Guia fácil de usar para a regressão logística
O que há nesta página
O que é regressão logística?
A regressão logística estima uma fórmula matemática que relaciona uma ou mais variáveis de entrada a uma variável de saída.
Por exemplo, digamos que você tenha uma barraca de limonada e esteja interessado em saber quais tipos de clientes tendem a voltar. Seus dados incluem uma entrada para cada cliente, sua primeira compra e se eles voltaram no mês avançar para comprar mais limonada. Seus dados podem ter a seguinte aparência:
| Voltar | Idade do cliente | Sexo | Temp. na primeira compra | Cor de limonada | Comprimento da calça |
|---|---|---|---|---|---|
| Não foi | 21 | Masculino | 24 | Rosa | Shorts |
| Devolvido | 34 | Feminino | 20 | Amarelo | Shorts |
| Devolvido | 13 | Feminino | 25 | Rosa | Calças |
| Não foi | 25 | Feminino | 27 | Amarelo | Vestido |
| etc. | etc. | etc. | etc. | etc. | etc. |
Você acha que a “Idade do cliente” (um inputou variável explicativa) pode afetar o “Retorno” (um outputou variável de resposta). A regressão logística pode produzir o seguinte resultado
: Aos 12 anos (a idade mais baixa), a probabilidade de o retorno ser “Devolvido” é de 10%.
Para cada ano adicional de idade, o “Retorno” é 1,1 vezes mais “Retornado”
Esse conhecimento é útil por dois motivos.
Primeiro, ele permite que você entenda um relação: clientes mais antigos têm maior probabilidade de retornar. Esse insight pode levá-lo a direcionar sua publicidade para clientes mais antigos, pois é mais provável que eles se tornem clientes recorrentes.
Em segundo lugar, e de forma relacionada, ele também pode ajudá-lo a fazer previsões específicas. Se um cliente de 24 anos passar por ali, você pode estimar que, se ele comprar uma limonada, há 26% de chance de ele se tornar um cliente recorrente.
Entendendo a multiplicação de probabilidades
Observe que, se disséssemos que “Retornado” era “1,5 vezes mais provável” em alguma situação do que em outra, estaríamos fazendo o seguinte
: As chances eram de 1:9, também escrito 1/(1+9) = 10%.
A “probabilidade para” (o 1) é multiplicada por 1,5.
Agora, 1,5:9, também escrito 1,5/(1,5+9) = 14%.
Outro exemplo, desta vez de passar de 50% de probabilidade para algo 3 vezes mais provável
: As chances eram de 1:1, também escrito 1/(1+1) = 50%.
A “probabilidade para” (o 1 do lado esquerdo) é multiplicada por 3.
Agora, 3:1, também escrito 3/(3+1) = 75%.
Agora, vamos examinar o processo de criação desse modelo de regressão.
Preparação para criar um modelo de regressão
1. Pense na teoria de sua regressão.
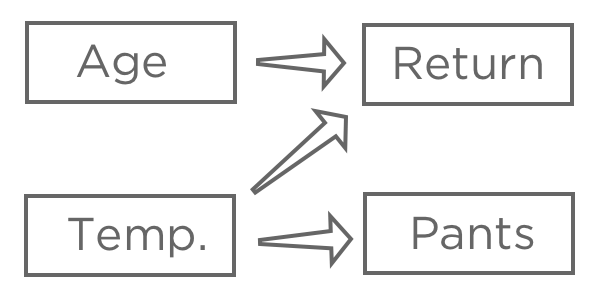
Depois de escolher uma variável de resposta, “Receita“, levante a hipótese de como vários inputs podem estar relacionados a ela. Por exemplo, você pode achar que uma “Temperatura na primeira compra” mais alta levará a uma maior probabilidade de “Devolução”, pode não ter certeza de como a “Idade” afetará a “Devolução” e pode acreditar que a “Calça”(em vez de bermuda) é afetada pela “Temperatura”, mas não tem nenhum impacto na sua barraca de limonada.
{kind=link}
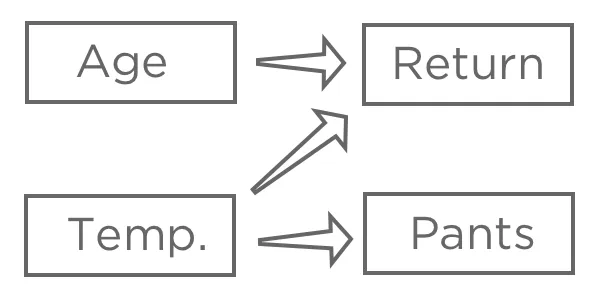
O objetivo da regressão normalmente é entender a relação entre vários inputs e um output, portanto, nesse caso, você provavelmente decidiria criar um modelo que explicasse “Return” (retorno) com “Temperature” (temperatura)e “Age” (idade)(também conhecido como “predicting Return from Temperature and Age” (previsão de retorno a partir da temperatura e da idade),mesmo que você esteja mais interessado na explicação do que na previsão real).
Você provavelmente não incluiria “Pants” em sua regressão. Ela pode estar correlacionada com “Retorno” porque ambas estão relacionadas à “Temperatura”, mas não vem antes de “Retorno” na cadeia causal, portanto, incluí-la confundiria seu modelo.
2. “Descreva” todas as variáveis que possam ser úteis para seu modelo.
Comece descrevendo a variável de resposta, neste caso “Receita”, e tenha uma boa noção dela. Faça o mesmo com suas variáveis explicativas.
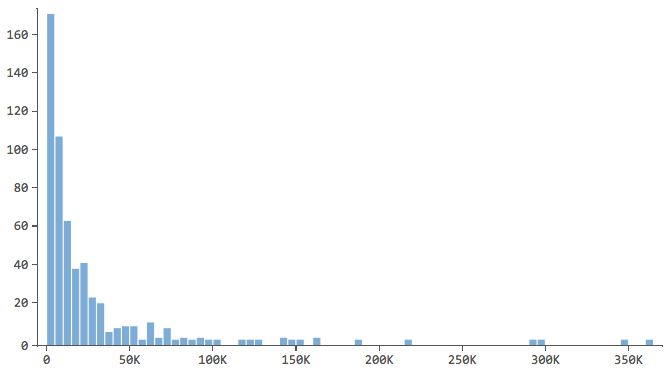
Observe quais têm um formato como este..
{kind=link}
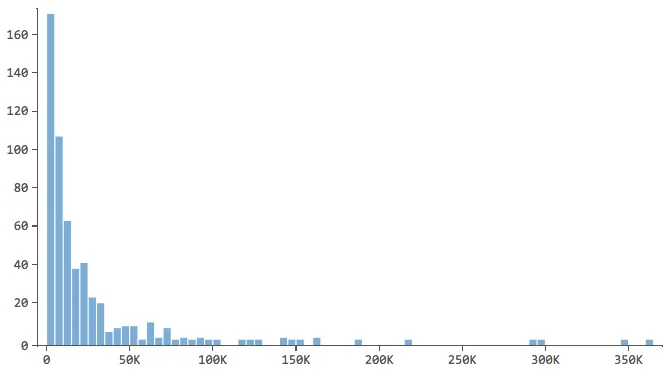
… em que a maioria dos dados está nos primeiros compartimentos do histograma. Essas variáveis exigirão atenção especial posteriormente.
3. “Relacionar” todas as possíveis variáveis explicativas à variável de resposta.
Stats iQ ordenará os resultados de acordo com a força da relação estatística. Dê uma olhada e tenha uma ideia dos resultados, observando quais variáveis estão relacionadas à “Receita” e como.
4. Comece a criar a regressão.
A criação de um modelo de regressão é um processo iterativo. Você passará pelos três estágios a seguir quantas vezes forem necessárias.
As três etapas da criação de um modelo de regressão
Etapa 1: Adicionar ou subtrair uma variável.
Uma a uma, comece a adicionar as variáveis que suas análises anteriores indicaram estar relacionadas à “Receita”(ou adicione as variáveis que você tem um motivo teórico para adicionar). Não é estritamente necessário fazer um por um, mas isso facilita a identificação e a correção de problemas à medida que você avança e ajuda a ter uma noção do modelo.
Digamos que você comece prevendo “Receita” com “Temperatura” Você encontra um relação sólido, avalia o modelo e o considera satisfatório (mais detalhes em um minuto).
Retorno <- TemperaturaVocê
então acrescenta “Cor da limonada” e agora seu modelo de regressão tem dois termos, sendo que ambos são preditores estatisticamente significativos. Assim
:Receita <- Temperatura & Cor da limonadaEm seguida,
você adiciona “Sexo”, e resultados do modelo agora mostram que “Sexo” é estatisticamente significativo no modelo, mas “Cor da limonada” não é mais. Normalmente, você removeria “Lemonade color” do modelo.
Ou
seja, se você souber o sexo do cliente, saber a cor da limonada que ele pediu não lhe dará mais informações sobre se ele será um cliente recorrente.
Você pode investigar e discover que as mulheres tendem a colher limonada amarela mais do que os homens e que as mulheres têm maior probabilidade de retornar. Portanto, inicialmente parecia que escolher a cor amarela aumentava a probabilidade de um cliente retornar, mas, na verdade, a “cor da limonada” só está relacionada a “Retorno” por meio de “Sexo” Portanto, quando você inclui “Sexo” na regressão, a “Cor da limonada” sai da regressão.
A interpretação dos resultados da regressão requer muito discernimento, e o fato de uma variável ser estatisticamente significativa não significa que ela seja de fato causal. Porém, adicionando e subtraindo variáveis com cuidado, observando como o modelo muda e sempre pensando na teoria por trás do modelo, você pode descobrir relações interessantes em seus dados.
Etapa 2: Avaliar o modelo.
Toda vez que adicionar ou subtrair uma variável, você deve avaliar a precisão do modelo observando o r-quadrado (R2), o AICc e quaisquer alertas do Stats iQ. Toda vez que você alterar o modelo, compare os novos gráficos de r-quadrado, AICc e diagnóstico com os antigos para determinar se o modelo melhorou ou não.
R-quadrado (R2)
A métrica numérica para quantificar a precisão da previsão do modelo é conhecida como r-quadrado, que varia entre zero e um. Um zero significa que o modelo não tem valor preditivo, e um um significa que o modelo prevê tudo perfeitamente.
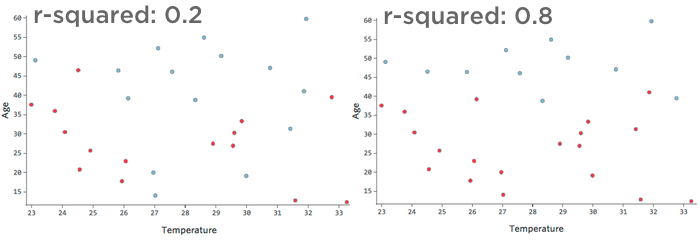
Por exemplo, os dados representados à esquerda levarão a um modelo muito menos preciso do que os dados à direita. Imagine tentar desenhar uma linha no gráfico de dispersão; você poderia separar quase completamente o azul (“Retornou”) do vermelho (“Não retornou”) no lado direito, mas no lado esquerdo seria difícil fazer isso.
Ou seja, o lado direito tem um r-quadrado alto; se você souber “Temperature” (Temperatura) e “Age” (Idade), poderá determinar “Returned” (Devolvido) vs. “Returned” (Retornado). “Não” com bastante facilidade. O lado esquerdo tem um r-quadrado baixo a médio; se você souber “Temperature” (Temperatura) e “Age” (Idade),terá um bom palpite sobre se o produto será “Returned” (Devolvido) ou não. “Não”, mas haverá muitos erros.
{kind=link}

Não há uma definição fixa de um “bom” r-quadrado. Em algumas configurações, pode ser interessante ver qualquer efeito, enquanto em outras, seu modelo pode ser inútil, a menos que seja altamente preciso.
Sempre que você adicionar uma variável, o r-quadrado aumentará, portanto, atingir o maior r-quadrado possível não é o objetivo; em vez disso, você deseja equilibrar a precisão do modelo (r-quadrado) com sua complexidade (geralmente, o número de variáveis nele).
AICc
AICc é uma métrica que equilibra precisão e complexidade – maior precisão leva a melhores pontuações e maior complexidade (mais variáveis) leva a piores pontuações. O modelo com o AICc mais baixo é melhor.
Observe que a métrica AICc só é útil para comparar AICcs de modelos que têm o mesmo número de linhas de dadosea mesma variável de saída.
Alertas
De tempos em tempos, Stats iQ sugerirá maneiras de aprimorar seu modelo. Por exemplo, Stats iQ pode sugerir que você use o logaritmo de uma variável(detalhes sobre o que isso significa).
Matriz confusão e curva de precisão-recall
A matriz de confusão e a curva de precisão-recall também são ferramentas úteis para entender a precisão do seu modelo. E se você quiser fazer previsões com base em seu modelo, essas ferramentas o ajudarão a fazer isso. Elas não são estritamente necessárias para obter uma boa compreensão do que o modelo está dizendo, por isso as colocamos em uma seção diferente sobre a matriz de confusão e a curva de precisão-recall
Etapa 3: Modificar o modelo adequadamente.
Se a sua apreciação do modelo for satisfatória, você terá terminado ou poderá voltar ao Estágio 1 e inserir mais variáveis.
Se a sua apreciação constatar que o modelo não está funcionando, você usará os alertas Stats iQ para corrigir os problemas.
Ao modificar o modelo, observe continuamente as mudanças no r-quadrado, no AICR e nos diagnósticos residuais e decida se as mudanças que você está fazendo estão ajudando ou prejudicando o modelo.
Perguntas frequentes
Como crio uma nova variável do Stats iQ?
Como crio uma nova variável do Stats iQ?
Quais são as opções para analisar meus dados no Stats iQ?
Quais são as opções para analisar meus dados no Stats iQ?
- Descrever: selecionar uma variável da lista e clicar em Descrever fornecerá uma visualização dos dados contidos nessa variável. Use quando você quiser ver como os dados de uma determinada variável são distribuídos.
- Relacionar: selecionar duas variáveis e, em seguida, clicar em Relacionar executará uma análise estatística da relação entre as duas variáveis. Use quando quiser saber a intensidade com que duas variáveis estão correlacionadas.
- Tabela dinâmica: selecionar duas ou mais variáveis e clicar em Tabela dinâmica criará uma tabela que exibe os valores das variáveis como linhas e colunas. As células podem ser configuradas para exibir uma variedade de informações diferentes, incluindo porcentagem de coluna e linha, soma e desvio. Use quando você quiser comparar a sobreposição entre valores específicos de um conjunto de variáveis.
- Regressão: Selecionar duas variáveis e clicar em Regressão dará a relação matemática entre as variáveis. Use quando você quiser prever valores para uma variável com base nos valores de outra.
- Cluster: selecionar de duas a dez variáveis demográficas e clicar em Cluster exibirá agrupamentos de características com maior probabilidade de ocorrer juntas, revelando assim os segmentos populacionais capturados em seus dados.
Não sei o que esse termo estatístico significa. Você pode me dizer?
Não sei o que esse termo estatístico significa. Você pode me dizer?
- Testes estatísticos: ANOVA, teste T e Qui-quadrado são todos testes estatísticos que o Stats iQ realiza para testar se a relação entre duas variáveis é ou não significativa. Estes testes são utilizados para gerar um valor P.
- Valor P: Esse valor representa a probabilidade de que os resultados observados sejam vistos se não houver correlação entre as variáveis. Um valor P mais baixo significa mais dados correlacionados.
- Tamanho do Efeito: O tamanho do efeito é uma medida do tamanho da correlação entre duas variáveis. Isso é medido de diferentes formas, dependendo do tipo de teste estatístico realizado. Exemplos são o d de Cohen, r de Pearson e v de Cramer. Quanto maior o valor do tamanho do efeito, mais correlacionadas são as variáveis.
Como filtro os dados que aparecem no Stats iQ?
Como filtro os dados que aparecem no Stats iQ?
Como faço para que minhas novas respostas apareçam no Stats iQ?
Como faço para que minhas novas respostas apareçam no Stats iQ?
Como os cartões de análise são pedidos no meu espaço de trabalho do Stats iQ?
Como os cartões de análise são pedidos no meu espaço de trabalho do Stats iQ?
O que é Stats iQ? / Onde está o Statwing?
O que é Stats iQ? / Onde está o Statwing?
O que faço se meus dados não estiverem sendo carregados corretamente?
O que faço se meus dados não estiverem sendo carregados corretamente?
Isso é ótimo! Obrigado pelo seu feedback!
Obrigado pelo seu feedback!