Clusters de MaxDiff
O que há nesta página
Sobre o MaxDiff Clustering
Dentro das populações de respondentes pesquisa, há grupos de pessoas com a mesma opinião. Esses grupos, ou “clusters”, podem ser determinados pela semelhança entre os recursos preferidos de cada entrevistado. Ao agrupar cada respondente com base em sua utilidade individual para cada atributo, podemos determinar subpopulações e quais dados demográficos compõem essas subpopulações.
Qdica: esse característica é incrivelmente útil quando você está procurando definir segmentos.
Preparação de uma Pesquisa para clustering
Antes de usar o MaxDiff clustering, é preciso ter certeza de que a pesquisa do seu projeto MaxDiff está fazendo as perguntas certas. Isso significa que você precisa configurar determinados recursos antes de coletar dados.
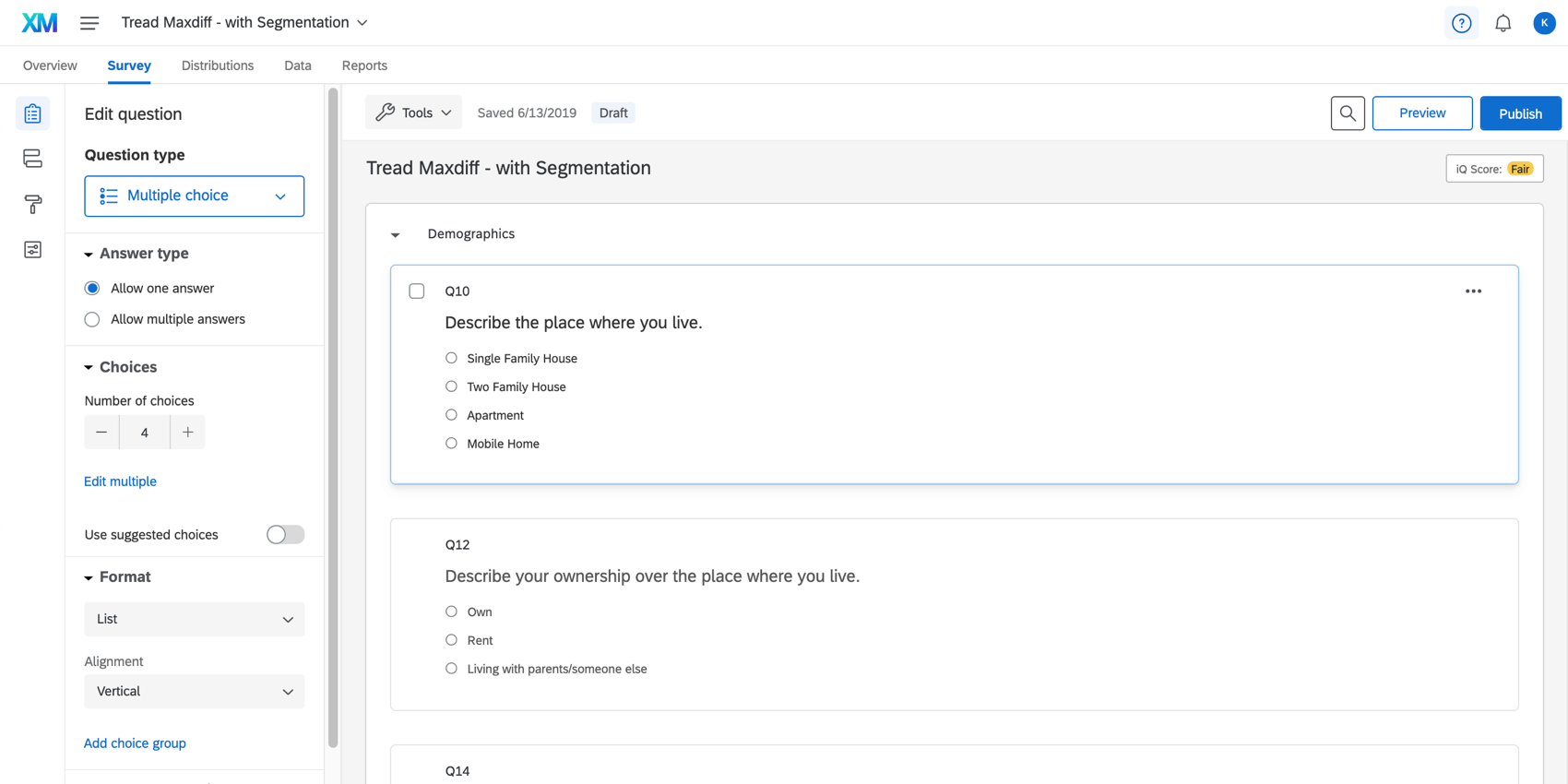
Na guia Pesquisa, verifique se adicionou perguntas a um bloco não-MaxDiff. No exemplo abaixo, o bloco Demografia tem uma pergunta sobre idade, o número de pessoas na casa do respondente e muito mais.
{kind=link}
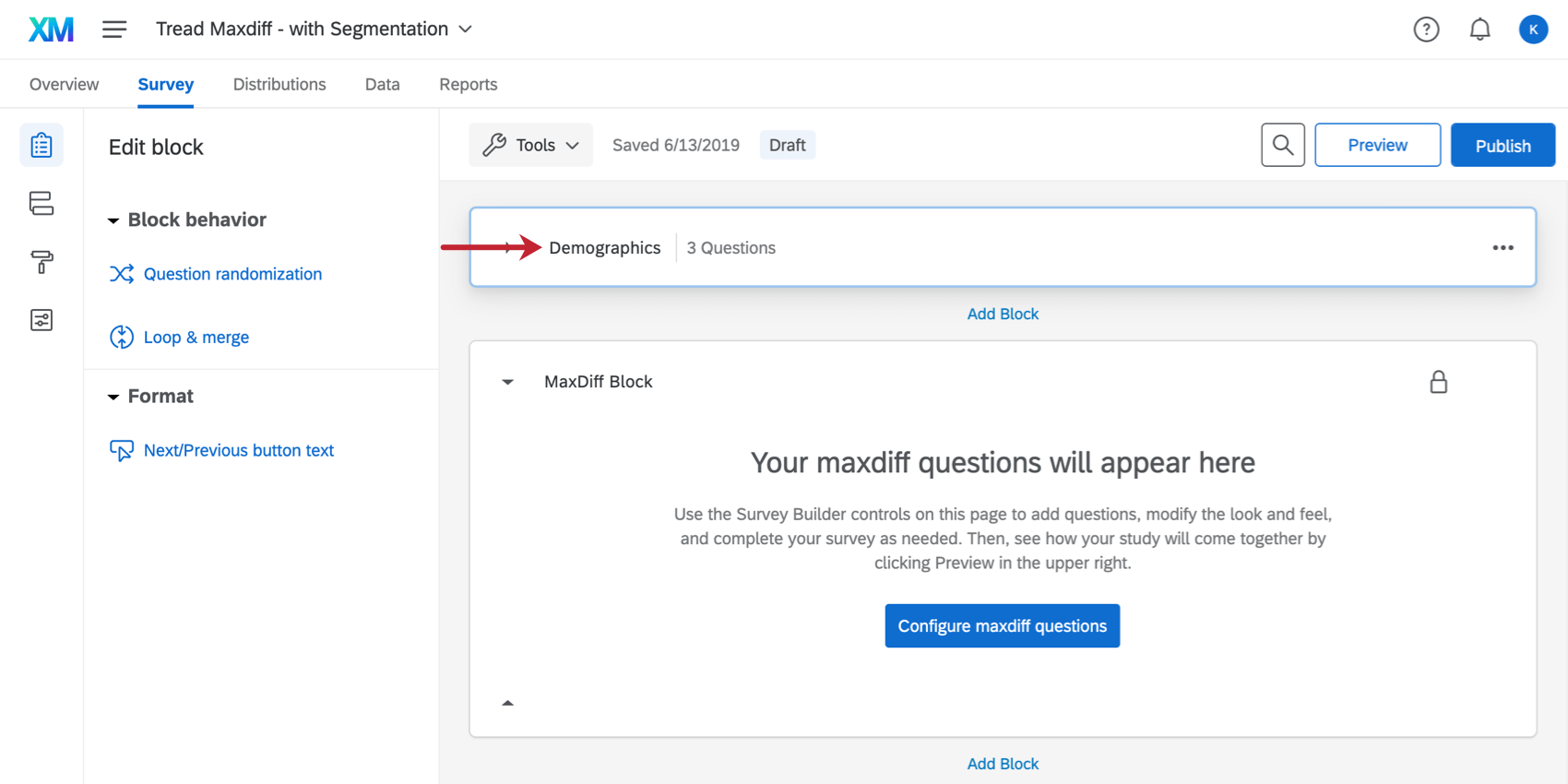
O bloco Demographics está localizado logo acima do bloco MaxDiff, embora você possa movê-lo conforme desejar.
{kind=link}
Formatação de perguntas
Você só pode realizar o MaxDiff clustering usando perguntas múltipla escolha de seleção única. Isso ocorre porque eles oferecem uma seleção finita de opções que podem ser facilmente analisadas.
- Dados demográficos: Pergunte sobre informações descritivas básicas, como idade, faixa de renda, raça ou gênero.
- Comportamento: Pergunte como os clientes interagem com sua marca e seus produtos, ou sobre comportamentos que possam estar relacionados ao comportamento de compra deles. Por exemplo, você pode perguntar com que frequência o cliente vai às compras.
- Dadosoperacionais : São informações como o tempo gasto em seu site ou o tempo de permanência de um colaborador em sua empresa.
- Formatos de perguntas: Formate as perguntas sobre comportamentos e crenças como escalas. O intervalo em uma escala pode nos ajudar a entender quais pontos da escala estão correlacionados e, portanto, mais ou menos no mesmo cluster; perguntas do tipo Sim/Não e de seleção única não são tão úteis para a análise cluster. Exemplo: Se você perguntar “Que tipo de comprador você é?” e der as opções “Prefere fazer compras em shoppings”, “Prefere fazer compras on-line” e “Prefere fazer compras em butiques”, o algoritmo de agrupamento desejará dividir os entrevistados em três grupos, um para cada resposta. Se, em vez disso, você fizer uma série de perguntas (por exemplo, “Você gosta de fazer compras em shoppings?”) com respostas de 1 a 7, o algoritmo de agrupamento fará um trabalho melhor para realmente discernir o que separa os diferentes compradores uns dos outros.

Qdica: Quando terminar de adicionar perguntas, não se esqueça de publicar.
Habilitação de clusters
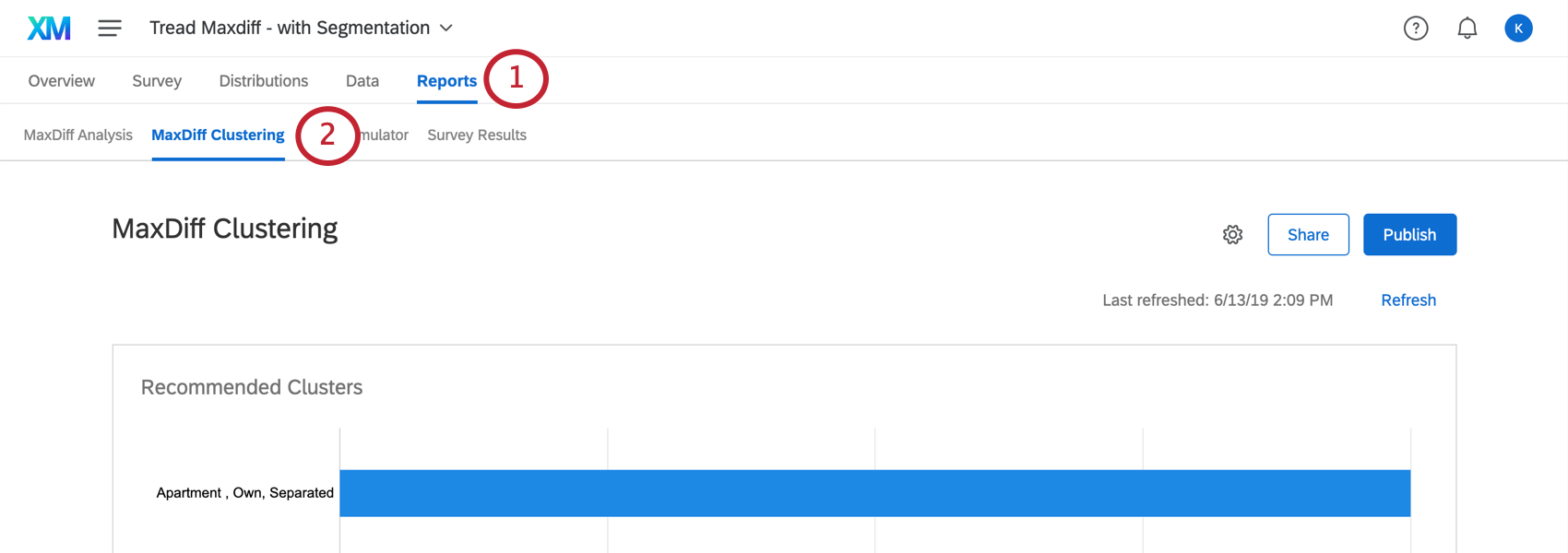
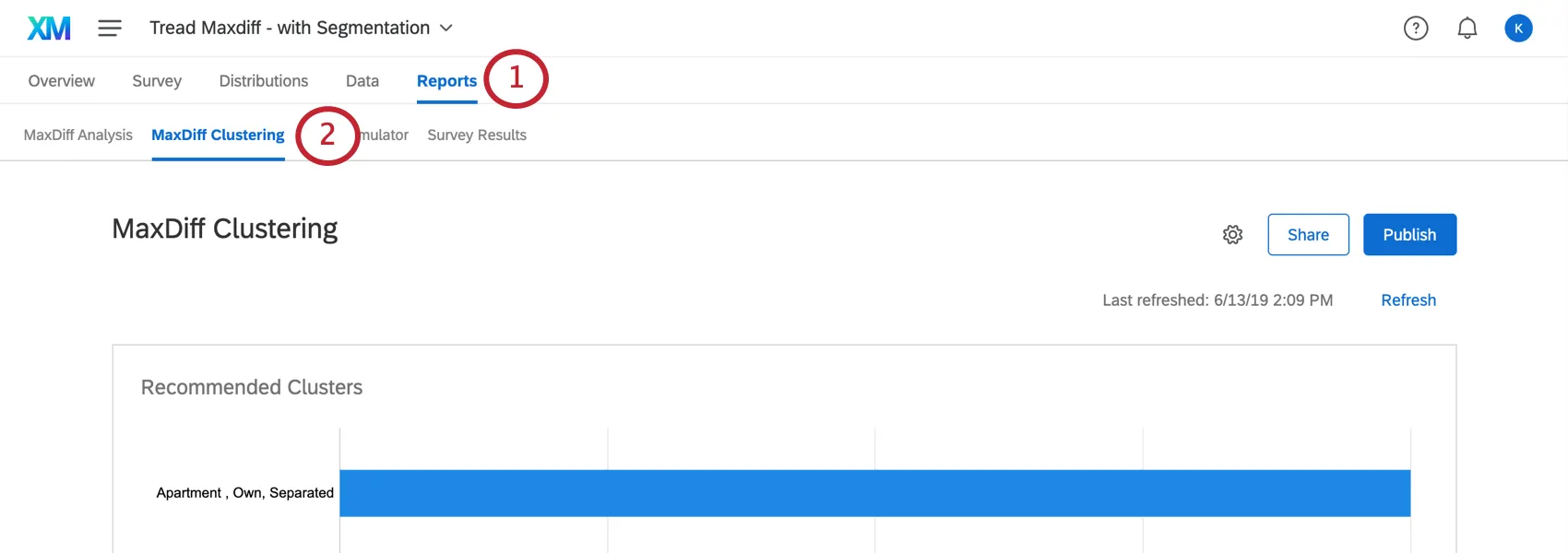
O agrupamento pode ser encontrado na seção MaxDiff Clustering da guia Relatórios .
{kind=link}
Para que os dados apareçam pela primeira vez, talvez seja necessário clicar em Refresh (Atualizar ) na seção MaxDiff Analysis (Análise do MaxDiff ).
{kind=link}

Qdica: assim como relatórios de análise MaxDiff, o relatório de clustering MaxDiff é atualizado a cada hora.
Ajuste dos dados demográficos usados no clustering
Por padrão, o agrupamento MaxDiff usará todas as perguntas pesquisa múltipla escolha que você tiver feito no questionário. No entanto, você não precisa usar todas as perguntas se não quiser, e pode adicionar e remover conteúdo para ver quais clusters diferentes esse característica recomenda para você.
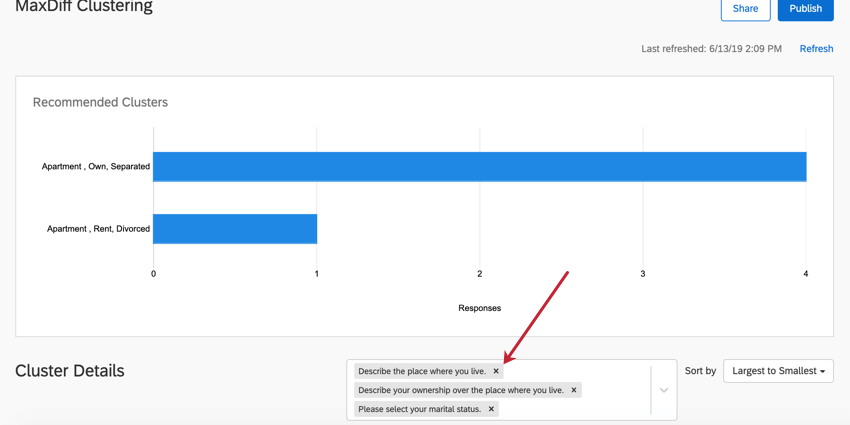
Remoção de dados demográficos
Na caixa à direita do cabeçalho Detalhes Cluster, clique no X em uma pergunta para removê-la da análise cluster. A remoção de uma pergunta não faz com que os clusters sejam recalculados.
{kind=link}
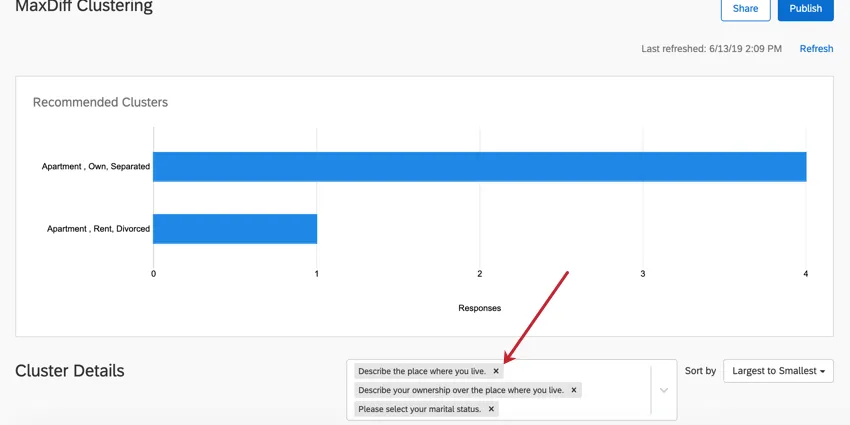
Adição de dados demográficos
Na caixa à direita do cabeçalho Cluster Details (Detalhes do cluster ), clique na seta suspensa. Em seguida, selecione as perguntas que você gostaria de adicionar novamente aos clusters.
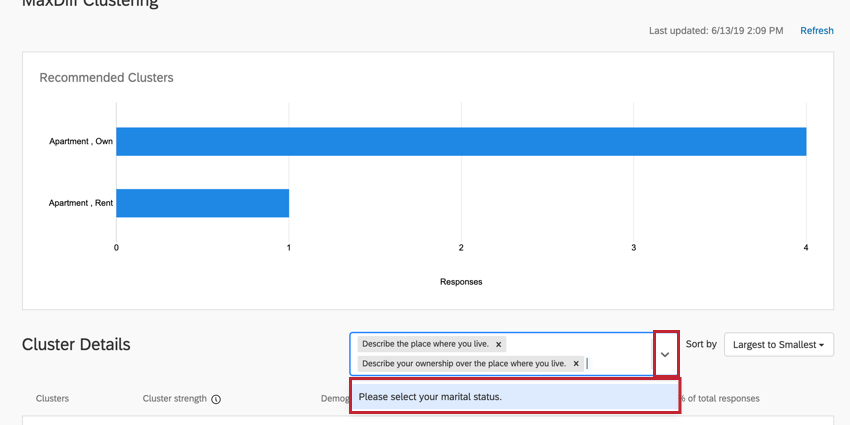{kind=link}

Clusters recomendados
Depois de coletar dados suficientes e atualizar a página de clustering MaxDiff, esse característica recomendará clusters para você. Esses clusters são determinados com base na semelhança entre os recursos preferidos dos entrevistados. Sua utilidade individual para cada atributo é calculada e, em seguida, os dados demográficos comuns entre esses grupos são destacados para que você possa entender melhor como diferentes populações preferem seus produtos.
Destaque um cluster no gráfico superior para saber mais sobre esse cluster. Clique nele para abrir os detalhes cluster abaixo.
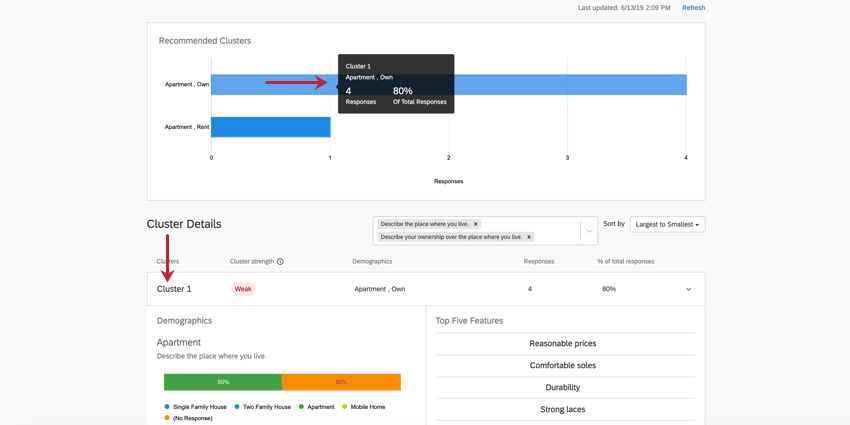{kind=link}

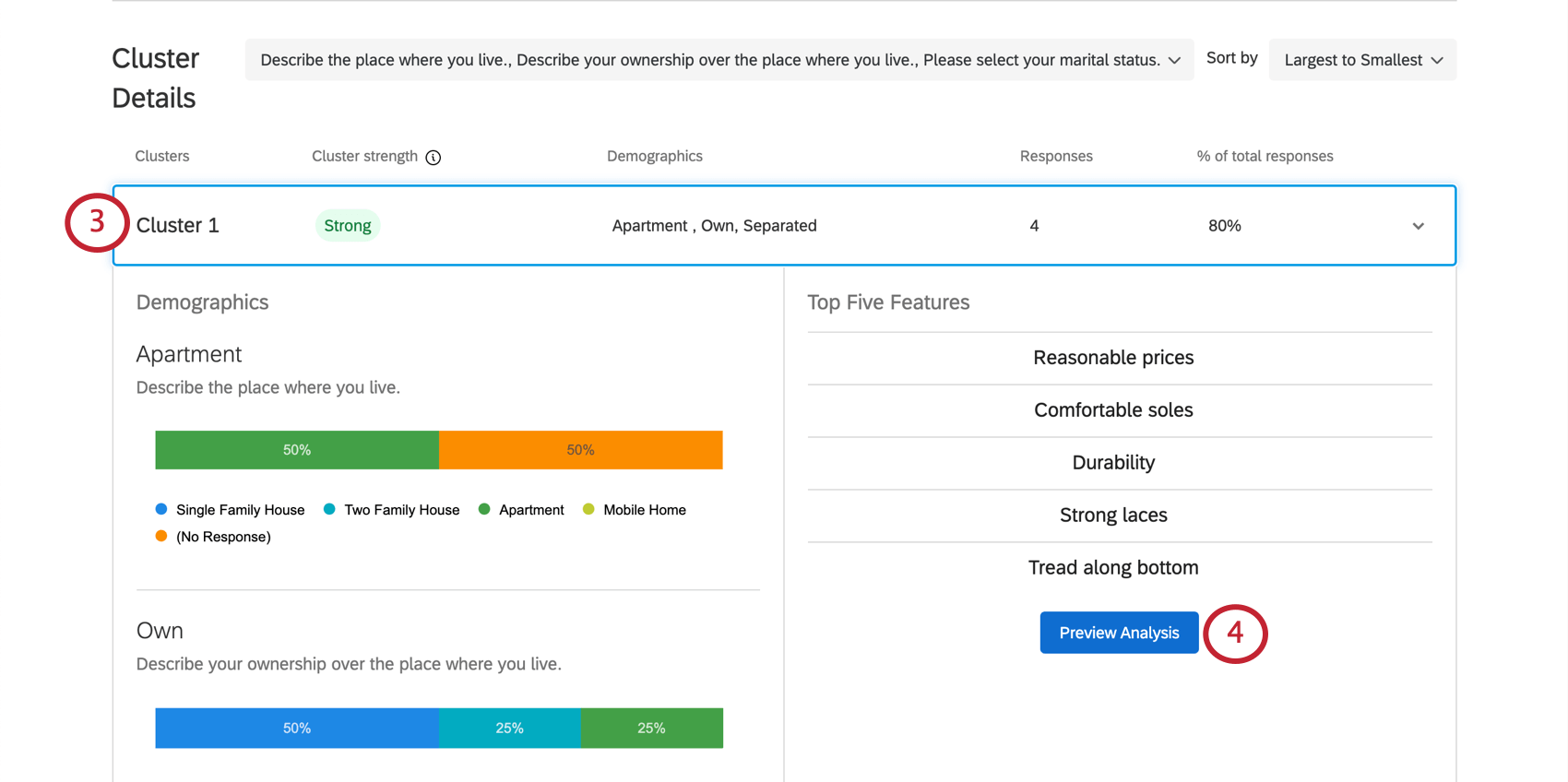
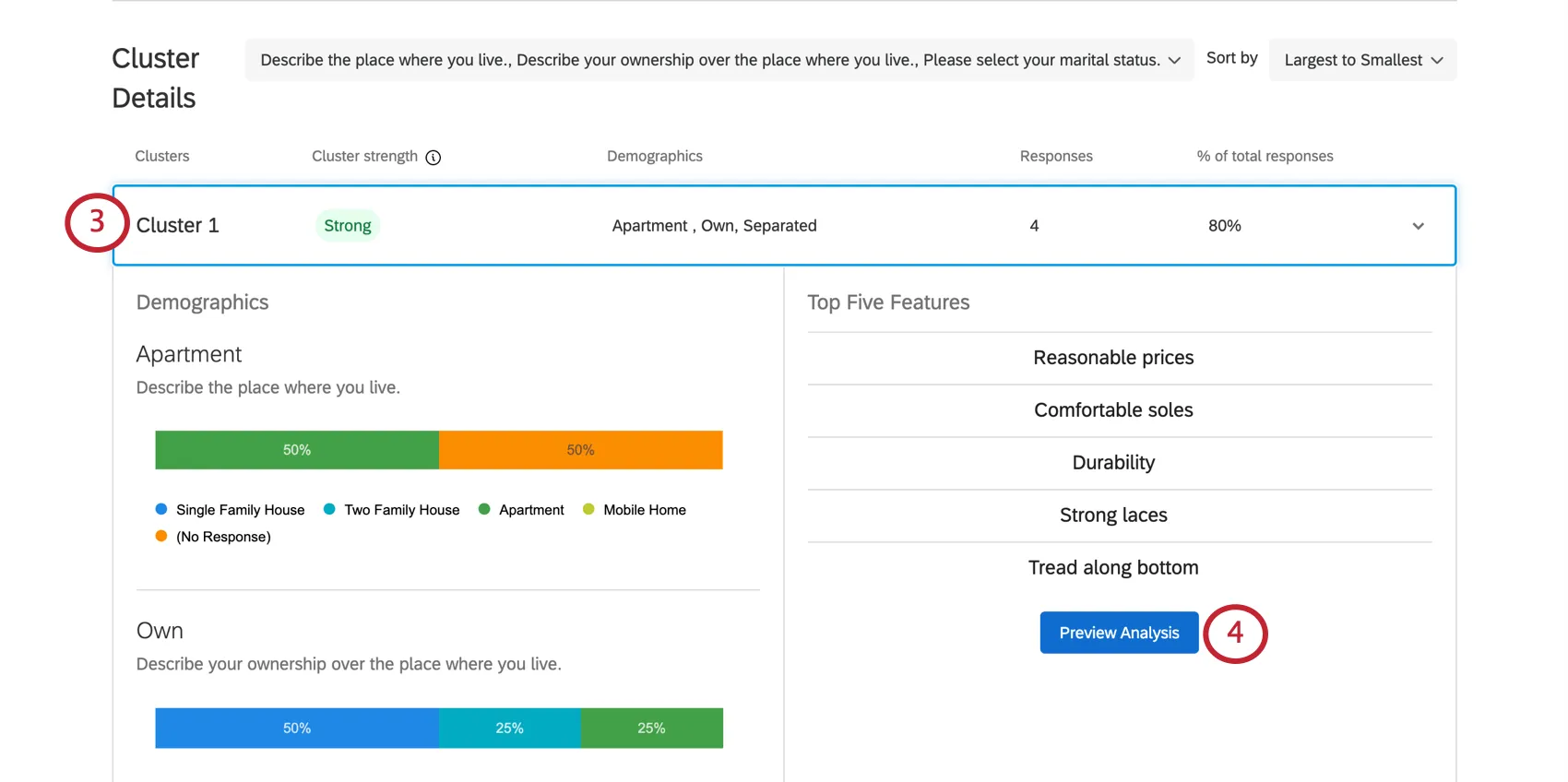
Detalhes do cluster
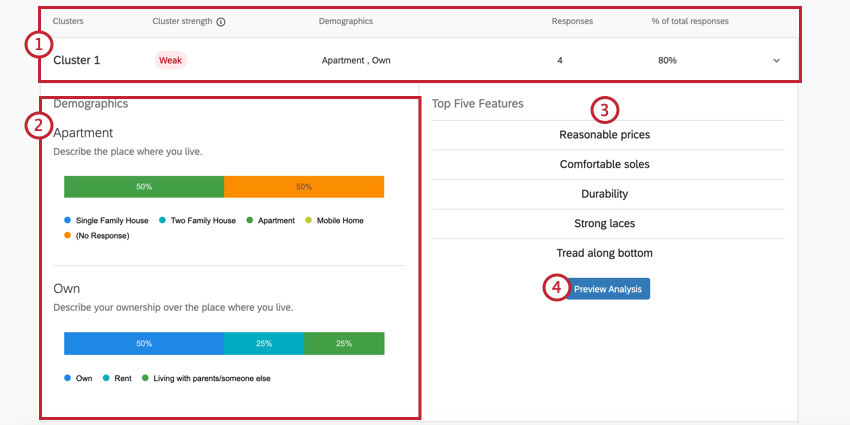{kind=link}

Exemplo: No Cluster 1 mostrado aqui, as respostas tendem a ser de pessoas que possuem seu próprio apartamento. em geral, 4 respondentes se encaixam nesse padrão, o que representa 80% de todo o conjunto de dados. Esse é um conjunto de dados muito pequeno, portanto, provavelmente não se deve tomar decisões com base nesses resultados. Isso também é indicado pela fraca força do cluster.
Exemplo: A renda anual do Cluster 1 está listada como “$20.000 – $29.000” Entretanto, essa não é a renda anual mais comum para esse cluster, pois podemos ver que a barra de “US$ 70.000 – US$ 79.000” no final é muito mais longa. Isso se deve ao fato de que as pessoas com renda mais baixa simplesmente têm maior probabilidade de valorizar preços razoáveis, durabilidade e assim por diante do que as pessoas do cluster com renda anual mais alta.
Qdica: Lembre-se de que os “Dados demográficos” nesses gráficos são as perguntas não-MaxDiff que você criou na guia Pesquisa.
Determinação da força Cluster
O Qualtrics usa uma métrica chamada pontuação de silhueta para determinar a força de cada cluster. Essa pontuação produz um valor entre 0 e 1 que determina a proximidade entre os entrevistados. Usamos a tabela a seguir para converter a pontuação da silhueta em força cluster:
| Pontuação de correlação | Força Relação | Etiqueta de força Cluster |
|---|---|---|
| 0.71 a 1,0 | relação muito forte | Forte |
| 0.51 a 0,70 | relação um pouco forte | Moderadamente forte |
| 0.26 a 0,50 | relação um pouco fraca | Um pouco fraco |
| 0 a 0,25 | Nenhuma relação significativa | Fraco |
Aplicação de clusters a Relatórios
Os clusters podem ser aplicados ao relatório MaxDiff Analysis para que você possa ver detalhes mais específicos sobre como os entrevistados desse cluster avaliaram os atributos apresentados a eles.
Na seção Análise de MaxDiff da guia Relatórios, selecione um cluster no menu suspenso Segmentos no canto superior esquerdo.
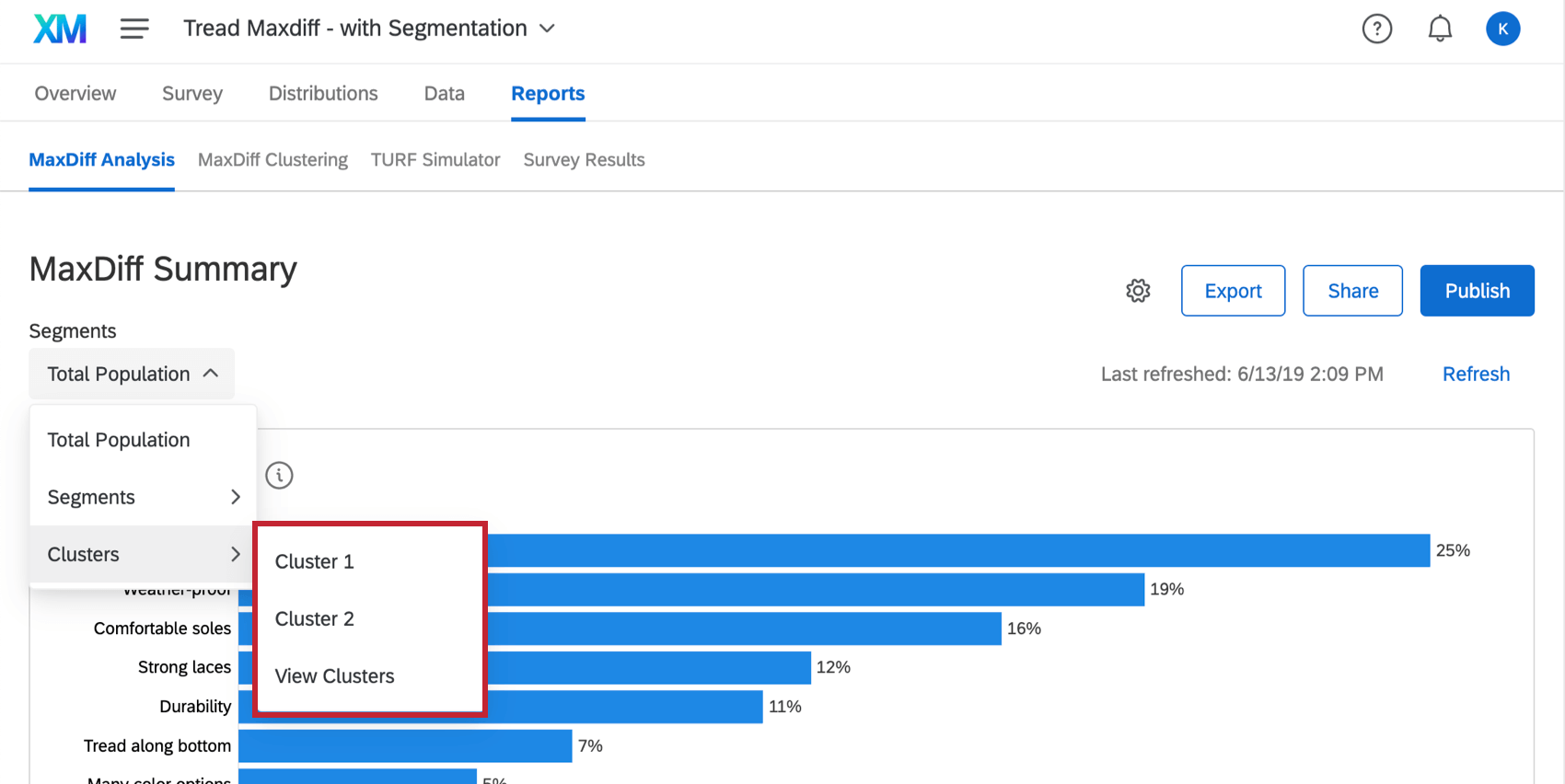{kind=link}
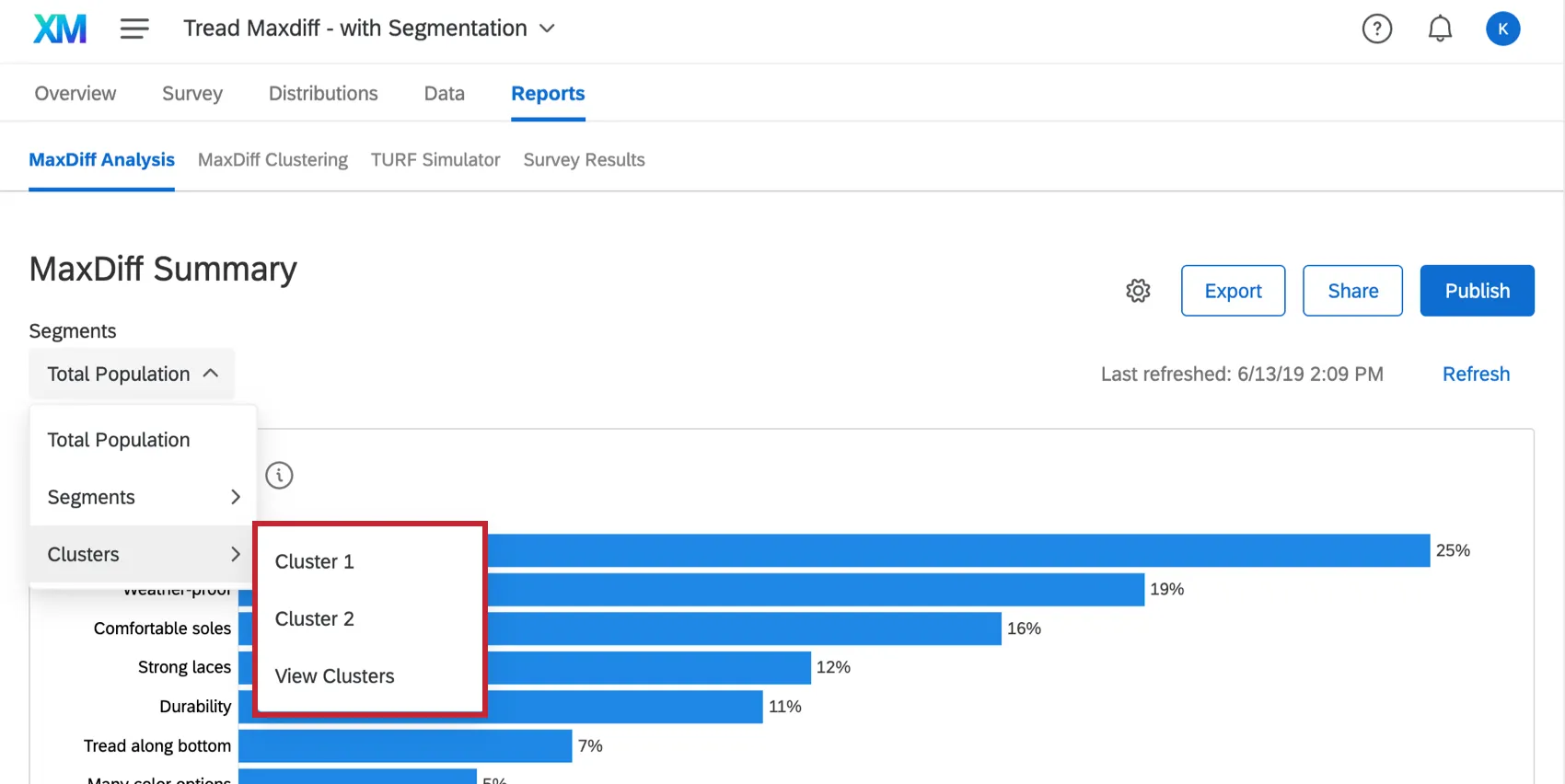
Você também pode selecionar Preview Analysis quando tiver um cluster selecionado na seção MaxDiff Clustering da guia Relatórios.
{kind=link}
{kind=link}
Isso é ótimo! Obrigado pelo seu feedback!
Obrigado pelo seu feedback!