ルーブリックの作成
スイート
Customer Experience
製品
Qualtrics
このページの内容
ルーブリックの作成について
スコアリングのモデルを選択したら、ルーブリックを作成します。ルーブリックは文書のスコアリング基準を定義する。各スコアリング基準に対して、合格するために必要なコンテンツの有無、相対的な重み設定、自動不合格を設定することができます。
Qtip:ルーブリックがどのように定義されているかを関係者に見せたい場合、オブジェクトビューアウィジェットを使用してダッシュボードにルーブリックを表示することができます。
ルーブリックの作成
QTip:ルーブリックを作成するには、Manage Rubrics(ルーブリックの管理)パーミッション、プロジェクトの管理者レベルのデータアクセス権、およびIntelligent Scoring UIグループのメンバーである必要があります。
スタジオにログインします。
グローバルナビゲーションメニューを開く。

インテリジェントスコアリングを選択する。
ドロップダウンメニューからプロジェクトを選択します。

新しいルーブリックを作成」をクリックします。
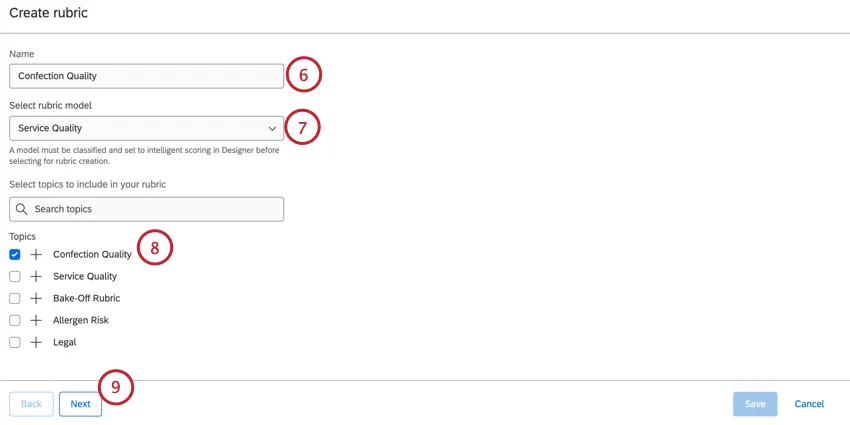
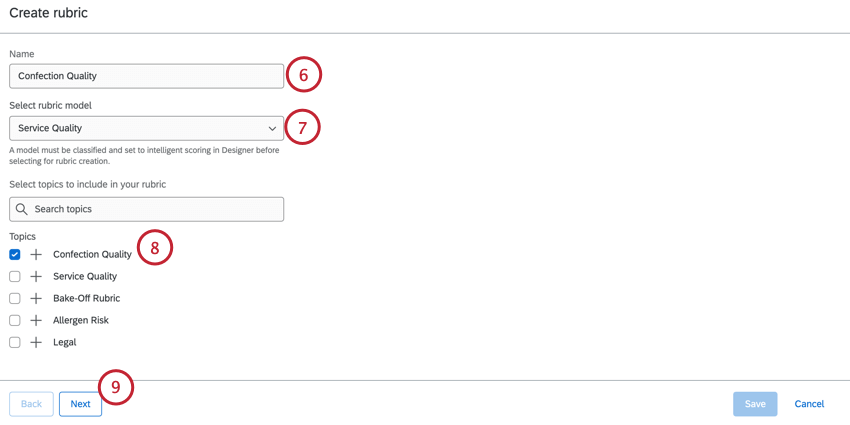
ルーブリックに名前をつける。
Qtip:プロジェクト内のすべてのルーブリックにはユニークな名前が必要です。
Qtip:インテリジェントスコアには「スコア」という単語が自動的に追加されますので、ルーブリック名に使用する必要はありません。
ルーブリックモデルを選択する。詳しくはスコアリングモデルの選択を参照。
ルーブリックに含めたいトピックを選択する。検索バーを使ってトピックを検索できます。トピックを展開するには、プラス記号 (+) をクリックします。
Qtip:モデルごとに複数のルーブリックを作成できますが、任意のトピック (兄弟および子トピックを含む) は 1 つのルーブリックにのみ使用できます。もし、あるトピックが使えないと感じたら、それは他のルーブリックですでに使われている可能性が高い。
[次へ]をクリックします。
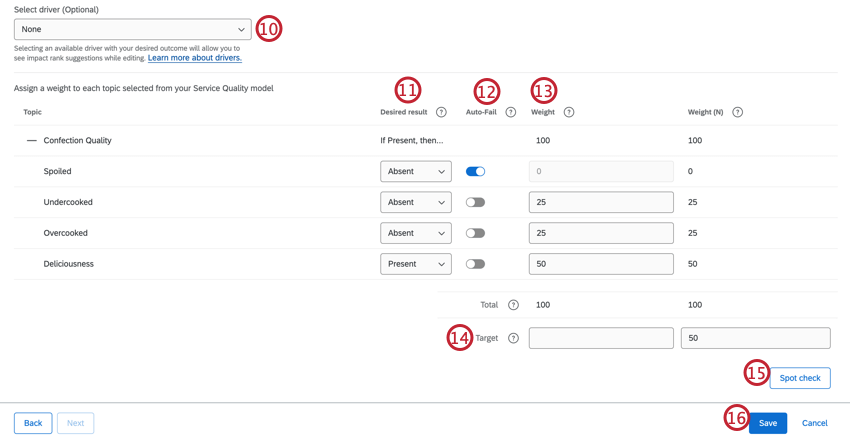
望ましい結果] では、各トピックの重み設定を文書の最終スコアに加算するタイミング、または文書を自動不合格にするタイミングを決定します:
- 存在 (自動落選なし):このトピックが文書に存在する場合、トピックに割り当てられた重み設定分だけスコアを増やします。 例: サポートにおける丁寧な挨拶。

- 欠席 (自動落選なし):このトピックが文書にない場合、トピックに割り当てられた重み設定分だけスコアを増やします。 例: 製品評価や代表電話における不確実性の表現。
- 存在 (自動不合格):文書にトピックがない場合、文書全体のスコアは 0 となります。 例: 必須のスクリプト、確認文、または担当者が毎回尋ねなければならない同意の質問があります。
- 不在 (自動不合格):トピックが文書内に存在する場合、文書全体のスコアは 0 となります。 例: プロとしてあるまじき行為
自動不合格]は、トピックに対して [望ましい結果] を満たさない場合、文書の最終スコアを 0 に設定します。
Qtip:その文書が追加トピックごとに合格か不合格かを見ることはできますが、何点獲得できたかを見ることはできません。
トピックの重み設定を数値で設定します。トピックの重み設定が高いほど、文書のスコアに影響する。
Qtip:重み設定 (N)列は、各トピックの重みが 100% になるように正規化したものです。これらの値は自動的に計算される。
このルーブリックに合格するためのターゲットスコアを定める。ターゲットを定義するには2つの方法がある。
- ターゲット:正確な合格スコアを設定する。ターゲット以上のスコアを獲得した文書は、”合格 “とみなされる。スコアがターゲットに満たない文書は、”不合格 “とみなされる。
- ターゲット(N):合格スコアを100%とする。 Qtip:ターゲット(N)には小数点以下3桁まで加算できます。

スポットチェックボタンを使って、正式に使用する前にルーブリックをテストしてください。
Qtip:スポット・チェックの使い方を参照してください。
[保存]をクリックします。
これでルーブリックを有効にする準備ができました。
スポット・チェックの使用
スポットチェックボタンを使えば、ルーブリックを正式に使用する前に、文書がルーブリックでどのように評価されるかをテストすることができます。スポットチェックは、一度に最大10,000のランダムに選ばれたドキュメントのスコアを計算します。
Qtip:ルーブリックに加えた編集は、キャッシュをクリアするまで同じ10,000のドキュメントでテストされます。
- 結果:テストした文書のうち、何件がターゲットスコアを下回ったか。
- ターゲット(N):現在のターゲットスコアの全体に占める割合。
- 最小/最大:テストされた文書の中で最も低いスコアと最も高いスコア。
- 平均点:テストされた文書の平均スコア。
- 四分位数:下位四分位点、中央値、上位四分位点。これは、検査で採取されたサンプリングがどの程度正確かを判断するのに役立ちます。
- 潜在的カバレッジ:あなたのプロジェクトのデータが、ルーブリックで選択したモデルでどの程度スコアリングされそうか。これを使用して、トピックの除外を調整できます。
- キャッシュをクリアする:このボタンをクリックすると、別の10,000ドキュメントのセットをテストします。
Qtip:プロジェクトに含まれる日付範囲フィルターに関係なく、最大10,000ドキュメントのサンプルをサンプリング。日付範囲に10,000件のドキュメントがない場合、サンプルは完全なデータセットで実行される。
当サポートサイトの日本語のコンテンツは英語原文より機械翻訳されており、補助的な参照を目的としています。機械翻訳の精度は十分な注意を払っていますが、もし、英語・日本語翻訳が異なる場合は英語版が正となります。英語原文と機械翻訳の間に矛盾があっても、法的拘束力はありません。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!