-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
スタックサイズ(スタジオ)
スタックサイズについて
このページでは、スタック・ウィジェットの各分割のサイズを決定する方法について説明する。
Qtip:スタッキングはラインとバーウィジェットでのみ使用できます。
スタッキングの仕組み
アイテムを積み重ねるときは、親の計算値(“Group By“オプション)に基づいてそれらの合計サイズを決定し、返された細分化の比率に基づいてその計算を細分化します。つまり、個々の細分化された体積の合計は、必ずしもスタックの総体積に一致しない。例を挙げて説明しよう。
下のウィジェットは、都市ごとに上位3つのトピックを返すように設定されています。
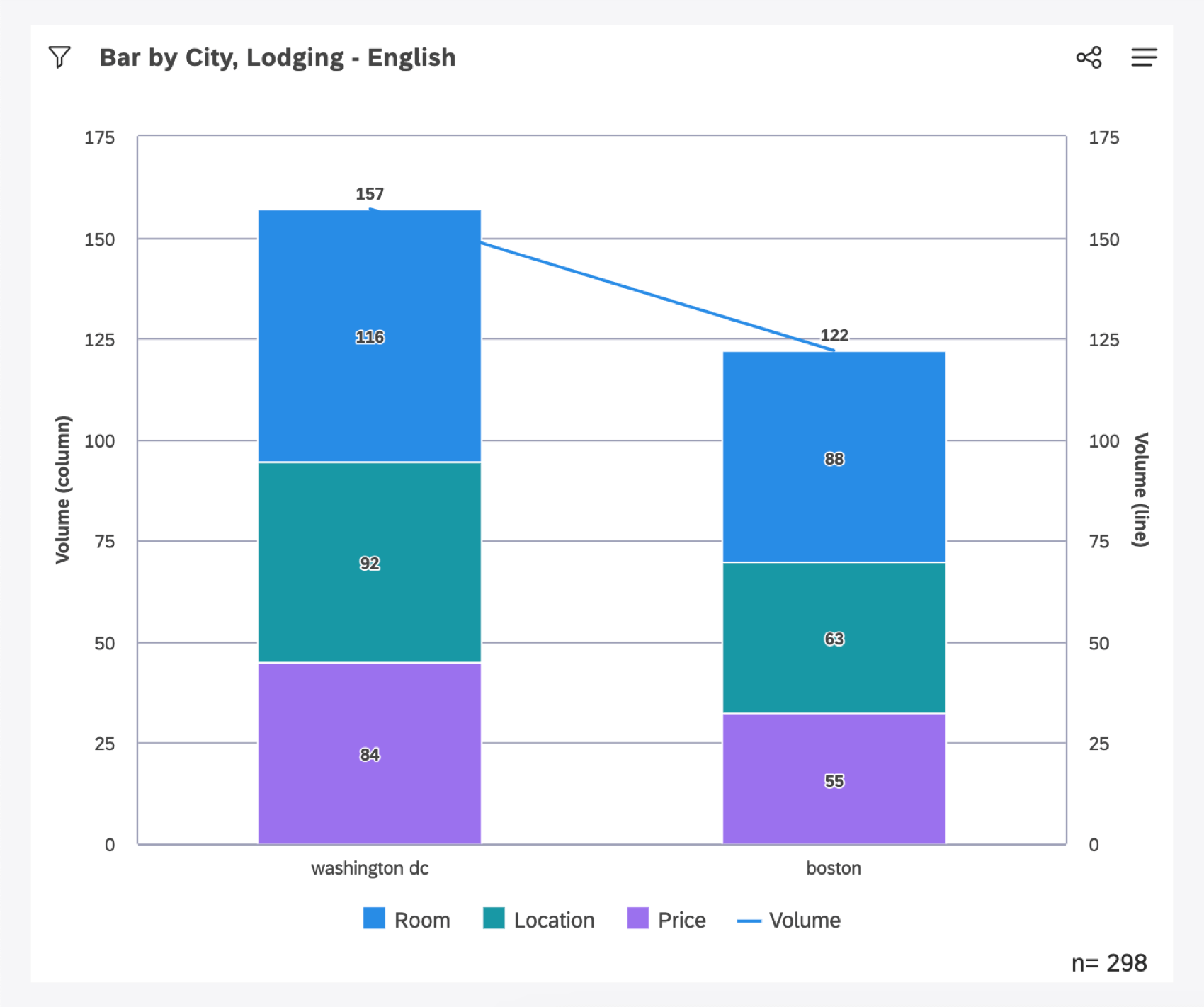
- 列は都市(ワシントンD.C.、ボストン)を表し、積み重ねられた細分化は宿泊モデルのトピック(部屋、場所、価格)を表す。
- 列の全体の高さは、都市のレコードの総容量によって決定される。ボトンの体積は122。
- ボストンでは、「部屋」は88件、「場所」は63件、「価格」は55件であった。その細分化は、ボストンの全高に比例して表示されている。
数字が腑に落ちない理由を理解する
ボストン内の各トピックの全体量と、ボストンの総量とを比較すると、88 + 63 + 55 = 206という矛盾に気づくかもしれない。しかし、ボストンの記録は122である。ボストン全体の高さの中で、積み重ねた細分化を意図的に比例させて表示している。棒グラフをこのように表示する理由はいくつかある:
- 自然言語処理(NLP)ベースの細分化は、相互に排他的なものではない。1つのレコードが複数のトピックに言及することがあり、これは1つのレコードが複数のトピックにカウントされることを意味する。その結果、記録よりも言及されているトピックの方が多いかもしれない。結果、トピックボリュームの合計がボストン全体の記録数を上回ることがある。個々の親トピックの体積の合計で列全体の高さを示すと、親トピックの体積が過大に表示される可能性があるため、ボストンの真の体積を使用している。
- この例では、すべての可能なトピックではなく、上位3つのトピックのみが表示されています。これは、どの文書でも言及されているトピックが1つ以下の場合に特に顕著である。このシナリオは、属性や満足度メトリックのバンドなど、非NLPグループ化による並列の副作用として頻繁に起こる。しかし、大量の文書には、何百とは言わないまでも、何十ものトピックが記載されている可能性があり、トピックの全範囲をスタックしようとすると、最も関連性の高いトピックがかき消されてしまう可能性がある。したがって、トピックのサブセットを調整するために、表示されたグループを互いに比例して表示する。
Qtip: トピックボリュームの合計を親グループのボリュームと一致させる必要がある場合 (特にパーセンテージ で表示する場合)、グループ化設定ですべてのトピックまたは値を表示するのがベストプラクティスです。
二次軸でのスタッキング
二次軸設定でStackedを選択すると、気泡は一次軸と同じように積み重ねられます。
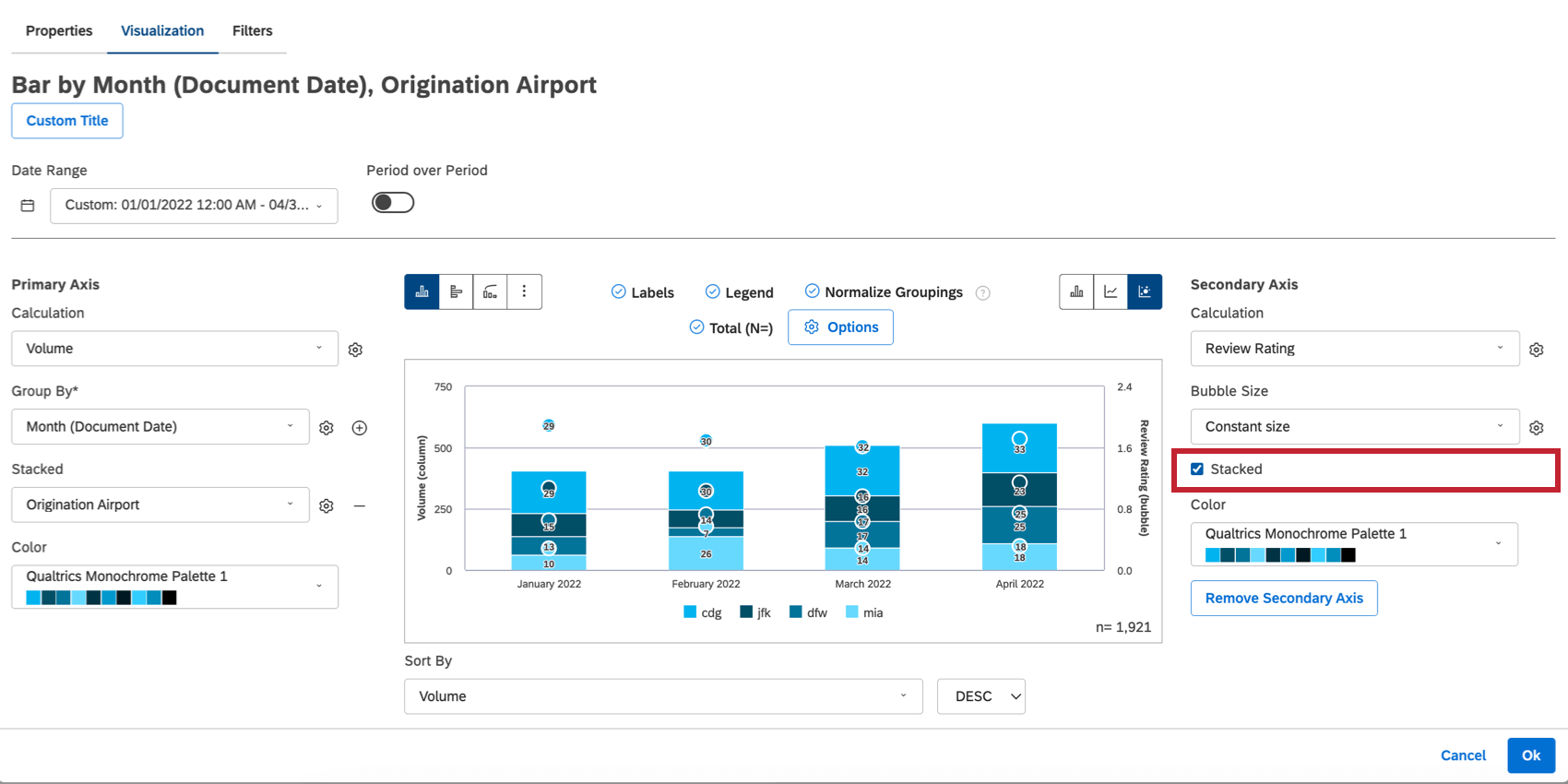
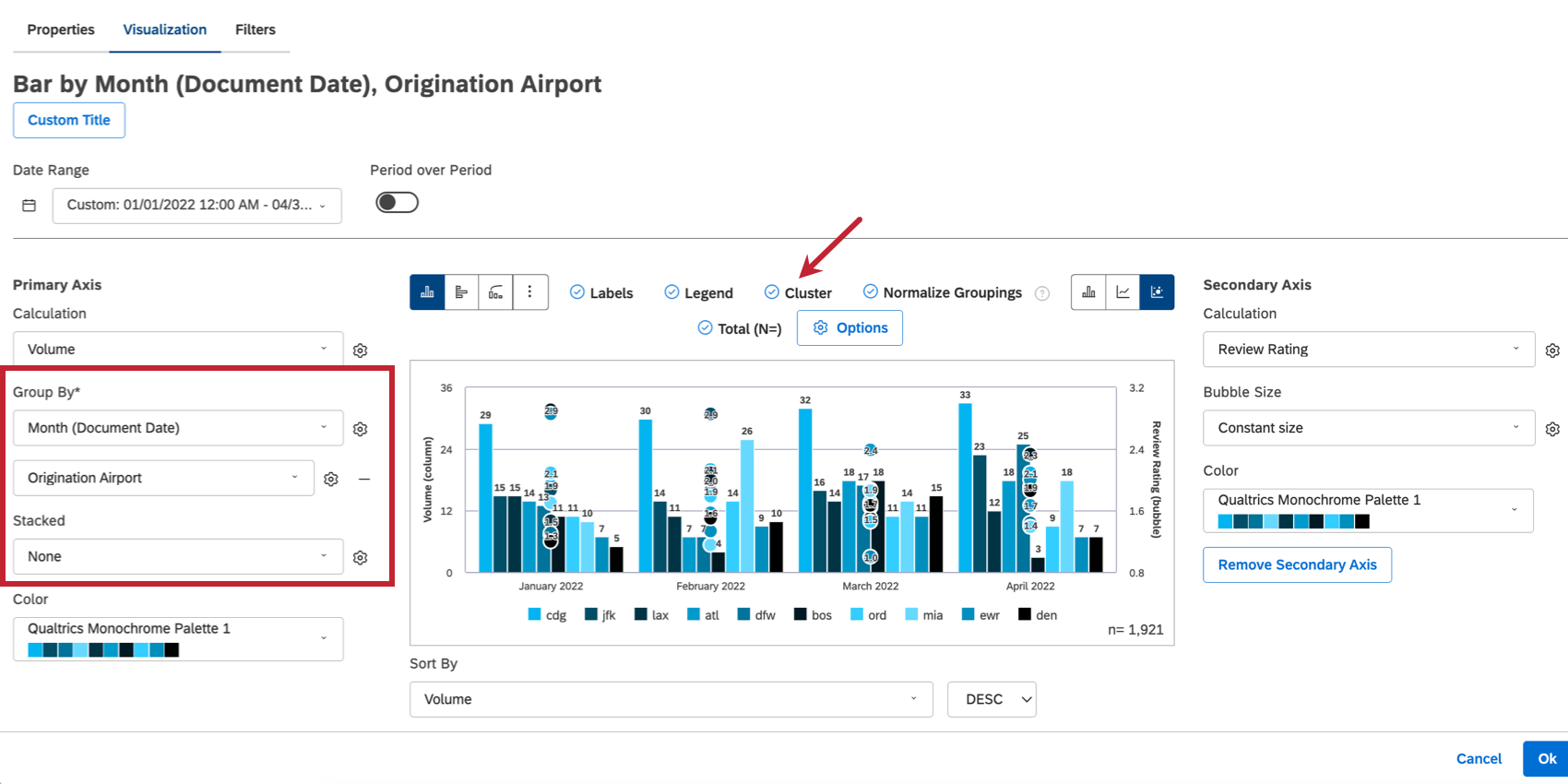
以下の積み上げ棒ウィジェットは、月ごとの空港の積み上げ評価者を二次軸に表示し、月ごとの取扱高上位4つのオリジネーション空港を返すように設定されています。
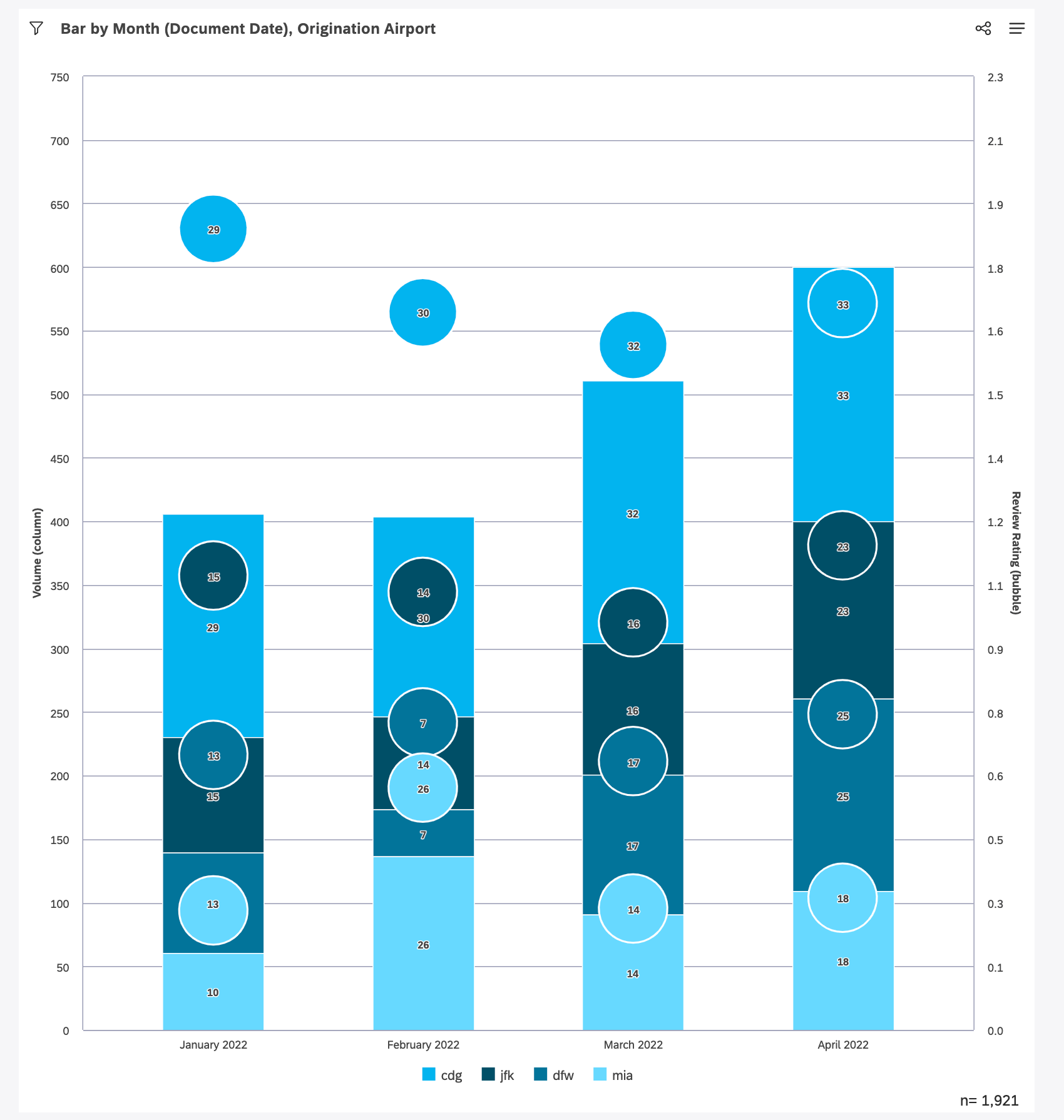
この例では、スタッキングがどのように機能するかを説明する:
- 列は月(文書日付)を表し、細分化は出発空港(CDG、JFKなど)を表す。
- バブルは評価者を表し、積み重ねられる。それぞれのバブルは、主軸の列に示された、積み上げられたオリジネーション空港コードのそれぞれの格付けを表している。
- ラベルがオンになり、バーとバブルの両方の主軸計算(体積)が表示される。バブルには、そのバブルが表すそれぞれのトピックスタック細分化のボリュームラベルが表示される。
- 重要なことは、バブルは単に積み重ねられた細分化されたそれぞれの評価者を表示しているのではないということです。バブルも同様にスタックされ、それぞれの値が加算される。これにより、第二軸の範囲は、個々の値自体から予想される値よりも大きな値を表示することになります。
- 以下に、2022年4月のMIA空港のツールチップを示す。4月のMIAの言及数は18、平均評価者は1.4であった。しかし、二次軸(右側)のMIAバブルの位置を見ると、それはおよそ0.36の評価者と並んでいることがわかる。なぜなら、積み重ねられたバブルの垂直方向の位置は、評価者に一次軸の対応する積み重ねられたセグメントの割合を掛けたものによって決まるからである。それぞれのバブルの位置は、このように比例して計算され、「積み重ね」られていく。
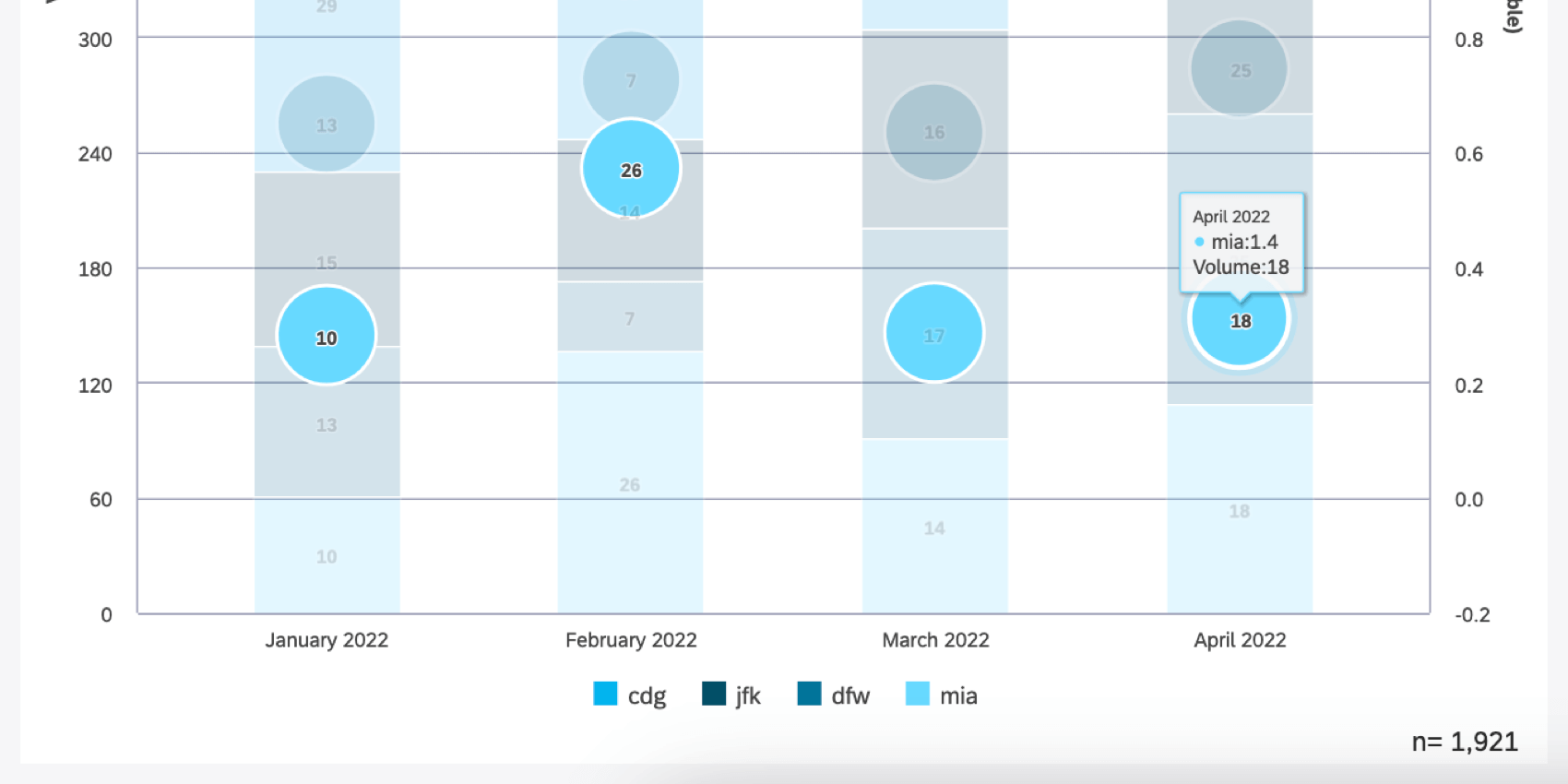
Qtip:縦に整列しているが比例計算されていないバブルを2次軸に表示する必要がある場合は、クラスタオプションをお試しください。そのためには、スタッキングを削除し、代わりにセカンダリー・グループとしてスタッキング属性を追加する必要がある。そして一番上のクラスタを選択する。
スタッキングのベストプラクティス
- (感情、努力、Npsのような)スケールが分岐する指標を使用する場合、細分化することで積み重ねることができる「合計」値がないため、積み重ねは推奨しません。この種の図表には、5段階評価やCSATのような指標が効果的です。
- ウィジェットに表示される情報の大部分は、特にスタックする場合、常に主軸上に保つのがベストである。
- メトリクスの個々の値を主軸に表示するには、次のいずれかを使用する:
- クラスタ棒グラフで、二次軸に線がある。
- 二次軸にバブルを持つクラスタ棒グラフ。
- クラスタ棒グラフで、二次軸に線がある。