-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
フィルター・インタラクション(スタジオ)
相互作用のフィルターについて
日付やその他のパラメーターでドキュメントをフィルターできます。これは、特定の回答を探したり、何を削除またはエクスポートするかを決定する際に役立ちます。
Qtip:インタラクション年齢に適用されたフィルターはエクスポートに反映されます。
Qtip: フィードバックをテキストでフィルタすると、結果ペインが常にすべての文章を表示するように切り替わります。
相互作用のフィルター
Qtip:このページにアクセスするには、View Interactions Explorerのパーミッションが必要です。
- Spacesメニューをクリックする。
- 相互作用を選択する。
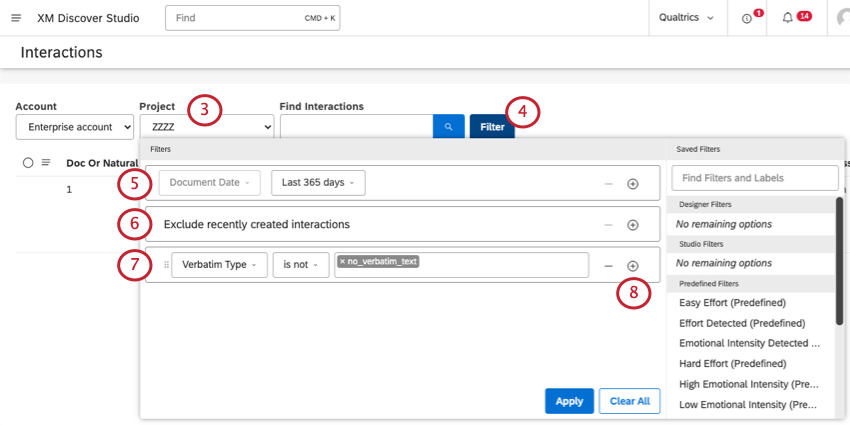
- プロジェクトドロップダウンを使用して、さまざまなプロジェクトに関連するインタラクションを表示します。
 Qtip:アクセシビリティによっては、アカウントとコンテンツプロバイダーを選択する必要があります。
Qtip:アクセシビリティによっては、アカウントとコンテンツプロバイダーを選択する必要があります。 - フィルターをクリックします。
- 必要に応じて、日付フィルタを調整します。デフォルトでは30日以内に記録された文書のみが含まれるように設定されている。
Qtip:ドキュメントの日付フィルターは削除できません。
- 過去10分以内に作成された結果のみが除外され、完全に準備されたデータのみが結果に含まれるようになります。
Qtip:このフィルターは削除できません。
- デフォルトでは、テキストのない逐語訳は結果から除外されます。マイナス記号(-)をクリックすると、この条件を削除できます。
- さらに条件を追加するには、プラス記号(+)をクリックします。
- 作成したい条件の種類を選択します:
- 文書の日付:ドキュメントの作成日でフィルターをかけます。詳しくは日付範囲フィルタをご覧ください。
- テキスト特定の語句を含む文書を検索します。検索の仕組みについてはテキストフィルターをご覧ください。
- トピック:カテゴリモデルまたはそのトピックによってドキュメントをフィルタ。
- 属性:構造化された属性の値でドキュメントをフィルタ。
- NLP:XM Discoverの自然言語処理(NLP)エンジンによって発見された単語やその他の言語エンティティによってドキュメントをフィルタリングします。下記の「 NLP条件」の項をご覧ください。
- また、右から保存されたフィルタを選択することもできます。
Qtip:フィルタの保存方法については、「フィルタの使用」のページをご覧ください。
- 完了したら、適用をクリックしてインタラクションをフィルタリングする。
Qtip:デフォルトのフィルターに戻すには、Clear Allを選択します。
NLP条件
自然言語処理(NLP)の条件については、以下のオプションがある:
- 単語:単語や単語の種類でデータをフィルターします。オプションは次のとおりです。
- すべての単語:選択肢の単語でデータをフィルタ。
- CBブランド:ブランド名でフィルタ。
- CBカンパニー会社名でフィルターをかける。
- CB通貨:通貨名、記号、略語を変えるなど、通貨量でデータをフィルタ。
- CBメールアドレス:フィードバックに記載されたメールアドレスでデータをフィルタ。
- CBエモーティコン:フィードバックで使用される絵文字やエモーティコンでデータをフィルタ。
- CBイベント:フィードバックで言及された休日やイベントでデータをフィルタ。
- CB インダストリー業種別フィルター。
- CB Person:フィードバックで言及された人の名前でデータをフィルタ。
- CB電話番号:フィードバックに記載された電話番号でデータをフィルタ。
- CB製品:製品の言及によってデータをフィルタリングします。
- CB冒涜:冒涜的な言葉でデータをフィルタリングします。
- 関連語: 関連する単語のペアでデータをフィルタリングします。
- ハッシュタグ:ハッシュタグ(ハッシュ記号(#)で始まる単語またはスペースのないフレーズ)でデータをフィルターします。
- エンリッチメント: エンリッチメントは、XM Discover NLU(自然言語理解)エンジンが導き出したCXデータです。エンリッチメントには、処理中にNLUエンジンが文または文書レベルで文書に追加するさまざまなメタデータが含まれる。フィルタリングできるエンリッチメントには次のようなものがある:
- CBチャプター:オープニング、ニーズ、検証、解決ステップ、クロージングなどの会話チャプターでデータをフィルタします。
- CB検出機能:検出されたNLP機能の種類によってデータをフィルタリングします。例えば、業界やブランドの言及を含むデータをフィルターすることができます。
- CBエモーション:Anger(怒り)、Confusion(混乱)、Disappointment(失望)、Embarrassment(恥ずかしさ)、Fear(恐怖)、Frustration(欲求不満)、Jealousy(嫉妬)、Joy(喜び)、Love(愛)、Sadness(悲しみ)、Surprise(驚き)、Thankfulness(感謝)、Trust(信頼)、Other(その他)など、NLPエンジンが検出した感情の種類によってデータをフィルタリングします。
- CB センテンスタイプ:文の種類によってデータをフィルタリングする。
- コンテンツ・タイプ:データにコンテンツが含まれているかどうかでフィルタをかける。”コンテンツの検証 “データは、有効なレビュー、顧客のフィードバック、または顧客との対話があることを意味します。contentful」でないドキュメントはコンテンツの検証を行わない(以下のサブタイプを参照)。
- コンテンツのサブタイプ:広告、クーポン、記事リンク、または「未定義」タイプなど、サブタイプによって空のデータをさらにフィルタリングします。
Qtip:入手可能なデータによっては、ここに掲載されていない充実した内容があるかもしれません。
- 言語言語によるフィルター。
- 自動検出された言語:自動的に検出された言語によってデータをフィルタリングします。これは、プロジェクトで言語の自動検出が有効になっている場合にのみ有効です。
- 処理された言語:フィードバックが処理された実際の言語によってデータをフィルタする。XM Discoverでサポートされていない言語はOTHERと表示されます。対応言語のリストについては、XM Discoverサポートチームまでお問い合わせください。
オペレーター
演算子は、選択したフィルター条件とターゲットとの関係を定義する方法である。例えば、感情が5以上の文書だけを含めたい場合は、”greater than or equal to “が演算子となります。
利用可能なオペレーターのリストを見る。