-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Análise de correspondência (BX)
Sobre a Análise de Correspondência
A análise de correspondência revela as relações relativas entre e dentro de dois grupos de variáveis, com base nos dados fornecidos em uma tabela de contingência. Para percepções de marca, esses dois grupos são:
- Marcas
- Atributos que aplicar a essas marcas
Por exemplo, digamos que uma empresa queira saber quais atributos os consumidores associam a diferentes marcas de bebidas. A análise de correspondência ajuda a medir as semelhanças entre as marcas e a força das marcas em termos de suas relações com diferentes atributos. A compreensão das relações relativas permite que os proprietários marca identifiquem os efeitos de ações anteriores em diferentes atributos relacionados à marca e decidam as avançar etapas a serem tomadas.
A análise de correspondência é valiosa para as percepções marca por alguns motivos. Ao tentar observar as relações relativas entre marcas e atributos, o tamanho marca pode ter um efeito enganoso; a análise de correspondência elimina esse efeito. A análise de correspondência também oferece uma visão rápida e intuitiva das relações de atributo marca (com base na proximidade e na distância da origem) que não é fornecida por muitos outros gráficos.
Nesta página, apresentaremos um exemplo de como aplicar a análise de correspondência a um caso de uso de diferentes marcas (fictícias) de refrigerantes.
Vamos começar com o formato dos dados de entrada: uma tabela de contingência.
Tabelas de contingência
Uma tabela de contingência é uma tabela bidimensional com grupos de variáveis nas linhas e colunas. Se os nossos grupos, conforme descrito acima, fossem marcas e seus atributos associados, faríamos pesquisas e obteríamos diferentes contagens de respostas associando diferentes marcas aos atributos fornecidos. Cada célula da tabela representa o número de respostas ou contagens que associam esse atributo a essa marca. Essa “associação” seria exibida por meio de uma pergunta pesquisa, como “Escolha as marcas de uma lista abaixo que você acredita que apresentam ___ atributo”
Aqui, os dois grupos são “marcas” (linhas) e “atributos” (colunas). A célula no canto inferior direito representa a contagem de respostas para a marca “Brawndo” e atributo”Econômico”.
| Saboroso | Estética | Econômico | |
| Cerveja amanteigada | 5 | 7 | 2 |
| Squishee | 18 | 46 | 20 |
| Slurm | 19 | 29 | 39 |
| Bebida efervescente para levantamento de peso | 12 | 40 | 49 |
| Brawndo | 3 | 7 | 16 |
Resíduos (R)
Na análise de correspondência, queremos examinar os resíduos de cada célula. Um resíduo quantifica a diferença entre os dados observados e os dados que esperaríamos – supondo que não haja relação entre as categorias de linha e coluna (aqui, essas seriam marca e atributo). Um resíduo positivo nos mostra que a contagem desse par de atributo marca é muito maior do que o esperado, sugerindo uma relação forte; da mesma forma, um resíduo negativo mostra um valor menor do que o esperado, sugerindo uma relação mais fraca. Vamos calcular esses resíduos.
Um resíduo (R) é igual a: R = P – E, em que P são as proporções observadas e E são as proporções esperadas para cada célula. Vamos detalhar essas proporções observadas e esperadas!
Proporções observadas (P)
Uma proporção observada (P) é igual ao valor em uma célula dividido pela soma total de todos os valores na tabela. Portanto, para nossa tabela de contingência acima, a soma total seria: 5 + 7 + 2 + 18 … + 16 = 312. A divisão do valor de cada célula pelo total resultados na tabela abaixo para proporções observadas (P).
Por exemplo, na célula inferior direita, pegamos nosso valor inicial de célula de 16/312 = 0,051. Isso nos informa a proporção de todo o nosso gráfico que o emparelhamento de Brawndo e Economic representa com base em nossos dados coletados.
| Saboroso | Estética | Econômico | |
| Cerveja amanteigada | 0.016 | 0.022 | 0.006 |
| Squishee | 0.058 | 0.147 | 0.064 |
| Slurm | 0.061 | 0.093 | 0.125 |
| Bebida efervescente para levantamento de peso | 0.038 | 0.128 | 0.157 |
| Brawndo | 0.01 | 0.022 | 0.051 |
Massas de linhas e colunas
Algo que podemos calcular facilmente a partir de nossas proporções observadas, e que será muito usado posteriormente, são as somas das linhas e colunas de nossa tabela de proporções, conhecidas como massas de linha e coluna. A massa de uma linha ou coluna é a proporção de valores para essa linha/coluna. A massa da linha para “Butterbeer”, observando o gráfico acima, seria 0,016 + 0,022 + 0,006, o que nos dá 0,044.
Fazendo cálculos semelhantes, chegamos ao resultado final:
| Saboroso | Estética | Econômico | Massas de fileiras | |
| Cerveja amanteigada | 0.016 | 0.022 | 0.006 | 0.044 |
| Squishee | 0.058 | 0.147 | 0.064 | 0.269 |
| Slurm | 0.061 | 0.093 | 0.125 | 0.279 |
| Bebida efervescente para levantamento de peso | 0.038 | 0.128 | 0.157 | 0.324 |
| Brawndo | 0.01 | 0.022 | 0.051 | 0.083 |
| Massas de coluna | 0.182 | 0.413 | 0.404 |
Proporções esperadas (E)
As proporções esperadas (E) seriam o que esperamos ver na proporção de cada célula, supondo que não haja relação entre linhas e colunas. Nosso valor esperado para uma célula seria a massa da linha dessa célula multiplicada pela massa da coluna dessa célula.
Veja na célula superior esquerda, a massa da linha para a cerveja amanteigada multiplicada pela massa da coluna para o Tasty, 0,044 * 0,182 = 0,008.
| Saboroso | Estética | Econômico | |
| Cerveja amanteigada | 0.008 | 0.019 | 0.018 |
| Squishee | 0.049 | 0.111 | 0.109 |
| Slurm | 0.051 | 0.115 | 0.113 |
| Bebida efervescente para levantamento de peso | 0.059 | 0.134 | 0.131 |
| Brawndo | 0.015 | 0.034 | 0.034 |
Agora podemos calcular nossa tabela de resíduos (R), em que R = P – E. Os resíduos quantificam a diferença entre as proporções de dados observadas e as proporções de dados esperadas, se presumirmos que não há relação entre as linhas e as colunas.
Tomando nosso valor mais negativo de -0,045 para Squishee e Economic, o que interpretaríamos aqui é que há uma associação negativa entre Squishee e Economic; é muito menos provável que a Squishee seja vista como “Econômica” do que nossas outras marcas de bebidas.
| Saboroso | Estética | Econômico | |
| Cerveja amanteigada | 0.008 | 0.004 | -0.012 |
| Squishee | 0.009 | 0.036 | -0.045 |
| Slurm | 0.01 | -0.022 | 0.012 |
| Bebida efervescente para levantamento de peso | -0.021 | -0.006 | 0.026 |
| Brawndo | -0.006 | -0.012 | 0.018 |
Residuais indexados (I)
No entanto, há alguns problemas com a simples leitura dos resíduos.
Observando a linha superior de nossa tabela de cálculo de resíduos acima, vemos que todos esses números são muito próximos de zero. Não devemos tirar a conclusão óbvia de que a cerveja amanteigada não tem relação com nossos atributos, pois essa suposição é incorreta. A explicação real seria que as proporções observadas (P) e as proporções esperadas (E) são pequenas porque, como nossa massa de linha nos diz, apenas 4,4% da amostra são de cerveja amanteigada.
Isso levanta um grande problema em relação à análise de resíduos, pois, como desconsideramos o número real de registros nas linhas e colunas, nossos resultados são distorcidos em relação às linhas/colunas com massas maiores. Podemos corrigir isso dividindo nossos resíduos por nossas proporções esperadas (E), o que nos dá uma tabela de nossos resíduos indexados (I, I = R / E):
| Saboroso | Estética | Econômico | |
| Cerveja amanteigada | 0.95 | 0.21 | -0.65 |
| Squishee | 0.17 | 0.32 | -0.41 |
| Slurm | 0.2 | -0.19 | 0.11 |
| Bebida efervescente para levantamento de peso | -0.35 | -0.04 | 0.2 |
| Brawndo | -0.37 | -0.35 | 0.52 |
Os resíduos indexados são fáceis de interpretar: quanto mais longe o valor estiver da tabela, maior será a proporção observada em relação à proporção esperada.
Por exemplo, considerando o valor superior esquerdo, a probabilidade de a cerveja amanteigada ser vista como “saborosa” é 95% maior do que a que esperaríamos se não houvesse relação entre essas marcas e atributos. No entanto, no valor superior direito, a probabilidade de a cerveja amanteigada ser vista como “Econômica” é 65% menor do que o esperado, já que não há relação entre nossas marcas e atributos.
| Saboroso | Estética | Econômico | |
| Cerveja amanteigada | 0.95 | 0.21 | -0.65 |
| Squishee | 0.17 | 0.32 | -0.41 |
| Slurm | 0.2 | -0.19 | 0.11 |
| Bebida efervescente para levantamento de peso | -0.35 | -0.04 | 0.2 |
| Brawndo | -0.37 | -0.35 | 0.52 |
Considerando nossos resíduos indexados (I), nossas proporções esperadas (E), nossas proporções observadas (P) e nossas massas de linhas e colunas, vamos calcular nossos valores de análise de correspondência para nosso gráfico!
Cálculo de coordenadas para análise de correspondência
Decomposição de valor singular (SVD)
Nossa primeira etapa é calcular a Decomposição de Valor Singular, ou SVD. O SVD nos fornece valores para calcular a variação e traçar nossas linhas e colunas (marcas e atributos).
Calculamos a SVD no resíduo padronizado (Z), onde Z = I * sqrt(E), onde I é o nosso resíduo indexado e E é a nossa proporção esperada. A multiplicação por E faz com que a nossa SVD seja ponderada, de modo que as células com um valor esperado mais alto recebam um peso maior e vice-versa, o que significa que, como os valores esperados geralmente estão relacionados ao tamanho amostra, as células “menores” da tabela, onde o erro de amostragem teria sido maior, são menos ponderadas. Assim, a análise de correspondência usando uma tabela de contingência é relativamente robusta em relação aos outliers causados por erro de amostragem.
Voltando ao nosso SVD, temos: SVD = svd(Z). Uma decomposição de valor singular gera 3 saídas:
Um vetor, d, que contém os valores singulares.
| 1ª dimensão | 2ª dimensão | 3ª dimensão |
| 2.65E-01 | 1.14E-01 | 4.21E-17 |
Uma matriz, u, que contém os vetores singulares esquerdos (marcas).
| 1ª dimensão | 2ª dimensão | 3ª dimensão | |
| Cerveja amanteigada | -0.439 | -0.424 | -0.084 |
| Squishee | -0.652 | 0.355 | -0.626 |
| Slurm | 0.16 | -0.0672 | -0.424 |
| Bebida efervescente para levantamento de peso | 0.371 | 0.488 | -0.274 |
| Brawndo | 0.469 | -0.06 | -0.588 |
Uma matriz, v, contendo os vetores singulares direitos (atributos).
| 1ª dimensão | 2ª dimensão | 3ª dimensão | |
| Saboroso | -0.41 | -0.81 | -0.427 |
| Estética | -0.489 | >0.59 | -0.643 |
| Econômico | 0.77 | -0.055 | -0.635 |
Os vetores singulares à esquerda correspondem às categorias nas linhas da tabela, e os vetores singulares à direita correspondem às colunas. Cada um dos valores singulares, para calcular a variância, e os vetores correspondentes (ou seja, colunas de u e v), para plotar posições, correspondem a uma dimensão. As coordenadas usadas para traçar categorias de linhas e colunas em nosso gráfico de análise de correspondência são derivadas das duas primeiras dimensões.
Variância expressa por nossas dimensões
Os valores singulares ao quadrado são conhecidos como valores próprios (d^2). Os valores próprios em nosso exemplo são 0,0704, 0,0129 e 0,0000. A expressão de cada valor próprio como uma proporção da soma total nos informa a quantidade de variação capturada em cada dimensão de nossa análise de correspondência, com base no valor singular de cada dimensão; obtemos 84,5% da variação expressa por nossa primeira dimensão e 15,5% em nossa segunda dimensão (nossa terceira dimensão explica 0% da variação).
Análise de correspondência padrão
Agora estamos equipados com os recursos para calcular a forma básica de análise de correspondência, usando o que é conhecido como coordenadas padrão, calculadas a partir de nossos vetores singulares esquerdo e direito. Anteriormente, ponderávamos os resíduos indexados antes de realizar a SVD. Para obter coordenadas que representem nossos resíduos indexados, agora precisamos remover a ponderação dos resultados da SVD, dividindo cada linha dos vetores singulares da esquerda pela raiz quadrada das massas das linhas e dividindo cada coluna dos vetores singulares da direita pela raiz quadrada das massas das colunas, obtendo as coordenadas padrão das linhas e colunas para plotagem.
Coordenadas padrão Marca:
| 1ª dimensão | 2ª dimensão | 3ª dimensão | |
| Cerveja amanteigada | -2.07 | -2 | -0.4 |
| Squishee | -1.27 | 0.68 | -1.21 |
| Slurm | 0.3 | -1.27 | -0.8 |
| Bebida efervescente para levantamento de peso | 0.65 | 0.86 | -0.48 |
| Brawndo | 1.62 | -0.21 | -2.04 |
Coordenadas padrão Atributo:
| 1ª dimensão | 2ª dimensão | 3ª dimensão | |
| Saboroso | -0.96 | -1.89 | -1 |
| Estética | -0.76 | 0.92 | >-1 |
| Econômico | 1.21 | -0.09 | -1 |
Usamos as duas dimensões com a maior variação capturada para plotagem, a primeira dimensão no eixo X e a segunda dimensão no eixo Y, gerando nosso gráfico de análise de correspondência padrão.
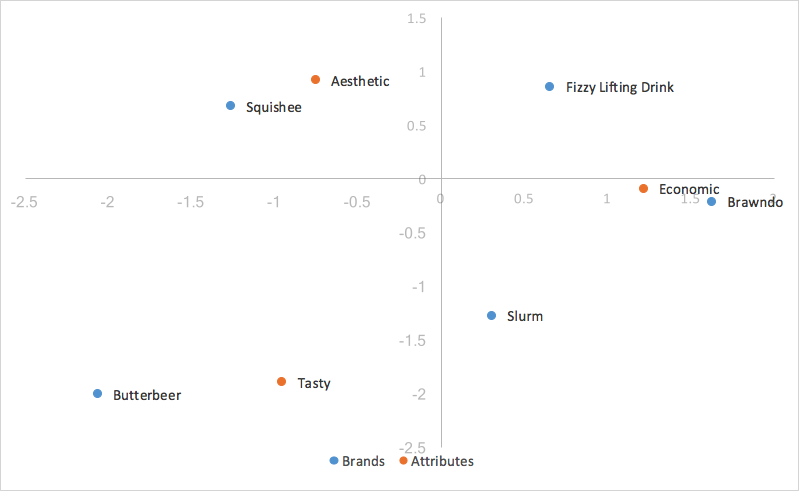
Na avançar seção, exploraremos os prós e os contras dos diferentes estilos de análise de correspondência e qual é o que melhor se adapta aos nossos objetivos de ajudar na análise das percepções marca.
Tipos de análise de correspondência
Análise de correspondência principal de linha/coluna
A análise de correspondência padrão é fácil de calcular, e é possível obter resultados sólidos com ela. No entanto, a correspondência padrão é uma opção de resposta ruim para nossas necessidades; as distâncias entre as coordenadas de linha e coluna são exageradas e não há uma interpretação direta das relações entre as categorias de linha e coluna. O que queremos para interpretar as relações entre as coordenadas de linha (marca) e interpretar as relações entre as categorias de linha e coluna é a normalização principal de linha (ou, se nossas marcas estivessem em nossas colunas, a normalização principal de coluna).
Para a normalização principal da linha, você deseja utilizar as coordenadas padrão calculadas acima para os valores da coluna (atributo), mas deseja calcular as coordenadas principais para os valores da linha (marca). O cálculo das coordenadas principais é tão simples quanto pegar as coordenadas padrão e multiplicá-las por seus valores singulares correspondentes (d). Portanto, para nossas linhas, queremos apenas multiplicar nossas coordenadas de linha padrão por nossos valores singulares (d), mostrados na tabela abaixo. Para a normalização principal da coluna, simplesmente multiplicaríamos nossas colunas, em vez de nossas linhas, por nossos valores singulares (d).
| 1ª dimensão | 2ª dimensão | 3ª dimensão | |
| Cerveja amanteigada | -0.55 | -0.23 | 0 |
| Squishee | -0.33 | 0.08 | 0 |
| Slurm | 0.08 | -0.14 | 0 |
| Bebida efervescente para levantamento de peso | 0.17 | 0.1 | 0 |
| Brawndo | 0.43 | -0.02 | 0 |
Substituindo nossas coordenadas principais por nossas linhas (marcas), obtemos:
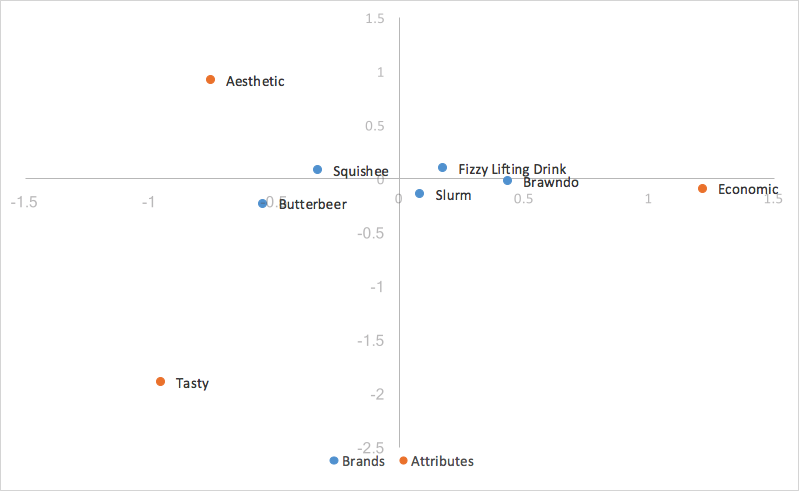
Como dimensionamos por nossos valores singulares, nossas coordenadas principais para nossas linhas representam a distância entre os perfis de linha de nossa tabela original; é possível interpretar as relações entre nossas coordenadas de linha em nosso gráfico de análise de correspondência pela proximidade entre elas.
A distância entre as coordenadas de nossas colunas, por serem baseadas em coordenadas padrão, ainda é exagerada. Além disso, nosso escalonamento por nossos valores singulares em apenas uma das duas categorias (linhas/colunas) nos deu uma maneira de interpretar as relações entre as categorias de linhas e colunas. Dado um valor de linha e um valor de coluna, por exemplo, Butterbeer (linha) e Tasty (coluna), quanto maior for a distância até a origem, mais forte será a associação com outros pontos no mapa. Além disso, quanto menor for o ângulo entre os dois pontos (Butterbeer e Tasty), maior será a correlação entre os dois.
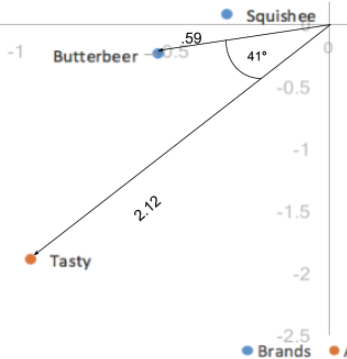
A distância até a origem, combinada com o ângulo entre os dois pontos, é o equivalente a tomar o produto escalar; o produto escalar entre um valor de linha e de coluna mede a força da associação entre os dois. De fato, quando a primeira e a segunda dimensão explicam toda a variação dos dados (somam 100%), o produto escalar é diretamente igual ao resíduo indexado das duas categorias. Aqui, o produto escalar seria a distância à origem dos dois pontos multiplicada pelo cosseno do ângulo entre eles; 0,59*2,12*cos(41) = 0,94. Levando em conta os erros de arredondamento, é o mesmo que nosso valor residual indexado de 0,95. Assim, ângulos menores que 90 graus representam um resíduo indexado positivo e, portanto, uma associação positiva, e ângulos maiores que 90 graus representam um resíduo indexado negativo ou uma associação negativa.
Análise de correspondência principal de linha escalonada
Observando o gráfico acima para a normalização principal da linha, temos uma observação fácil: os pontos de nossas colunas (características) estão muito mais espalhados, e os pontos de nossas linhas (marcas) estão agrupados em torno da origem. Isso pode tornar a análise do nosso gráfico bastante difícil e pouco intuitiva e, às vezes, impossível de ler as categorias de linha se elas estiverem todas sobrepostas. Felizmente, há uma maneira fácil de dimensionar nosso gráfico para incluir nossas colunas e, ao mesmo tempo, manter a capacidade de utilizar o produto de pontos (distância da origem e ângulo entre os pontos) para analisar as relações entre nossos pontos de linha e coluna, conhecida como normalização principal de linha dimensionada.
A normalização principal de linha escalonada usa a normalização principal de linha e escalona as coordenadas da coluna da mesma forma que escalonamos o eixo x das coordenadas de linha – em outras palavras, nossas coordenadas de coluna são escalonadas pelo primeiro valor de nossos valores singulares (d). Nossos valores de linha permanecem os mesmos da normalização principal de linha, mas agora nossas coordenadas de coluna são reduzidas por um fator constante.
| 1ª dimensão | 2ª dimensão | 3ª dimensão | |
| Saboroso | -0.2544 | -0.501 | -0.265 |
| Estética | -0.201 | 0.2438 | -0.265 |
| Econômico | 0.321 | -0.02 | -0.265 |
O que isso significa para nós é que nossas coordenadas de coluna são dimensionadas para se ajustarem muito melhor às nossas coordenadas de linha, facilitando muito a análise de tendências. Como dimensionamos todas as coordenadas de nossas colunas pelo mesmo fator constante, reduzimos a dispersão das coordenadas de nossas colunas no mapa, mas não alteramos suas relatividades; ainda utilizamos o produto de pontos para medir a força das associações. A única mudança é que, quando nossa primeira e segunda dimensão cobrem toda a variação nos dados, em vez de o resíduo indexado ser igual ao produto escalar das duas categorias, ele agora é igual ao produto escalar das duas categorias, que é o produto escalar de um valor constante do nosso primeiro valor singular (d). A interpretação do gráfico permanece a mesma da normalização principal da linha.
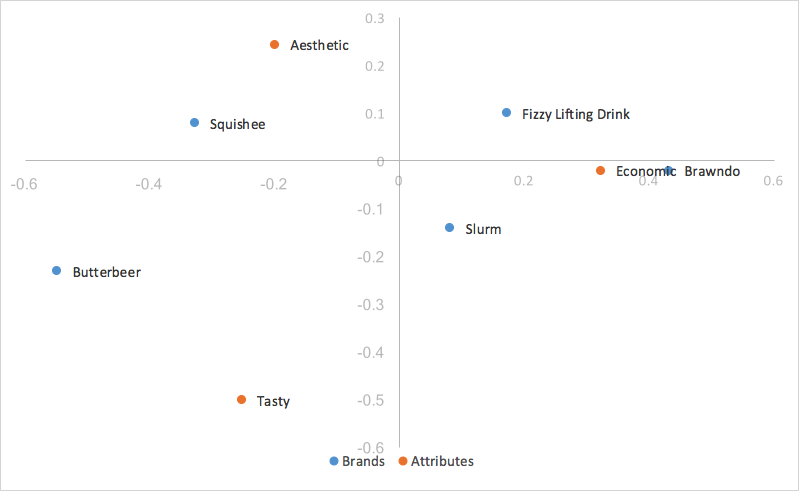
Análise de correspondência principal
Uma forma final de análise de correspondência que mencionaremos é a análise de correspondência principal, também conhecida como mapa simétrico, escalonamento francês ou análise de correspondência canônica. Em vez de apenas multiplicar as linhas ou colunas padrão pelos valores singulares (d), como na análise de correspondência principal de linha/coluna, multiplicamos ambas pelos valores singulares. Assim, nossos valores de coluna padrão, multiplicados pelos valores singulares, tornam-se:
| 1ª dimensão | 2ª dimensão | 3ª dimensão | |
| Saboroso | -0.2544 | -0.215 | 0 |
| Estética | -0.201 | 0.105 | 0 |
| Econômico | 0.321 | -0.01 | 0 |
Juntando esses valores com nossos valores de linha calculados na análise principal de linha, obtemos:
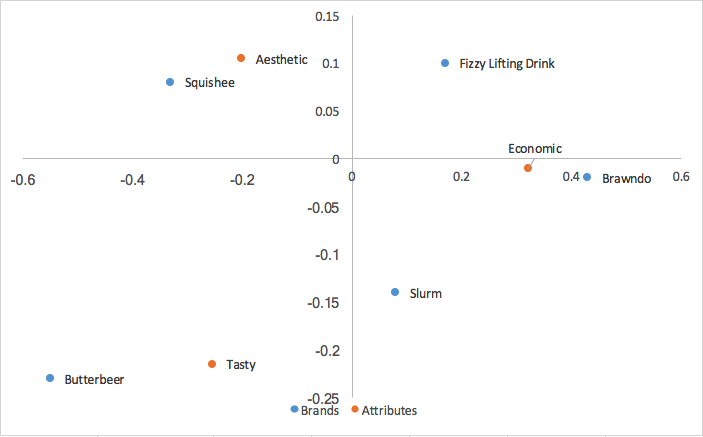
A análise de correspondência canônica dimensiona as coordenadas de linha e coluna pelos valores singulares. Isso significa que podemos interpretar nossas relações entre as coordenadas de linha da mesma forma que fizemos na análise de correspondência principal de linha (com base na proximidade), E podemos interpretar nossas relações entre as coordenadas de coluna da mesma forma que na análise de correspondência principal de coluna; podemos analisar as relações entre as marcas e as relações entre os atributos. Também perdemos o agrupamento de linha/coluna no centro do mapa da análise principal de linha/coluna. No entanto, o que perdemos com a análise de correspondência canônica é uma forma de interpretar as relações entre nossas marcas e atributos, algo muito útil nas percepções marca.
Comparação lado a lado
Análise de correspondência padrão
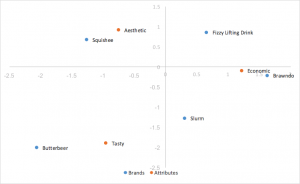
O estilo de análise de correspondência mais fácil de calcular, usando vetores singulares à esquerda e à direita da SVD divididos por massas de linhas e colunas. As distâncias entre as coordenadas de linha e coluna são exageradas e não há uma interpretação direta das relações entre as categorias de linha e coluna.
Análise de correspondência de normalização principal de linha
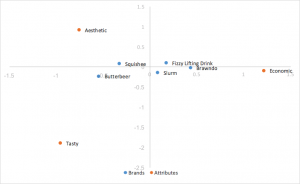
Usa as coordenadas padrão acima, mas multiplica as coordenadas de linha pelos valores singulares para normalizar. As relações entre as linhas (marcas) são baseadas na distância entre elas. As distâncias de coluna (atributo) ainda são exageradas. As relações entre linhas e colunas podem ser interpretadas pelo produto escalar. As linhas (marcas) tendem a se agrupar no centro.
Análise de correspondência de normalização principal de linha escalonada
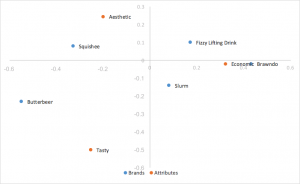
Obtém a normalização principal da linha e dimensiona as coordenadas da coluna por uma constante do primeiro valor singular. As mesmas interpretações desenhadas como normalização principal de linha, substituindo o produto de pontos pelo produto de pontos em escala. Ajuda a remover o acúmulo de fileiras no centro. Esse é o estilo de análise de correspondência que preferimos.
Análise de correspondência de normalização principal (simétrica, mapa francês, canônica)
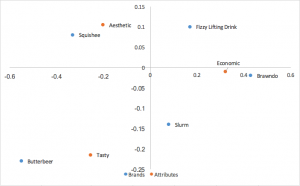
Outra forma popular de análise de correspondência que usa as principais coordenadas normalizadas nas linhas e colunas. As relações entre as linhas (marcas) podem ser interpretadas pela distância entre elas; o mesmo pode ser dito das colunas (atributos). Nenhuma interpretação pode ser feita para os relacionamentos entre linhas e colunas.
Concluindo
Em conclusão, a análise de correspondência é usada para analisar as relações relativas entre e dentro de dois grupos; em nosso caso, esses grupos seriam marcas e atributos.
A análise de correspondência elimina uma distorção nos resultados de diferentes massas entre grupos, utilizando resíduos indexados. No caso das percepções marca para análise de correspondência, utilizamos a normalização principal de linha (ou principal de coluna, se as marcas forem colocadas nas colunas), pois isso nos permite analisar as relações entre diferentes marcas pela proximidade entre elas e também nos permite analisar as relações entre marcas e atributos pela distância da origem combinada com o ângulo entre elas e a origem (o produto de pontos), com o sacrifício de deturpar a relação entre atributos com distâncias exageradas (o que não importa para nós, pois não nos importamos com as relações entre atributos). Utilizamos a normalização principal de linha/coluna em escala para facilitar a análise de nosso gráfico sem nenhum custo. Devemos ter em mente que somamos a variação explicada pelos rótulos dos eixos X e Y (a primeira e a segunda dimensão) para visualizar a variação total capturada no mapa; quanto menor esse número, mais variação inexplicada há nos dados e mais enganoso é o gráfico.
Um último aspecto a ser lembrado é que a análise de correspondência mostra apenas relatividades, pois eliminamos o fator de massa de nossos dados; nosso gráfico não nos dirá nada sobre quais marcas têm as pontuações “mais altas” em atributos. Depois de entender como criar e analisar os gráficos, a análise de correspondência é uma ferramenta poderosa que desconsidera os efeitos do dimensionamento marca para fornecer percepções poderosas e fáceis de interpretar sobre as relações entre e dentro das marcas e seus atributos aplicáveis.