外れ値を使う(スタジオ)
このページの内容
外れ値の利用について
外れ値とは、与えられたデータ・ポイントについて、どの単語がユニークで異常であるかを素早く特定する根本原因探索ツールである。
外れ値の仕組み
アウトライヤーは、選択したデータポイント内の単語、関連する単語、またはハッシュタグの有病率をウィジェット全体の有病率と比較し、最大の格差によってこれらの単語をランク付けする。予想よりはるかに稀な、あるいははるかに人気のある言葉が上位にランクされる。
Outliersは、以下の基準のいずれかを満たす単語、関連語、ハッシュタグを表示します:
- このような現象は、データセットの残りの部分とは対照的に、選択されたデータポイントで異常に頻繁に発生する。
- 選択されたデータポイントでは、他のデータセットとは対照的に、発生頻度が異常に低い。 Qtip: 言い換えれば、異常値は実際には個々のボリュームが非常に少ない可能性があります。なぜなら、それらの用語は他のデータポイントと比較して、データポイントのボリュームが異常に少ないからです。

Outliers は、Studio の任意のデータポイントの「上位 10 語」を見つける代わりに使用できます。しかし、「上位10語」は多くの場合、すべてのデータポイントの上位10個の値であり、あなたが興味を持っている特定のデータポイントの背後で起こっていることを必ずしも区別するものではない。
有病率の変化
{kind=link}
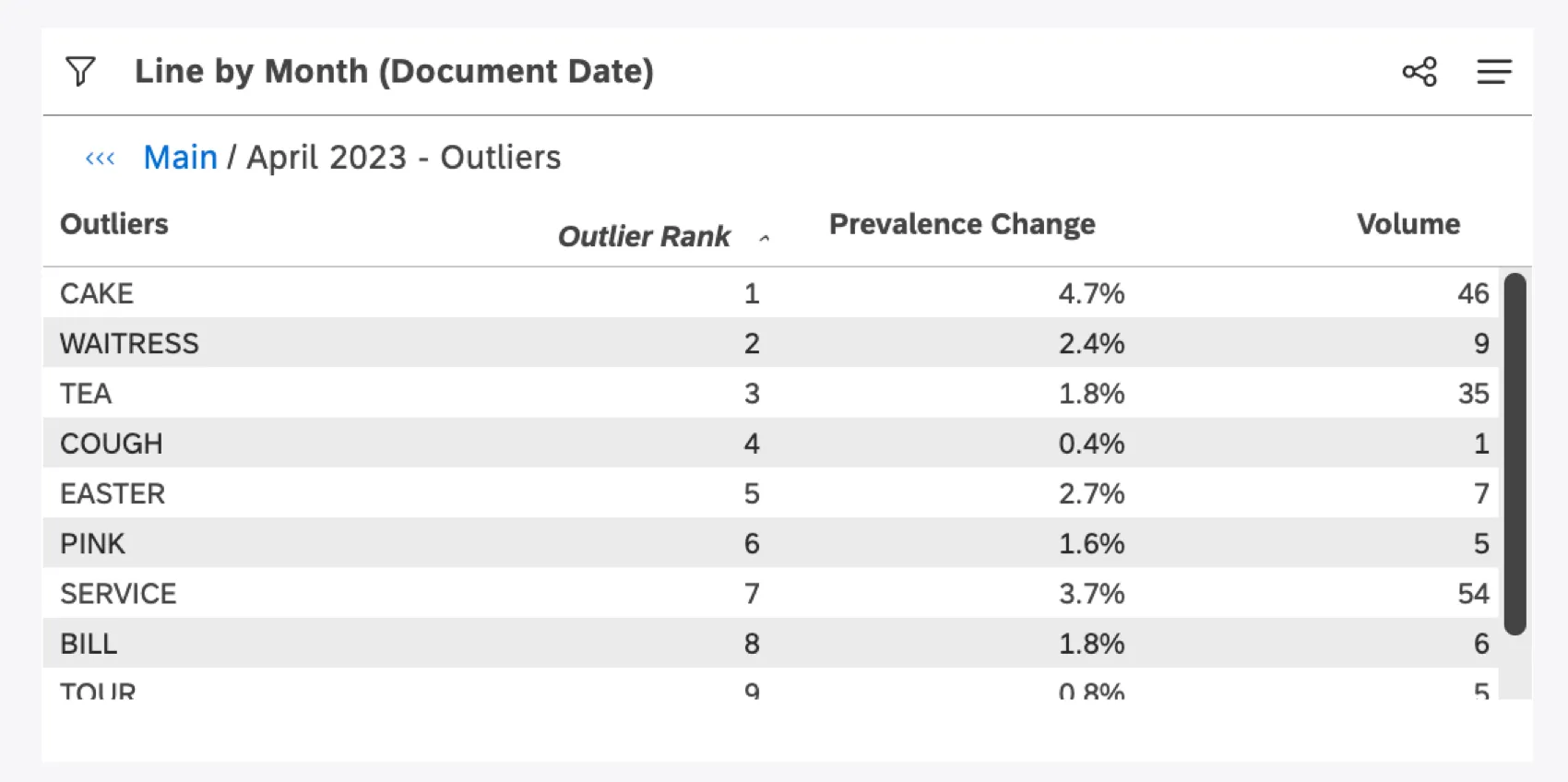
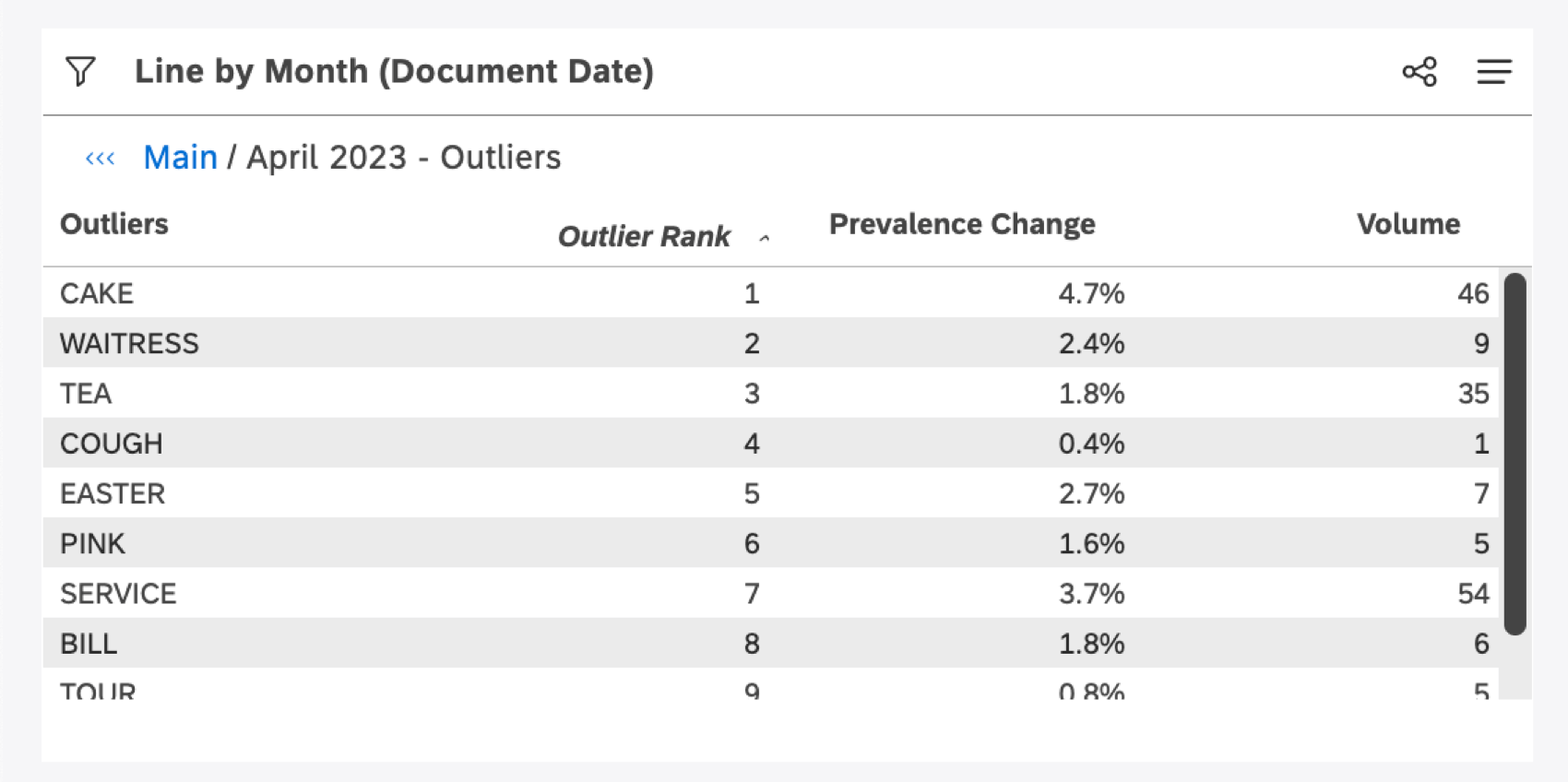
有病率の変化は,ウィジェットのデータ全体と比較して,あなたがドリルした項目に対して,異常値がどの程度多いか少ないかを示す.
外れ値までドリルすると、XM Discoverはドリルされたアイテムのインタラクション(これを「フォアグラウンド」と呼ぶ)を評価し、それらをウィジェット全体のインタラクション(これを「バックグラウンド」と呼ぶ)と比較する。そして、有病率の格差が最も大きい値、つまり有病率が最も異例な値を提示する。Prevalence Change(有病率の変化)」指標は、その格差がどの程度なのかを正確に示し、異常値がどの程度極端なのかをよりよく理解できるようにするものである。
有病率変化率 = 有病率前景 – 有病率背景 なお、ある単語が背景と比較してドリルドグループで異常に珍しい場合、これは負の値となる可能性がある。
例: 北米のデータを表示するウィジェットでニューヨークをドリルする。北米ではこの単語は比較的珍しく、おそらく “ブロードウェイ “に言及するやりとりは0.5%程度であろう。しかし、ニューヨーク市の交流では、この言葉は11%の頻度で出てくる。この場合、有病率は10.5%(11%-0.5%)となる。
外れ値を使用するタイミング
ここで、外れ値を使うことが有益な場合がある:
- 通常とは異なるデータポイント(トレンドグラフのスパイクやディップ、円グラフやヒートマップの巨大な領域、ワードクラウドの気になる色など)を調査し、その原動力を明らかにする。
- ドライバーの使用。ドライバーは、結果の指標となる単語や関連語、ハッシュタグを返さない。外れ値では、データポイントを選択し、相関関係を導き出す。
- トレンド用語をDiscoverして、新しいトピックの可能性を発見する。
外れ値の見方
{kind=link}

データ・ポイントに関連する単語、関連する単語、ハッシュタグを示すテーブルが生成される。これらはすべてランク順に並べられ、有病率の格差が最も大きいものが上位となる。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!