conjunto de dados
O que há nesta página
Sobre seu conjunto de dados de resposta
Para análise adicional fora do Qualtrics, é possível fazer download de um arquivo de conjunto de dados para qualquer pesquisa. Esse conjunto de dados inclui todos os dados brutos de resposta do seu pesquisa, que abrangem tudo, desde as respostas às perguntas pesquisa até metadados adicionais, como duração e datas, dados integrados e muito mais.
Nesta página, veremos:
- Explique as diferentes colunas de informações que você pode ver em seu arquivo de dados.
- Explique como as respostas podem ser formatadas nesse arquivo de dados, dependendo da coluna.
- Vincule outros recursos que lhe permitam entender ou personalizar o download dos dados.
No entanto, esta página não discute a análise estatística nem informa como interpretar os resultados dos seus dados, além do literal (por exemplo, este respondente marcou que estava muito satisfeito). Há muitas variáveis e projetos diferentes que fazem parte da pesquisa e, embora gostaríamos de dizer que sabemos tudo, isso realmente depende das especificidades do seu estudo e de como você o montou!
Atenção: O arquivo usado nas capturas de tela desta página foi baixado no formato CSV e é aberto no Excel. Ele também foi formatado usando o característica quebra de texto para facilitar a leitura. Outros formatos de arquivo incluem os mesmos pontos de dados, mas podem exibir o conteúdo com um layout ligeiramente diferente.
Tipos de conjuntos de dados de resposta abrangidos por esta página
Esta página pode ajudá-lo a entender os dados brutos que você exporta dos seguintes tipos de projetos:
Há alguns outros tipos de projetos nos quais você pode exportar dados de resposta. No entanto, há diferenças importantes para ter em mente:
- Para projetos 360, consulte Entendendo seu conjunto de dados de resposta (360).
- Para todos os outros projetos experiência dos colaboradores, Employee Experience, consulte Understanding Your Response Dataset (EX).
Tecnicamente, os conjuntos de dados Conjoint e MaxDiff também são formatados conforme descrito nesta página quando exportados do Data & Analysis. Entretanto, essa exportação de dados exclui os dados específicos doConjoint e do MaxDiff.
Noções básicas de formato de arquivo
Cada linha do arquivo é uma resposta pesquisa diferente (embora não necessariamente respondentes diferentes, se você permitir que as pessoas respondam várias vezes). Cada coluna é um tipo de dados pesquisa.

Os arquivos CSV e TSV vêm com 3 linhas de cabeçalhos. O primeiro cabeçalho é o ID Qualtrics interno do campo (por exemplo, EndDate, Q1, Q2 e assim por diante). O segundo cabeçalho é o nome ou o texto do campo (por exemplo, End Date (Data de término), How satisfied are you with Qualtrics? O terceiro cabeçalho tem IDs de importação. Todos esses três cabeçalhos estão incluídos porque são necessários para carregar os dados em uma pesquisa. Os dados do entrevistado começam na quarta linha do arquivo.

Qdica: com base no formato de arquivo que você baixou (SPSS, Excel, etc.), você poderá ver cabeçalhos diferentes. Consulte Formatos de exportação para obter mais informações sobre os formatos disponíveis.
Informação do entrevistado
As primeiras colunas em um conjunto de dados incluem informações sobre cada respondente e sua resposta, como nome, endereço IP, datas de envio da resposta e assim por diante. lista cada uma dessas colunas e como entender seu conteúdo aqui.
Qdica: O zona horário usado para todas as datas e horas registradas em sua conta Qualtrics está correlacionado com o zona horário definido em suas Configurações Conta.
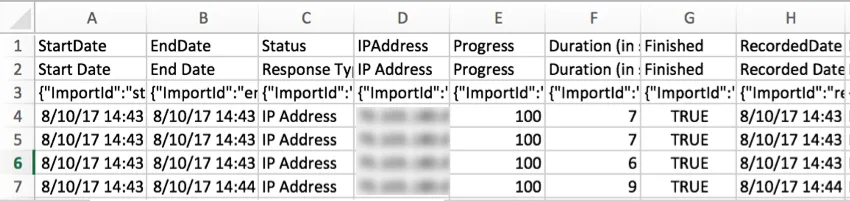
StartDateEsses
valores de data e hora indicam quando os questionados clicaram pela primeira vez no link da pesquisa.
Qdica: se as colunas Data de início e Data de término no Excel contiverem ######, tente aumentar a largura das colunas. O Excel usa símbolos # quando um valor não cabe na célula.
EndDateEsses
valores de data e hora indicam quando o respondente enviou o pesquisa. Se a entrada for uma resposta incompleta, essa data indicará a última vez que o respondente interagiu com a pesquisa.
Qdica: ao importar uma resposta, você pode atribuir à resposta qualquer data final ou data de início que desejar. No entanto, depois que uma resposta é registrada, a data final e as datas de início são definidas e não podem ser editadas.
Status / Tipo de respostaO
valor na coluna Status indica o tipo de resposta coletada. Esses são os status possíveis, apresentados em formato de valor e rótulo:
- 0 / Endereço IP: Uma resposta normal
- 1 / Visualização Pesquisa: A resposta de visualização
- 2 / Teste Pesquisa: Uma resposta de teste
- 4 / Importado: Um resposta importada
- 16 / Off-line: A Aplicativo offline da Qualtrics resposta
- 17 / Visualização off-line: Visualizações enviadas por meio do Aplicativo offline da Qualtrics. Este recurso está obsoleto nas versões mais recentes do aplicativo
- 256 / Sintético: Uma resposta painel sintético.
Qdica: arquivos antigos também podem ter os códigos 6, 8 ou 12, relacionados a Spam. Todos os status de spam foram descontinuados. Para obter ferramentas melhores que o ajudarão a identificar spam, confira Detecção de fraude e qualidade de resposta.
Qdica: Se você exportar os dados com a opção Exportar rótulos ativada, a exportação conterá o texto de cada status (por exemplo, Visualização Pesquisa ) em vez do código numérico.
Qdica: respostas licenciadas são quaisquer respostas concluídas que não sejam visualizações ou testes pesquisa. respostas concluídas incluem pesquisas finalizadas e pesquisas incompletas que foram retiradas das respostas em andamento e registradas. Contato o seu executivo Conta para saber o preço das respostas importadas. Se você quiser ver o número de respostas que usou, vá para Configurações Conta e, em seguida Uso da conta.
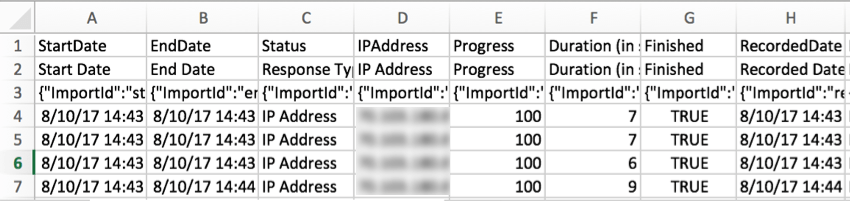
IPAddressEssa
coluna inclui o endereço IP do respondente. Esses dados não estarão disponíveis se respostas tiverem sido completamente anônimo.
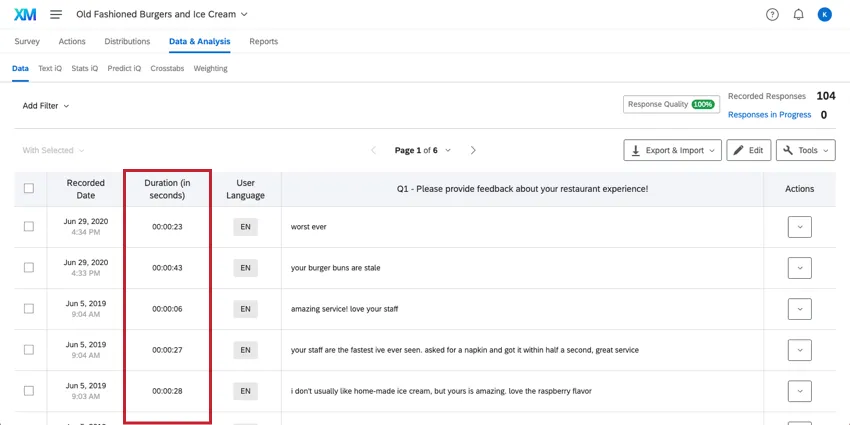
DuraçãoO
número de segundos que o respondente levou para concluir a pesquisa. Esta é toda a duração da resposta; se um entrevistado para no meio da pesquisa, fecha o navegador e volta outro dia, esse tempo é contado.
Qdica: enquanto a exportação mede a duração em segundos, na guia Dados esse campo é exibido em horas:minutos:segundos.
{kind=link}
{kind=link}
{kind=link}
Finished and ProgressA
coluna Finished detalha se a resposta foi enviada ou fechada. Um “1” ou “Verdadeiro” indica que o respondente chegou a um ponto final no pesquisa (pressionando o último botão Avançar, sendo excluído pela lógica de ramificação ou Ramificação, etc.). Um “0” ou “Falso” indica que o respondente saiu do pesquisa antes de atingir um ponto final e a resposta foi fechada manualmente ou devido à expiração da sessão.
A coluna Progresso mostra o progresso que o respondente fez na pesquisa antes de terminar. Para aqueles marcados como “1” ou “Verdadeiro” na coluna Concluído, o Progresso é marcado como 100. Para aqueles cujas respostas estão marcadas como “0” ou “Falso”, você obterá uma porcentagem exata de quão longe eles chegaram na pesquisa com base na pergunta em que pararam.
Qdica: a porcentagem de progresso é calculada com base em todos os elementos do pesquisa, incluindo os elementos do fluxo da pesquisa. Se o seu pesquisa contiver muitos elementos, a porcentagem de progresso poderá ser inferior a 1%, mesmo quando as perguntas forem respondidas. O progresso inferior a 1% é arredondado para 0%.
RecordedDate Essa
coluna indica quando um pesquisa foi registrado no Qualtrics. Para usuários que realizam pesquisas on-line, essa data e hora serão muito semelhantes à Data de término. No entanto, para respostas importadas ou carregadas do aplicativo offline, a Data de registro geralmente será diferente da Data de término, refletindo quando você carregou manualmente os resultados, e não quando o respondente terminou o pesquisa.
Qdica: Está percebendo uma diferença de vários minutos entre a data de término e a data de registro? Uma conexão lenta com a Internet pode atrasar o tempo entre o momento em que o entrevistado envia os dados da pesquisa e quando a Qualtrics os salva oficialmente no site.
Qdica: a ordem de exportação das respostas é organizada com base na Data de Registro, com a resposta registrada mais antiga aparecendo primeiro.
{kind=link}
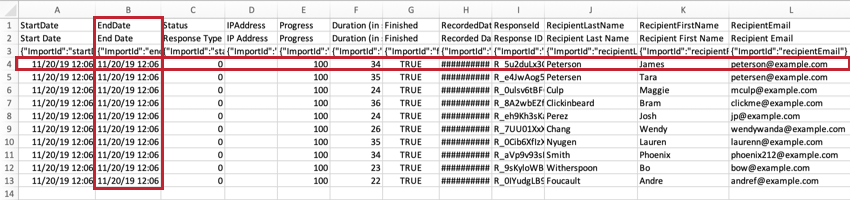
ResponseID O
ResponseID é o ID que o Qualtrics usa para identificar cada resposta no banco de dados. Esse identificador exclusivo é fornecido como referência e geralmente não é usado na análise de dados.
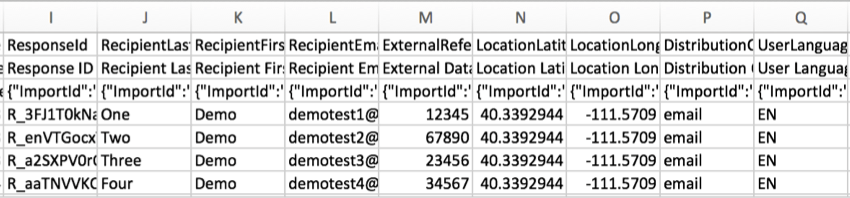
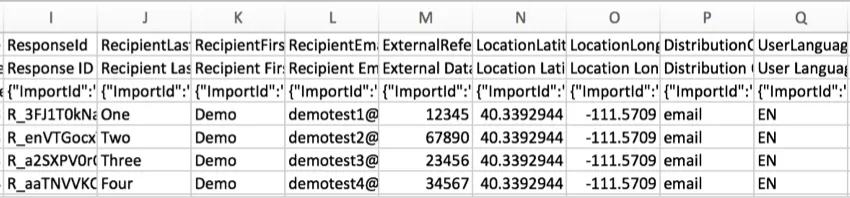
RecipientLastName, RecipientFirstName e RecipientEmailOs
nomes e endereços de e-mail dos
respondentes
serão exibidos nessas colunas se o seu pesquisa tiver sido distribuído usando uma lista de contatos. Algumas das distribuições comuns que usam listas contato incluem:
Para todas as outras respostas, como as coletadas com um link anônimo ou com determinadas opções Pesquisa ativadas, essas colunas ficarão em branco. Observe que qualquer distribuição pode ser anonimizada, independentemente do método de distribuição.
Qdica: Os nomes dos respondentes serão sorteados entre os lista de contatos no qual a distribuição foi baseada. A exclusão da lista de contatos ou a exclusão de informações da lista de contatos não afetará os dados de resposta, a menos que isso seja feito antes de o questionado iniciar o pesquisa (ou antes de a distribuição ser enviada). Se você excluir ou editar uma lista de contatos depois que a resposta for coletada, ela ainda conterá os dados originais contato. Você sempre pode editar a resposta conforme necessário.
Qdica: Para perguntas relacionadas à privacidade do respondente e ao GDPR, consulte nossa página de suporte Qualtrics & GDPR Compliance.
ExternalDataReferenceFrequentemente
usado ao fazer o upload de um lista de contatos para a Qualtrics para uso em um autenticador e , ocasionalmente, em um e-mail distribuição, uma referência de dados externos pode ser incluída para cada participante. Este é um campo genérico que pode armazenar qualquer informação de que você goste (e é usado com mais frequência para identificadores exclusivos, como IDs de funcionário ou aluno). Se uma referência de dados externos tiver sido adicionada à lista de contatos, ela será exibida nessa coluna. Se você não optar por usar esse campo, a coluna ficará em branco.
Qdica: para maior flexibilidade com distribuições de e-mail e dados coletados de links pesquisa com cadeias de consulta, geralmente recomendamos o upload de detalhes adicionais como dados integrados em vez de usar referência de dados externos.
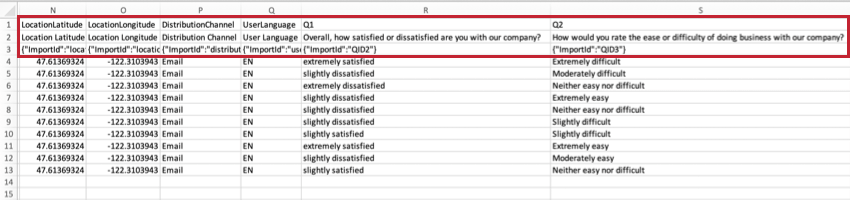
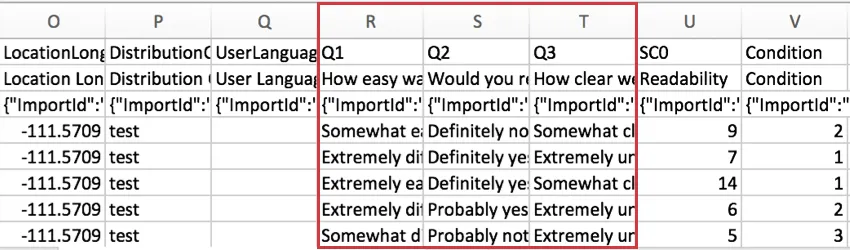
LocationLatitude e LocationLongitudeSe
o respondente completou a pesquisa usando o Aplicativo offline da Qualtrics em um dispositivo habilitado para GPS, esses dados serão uma representação precisa da localização do entrevistado.
Para todos os outros entrevistados, o local é uma aproximação determinada pela comparação do endereço IP do participante com um banco de dados local. Nos Estados Unidos, esses dados geralmente são precisos no nível da cidade. Fora dos Estados Unidos, esses dados geralmente são precisos apenas em nível de país.
Esses dados não estarão disponíveis se respostas tiverem sido completamente anônimas.
Qdica: os valores dos dados de latitude e longitude são baseados no código de cidade/zip e não podem ser usados para identificar um local ou indivíduo específico.
DistributionChannelEsta
coluna descreve o método de distribuição pesquisa.

No exemplo acima, a pesquisa foi enviada por e-mail aos participantes.
Qdica: se esta coluna disser “teste”, trata-se de uma resposta de teste. “Pré-visualização” refere-se a uma resposta concluída com o link de pré-visualização.
UserLanguageSe
o seu pesquisa tiver vários idiomas, o código de idioma do respondente será exibido nessa coluna.
Qdica: para obter mais detalhes sobre como definir o idioma de um participante, consulte a página de suporte vinculada.
Qdica: para configurar lógica de exibição e criar conteúdo personalizado com base nos idiomas dos usuários, tente Q_Language em vez de UserLanguage.
Mesmo que um pesquisa tenha apenas um idioma, todas as respostas devem ter dados na coluna UserLanguage, incluindo visualizações. A única exceção são as respostas de teste, que terão uma coluna UserLanguage em branco.
Respostas das perguntas
As avançar colunas do conjunto de dados exibem as respostas fornecidas para cada pergunta pesquisa. As colunas são encabeçadas com os números das perguntas (por exemplo, Q1) e, em seguida, com as linhas iniciais do texto da pergunta (por exemplo, How easy was it to understand the reading assignment?).
As perguntas simples (entrada de texto, múltipla escolha – 1 resposta, etc.) estarão contidas em uma coluna, mas as perguntas mais complexas com várias declarações (tabela matriz, lado a lado, etc.) serão distribuídas em várias colunas.
{kind=link}
Qdica: Tipos de perguntas diferentes armazenam dados de forma diferente, portanto, recomendamos gerar dados amostra e verificar o formulário baixado antes de iniciar o pesquisa. Dessa forma, você pode ter certeza de que está obtendo o tipo de resultado desejado.
Por padrão, o download dos dados é feito em rótulos (ou seja, o texto exato das perguntas e respostas). No entanto, você também pode optar por exportá-lo como valores (chamados de “valores de recodificação“) para cada opção de resposta resposta. Por exemplo, em uma escala de 5 pontos, “Concordo plenamente” seria exibido como “5”, facilitando a localização de uma média ou a realização de outras análises estatísticas.
Qdica: para obter mais detalhes sobre a exportação em formato de rótulo versus valor e outras opções de exportação que podem afetar a formatação de dados, consulte Opções de exportação.
Se a codificação numérica das suas escolhas não corresponder às suas expectativas, você sempre poderá voltar à guia Pesquisa para alterá-las e exportar os dados novamente. Pode também exportar seu pesquisa para o Word para recuperar um livro de códigos que descreve como cada opção de resposta é codificada no conjunto de dados.
Guia para tipos específicos de perguntas
Os dados exportados geralmente parecem diferentes com base nos tipos de perguntas que você escolheu incluir. Essas diferenças são explicadas na página individual da pergunta. Vinculamos as seções relevantes abaixo.
- Múltipla escolha ( incluindo como as exportações de múltiplas respostas aparecem)
- Tabela matricial
- Entrada de texto
- Campo de formulário
- Controle deslizante
- Ordem de classificação
- Lado a lado
- Soma constante
- Escolha, agrupe, & classifique
- Hot spot
- Mapa de calor
- Gráfico deslizante
- Drill down
- Net promotor score
- Destaque
- Assinatura
- Temporizador
- Metainformações
- Carregar arquivo
Perguntas em Loop & Merge Blocks
Ao visualizar seus dados, cada loop é tratado como um conjunto separado de perguntas. Se você tiver 5 loops possíveis, verá as perguntas em loop repetidas 5 vezes nos dados. Mesmo que não sejam mostrados todos os loops a um respondente, todos os loops possíveis serão representados nos dados.
Consulte Visualização da ordem do loop em seus dados.
Resultados por pontuação
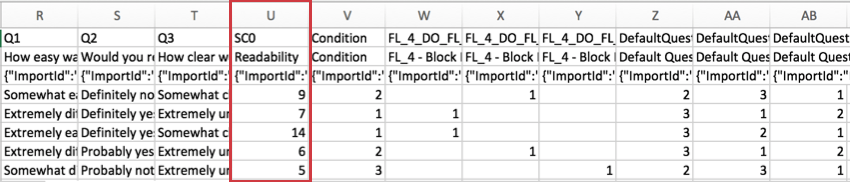
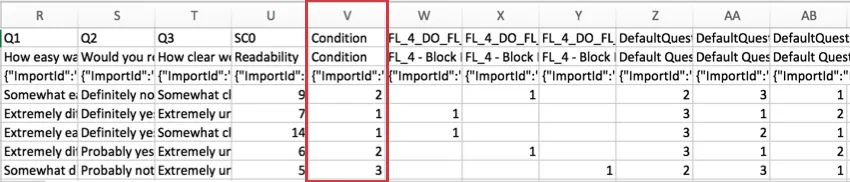
Para pesquisas que usam Pontuação, a pontuação de cada categoria é incluída no conjunto de dados. Cada categoria de pontuação recebe sua própria coluna de dados. No exemplo abaixo, o pesquisa tinha apenas uma categoria de pontuação, chamada “Legibilidade”
Essa pontuação é uma soma dos pontos que o entrevistado ganhou na categoria, e não uma média.
{kind=link}
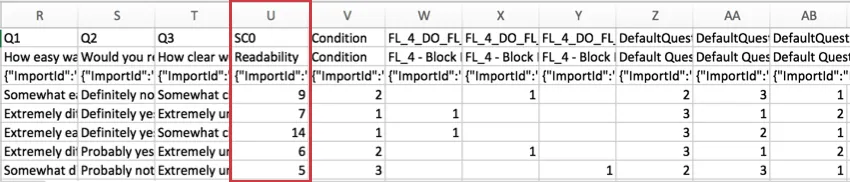
O “SC” no cabeçalho significa “Pontuação Category” (Categoria de pontuação ) e o número representa a categoria numérica em que se encontra, contando a partir de zero. Como o exemplo de pesquisa acima tem uma categoria de pontuação, vemos SC0, mas se houvesse mais, veríamos SC1, SC2 e assim por diante.
Qdica: para obter dados sobre a pontuação média, mínima, máxima e outras estatísticas, consulte seus Resultados. Geralmente, há uma tabela de estatísticas para suas categorias pontuação na parte inferior do relatório.
Dados integrados
Para pesquisas que usam dados integrados, as informações dados integrados são incluídas nas colunas após as informações pontuação.
{kind=link}
Somente os campos dados integrados salvos no fluxo da pesquisa são incluídos no conjunto de dados baixado. Os campos Dados integrados com valores de uma lista de contatos ou URL podem ser salvos no fluxo da pesquisa a qualquer momento, antes ou depois da coleta de dados.
Qdica: Além de poder criar seus próprios dados integrados, o Qualtrics também fornece uma lista de campos pré-construídos para escolha. Consulte Campos de dados incorporados incorporados para obter mais detalhes sobre como cada 1 funciona e o tipo de dados que eles resultam.
Qdica: Está curioso sobre a coluna Q_DataPolicyViolations? Consulte a Política de dados confidenciais. Nem todas as licenças têm políticas de dados confidenciais ativadas, portanto, se essa coluna estiver em branco, não se preocupe.
Qdica: para obter ajuda na interpretação dos campos de detecção de fraude (detecção de bots, envios duplicar, etc.), consulte Detecção de fraude.
Dados de randomização
Qdica: para obter instruções passo a passo sobre como incluir dados de randomização na exportação de dados de resposta, consulte Exportação de dados randomizados.
Você verá colunas de randomização seguindo os dados de resposta da pergunta. Haverá uma coluna para cada elemento aleatório da pesquisa. Por exemplo, se você randomizar um bloco com 5 perguntas, terá 5 colunas, uma para cada pergunta. Se você tivesse um randomizador em seu fluxo da pesquisa com 7 elementos sob ele, teria 7 colunas, 1 para cada elemento que foi randomizado.
Se você randomizar a ordem de todos os elementos apresentados, a coluna mostrará a ordem em que o elemento foi apresentado, por exemplo, 1, 2, 3 e assim por diante.
Exemplo: Na captura de tela abaixo, a ordem das perguntas foi aleatória e as colunas mostram a ordem em que cada pergunta apareceu na sequência. Observe que os números das perguntas estão nos cabeçalhos.

{kind=link}
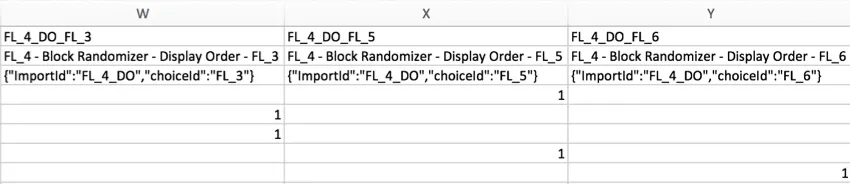
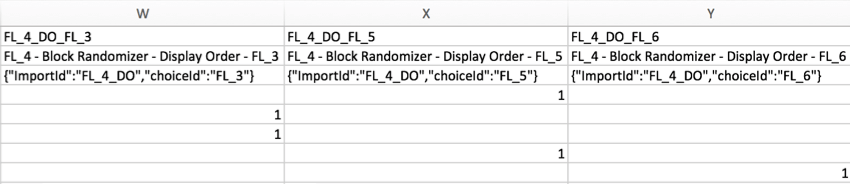
Quando você apresenta aleatoriamente um elemento de uma lista de vários, os elementos que foram exibidos serão marcados como 1. Os elementos que não foram exibidos para o respondente ficarão em branco.
Exemplo: No exemplo abaixo, 1 elemento foi apresentado aleatoriamente de uma lista de 3. As colunas indicam qual elemento foi mostrado ao entrevistado colocando um 1 abaixo da coluna rotulada para o elemento apresentado.
{kind=link}
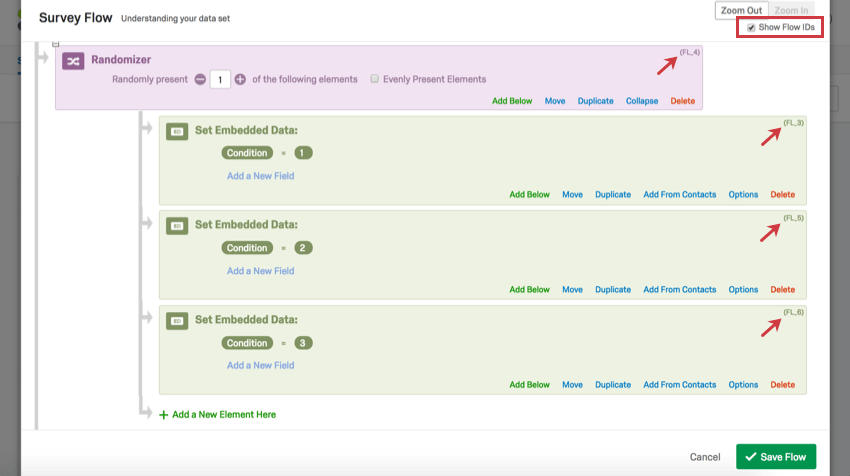
Qdica: Está confuso sobre como ler os cabeçalhos no segundo exemplo? Como o randomizador fluxo da pesquisa foi usado neste exemplo, a coluna exibe IDs de fluxo em vez de IDs de pergunta. Você pode recuperar IDs de fluxo acessando o fluxo da pesquisa e selecionando Mostrar IDs de fluxo no canto superior direito. As IDs de fluxo não podem ser editadas.

{kind=link}
Solução de problemas de um arquivo de dados
Esta seção abordará algumas dúvidas e preocupações comuns que muitos usuários têm em relação ao seu arquivo de dados. Também destaque alguns recursos úteis que você pode usar para personalizar suas exportações de dados.
Guia para exportação de dados e todas as opções disponíveis
Para obter instruções sobre como exportar dados, consulte as seguintes páginas de suporte:
- Exportação de dados de resposta: Instruções e dicas passo a passo.
- Opções de exportação de dados: Guia para opções adicionais, como exportação de dados aleatórios, rotulagem de perguntas vistas, mas não respondidas, exportação em formato de valor versus rótulo e assim por diante.
- Formatos de exportação de dados: Guia para diferentes tipos de arquivos que você pode exportar.
Personalização das colunas incluídas na exportação
Para personalizar as colunas em suas exportações,
Exportação de dados filtrados
Para exportar dados filtrados,
Recursos que não têm dados para incluir em uma exportação
Se você tiver incluído um texto descritivo (como um parágrafo de introdução sem pergunta anexa) ou um gráfico (como uma figura sem pergunta anexa), esses campos não terão suas próprias colunas na exportação de dados, pois não têm respostas para o respondente selecionar. Se você notou que os números das perguntas foram “ignorados” na exportação do pesquisa, pode ser porque você incluiu campos como esse.
No entanto, se você randomizou quando o texto descritivo ou os campos gráficos são exibidos para os questionados, é possível encontrar esses dados exportando os dados randomizados. Consulte Exportar dados randomizados para obter instruções passo a passo e consulte Dados de randomização para obter um guia sobre como ler o resultado.
Determinadas opções de resposta excluídas do arquivo / Como excluir valores da análise
Consulte Excluir da análise. Alguns valores, com base em sua redação, são excluídos por padrão. Essas respostas são registradas e podem ser adicionadas novamente aos dados a qualquer momento, sem nenhum problema.
Qdica: Se você não tiver valores excluídos da análise e ainda não tiver coletado muitos dados, pode ser que nenhum respondente tenha selecionado essa resposta ainda. Se essa for uma resposta com lógica de exibição, certifique-se de verificar novamente as condições da lógica.
Dados incorporados excluídos do arquivo
Certifique-se de que o elemento dados integrados seja adicionado ao fluxo da pesquisa e esteja puxando todos os campos contato.
Para obter uma solução de problemas mais detalhada com dados integrados, consulte as páginas de suporte vinculadas.
Outros campos excluídos do arquivo
Certifique-se de que o Download de todos os campos esteja selecionado ao exportar seus dados. Os dados aleatórios não são incluídos por padrão, mas podem ser adicionados de acordo com estas instruções.
Consulte as opções adicionais de exportação.
Personalizar números de perguntas
Consulte Numeração automática de perguntas e Números de perguntas.
Personalizar a redação da pergunta ou da resposta na exportação de dados, mas não no Pesquisa
É possível usar legendas de pergunta para alterar a forma como as próprias perguntas são redigidas na exportação, sem afetar a forma como as perguntas aparecem para pesquisa questionados. Você pode usar nomes de variáveis para alterar o texto das opções de resposta. É seguro editar as legendas das perguntas e os nomes das variáveis a qualquer momento durante a coleta pesquisa.
Os rótulos das perguntas e os nomes das variáveis também afetam a forma como esses dados aparecem nos resultados e nos relatórios.
Exemplo: Suas perguntas e respostas são muito longas e você deseja encurtar os nomes para facilitar a leitura e o relatório.
A redação das perguntas/respostas difere do editor Pesquisa
Se o texto das perguntas for diferente do que você vê no editor pesquisa, verifique novamente se não há rótulos de perguntas adicionados. Se o texto das suas respostas for diferente do que você vê no editor pesquisa, verifique os nomes das variáveis em opções de recodificação. Se você criou o pesquisa a partir de uma cópia de uma versão anterior, essas configurações podem ser transferidas. É seguro editar as legendas das perguntas e os nomes das variáveis a qualquer momento durante a coleta pesquisa.
Problemas de exportação de CSV
Se a exportação de CSV não tiver a aparência correta (por exemplo, tiver símbolos em vez do texto esperado ou colunas que se cruzam), exporte os dados no formato TSV. O TSV é especialmente útil para dados que contêm caracteres especiais.
Para obter mais soluções de problemas, consulte Problemas com arquivos CSV baixados.
Arquivos de respostas de Projetos de pesquisa 360, de engajamento, de ciclo de vida e de pesquisa ad hoc Colaborador
Para 360, consulte Entendendo seu conjunto de dados de resposta (360).
Para todos os outros projetos EX, consulte Entendendo seu conjunto de dados de resposta (EX).
Diferenças de formato de arquivo
Embora todos os tipos de arquivo baixem os mesmos campos de dados descritos acima, cada um possui um layout que pode ser um pouco diferente.
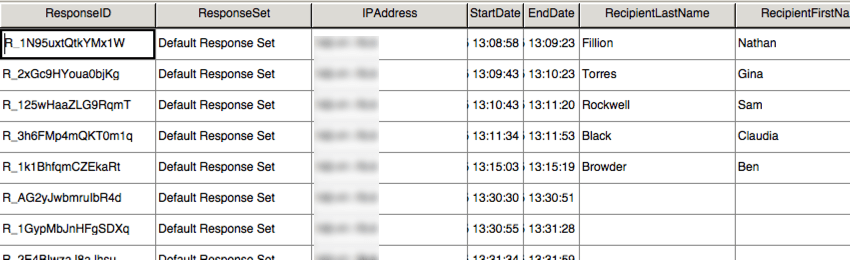
SPSSA
visualização de dados no SPSS inclui exatamente o mesmo layout do arquivo CSV, com menos cabeçalhos.
{kind=link}
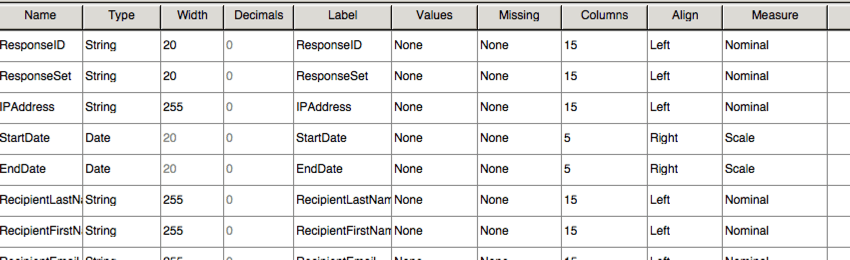
O SPSS inclui outra exibição, chamada de Visualização variável. Essa visualização lista todas as variáveis do seu conjunto de dados com informações sobre cada uma, como o tipo de variável e os valores possíveis.
{kind=link}

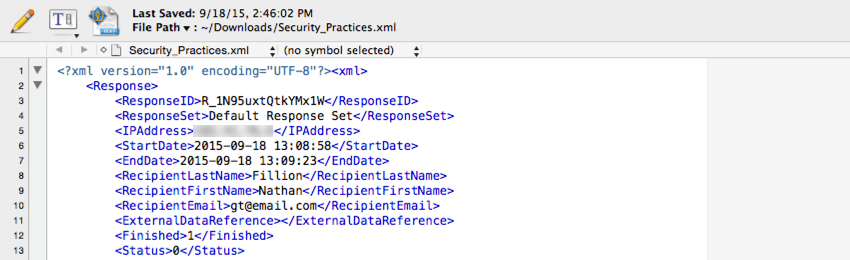
XMLO
tipo de arquivo XML é frequentemente usado na integração de dados Qualtrics com um banco de dados de terceiros. Esse tipo de arquivo pode ser analisado facilmente pelo software de banco de dados comum.
{kind=link}
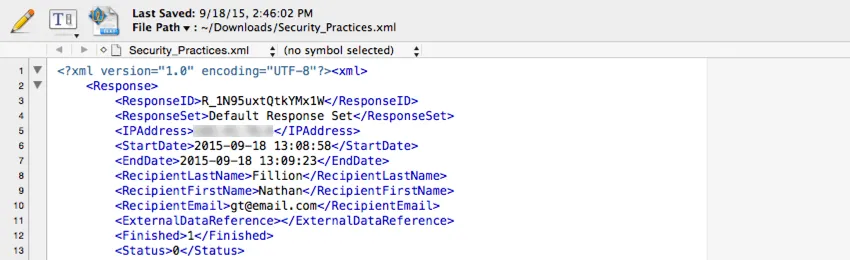
Um elemento XML é fornecido para cada resposta, com um elemento filho para cada parte dos dados armazenados nessa resposta.
Perguntas frequentes
Por que minhas informações da lista de contatos não estão aparecendo nos dados baixados?
Por que minhas informações da lista de contatos não estão aparecendo nos dados baixados?
Se você esqueceu de colocar Dados integrados no Fluxo da pesquisa, pode adicioná-los aos seus dados retroativamente, desde que existam valores na lista de contatos. Consulte a página de suporte de Dados integrados para obter mais instruções.
Observe que se as informações da lista de contatos que você está tentando baixar não tiverem sido incluídas na lista de contatos no momento em que os membros pegaram a pesquisa, a adição retroativa dos campos de Dados integrados ao Fluxo da pesquisa não adicionará essas informações aos dados baixados mais tarde.
Como exporto meus dados para um arquivo CSV ou SPSS?
Como exporto meus dados para um arquivo CSV ou SPSS?
Quais são os números no meu arquivo de dados exportado e posso modificá-los?
Quais são os números no meu arquivo de dados exportado e posso modificá-los?
Como exporto o texto da opção de resposta ou os valores de recodificação que meu respondente selecionou na pesquisa?
Como exporto o texto da opção de resposta ou os valores de recodificação que meu respondente selecionou na pesquisa?
Por que meu arquivo de dados exportado não está mostrando todas as minhas colunas de dados?
Por que meu arquivo de dados exportado não está mostrando todas as minhas colunas de dados?
Os dados também podem ser excluídos da exportação se você tiver um filtro aplicado ao exportar os dados.
Se estiverem faltando informações armazenadas em uma lista de contatos, você deverá se certificar de adicionar Dados integrados ao Fluxo da pesquisa para que sua pesquisa saiba como coletar essas informações. Esses dados integrados podem ser adicionados retroativamente se você se esqueceu da primeira vez. Você pode encontrar instruções para isso na página de suporte Dados integrados.
Se a redação estiver configurada para um tópico, as exportações de dados também ocultarão esses dados?
Se a redação estiver configurada para um tópico, as exportações de dados também ocultarão esses dados?
Por que meus campos de contato foram substituídos por “******”?
Por que meus campos de contato foram substituídos por “******”?
Isso é ótimo! Obrigado pelo seu feedback!
Obrigado pelo seu feedback!