-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Guia fácil de usar para regressão linear
O que é regressão?
A regressão estima uma fórmula matemática que relaciona uma ou mais variáveis de entrada a uma variável de saída.
Por exemplo, digamos que você tenha uma barraca de limonada e esteja interessado em saber o que gera receita. Seus dados incluem a “Receita” de cada dia, a alta “Temperatura”, o “Número de crianças que passaram”, o “Número de adultos que passaram”, a “Sinalização” que você usou naquele dia e uma “Receita do concorrente” próxima
| Receita | Temperatura (Celsius) | Minutos de intervalo | Número de crianças que passaram pelo local | Número de adultos que passaram pelo local | Sinalização | Receita do concorrente |
|---|---|---|---|---|---|---|
| US$ 44 | 28,2 | 30 | 43 | 380 | Pintado à mão | $20 |
| US$ 23 | 21,4 | 42 | 28 | 207 | LED | US$ 30 |
| US$ 43 | 32,9 | 14 | 43 | 364 | Pintado à mão | $34 |
| US$ 30 | 24,0 | 24 | 18 | 103 | LED | $15 |
| etc. | etc. | etc. | etc. | etc. | etc. | etc. |
Você acha que a “Temperatura” (um inputou variável explicativa) pode afetar a “Receita” (um outputou variável de resposta). Quando você usa a regressão para analisar essa relação, ela pode produzir a seguinte fórmula
:Receita = 2,71 * Temperatura – 35Essa
fórmula é útil por dois motivos.
Primeiro, ele permite que você entenda uma relação: dias mais quentes levam a mais “receita” Em particular, o valor de 2,71 antes de “Temperatura” (chamado de coeficiente) significa que, para cada grau de aumento de “Temperatura”, haverá, em média, US$ 2,71 a mais de “Receita” Essa percepção pode levá-lo a decidir não vender limonada em dias frios.
Em segundo lugar, e de forma relacionada, ele também pode ajudá-lo a fazer previsões específicas. Se a “Temperatura” for 24, você poderia estimar que, como…
Receita = 2,71 * Temperatura – 35
Receita = 2,71 * 24 – 35
Receita = 30
… você terá cerca de US$ 30 em “Receita” Essa pode ser uma informação útil para saber se você conseguirá fazer um pagamento naquele dia, supondo que você tenha certeza de que seu modelo é preciso.
Agora, vamos examinar o processo de criação dessa equação de regressão.
Preparação para criar um modelo de regressão
1. Pense na teoria de sua regressão
Depois de escolher uma variável de resposta, “Receita“, levante a hipótese de como vários inputs podem estar relacionados a ela. Por exemplo, você pode achar que uma “Temperatura” mais alta levará a uma “Receita” mais alta, pode não ter certeza de como várias sinalizações afetarão a “Receita” e pode acreditar que as “Vendas do concorrente” são afetadas pela “Temperatura”, mas não têm nenhum impacto sobre a sua barraca de limonada.
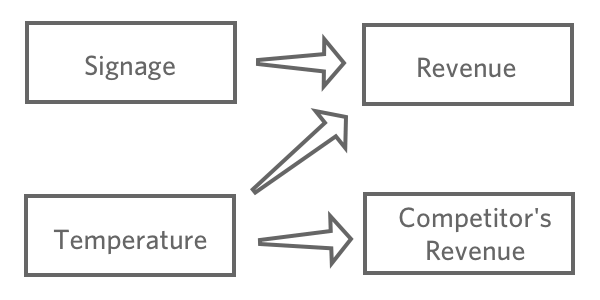
O objetivo da regressão normalmente é entender a relação entre várias entradas e uma saída, portanto, nesse caso, você provavelmente decidiria criar um modelo que explicasse a “Receita” com a “Temperatura”e a “Sinalização”(também conhecida como “previsão de receita a partir da temperatura e da sinalização“, mesmo que você esteja mais interessado na explicação do que na previsão real).
Você provavelmente não incluiria “Vendas do concorrente” em sua regressão. É provável que esteja correlacionada com “Receita”, mas não vem antes dela na cadeia causal, portanto, incluí-la confundiria seu modelo.
2. “Descreva” todas as variáveis que possam ser úteis para seu modelo
Comece descrevendo a variável de resposta, neste caso “Receita”, e tenha uma boa noção dela. Faça o mesmo com suas variáveis explicativas.
Observe quais têm um formato como este..
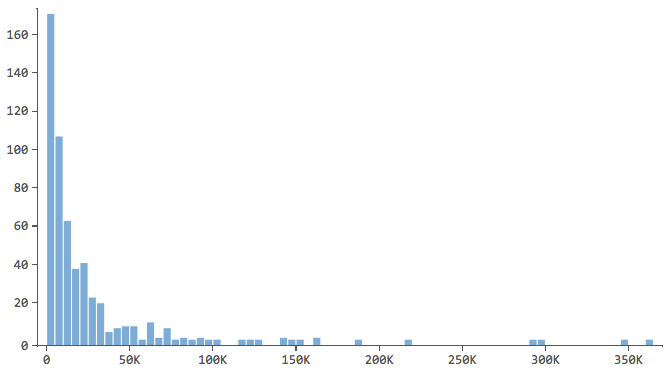
… em que a maioria dos dados está nos primeiros compartimentos do histograma. Essas variáveis exigirão atenção especial posteriormente.
3. “Relacionar” todas as possíveis variáveis explicativas à variável de resposta
Stats iQ ordenará os resultados de acordo com a força da relação estatística. Dê uma olhada e tenha uma ideia dos resultados, observando quais variáveis estão relacionadas à “Receita” e como.
Se você já tiver uma boa ideia de quais variáveis devem teoricamente direcionar o resultado (por exemplo, de trabalhos acadêmicos anteriores), pule esta etapa. Mas se a sua análise for de natureza um pouco mais exploratória (como uma pesquisa com clientes), essa é uma etapa útil e importante.
4. Comece a criar a regressão
A criação de um modelo de regressão é um processo iterativo. Você passará pelos três estágios a seguir quantas vezes forem necessárias.
As três etapas da criação de um modelo de regressão
Etapa 1: Adicionar ou subtrair uma variável
Uma a uma, comece a adicionar as variáveis que suas análises anteriores indicaram estar relacionadas à “Receita” (ou adicione as variáveis que você tem um motivo teórico para adicionar). Não é estritamente necessário fazer um por um, mas isso facilita a identificação e a correção de problemas à medida que você avança e ajuda a ter uma noção do modelo.
Digamos que você comece prevendo “Receita” com “Temperatura” Você encontra um relação sólido, avalia o modelo e o considera satisfatório (mais detalhes em um minuto).
Receita = 2,71 * Temperatura – 35Você
então acrescenta “Número de crianças que passaram por aqui” e agora seu modelo de regressão tem dois termos, ambos preditores estatisticamente significativos. Assim
:Receita = 2,5 * Temperatura +
0
,3 * NumberOfChildrenWhoWalkedBy – 12Em seguida,
você adiciona “Number of adults who walked by”, e resultados do modelo agora mostram que “Number of adults” é estatisticamente significativo no modelo, mas “Number of children” não é mais. Normalmente, você removeria “Number of children” (Número de filhos) do modelo. Agora nós temos:
Receita = 2,6 * Temperatura + 0,4 * Número de adultos que caminharam por– 14
Isso significa que “Número de adultos” é o melhor indicador de “Receita”; ou seja, se você sabe quantos adultos aparecem, saber quantas crianças aparecem não acrescenta nenhuma informação nova – não ajuda a prever as vendas.
Talvez você se lembre de que as crianças nunca compram sua limonada, portanto, faz sentido que essa variável não faça parte do modelo.
Mas por que isso foi estatisticamente significativo no primeiro modelo? Provavelmente porque o “Número de crianças” está correlacionado com o “Número de adultos” e, como o “Número de adultos” ainda não estava no modelo, o “Número de crianças”estava agindo como um substituto aproximado do “Número de adultos”
A interpretação dos resultados da regressão requer muito discernimento, e o fato de uma variável ser estatisticamente significativa não significa que ela seja de fato causal. Porém, adicionando e subtraindo variáveis com cuidado, observando como o modelo muda e sempre pensando na teoria por trás do modelo, você pode descobrir relações interessantes em seus dados.
Etapa 2: Avaliar o modelo
Toda vez que adicionar ou subtrair uma variável, você deve avaliar a precisão do modelo observando o r-quadrado (R2), o AICR e os gráficos residuais. Toda vez que você alterar o modelo, compare os novos gráficos de r-quadrado, AICR e residual com os antigos para determinar se o modelo melhorou ou não.
R-quadrado (R2)
A métrica numérica para quantificar a precisão da previsão do modelo é conhecida como r-quadrado, que varia entre zero e um. Um zero significa que o modelo não tem valor preditivo, e um um significa que o modelo prevê tudo perfeitamente.
Por exemplo, o modelo à esquerda é mais preciso do que o da direita; ou seja, se você souber “Temperatura”, terá uma boa estimativa de qual será a “Receita”à esquerda, mas não à direita.
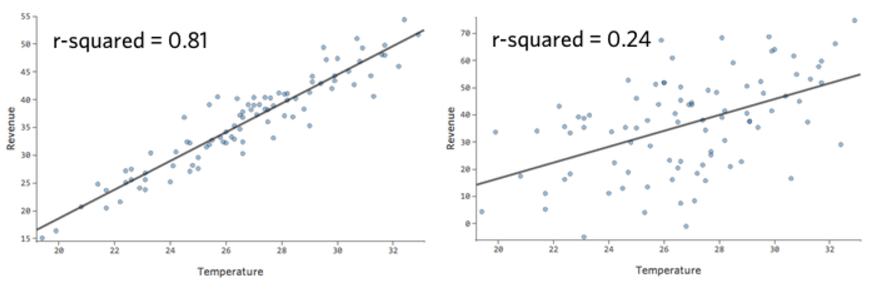
Não há uma definição fixa de um “bom” r-quadrado. Em algumas configurações, pode ser interessante ver qualquer efeito, enquanto em outras, seu modelo pode ser inútil, a menos que seja altamente preciso.
Sempre que você adicionar uma variável, o r-quadrado aumentará, portanto, atingir o maior r-quadrado possível não é o objetivo; em vez disso, você deseja equilibrar a precisão do modelo (r-quadrado) com sua complexidade (geralmente, o número de variáveis nele).
AICR
O AICR é uma métrica que equilibra precisão e complexidade – maior precisão leva a melhores pontuações, maior complexidade (mais variáveis) leva a piores pontuações. O modelo com o AICR mais baixo é melhor.
Observe que a métrica AICR só é útil para comparar AICRs de modelos que têm o mesmo número de linhas de dadosea mesma variável de saída.
Intervalos de previsão
Outra maneira útil de ter uma ideia da precisão de seu modelo é inserir valores amostra em sua fórmula e ver o intervalo de previsão que Stats iQ calcula. Por exemplo, se você inserir o número 30 na fórmula, Stats iQ informará que o valor previsto é 45,5, mas o intervalo de confiança de 95% é de 36,4 a 54,5, o que significa que você pode ter 95% de certeza de que, se amanhã estiver 30 graus, você obterá entre US$ 36,40 e US$ 54,50 em “Receita” Você poderia imaginar um modelo mais preciso em que o intervalo de previsão fosse uma faixa estreita, como de US$ 44 a US$ 48, ou um modelo menos preciso em que o intervalo fosse amplo, como de US$ 20 a US$ 72.
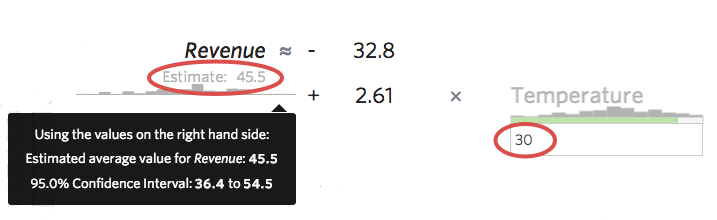
Essa abordagem só é útil quando seus gráficos residuais parecem saudáveis (veja abaixo), caso contrário, eles serão imprecisos.
Residuais
Os resíduos são a principal ferramenta de diagnóstico para avaliar e melhorar a regressão, portanto, há uma seção separada sobre como interpretar os resíduos para melhorar o modelo. Você aprenderá ou refrescará sua memória sobre o que são resíduos, como usá-los para avaliar e aprimorar o modelo e como pensar sobre a precisão que você precisa que seu modelo tenha.
Recomendamos que você o leia na íntegra, pois ele abordará tudo o que você precisa para produzir um modelo excelente. Mas você sempre pode voltar a ele, é claro.
Etapa 3: Modificar o modelo adequadamente
Se a sua apreciação do modelo for satisfatória, você terá terminado ou poderá voltar ao Estágio 1 e inserir mais variáveis.
Se a sua apreciação constatar que o modelo não é adequado, você usará os alertas Stats iQ e a seção de diagnóstico residual para corrigir os problemas.
Ao modificar o modelo, observe continuamente as mudanças no r-quadrado, no AICR e nos diagnósticos residuais e decida se as mudanças que você está fazendo estão ajudando ou prejudicando o modelo.