-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
インテリジェントスコアリングを始めよう
インテリジェントスコアリングについて
インテリジェントスコアリングは、XM Discoverとのやり取りを分類と柔軟なルールベースのスコアリングで評価します。インテリジェントスコアリングは、主観的なやり取りを定量的な尺度でスコアリングすることで、複雑な作業を簡素化し、従業員が最も重要なインサイトに労力を集中できるようにします。
インテリジェント・スコアリングは次のような場合に役立つ:
- 顧客対応エージェントの品質管理を行い、プロフェッショナリズム、共感、知識といったソフトスキルのアセスメントやコーチングを支援する。
Qtip:インテリジェントスコアリングは、CSATやNPSのような顧客から与えられたスコアがもたらすバイアスを取り除くのにも役立ちます。例えば、ある顧客が返品や製品の問題で動揺し、純粋なフラストレーションからエージェントを否定的に評価することがある。対比として、インテリジェントスコアリングは、エージェントのソフトスキルのパフォーマンスのみを考慮して評価を下す。
- ソーシャルメディア上の時事イベントに対する世間の反応をタイミングよく追跡することで、貴社は不確実な時代において、顧客にどのように対応するのが最善かを判断し、根拠に基づいた意思決定を行うことができます。
- 法的リスクの判断
- 販売効果の判定。
- さらにカスタマーエクスペリエンスのユースケースも!
インテリジェントスコアリングの設定
インテリジェントスコアリングを設定するには、DesignerとStudioの両方でいくつかのステップを完了する必要があります。
- スコアリングモデルの選択:デザイナーで、スコアリングに使用するカテゴリーモデルを選択する。
Qtip:XM Discoverに取り込まれたポイントフォワード・データをスコアリングしたい場合は、Incremental Data Loadsに含めるを選択してください。
- 指標の作成:ルーブリックとは、文書に対する期待スコアを設定する方法です。スタジオで、基準を定義し、重み設定をします。被評価者を自動的に不合格にするような項目を割り当てることもできる。
- ルーブリックを有効にする:ルーブリックを有効にすることで、スコアリングとレポート作成が可能になります。
- 過去のデータを再スコアする(オプション): 過去のデータにインテリジェントスコアリングを適用したり、ルーブリックやトピックの変更を反映して、以前にスコアリングされたドキュメントを更新することができます。
- スコアカード・レポートを作成する: レポートでインテリジェントスコアリングを使用する。
インテリジェントスコアリングへのナビゲート
- スタジオにログインします。
- グローバルナビゲーションメニューを開く。
- インテリジェントスコアリングをクリックする。
- ドロップダウンメニューからプロジェクトを選択します。
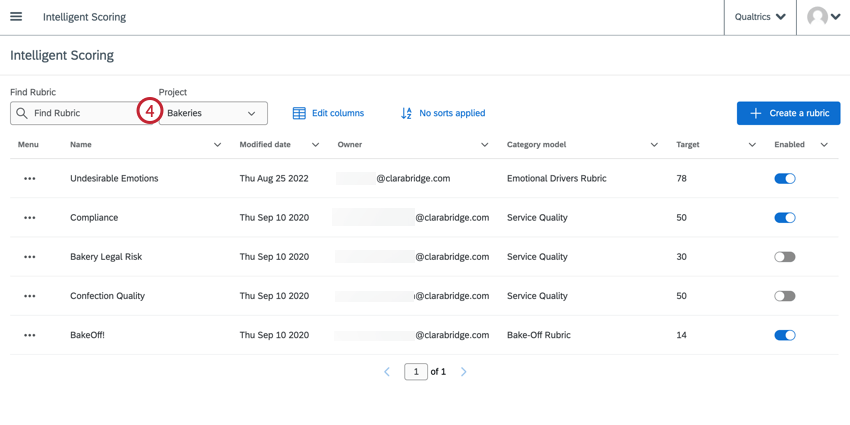
選択したプロジェクトのインテリジェント・スコアリング・ルーブリックのリストが表に表示されます。このテーブルから、ルーブリックの作成、編集、およびマネージャーを行うことができます。
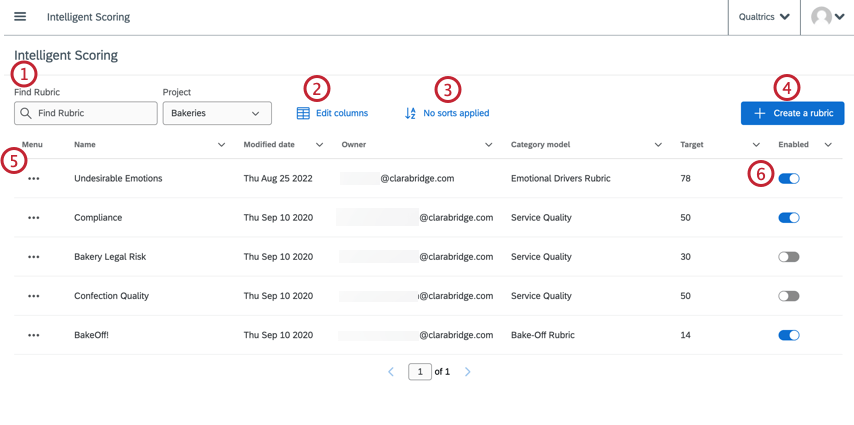
- プロジェクト内のルーブリックを検索する。ルーブリックを検索する前にプロジェクトを選択する必要があります。
- テーブルに表示される列を編集する。
- ルーブリックの表を並べ替える。あるいは、列のヘッダーをクリックして表を並べ替えることもできる。
- 新しいルーブリックを作成する。詳しくは、ルーブリックの作成をご覧ください。
- ルーブリックの編集、無効化、名前の変更、削除。
- ルーブリックを有効にしたり、無効にしたりする。
FAQ
- カテゴリモデルとはトピックとは
-
トピックは、XM Discoverがカテゴリモデルを使用して取得する自由記述のフィードバックに記載されている特定のテーマです。カテゴリモデルは、文をトピックに編成するために使用されるルールベースの階層分類法です。
カテゴリーモデルは XM Discover によるトピックの分析方法であるため、プラットフォーム全体で同じ意味で使用される「カテゴリーモデル」と「トピック」が表示されます。 - 指標とスコアカードの違いは何ですか。
-
指標は期待を定義し、スコアカードは結果を示します。
その考え方の1つは、ルーブリックがインプットで、スコアカードがアウトプットであることだ。 - 複数の指標を登録することはできますか。
-
はい!プロジェクトごとに最大 10 個のモデルを使用して、ルーブリックを設定することができます。モデルごとに多くのルーブリックを使用できます。任意のトピック (兄弟や子を含む) は、1 つのルーブリックでのみ使用することができます。
複数のモデルを使用してルーブリックを定義できることは、特定のモデルのルートノードルールが条件ロジックの最初の形式であるため、特に重要です。ドキュメントがルートノードルールを満たさない場合、そのドキュメントはスコア付けされません。そのため、アラートおよびケース登録の誤検知は生成されません。 - 重みの割り当てに関する推奨事項はありますか。
-
組織に確立された品質管理プロセスがある場合は、XM Discoverでルールを再利用することをお勧めします。そうでない場合は、ドライバを使用することをお奨めします。
品質評価のドライバを使用する方法は次のとおりです。- スコアモデルをドライバの入力として使用し、結果を高い CSAT スコアまたはカスタマーエクスペリエンススコアに設定します。
- 影響が最も大きいトピックと行動を確認します。
- ルーブリックを作成するときに、[順位を提案]ドロップダウンからドライバーを選択して、トピックの影響度のランクを重みの横に表示します。
- 目的の結果に追いつく可能性が高いトピックに、より大きな重みを割り当てます。もう 1 つのアプローチは、均等加重から開始し、必要に応じて調整することです。
- ルーブリックで使用されるルールが文書に複数回存在する場合、複数のスコアが生成されますか。
-
番号評価は、ドキュメントレベルで行われます。いずれかの時点でルールにヒットした場合は、そのルールが 1 回だけスコア付けされます。
- 再評価プロセスにおけるインテリジェントスコア属性の動作は何ですか。すべてのドキュメントで "null" として表示されますか。または、新しいスコアで置き換えられるまで、古いスコアは保持されますか。
-
ドキュメントのスコアは、新しいスコアを受け取った後にのみ更新されます。「NULL」期は間にないため、レポートには引き続き表示されます。
これに対する例外は、以前にスコアを付けた一部の伝票を除外したスコアリングロジックに何らかの更新があった場合です。このシナリオでは、これらの文書は "null" に更新されます。 - ルーブリックモデルを分類する場合、その効果はルーブリックの再評価と同じですか。履歴伝票のスコアリングにはどのような影響がありますか。
-
分類の実行と指標の再評価は同じ効果があります。再コアと分類の唯一の違いは、再評価を使用して、フィルタと一致しないデータのスコアに影響を与えることなく (フィルタを使用して) データのサブセットをターゲットにできることです。これは、パフォーマンス最適化および初歩的なスコアカードバージョニングの目的を果たすことができます。