計算(スタジオ)
このページの内容
計算について
出来高、感情、様々な指標や属性など、データの様々な計算をレポートすることができます。これらの計算は、以下のようなさまざまな方法で使用することができる:
- 棒グラフと折れ線グラフの大きさを決める。
- 表に値を表示する。
- ウィジェットでグループが表示される順序を並べ替えます。
- フィルターウィジェット。
Qtip:ほとんどのウィジェットでは、計算は計算ドロップダウンで利用可能です。ただし、ヒートマップ・ウィジェットなど、計算がボックス・ サイズで選択される例外もあります。

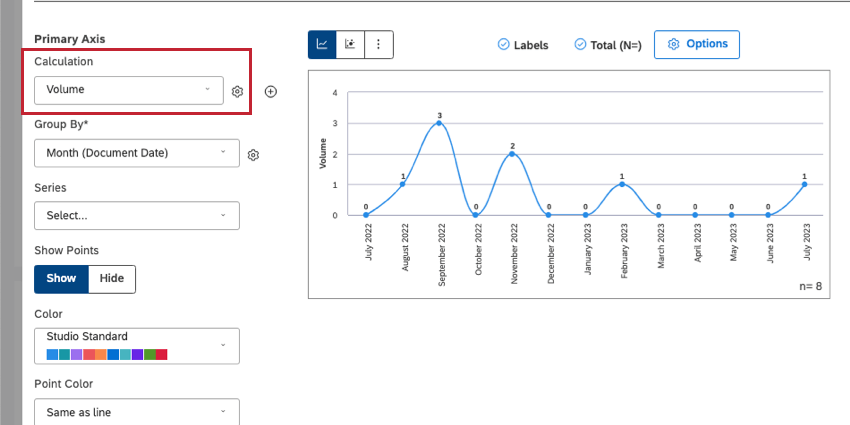
音量
ボリュームとは、特定のデータグループの文書数である。XM Discoverでは、ドキュメント(レコードとも呼ばれる)とは、顧客から提出された個々のフィードバックのことです。ドキュメントとは、レストランの評価者、コールセンターでのやりとりの記録、記入済みのアンケート調査、Facebookの投稿など、データセットによって異なります。
センテンスごとにデータをグループ化する vs. ドキュメント
個々の文章でデータをグループ化する場合でも、ボリュームは文書数を反映することを忘れてはならない。文レベルのグループ化のレベルには、感情や特定のトピックの存在などがある。
ある文書にそのグループ分けに一致する文が少なくとも1つ含まれていれば、その文書は文レベルのグループ分けにカウントされる。1つのレコードが同じグループ分けに関連する複数の文章を含んでいる場合、 そのレコードはそのグループ分けに対して1度だけカウントされる。あるレコードが複数の異なるグループ分けに関連する文章を含んでいる場合、そのレコードはこれらのグループ分けごとに1回ずつカウントされる。
例: カスタマーサービス」トピックを含むフィードバックの量を表示しています。フィードバックは1つしかなく、10種類の文章でカスタマーサービスについて触れている。フィードバックの文書が 1 つしかないため、Customer Service のトピック量は1 になります。
Qtip:センチメントを表示するウィジェット上のボリュームの不一致については、感情によるウィジェットデータのグループ化を参照してください。
感情
感情は、特定のデータグループに関連するすべての文章の平均感情を測定します。
感情が表現されていないセンテンスはゼロに設定され、平均感情計算にカウントされます。
Qtip: レポートの要素のサイズが、感情、労力、満足度メトリクスによって決定される場合、絶対値が使用されます。例えば、感情2と-2のワードは、クラウド・ウィジェットでは同じ大きさになる。
詳細は感情を参照。
労力
Effortは、特定のデータグループに関連する努力を要する文章の平均スコアを測定する。
努力が表現されていないセンテンスにはNULL値が割り当てられ、平均スコアの計算にはカウントされない。
Qtip: レポートの要素のサイズが、感情、労力、満足度メトリクスによって決定される場合、絶対値が使用されます。例えば、感情2と-2のワードは、クラウド・ウィジェットでは同じ大きさになる。
詳細は「努力」を参照。
感情の激しさ
感情の強さは、文の中で表現されている感情の強さを測定する。
感情の強弱が表現されていないセンテンスにはNULL値が割り当てられ、平均スコアの計算にはカウントされない。
詳しくは「感情の強さ」を参照。
影響
インパクトは、ドライバーが選択した結果を予測する力を測定する。影響スコアは、データをドライバー別にグループ化した場合にのみ利用できる。
詳細は「インパクトランクについて」を参照。
保護者の割合
Total は、ウィジェットの総体積に対するグルーピング体積の寄与を測定する。ウィジェットの合計ボリュームは、ウィジェットの条件とフィルタに一致するレコードの合計数です。
% Total = (グループ化のレコード数) / (ウィジェットの合計レコード数) * 100
% Parent は、親グループ化のボリュームに対するグループ化のボリュームの寄与を測定します。
% Parent は、親グループ化のボリュームに対するグループ化のボリュームの寄与を測定します。
Qtip: 選択されたグルーピングが親を持たない場合、ウィジェットの総量が分母として使用され、その場合% Parentは% Totalと一致します。
詳しくは「保護者の割合」と「合計の割合」を参照のこと。
指標
Studio では、テキスト・フィードバックや既存の属性から得られるさまざまなメトリッ クを使って、データのグループ化を分析できます。独自の指標をカスタマイズすることも、Discoverが提供する既存の指標のリストから選択することもできます。
カスタマイズできる指標
それぞれの詳細はリンク先のページを参照のこと。
- 上位ボックス:アンケート調査において、最も好意的な回答をした回答者の割合。
- 下位ボックス:アンケート調査において、最も好ましくない回答をした回答者の割合。
- 満足度:トップボックスとボトムボックスの値の差で、顧客満足度を測る指標となる。
- フィルター付き メトリック:選択したデータの部分集合に対して計算を実行する。
- カスタム数学:さまざまな集計や数式を使用して、さまざまなメトリクスや属性をミックス&マッチ。
プリメイド・メトリクス
これらの事前作成されたメトリクスは、合計または平均に設定できます。2つのオプションを切り替える手順を参照してください。
| メトリック名 | 合計 | 平均 | その他 |
|---|---|---|---|
| CB文書の単語数 | 特定のデータグループに関連する全文書の総単語数。 | 特定のデータグループに関連する全レコードの文書あたりの平均単語数。 | 該当なし |
| CBセンテンス四分位数 | お勧めできない。 | 特定のデータグループに関連するすべてのセンテンスが該当する逐語の平均四分位数。 | 該当なし |
| CBセンテンスの単語数 | 特定のデータグループに関連する全文の単語数の合計。 | 特定のデータグループに関連するすべての文の1文あたりの平均単語数。 | 該当なし |
| ロイヤルティ保有期間 | 該当なし | 該当なし | 顧客ロイヤルティの長さを年数で表す。 |
スコアカード指標
インテリジェントスコアリングを設定している場合は、作成したルーブリックごとにフィルタリングされた2つのメトリクスが表示されます:
- 合格率 – [ルーブリック名]:このルーブリックで合格スコアを獲得した文書の割合。
- 不合格の割合 – [ルーブリック名]:このルーブリックで不合格のスコアを獲得した文書の割合。
属性とプリメイドメトリクスの計算
計算には数値属性を選ぶことができる。デフォルトでは、この属性は平均として機能するように設定される。
しかし、次のようにすれば、これを合計に切り替えることができる:
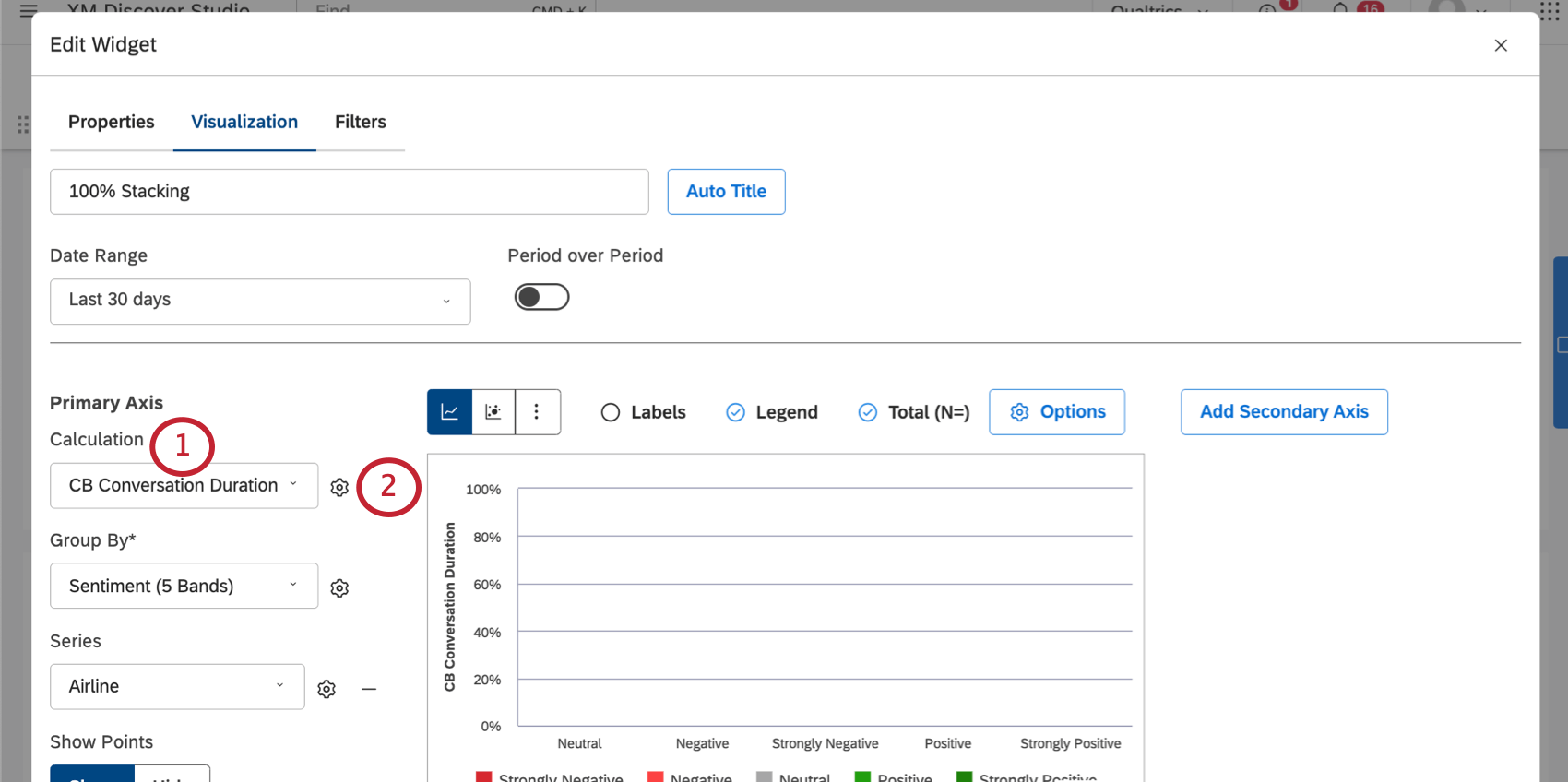
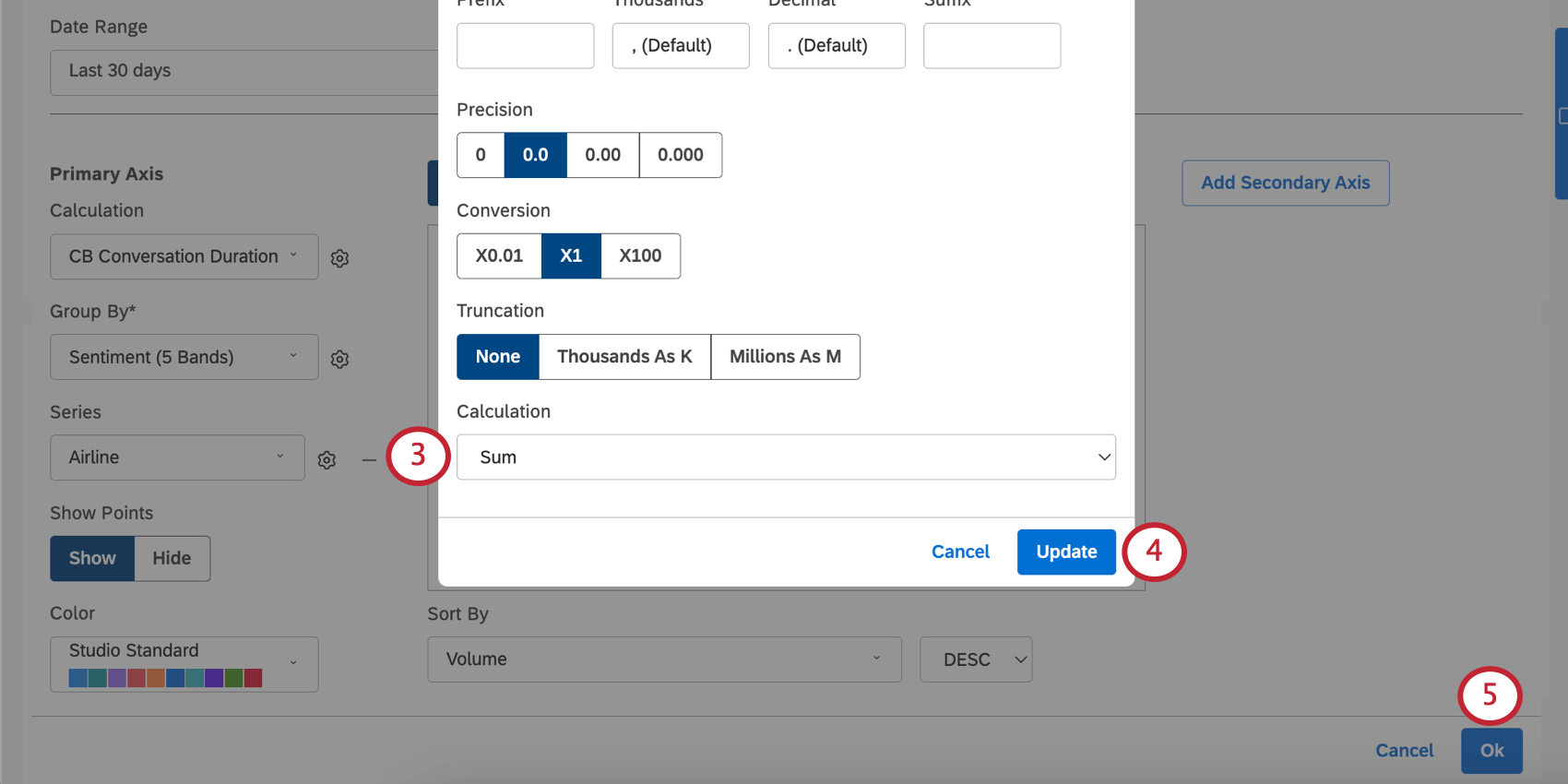
計算設定
計算の次へ歯車をクリックすると、調整できる追加設定があります。
詳しくはウィジェット計算設定をご覧ください。
派生する比較計算
メトリック・ウィジェットで表示するメトリックによっては、追加の計算オプションが付属している場合があります。
追加 Δ 変更
Qtip:これはすべての計算で利用可能です。
メイン値と比較値の差を示すために使用する。以下の式が使われる:
変化量=主要値-比較値 追加 増減率
Qtip: 感情、満足度指標、努力を除くすべての計算で利用可能です。
メイン値と比較値の間の変化率を表示するために使用します。以下の式が使われる:
変化率 = ((メイン値) - (比較値))/ (比較値) * 100 P値の追加
Qtip:これは、期間比較による平均で集計された数値属性に対して利用可能である。
これを用いて確率値を示す。
Qtip: XM Discoverは、アルファ値0.05の両側不等分散独立2標本T検定を使って統計的有意性を計算し、2つの平均に統計的に有意な差があるかどうかを判定します。
統計的有意性をシンボルとして追加
Qtip: これは、期間比較による平均で集計された数値属性に対して利用可能である。
実際の確率値の代わりに、これらの記号を使ってその範囲を示す:
- ns(p>0.05、有意ではない)
- * (p≦0.05、有意[一般的な0.05のしきい値を使用])。
- **(p≦0.01、より高い基準で有意)
- ***(p≦0.001、さらに高い基準で有意)
メトリック・ウィジェットの詳細については、メトリック・ウィジェットを参照してください。
カウント
“Count distinct “は、選択した属性の一意な値の数を集計するために使用できる計算です。この計算は、すべての属性タイプ(日付、数値、テキストなど)で使用できます。
例: “航空会社名 “を格納する属性があります。12の航空会社のデータを調査する場合、count distinctは12に等しい。
ウィジェットの計算に加えて、カウントの区別は、カスタム数学メトリックでも利用可能です。
Qtip:Count distinctは近似値を生成し、小さいデータセットや有限の値を持つ属性に最適です。高いカーディナリティの属性や、大量のデータを扱うプロジェクトでは、count distinctを使用することはお勧めしません。
Qtip:Count distinctはデフォルトでは有効になっていません。この機能にご興味のある方は、Discoverアカウントチームまでお問い合わせください。担当者の連絡先がわからない場合は、Discoverサポートチームにご連絡ください。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!