-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Uso e edição da fonte de dados do Marca Tracker
Sobre o uso e a edição da fonte de dados do Marca Tracker
Os programas BX coletam dados sobre sua marca, além das marcas concorrentes e do mercado em geral, o que faz com que o conjunto de dados seja mais complexo do que os projetos padrão. Os programas BX usam um conjunto de dados empilhados (Marca Tracker Data Source, ou BTDS) para identificar insights em seus dados com mais facilidade.
Entendendo a fonte de dados BX
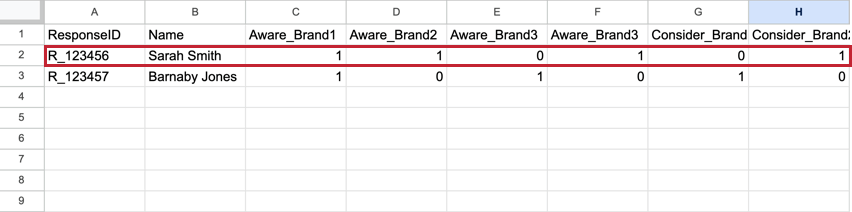
O BTDS varia em relação ao que você veria em um conjunto de dados padrão. Em um conjunto de dados padrão, cada entrevistado tem uma linha que contém todas as respostas às suas respostas, com a métrica de cada marca como sua própria coluna. Esses conjuntos de dados tendem a ser muito amplos, com centenas de colunas.
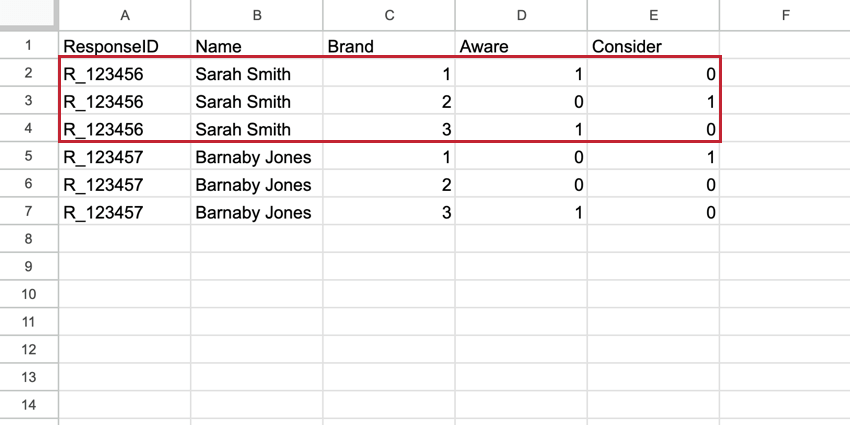
No BTDS, Marca se torna uma coluna de primeira classe no conjunto de dados e cada entrevistado tem uma linha para cada marca. A linha da marca contém todos os dados dessa única marca. Esses conjuntos de dados têm mais linhas do que o conjunto de dados padrão, mas têm muito menos colunas, o que facilita a leitura.
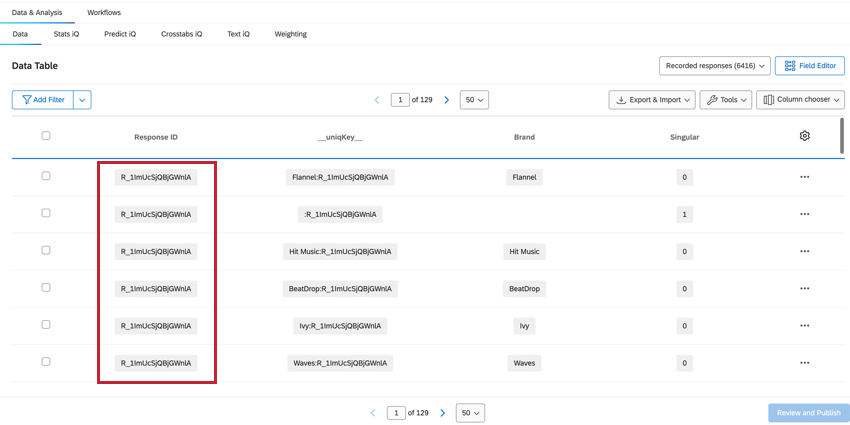
RESPONSEID
O campo ResponseID nos ajuda a identificar quais linhas pertencem ao mesmo respondente. Esse valor é do envio original pesquisa e é repetido para cada linha pertencente a esse respondente.
SINGULAR
A contagem de Respostas registradas na guia Dados & amp; Análise nos dará a contagem total de todas as linhas, que será maior do que o número total de respondentes exclusivos. Para determinar os únicos respondentes, podemos filtro pelo campo Singular.
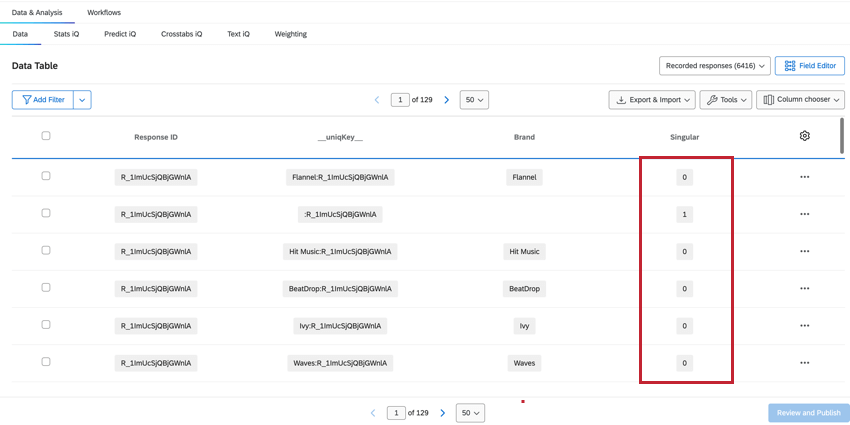
- Quando Singular = 1, são exibidas linhas exclusivas de respondentes sem informações sobre marca. Há uma única linha de respondente por resposta.
Qdica: Criar um filtro para Singular = 1 mostrará o número de questionados individuais.
- Quando Singular = 0, a linha contém dados marca. Há várias linhas de dados de marca para cada respondente.
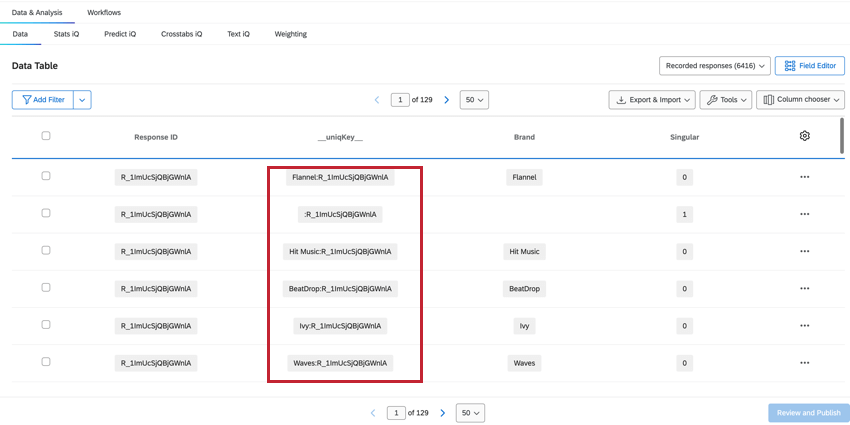
UNIQKEY
O campo __uniqKey__ combina o ResponseID e o nome marca, mostrado como BrandName:ResponseID. Para a linha exclusiva do respondente sem informações de marca, a mesma linha em que Singular = 1, a __uniqKey__ será :ResponseID. Isso é útil para restringir a resposta exata da qual esses dados são provenientes, bem como a marca sobre a qual eles fornecem feedback especificamente.
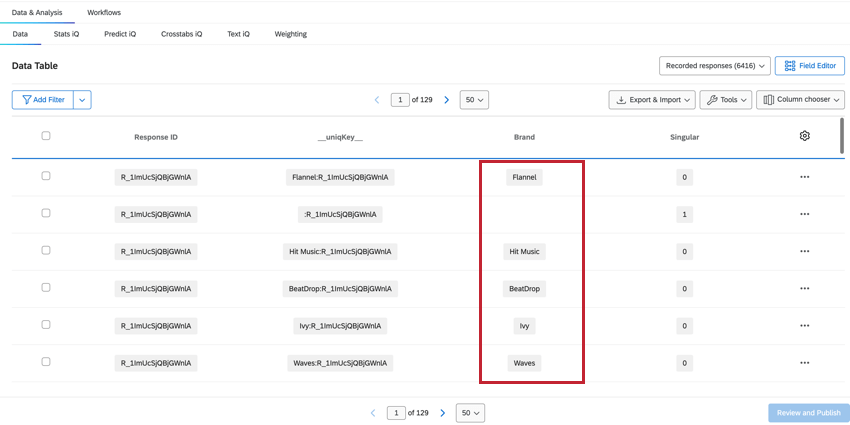
MARCA
O campo Marca mostra a qual marca os dados dessa coluna se referem, o que lhe permite ver e filtro facilmente os dados marca.
DADOS DE SELEÇÃO MÚLTIPLA ORIENTADOS POR ATRIBUTOS
As perguntas orientadas por atributos contêm as marcas como opções de resposta. Normalmente, são tipos de perguntas de seleção múltipla, e há várias colunas com dados correspondentes a essa pergunta.
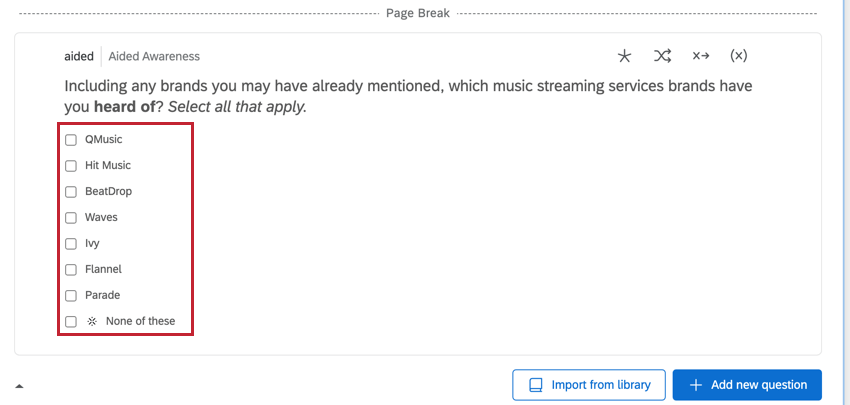
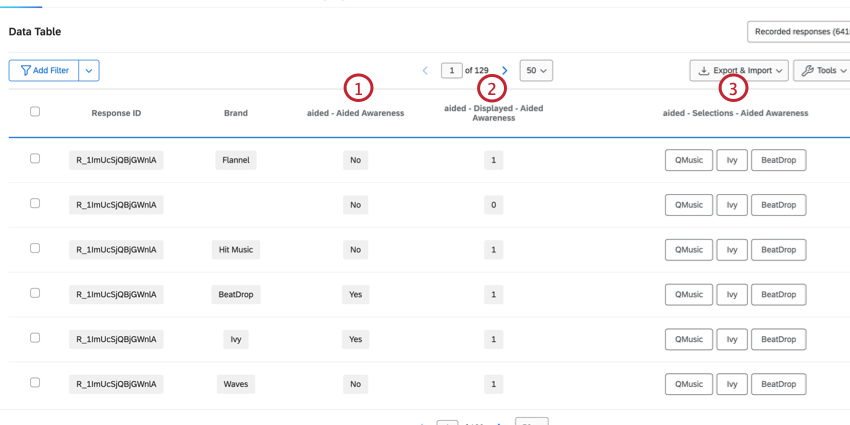
- Pergunta: Determina se a marca foi selecionada para essa pergunta. Os dados serão 1 (“Sim”) ou 0 (“Não”).
- Pergunta – Exibida: Determina se a marca foi exibida para essa pergunta. Os dados serão 1 (exibidos) ou 0 (não exibidos).
- Pergunta – Seleções: Contém todas as marcas que foram selecionadas para essa pergunta. Haverá vários valores nessa coluna, e a lista valores será a mesma para todas as linhas desse respondente.
FAZER LOOP E MESCLAR DADOS DE PERGUNTAS
Há também várias colunas para perguntas que inserem o nome marca usando loop & merge.
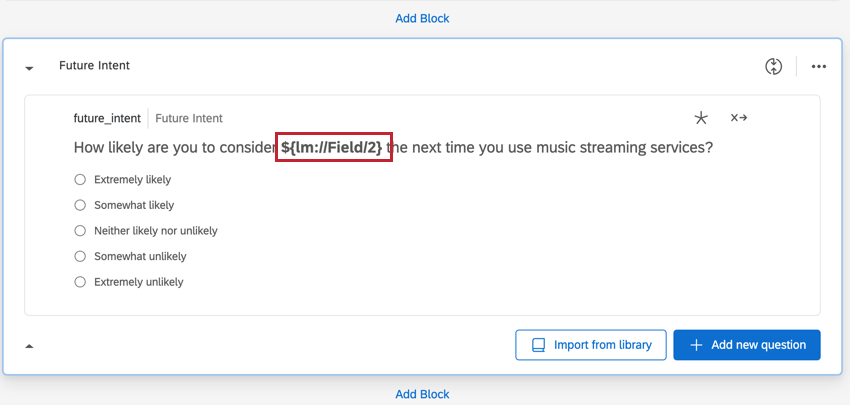
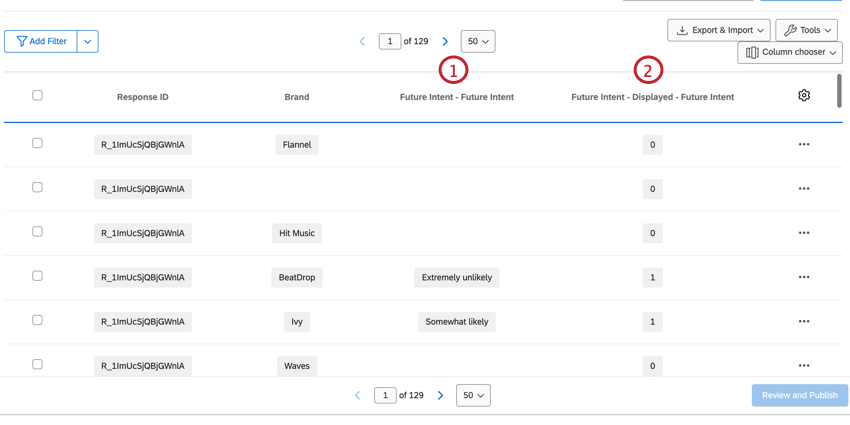
- Pergunta: Mostra qual opção de resposta de resposta foi selecionada para a pergunta.
- Pergunta – Exibida: Determina se a marca foi exibida para essa pergunta. Os dados serão 1 (exibidos) ou 0 (não exibidos).
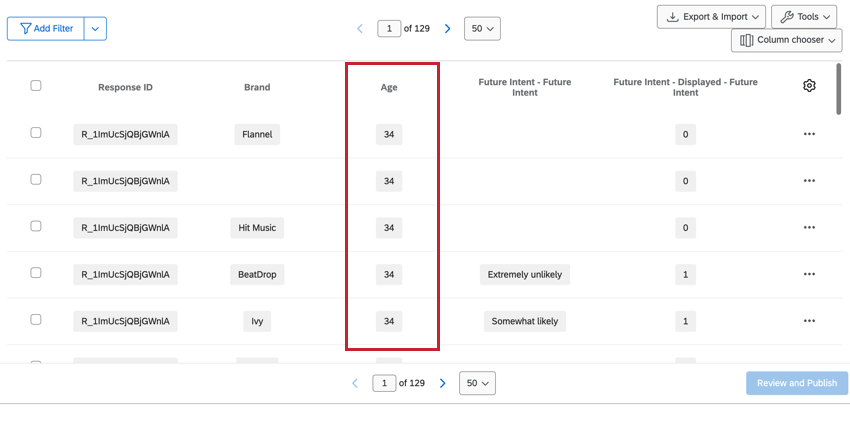
DADOS NÃO EMPILHADOS
Os dados não empilhados não estão relacionados à marca, como perguntas padrão (por exemplo, dados demográficos) e campos dados integrados não empilhados. Esses campos são repetidos por marca, o que mantém os dados disponíveis, quer você esteja analisando uma marca específica ou todas as marcas.
Geração do BTDS
Se você criar um programa BX do zero, a fonte de dados do Marca Tracker não será gerada automaticamente e deverá ser gerada antes da coleta de dados. Todos os dados coletados antes da geração do BTDS não serão empilhados.
- Criar um programa de BX.
- Navegue até sua pesquisa BX.
- Digite o fluxo da pesquisa.
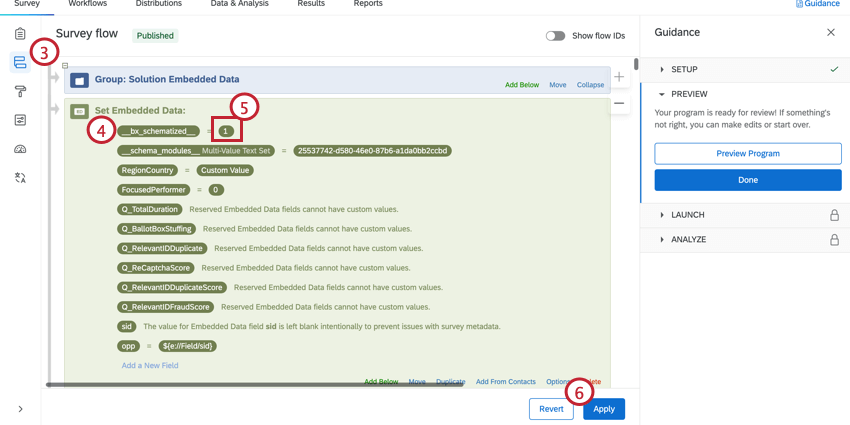
- Encontre o __bx_schematized__. Ele deve ser o primeiro campo dados integrados no fluxo da pesquisa.
- Altere o valor para 1.
- Clique em Aplicar.
- Navegue de volta ao editor pesquisa e clique em Publicar para publicar o pesquisa.
Compatibilidade com conjuntos de dados empilhados
Os conjuntos de dados empilhados têm limitações quanto aos tipos de campo e de pergunta que funcionam melhor para o processamento de dados. Ao criar seu programa BX, é importante garantir que a estrutura pesquisa seja compatível com o BTDS que será gerado.
O BTDS é compatível com os seguintes tipos de perguntas:
- Múltipla Opção de resposta (seleção única e múltipla)
- Entrada de texto, Matriz
- Texto descritivo
- Soma constante
- Controle deslizante
- Ordem de classificação
- Metainformações
Filtragem e exportação do BTDS
A filtragem e a exportação do BTDS funcionam da mesma forma que a filtragem e a exportação da guia Data & Analysis (Dados e amp; Análise). Essas operações podem ser úteis para entender melhor as percepções dashboard, reduzir o tamanho do conjunto de dados ou visualizar subseções específicas do conjunto de dados empilhados.
Otimização
Os programas de BX com grandes listas de marca podem criar conjuntos de dados maiores do que o necessário. Com a otimização marca, você pode limitar seus dados apenas às marcas que são significativas.
- Navegue até o Pesquisa Flow do seu projeto BX.
- No bloco dados integrados, clique em Add a New Field (Adicionar um novo campo).
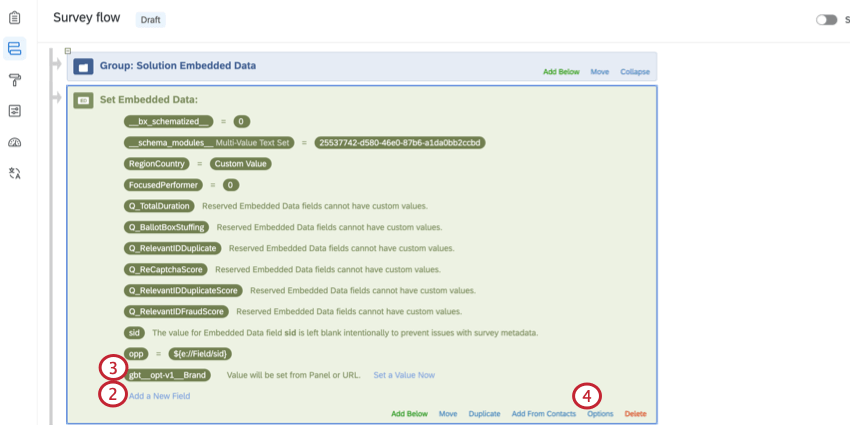
- Nomear o campo
gbt__opt-v1__Brand. - Clique em Options.
- Para a variável criada na etapa 3, selecione Multi-Value Text Set como o tipo de variável.
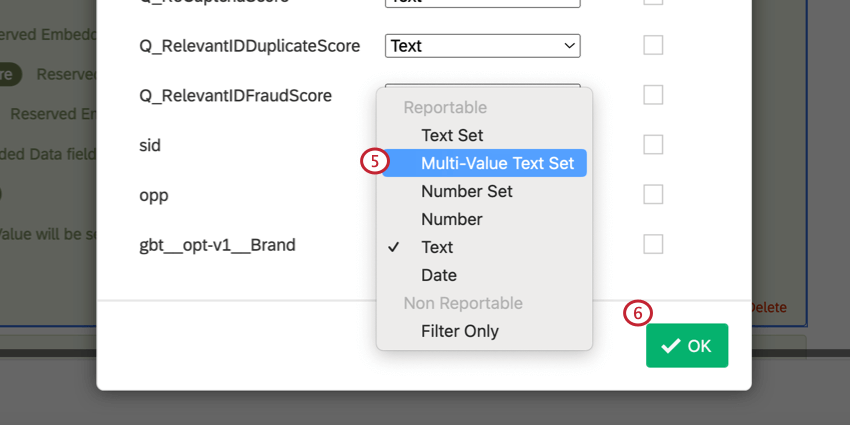
- Clique em OK.
- Após a pergunta que define a lista marca, adicione uma ramificação. No exemplo acima, essa ramificação estaria após a pergunta sobre países.
- Clique em Adicionar uma condição.
- Crie a condição que definirá sua lista marca. No exemplo acima, isso seria “Canadá”.
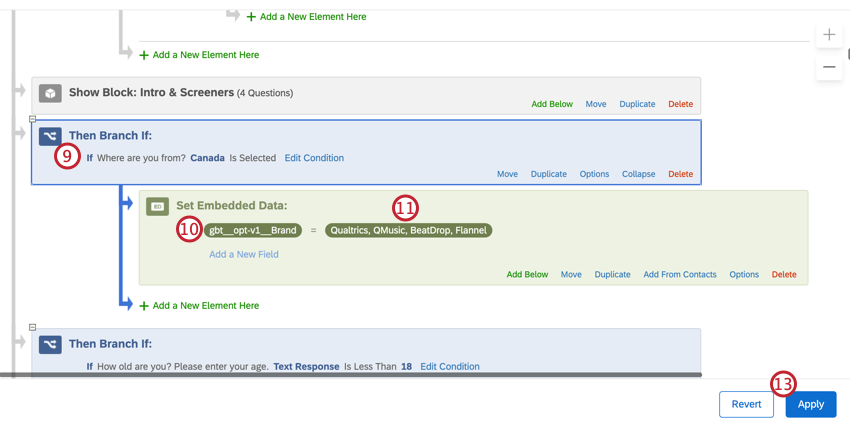
- Adicione a variável que você criou na etapa 3.
- Insira as marcas sobre as quais você gostaria de fazer o relatório. No exemplo acima, essas seriam as quatro marcas nas quais o Canadá está interessado.
- Repita as etapas 7 a 9 para as outras listas de marca que você gostaria de otimizar.
- Clique em Aplicar.
- Publicar sua pesquisa.
Com a variável de otimização definida, o BTDS processado removerá as linhas que não estiverem incluídas na lista dessa variável.
Solução de problemas com o BTDS
Os problemas comuns com o BTDS incluem:
- A contagem de respostas é diferente entre o BTDS e o Data & Analysis da pesquisa.
- As perguntas ou os campos marca não estão sendo empilhados ou estão sendo empilhados incorretamente depois que o BTDS é gerado.
CONTAGEM DE RESPOSTAS
Para comparar as contagens de resposta entre o conjunto de dados pesquisa e o BTDS, filtro o BTDS para Singular = 1. Compare essa contagem com a contagem total no conjunto de dados pesquisa. Se os dados estiverem fluindo corretamente, esses dois números deverão corresponder.
Se esses números não corresponderem, pode haver componentes incompatíveis na pesquisa. Analise as práticas recomendadas dos programas de BX. Se todos os componentes estiverem corretos, entre contato suporte da Qualtrics com uma lista dos IDs de resposta afetados.
NÃO EMPILHAMENTO OU EMPILHAMENTO INADEQUADO
- Verifique a lista Opção de resposta reutilizáveis e todas as perguntas relacionadas à marca. Os nomes das marca devem corresponder exatamente à lista Reusable Opção de resposta.
- Certifique-se de que não haja substrings na lista marca (por exemplo, uma marca “Qualtrics” e outra marca “Qualtrics experiência dos colaboradores, Employee Experience”).
- Certifique-se de que o texto da pergunta seja uma correspondência exata para cada pergunta que deve ser empilhada. Diferentes campos texto transportado em cada pergunta (por exemplo, texto transportado para diferentes logotipos por marca) evitarão que as perguntas sejam empilhadas juntas, o que é especialmente comum em perguntas Matriz.
- Verifique resultados do Expert Review > Data Stacking para ver se há algum problema sinalizado.