-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
インタラクションのフィルタリング (Studio)
インタラクションのフィルタリングについて
日付およびその他のパラメータでドキュメントをフィルタリングできます。これは、特定の回答を検索したり、削除またはエクスポートする内容を決定したりする場合に役立ちます。
ヒント:インタラクション経過時間に適用されたフィルターはエクスポートに反映されます。
ヒント:テキストでフィードバックをフィルタリングすると、[結果]ペインが常に切り替わり、すべての文が表示されます。
インタラクションのフィルタリング
ヒント:このページにアクセスするには、インタラクションエクスプローラーの表示権限が必要です。
- 領域メニューをクリックします。
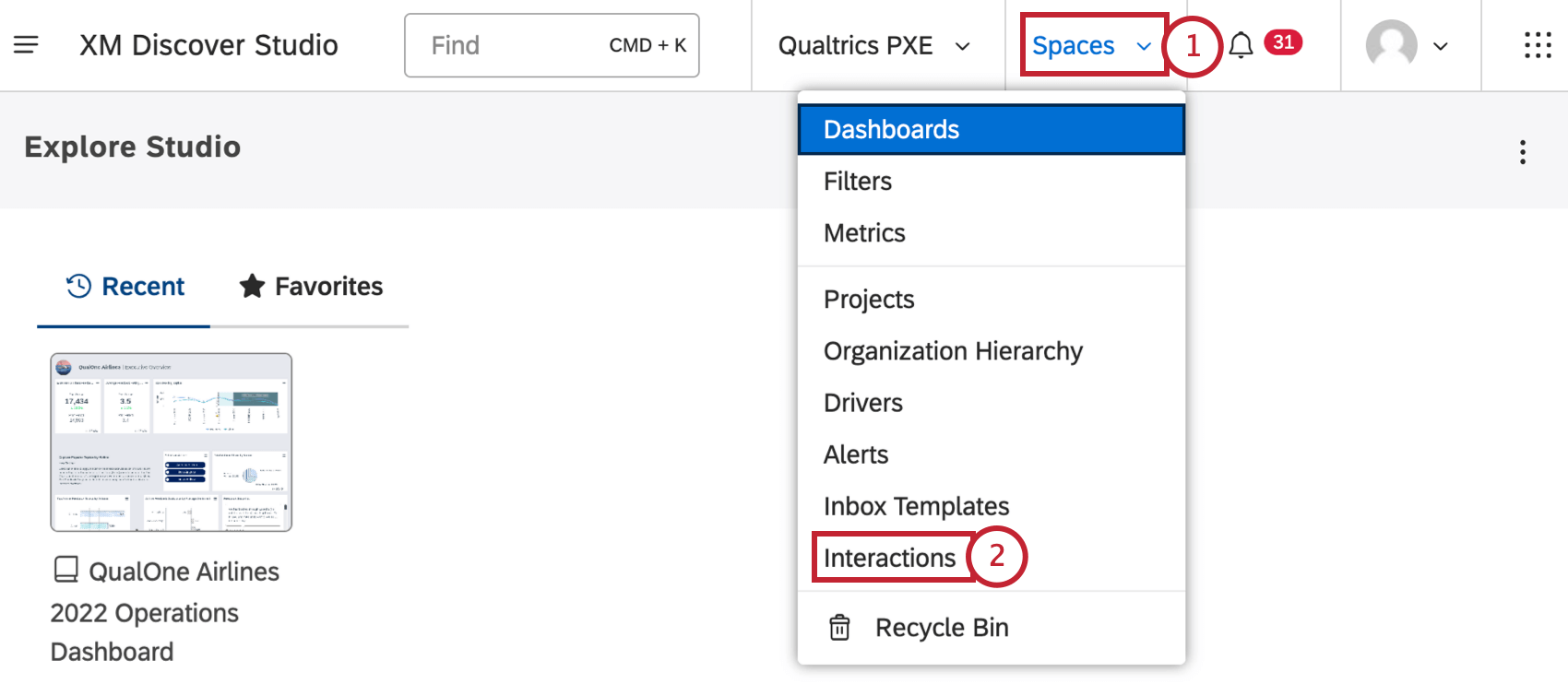
- インタラクションを選択します。
- プロジェクトドロップダウンを使用して、さまざまなプロジェクトに関連付けられているインタラクションを表示します。
 ヒント:アクセス権のあるものに応じて、アカウントとコンテンツプロバイダーを選択する必要がある場合もあります。
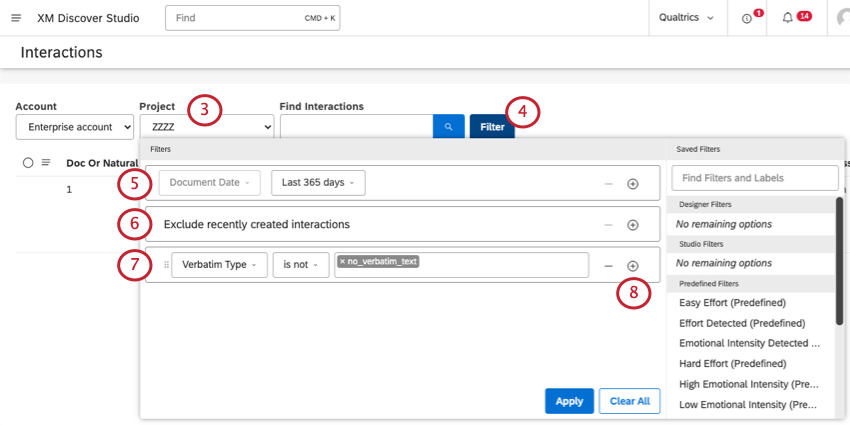
ヒント:アクセス権のあるものに応じて、アカウントとコンテンツプロバイダーを選択する必要がある場合もあります。 - フィルタをクリックします。
- 必要に応じて、伝票日付フィルタを調整します。デフォルトでは、30 日以内に記録された伝票のみが含まれるように設定されています。
ヒント:ドキュメント日付フィルターを削除できません。
- 完全な状態のデータのみが結果に含まれるように、過去 10 分以内にのみ登録されたインタラクションは除外されます。
ヒント:このフィルタは削除できません。
- デフォルトでは、テキストのない単語は結果から除外されます。マイナス記号 ( – ) をクリックすると、この条件を削除できます。
- さらに条件を追加するには、プラス記号 (+) をクリックします。
- 作成する条件の種類を選択します。
- 伝票日付: 伝票が登録された日付で伝票をフィルタリングします。詳細については、「日付範囲フィルタ」を参照してください。
- テキスト: 特定の単語またはフレーズを含む文書を検索します。検索の動作方法については、テキストフィルタを参照してください。
- トピック: カテゴリモデルまたはそのトピックでドキュメントをフィルタリングします。
- 属性: 構造化属性の値で文書をフィルタリングします。
- NLP: XM Discover Natural Language Processing (NLP) エンジンで検出された単語およびその他の言語エンティティでドキュメントをフィルタリングします。以下の NLP 条件セクションを参照してください。
- 右側から保存済みフィルタを選択することもできます。
ヒント:[フィルターの使用]ページでフィルターを保存する方法を学習します。
- 終了したら、適用をクリックしてインタラクションをフィルタリングします。
ヒント:既定のフィルターに戻るには、[すべてクリア]を選択します。
NLP 条件
自然言語処理 (NLP) 条件の場合、以下のオプションがあります。
- 単語: 単語または単語タイプ別にデータをフィルタリングします。オプションは次のとおりです。
- すべての単語: 任意の単語でデータをフィルタリングします。
- CB ブランド: ブランドメンション別にデータをフィルタリングします。
- CB 会社: 会社メンション別にデータをフィルタリングします。
- CB 通貨: さまざまな通貨名、シンボル、略語など、通貨数量別にデータをフィルタリングします。
- CB 電子メールアドレス: フィードバックに記載されている電子メールアドレスでデータをフィルタリングします。
- CB 顔文字: フィードバックで使用される絵文字および顔文字によってデータをフィルタリングします。
- CB イベント: フィードバックに記載されている休日およびイベント別にデータをフィルタリングします。
- CB 業種: 業種別にデータをフィルタリングします。
- CB 個人: フィードバックで言及されたユーザーの名前でデータをフィルタリングします。
- CB 電話番号: フィードバックに記載されている電話番号でデータをフィルタリングします。
- CB 製品: 製品メンション別にデータをフィルタリングします。
- CB 冒涜的言葉: 冒涜的な言葉でデータをフィルタリングします。
- 関連語: 関連付けられた単語のペアでデータをフィルタリングします。
- ハッシュタグ: ハッシュタグ (ハッシュ記号 (#) で始まる単語またはスペースのないフレーズ) によってデータをフィルタリングします。
- エンリッチメント:エンリッチメントは、XM Discover NLU(自然言語理解)エンジンによって導出される CX データです。エンリッチメントには、NLU エンジンによって文レベルまたはドキュメントレベルでの処理中にドキュメントに追加されたさまざまなメタデータが含まれます。フィルタリングできる拡張には、以下が含まれます。
- CB チャプタ: 期首、ニーズ、検証、ソリューションステップ、終了などの会話チャプタでデータをフィルタリングします。
- CB 検出機能: 検出された NLP 機能のタイプ別にデータをフィルタリングします。たとえば、業種またはブランドのメンションを含むデータをフィルタリングすることができます。
- CB エモーション: NLP エンジンによって検出された感情タイプ (怒り、混乱、失望感、禁煙、恐怖、不満、ジールージー、ジョイ、ラブ、サドネス、サプライズ、感謝度、信頼、その他など) によってデータをフィルタリングします。
- CB 文タイプ: 文のタイプでデータをフィルタリングします。
- コンテンツタイプ: コンテンツが含まれているかどうかによってデータをフィルタリングします。「内容に富んだデータ」とは、有効なレビュー、顧客フィードバック、または顧客との対話があることを意味します。”内容に問題がある” 文書には、有効なコンテンツがありません (以下のサブタイプを参照)。
- コンテンツサブタイプ: 空のデータを、広告、クーポン、記事リンク、または “未定義” タイプなどのサブタイプによってさらにフィルタリングします。
ヒント:利用可能なデータによっては、ここに記載されていない追加のエンリッチメントがある場合があります。
- 言語: 言語別にデータをフィルタリングします。
- 自動検出言語: 自動的に検出された言語でデータをフィルタリングします。これは、プロジェクトに対して言語の自動検出が有効になっている場合にのみ役立ちます。
- 処理済言語: フィードバックが処理された実際の言語でデータをフィルタリングします。XM Discoverでサポートされていない言語は「OTHER」とマークされます。サポートされている言語のリストについては、XM Discoverサポートチームにお問い合わせください。
演算子
演算子は、選択したフィルタ条件とターゲットの関係を定義する方法です。たとえば、センチメントが 5 以上の文書のみを含める場合、”以上” が演算子です。
使用可能な演算子の一覧を参照してください。