-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
データのグループ化(スタジオ)
スタジオでのデータのグループ化について
スタジオでダッシュボードを作成するときに、ダッシュボードに含めるデータを指定できます。データをグループ化、ソート、フィルタリングすることで、レポートのデータを制限することができます。
データにはさまざまなグループ分けができる。このページでは、これらの異なるグループ分けによってデータをグループ化する方法について説明します。
ウィジェットでデータをグループ化する
サポートされているウィジェットタイプでデータをグループ化することができます。ウィジェット内のデータをグループ化する:
- ダッシュボードの編集中に、データをグループ化したいウィジェットのウィジェット・オプション・メニューで[編集]をクリックします。
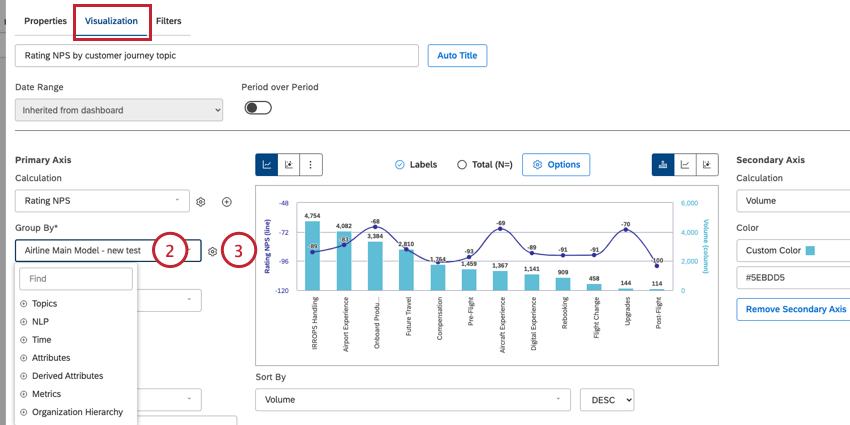
- 図表」タブで、ドロップダウンメニューを使ってデータのグループ化を選択します。このドロップダウンメニューの各オプションの詳細については、以下のセクションを参照してください。
 Qtip:テーブルウィジェットを使用している場合、このオプションは “Groupings “と呼ばれます。ヒートマップ・ウィジェットを使用する場合、このオプションは代わりに “Boxes “と呼ばれます。ネットワーク・ウィジェットを使用している場合、このオプションは代わりに “Nodes “と呼ばれます。
Qtip:テーブルウィジェットを使用している場合、このオプションは “Groupings “と呼ばれます。ヒートマップ・ウィジェットを使用する場合、このオプションは代わりに “Boxes “と呼ばれます。ネットワーク・ウィジェットを使用している場合、このオプションは代わりに “Nodes “と呼ばれます。 - 必要であれば、”Group By “ドロップダウンメニューの次へ歯車アイコンをクリックして、ウィジェットのグループ化設定を編集することができます。これらの設定の詳細については、グループ化の設定を参照してください。
トピック
トピックを選択すると、顧客フィードバックから得られたカテゴリーごとにデータをグループ化することができます。これにより、顧客の話題の概要を知ることができる。
カテゴリモデルを選択した後、グループ化設定を開き、ウィジェットに含めるトピックを選択します。詳しくはカテゴリー・モデルのグループ化のカスタマイズをご覧ください。
トピック別にデータをグループ化する場合、カテゴリー モデルで異なるレベルのレポートを選択できます。顧客の話題の概要をハイレベルで把握するには、レベル 1 のトピックごとにデータをグループ化します。顧客フィードバックのより具体的なテーマをモニターするには、 レベル2以下のトピックでデータをグループ化します(モデルによって異なります)。すべてのレベルで最も詳細なレポートを作成するには、トピックのリーフ、またはサブカテ ゴリを持たないカテゴリにフォーカスできるリーフオプションを使用してデータをグループ化します。
自然言語処理
NLPを選択すると、XM Discoverの自然言語処理エンジンによって自動的に作成された条件でデータをグループ化できます。これらの基準は、XM Discoverによって処理される非構造化フィードバックから作成されます。複数のサブグループから選ぶことができる:
ワード
WordsNLPグループ化では、顧客フィードバックで言及された単語または特定の種類の単語によってデータをグループ化できます。以下のグループ分けがある:
- すべての単語:通常の単語でデータをグループ化します。これにより、顧客があなたの製品やサービスについて話すときに最もよく使われる用語を知ることができます。
- CBブランド:ブランド別グループデータ。
- CBカンパニー企業別グループデータ
- CBメールアドレス:フィードバックに記載されたメールアドレスでデータをグループ化する。
- CBエモーティコン:フィードバックで使用される絵文字や顔文字でデータをグループ化します。
- CBイベント:標準的な祝日(新年やハロウィンなど)、ライフイベント(結婚式や卒業式など)、フィードバックで言及された一般的な文化イベント(スーパーボウルなど)を中心にデータをグループ化する。
- CB業界:関連産業別のグループデータ。
- CB Person:フィードバックで言及された人の名前でデータをグループ化する。
- CB電話番号:フィードバックに記載された電話番号でデータをグループ化する。
- CB製品:製品の言及ごとにデータをグループ化する。
- CB冒涜:事前に設定されたセットから冒涜的な言葉でデータをグループ化します。
関連語
Associated Words(関連する単語)グループ化では、顧客フィードバックの中で互いに関連して言及された単語のペアでデータをグループ化することができます。これにより、トピックの分類に関係なく、顧客フィードバックの最も一般的なトピックやテーマを確認することができます。
関連する単語は、単語1→単語2という形式で表示される。
ハッシュタグ
ハッシュタググループでは、ハッシュタグフレーズ(#記号が 先頭に付いた単語またはフレーズ)でデータをグループ化することができます。ハッシュタグは通常、ソーシャルメディアの投稿で、投稿の被評価者を特定・分類するために使用される。
エンリッチメント
エンリッチメント・グルーピングでは、顧客フィードバックに含まれるコンテンツのタイプ別にデータをグループ化することができます。以下のグループ分けがある:
- CBチャプター:会話の細分化(オープニング、ニーズ、検証、解決ステップ、クロージングなど)。
- CBコンテンツのサブタイプ:コンテントフルでないデータをサブタイプ(広告、クーポン、記事リンク、「未定義」タイプなど)でさらにグループ化する。コンテントフルレコードの場合、サブタイプも常にコンテントフルであることに注意。
- CBコンテンツタイプ:XM Discoverによって自動的に識別された、コンテンツがあるかないかでデータをグループ化する。
- CB検出機能:検出された NLP 機能のタイプ別にデータをグループ化します (たとえば、業界やブランドの言及を含むデータ)。
- CB感情:NLPエンジンによって検出された感情の種類(怒り、混乱、失望、恥ずかしさ、恐怖、欲求不満、嫉妬、喜び、愛、悲しみ、驚き、感謝、信頼、その他)によってデータをグループ化します。
- CB 条件:本文中に記載された医学的条件(例えば、”covid “や “meningitis”)ごとにデータをグループ化する。
- CB医療処置:テキストに記載された医療処置(例えば、「マンモグラム」や「腰の手術」など)ごとにデータをグループ化する。
- CB 参加者共感スコア:代表者が顧客とのやり取りの中で共感を示したかどうかで会話データをグループ分けする。0は代表者が共感を示さなかったことを意味し、1は代表者が共感を示したことを意味する。
- CB理由:特定の会話イベントの理由(例えば、連絡先や共感の理由)によってデータをグループ化する。
- CB Rx:テキストに記載された薬剤名(例えば「アセトアミノフェン」や「タイレノール」など)でデータをグループ化。
- CB センテンスタイプ:文の種類や意図によってデータをグループ化する(例えば、「助けを求める叫び」や「提案」など)。
言語
言語グループ化では、フィードバックが残された言語によってデータをグループ化することができます。以下のグループ分けがある:
- CB 自動検出された言語:自動的に検出された言語ごとにデータをグループ化する(プロジェクトで言語の自動検出が有効になっている場合)。
- CB 処理された言語:フィードバックが実際に処理された言語ごとにデータをグループ化する。XM Discoverの言語検出でサポートされていない言語は、”その他 “と表示されます。
会話
カンバセーション・グルーピングでは、様々なカンバセーション・エンリッチメントによってデータをグループ化することができます。これらのグループ分けは、会話データ(クアルトリクス会話フォーマットを使用して処理された通話とチャット)でのみ利用可能であることに注意してください。以下のグループ分けがある:
- CB % Silence:通話中の無音の割合でデータをグループ化する。
- CB会話時間:会話時間(ミリ秒)でデータをグループ化する。コールの場合、これは最初のセンテンスの開始から最後のセンテンスの終了までの時間である。前後の沈黙はカウントされない。チャットの場合、これは最初の文章から最後の文章までの時間です。
- CB 参加者の種類:参加者の種類によってデータをグループ化する。可能な値は以下の通り:
- Chat_botはチャットボットです。
- IVRとは、Interactive Voice Response botのことです。
- 人間とは人である。
- CB参加者タイプ:参加者のタイプ別にデータをグループ化する。可能な値は以下の通り:
- エージェントは企業の担当者かチャットボットだ。
- クライアントは顧客である。
- type_unknownは、エージェントまたはクライアントとして識別されない参加者である。
- CBセンテンスの継続時間:通話の文の継続時間(ミリ秒)でデータをグループ化する。
- CB センテンス開始時間:センテンス開始のタイムスタンプでデータをグループ化。通話の場合、これは、最初の文の最初の単語が聞こえ始めてからのミリ秒単位の時間である。チャットの場合、これは最初のメッセージが送信されてからのミリ秒単位の時間です。
Qtip:この属性では、最初のチャットメッセージの開始時間は常に0ミリ秒になります。
- CBトータルデッドエア:ミリ秒単位で通話中のデッドエアの合計でデータをグループ化する。通話におけるデッドエアとは、スピーカーとスピーカーの間の長い間のことである。
- CBトータルヘジテーション:通話の合計(エージェントとクライアントの)ヘジテーション(ミリ秒)でデータをグループ化する。通話におけるヘジテーションとは、片方の話し手が長い間を置くことである。
- CB トータル・オーバートーク:通話中に重複したセンテンスの累積長をミリ秒単位でグループ化したデータ。通話においてオーバートークとは、2人以上の話し手が同時に話していて、そのセンテンスのタイムスタンプが重なるタイミングを指す。
- CB Total Silence(合計無音時間):通話の参加者全員について、文と文の間の2秒以上の沈黙の長さの累計(ミリ秒単位)でデータをグループ化する。
時間
タイミングを選択すると、期間ごとにデータをグループ化することができます。時間属性のグルーピングを使用してトレンド・レポートを作成し、計算やメトリクスの経時変化を確認することができます。
属性
属性を選択すると、選択した構造化属性の値でデータをグループ化できます。構造化属性とは、実際のテキスト・フィードバックではない、レコードに存在する数値または文字列フィールドのことである。構造化属性は一般に、高度に組織化された離散データ(人の年齢や使用する製品名など)を含む。グループ化に利用できる属性はフィードバックのソースに依存し、通常はデータセットによって異なる。
指標
メトリクスを選択すると、特定の標準計算および派生メトリクスの離散値または帯域によってデータをグループ化できます。つまり、ある指標でデータを整理し、別の指標で測定することができる。以下のグループ分けがある:
- 感情(3バンド):3つの感情バンド(ネガティブ、ニュートラル、ポジティブ)でデータをグループ化。詳しくは感情によるグループ分けをご覧ください。
- 感情(5バンド):5つの感情バンド(強く否定的、否定的、中立、肯定的、強く肯定的)でデータをグループ化。詳しくは感情によるグループ分けをご覧ください。
- 努力(3バンド):3つのエフォートバンド(ハード、ニュートラル、イージー)でデータをグループ化。Effortでグループ化する場合、デフォルトではNULL値が含まれる。
- 努力(5バンド):5つのエフォートバンド(ベリーハード、ハード、ニュートラル、イージー、ベリーイージー)でデータをグループ化。Effortでグループ化する場合、デフォルトではNULL値が含まれる。
- 感情強度:3つの感情強度バンド(低、中、高)でデータをグループ化する。
- CB ドキュメント単語数:文書内の単語数でデータをグループ化する。
- CBロイヤルティ保有期間:顧客ロイヤリティの長さ(年)でデータをグループ化。
- CB Sentence Quartile(CBセンテンス四分位数):センテンスが該当する逐語の四分位数(1、2、3、4)でデータをグループ化。これは、会話のどの時点でどのようなトピックが話し合われているかを理解するのに役立つ。
- CB 文の単語数:文中の単語数でデータをグループ化する。
さらに、トップボックス、ボトムボックス、満足度の指標を独自に定義して、データをグループ化することもできる。これにより、フィードバックが推奨者からのものなのか、批判者からのものなのか、中立的な顧客からのものなのかを判断することができます。以下のグループ分けがある:
- トップボックス:トップボックスのバンド(推奨者、その他)ごとにデータをグループ化。
- ボトムボックス:ボトムボックスのバンド(批判者、その他)でデータをグループ化する。
- 満足度:満足度帯(批判者、中立者、推奨者)ごとにデータをグループ化。
ドライバー
ドライバーを選択すると、アカウントに作成したドライバーごとにデータをグループ化できます。これらのドライバーを使って、特定の結果につながる属性やトピックを見つけることができる。
組織階層
組織階層を選択すると、選択した組織階層のレベル別にデータをグループ化することができます。
グループ化費用
複数のグルーピングを使用してレポートを実行すると、次のようなエラーメッセージが表示されることがあります:
“Oops!各グループ分けには推定コストを適用し、コストの合計が[10.5]のガードレール予算を超えることはない。(高いカーディナリティのグルーピングは、よりコストがかかる。) ウィジェットの総コストが予算内に収まるように、以下のリストにあるコストに基づいて、異なるグ ルーピングを削除または選択する:[グループ化とそのコストのリスト] 現在の合計コスト: [すべてのコストの合計]”
各グループ化のコストは、グループ内のユニークな値の数に依存します(この尺度はカーディナリティと呼ばれます)。デフォルトでは、ほとんどのウィジェットは、ボリュームのトップ10アイテムを返します。アイテムが全部で100個ある場合、この計算は通常とても速い。1,000,000のアイテムがあれば、どれがトップ10かを計算するのに時間がかかる。一般的に、より多くのユニークなアイテムを持つことは、パフォーマンスという点で、よりコストのかかる計算になる結果となっている。複数のレベルのデータを返すウィジェットでは、このコストはすぐに膨れ上がり、上記のエラーメッセージが表示されることになります。
レポート内でグループ分けを使用する際に上記のエラーが表示される場合は、リスト内のグループ分けを1つ以上削除し、その合計コストが予算を超えないようにする必要があります。エラーメッセージには、どのグループ分けを削除するかを決定するのに役立つ、各グループ分けの推定コストが表示されます。