データフローのマネージャー(デザイナー)
このページの内容
データフローのマネージャーについて
データフローを作成したら、「データフロー」タブでそのデータフローをマネージャーすることができます。これには、データフローを後でスケジューリングしたり、キューに入れられたデータフローを削除したり、データフローを停止したりすることが含まれる。
データフローのスケジューリング
データフローを定期的に実行するようにスケジュールすることができます。
対応データフロー
すべてのデータフローがスケジューリングをサポートしているわけではない。以下のデータフローをスケジュールできる:
- 分類:このデータフローは、選択されたモデルの分類を実行する。インクリメンタルデータロードのテーマ検出がこれらのモデルで有効になっていれば、スケジュール通りに実行される。
- 連続プロセスモニター(事前にスケジュールされている):このデータフローは、データローダーを使用してアップロードされたデータの処理を確定するために必要である。
- カスタムデータフロー:管理者またはサービスチームが作成したデータフローをスケジュールできます。
- カスタムエクスポート:CSVファイルにデータをエクスポートします。
- データ・ローダー・アーカイブ(事前スケジューリング):このデータフローは、データローダーによって処理されたレコードをアーカイブする。
- 統計情報を収集する(事前にスケジュールされている):プロジェクトの統計情報を更新します。このデータフローは週に1度実行することをお勧めする。このデータフローによって影響を受ける統計は以下の通りである:
- Dataflowsタブに表示されるドキュメント、逐語訳、センテンスの総数。
- 感情タブの単語出現数。 Qtip:このデータフローはレポートには影響しません。

- DB レポート結果ストアの完全削除(事前にスケジュール):このデータフローは、定義された期間より古いレポート結果をすべて削除します。
- 通知期限切れ(事前スケジュール):このデータフローは、アカウントから期限切れの通知を削除します。通知の有効期限はアカウント設定で定義されます。
- 感情の再計算:このデータフローでは、感情データを再計算することができます。
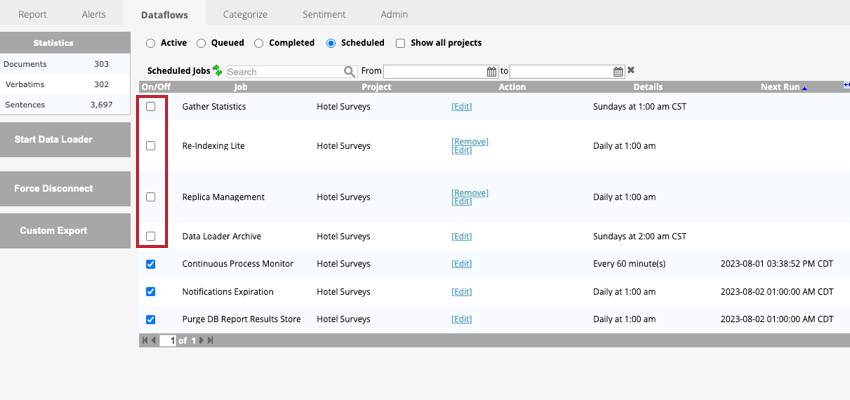
Qtip:スケジュール済みのデータフローはデフォルトで “Scheduled “タブに表示され、そこから削除することはできませんが、無効にすることはできます。
データフローのスケジューリング
データフローを定期的なスケジュールで実行するように設定することができます。データフローをスケジュールするには、まずデータフローを作成し、それを一度実行する必要がある。
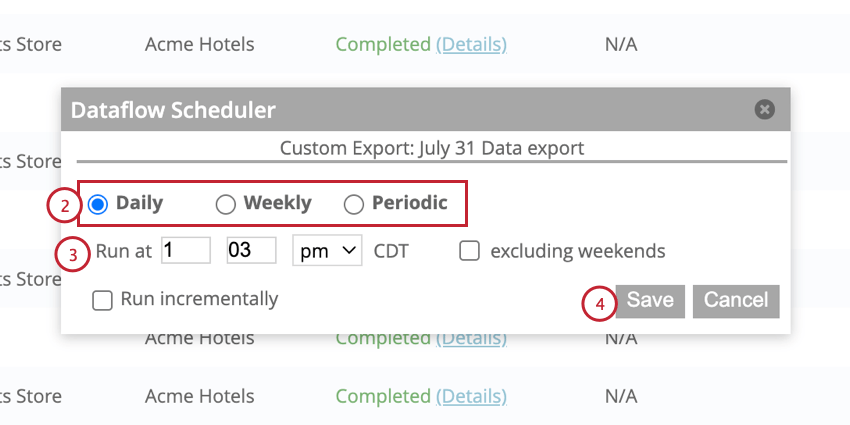
- 毎日:1日1回データフローを実行する。
- 毎週:週1回データフローを実行する。
- 定期的に:定期的なスケジュールでデータフローを実行する。データフローは一定の分数または時間後に実行される。
Qtip:DataflowsのスケジュールはCDTタイムゾーンで表示されます。データフロー・スケジュールを選択する際には、この点に留意すること。
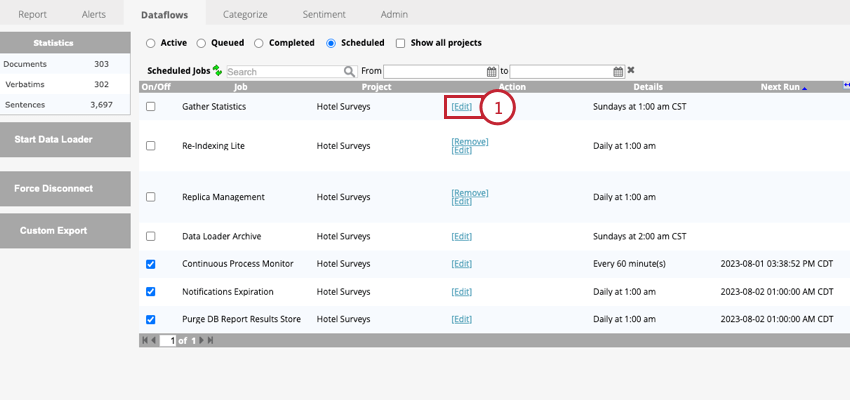
データフローのスケジュール変更
スケジュールされたデータフローの頻度はいつでも変更できる。
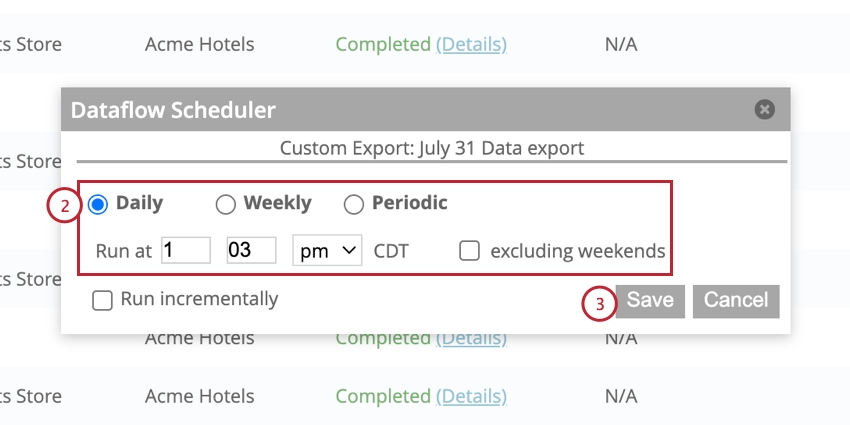
スケジュールされたデータフローの一時停止
スケジュールされたデータフローを一時停止して、一時的に実行しないようにすることができます。スケジュールされたデータフローを一時停止するには、Scheduledタブのデータフローの次へ のチェックボックスを外す。
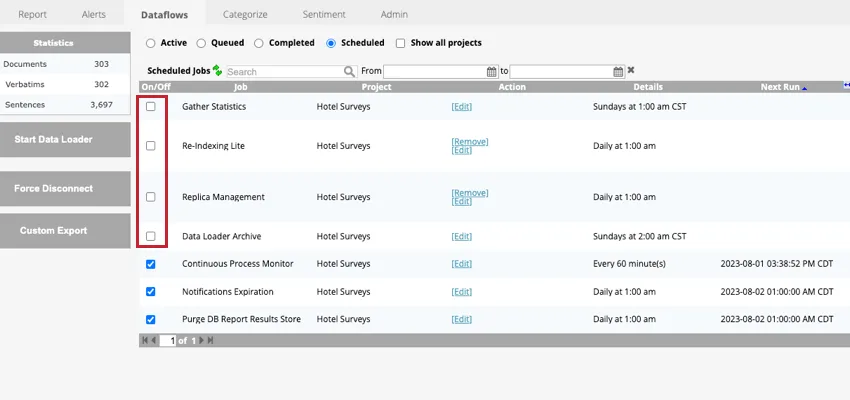
データフローが一時停止している場合、次へ実行の列は空になります。
スケジュールされたデータフローを再開するには、データフロー名の次へ のチェックボックスをオンにします。データフローが一時停止している間にデータフローの実行がスキップされた場合、実行は一時停止を解除した直後に処理され、その後、データフローはスケジュール通りに実行を継続する。
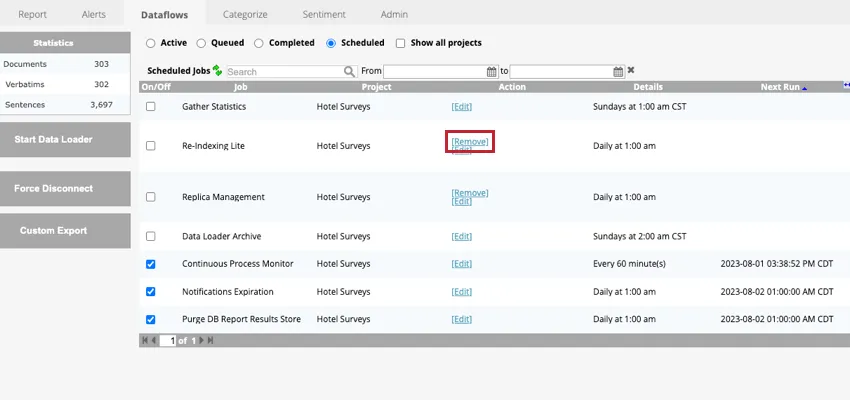
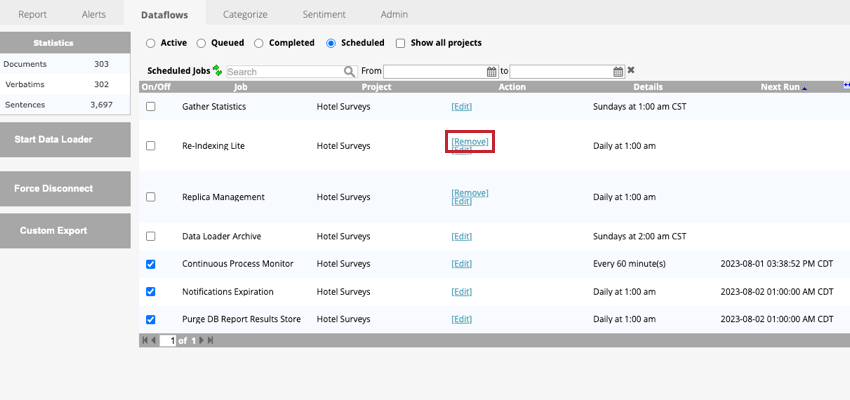
スケジュールされたデータフローの削除
スケジュールされたデータフローを永久に削除し、ITが実行されないようにするには、Scheduledタブでデータフローを表示する際にRemoveオプションをクリックします。
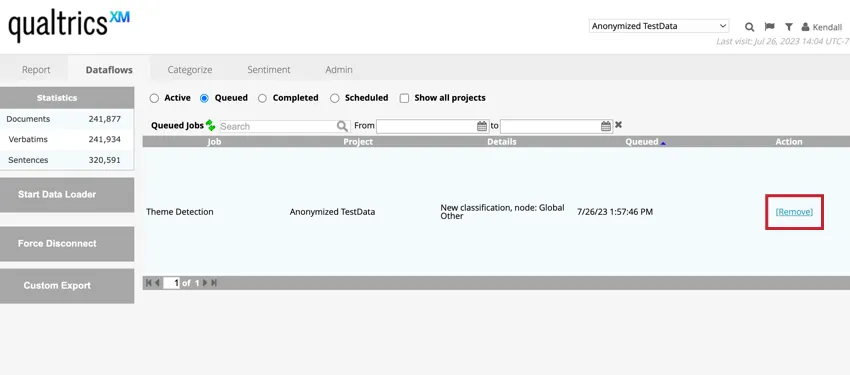
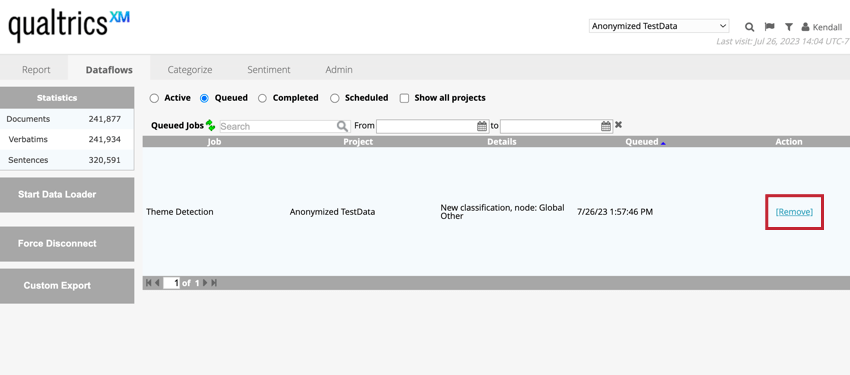
キューに入れられたデータフローの削除
データフローが処理キューに入っている場合、「キュー入り」タブでデータフローを確認しながら、データフロー名の次へ「削除」をクリックすることで、そのデータフローをキューから削除することができます。
データフローの停止
実行中のデータフローを停止またはキャンセルすることができる。データフローを停止するには2つの異なる方法がある:
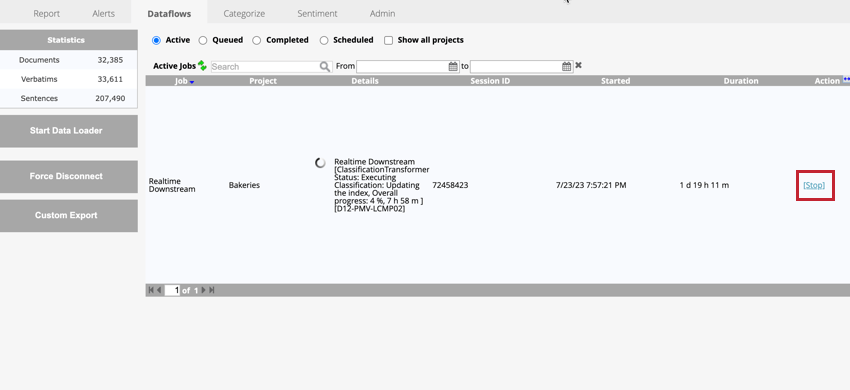
- Stop:このオプションは、データフローを緊急でない方法で一時停止し、データフローが停止する前にデータフローの現在のステップが処理を終了することを可能にする。これは、データフローを一時停止して別のデータフローを処理する必要がある場合や、データフローを再開する前に追加タスクを実行するためにデータフローを一時停止する必要がある場合に便利です。
- 強制切断:このオプションは、データフローを緊急停止させ、データフローの現在のステップを中断させる。このオプションは、プロジェクトに関連するすべての活動を停止し、すべてのアクティブユーザーを切断し、すべてのキューに入れられたジョブをキャンセルします。
停止
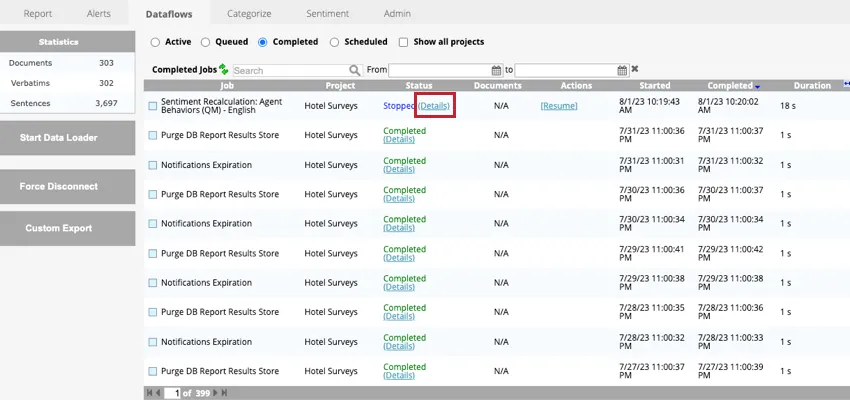
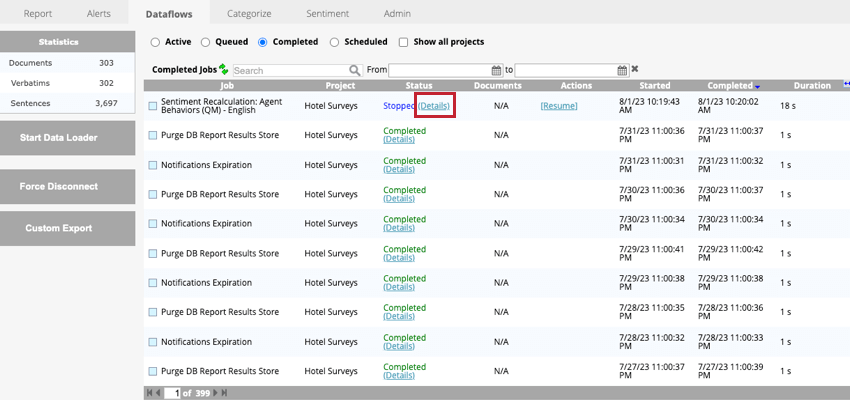
緊急でないオプションを使用してデータフローを停止するには、アクティブ タブでデータフローを表示しているときに、データフロー名の次へ の停止をクリックします。これにより、データフローはステータスがStoppedのCompletedタブに移動する。

Completed」タブをクリックし、データフローの次へ「Details」をクリックすることで、データフローのどのコンポーネントが完了したかを確認することができる。
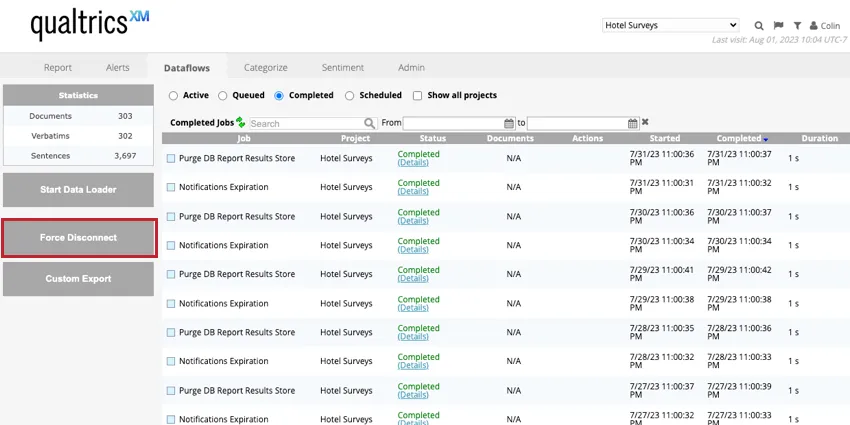
強制切断
注意: このオプションは、すべてのデータベース接続を再起動することで、すべてのプロジェクト活動を停止します。
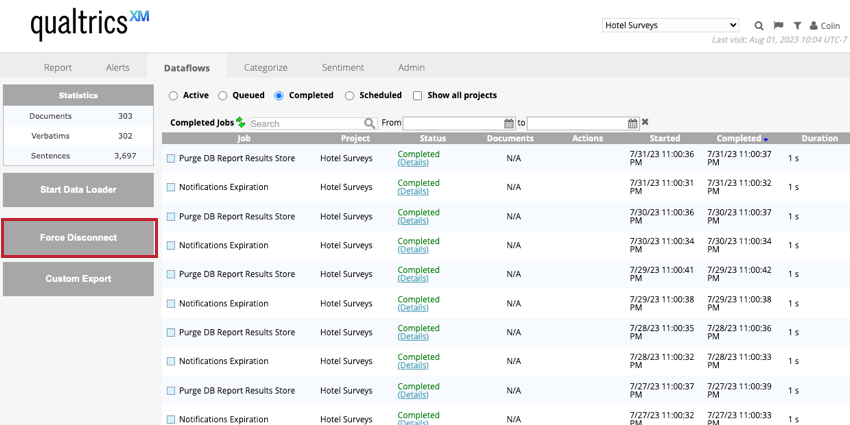
緊急オプションを使用してデータフローを停止するには、DataflowsタブにあるForce Disconnectボタンをクリックする。これにより、すべてのデータフローが「Completed(完了)」タブに移動し、ステータスは「Failed(失敗)」となる。
Qtip:“Show all projects “オプションが有効な場合、強制切断ボタンは非表示になります。
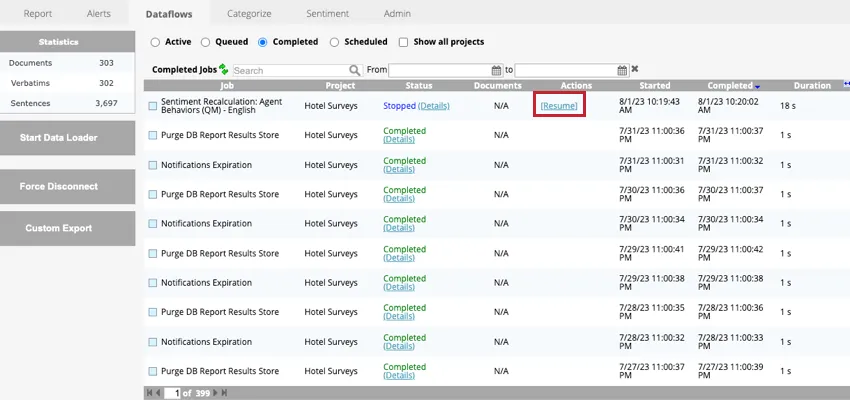
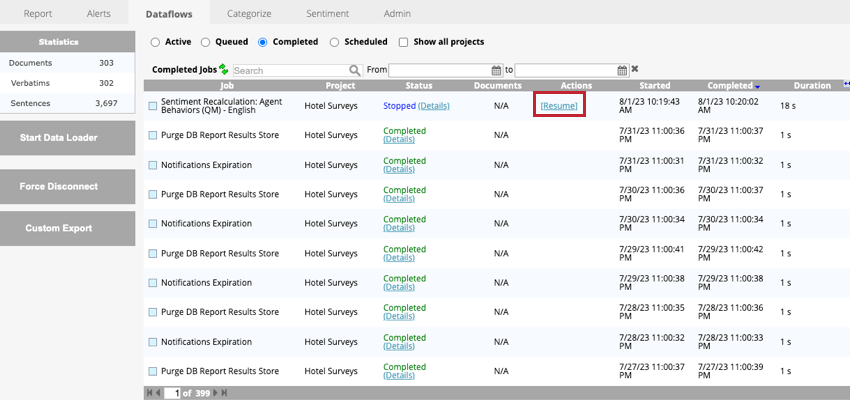
停止したデータフローの再開
停止したデータフローを再開するには、Completedタブに移動し、データフローの次へResumeをクリックします。データフローは、中断したところから再開される。
Qtip:失敗したデータフローを再開するために再開をクリックすることができますが、潜在的な問題を避けるために、データフローを正常に再実行することをお勧めします。
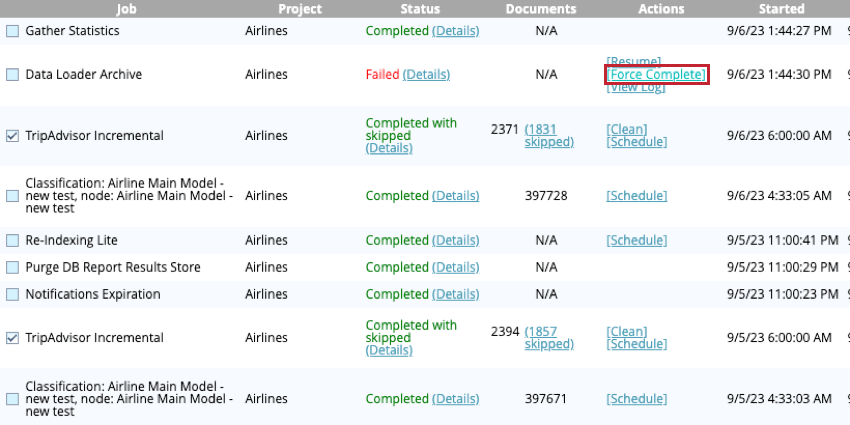
データフローの強制終了
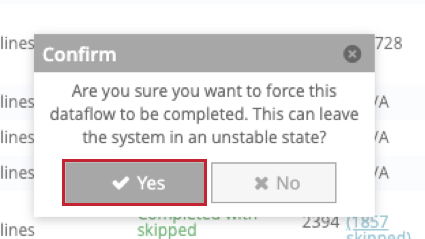
停止または失敗したデータフローを強制的に完了させることができる。データフローを強制完了するには、Completedタブに移動し、データフローの次へForce Completeをクリックします。
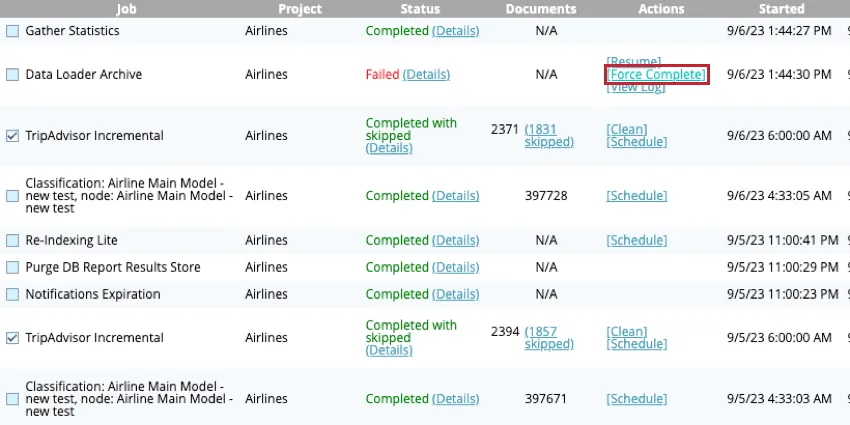
表示されるポップアップウィンドウで、「はい」をクリックして決定を確定する。
増分データのアップロード
プロジェクトに最初のデータアップロードを完了した後、そのプロジェクトにさらにデータをロードすると、すべて「増分」追加とみなされます。ということだ:
- 初期フィードバックデータと構造化属性がプロジェクトに追加される。
- インクリメンタルアップロードは、システムによって別個のアップロードセッションとして扱われる。できる:
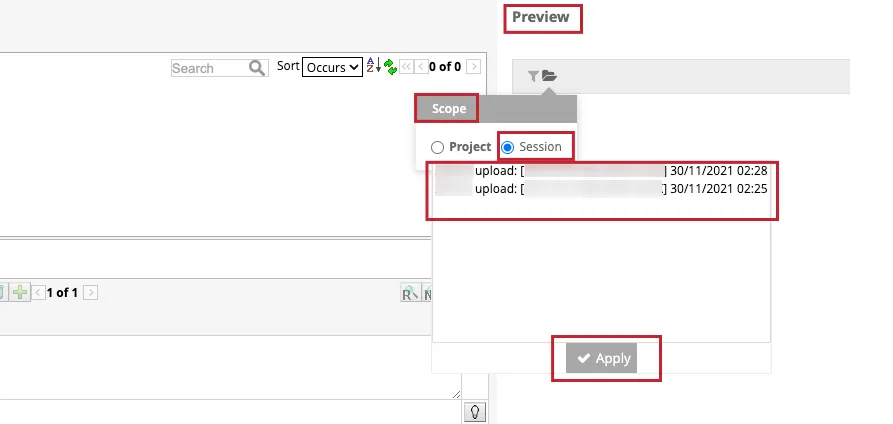
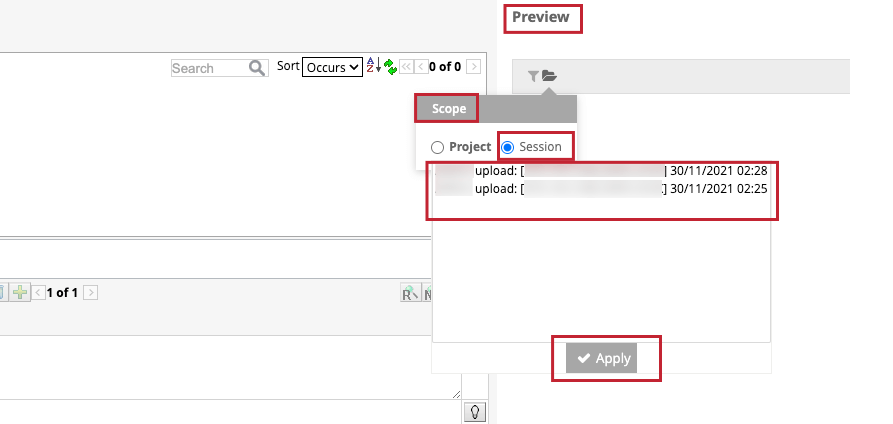
- Categorize]タブで特定のセッションの文章をカテゴリーレベルでプレビューする:[プレビュー]セクションのフォルダアイコンをクリックし、[セッション]チェックボックスを選択し、特定のアップロードセッションをクリックし、[適用]をクリックします。
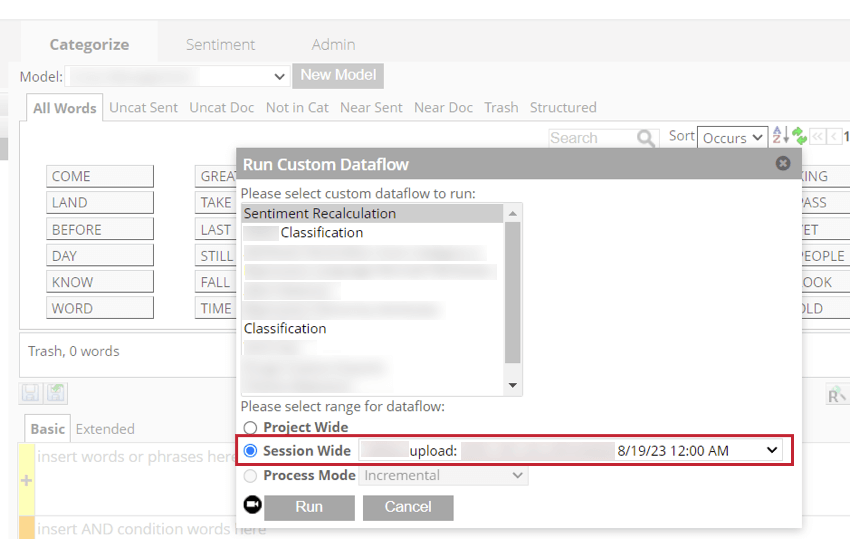
- セッション全体のデータフローを実行する。
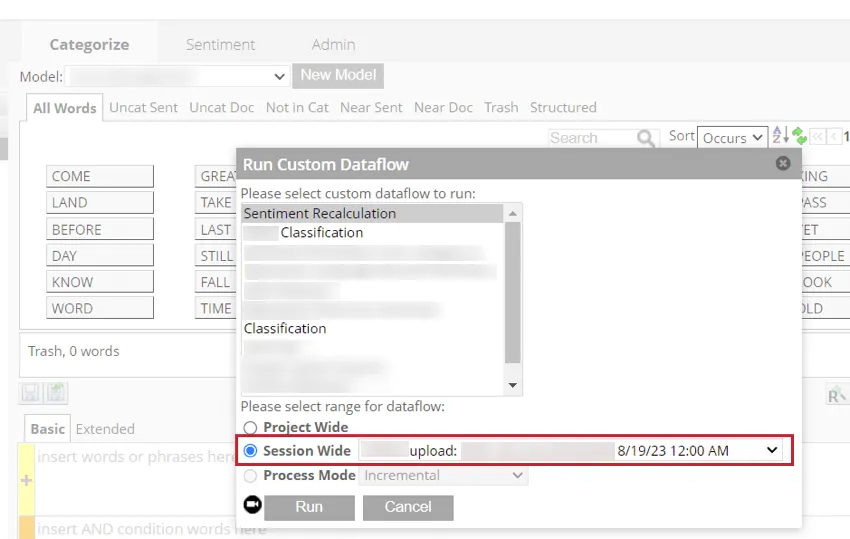
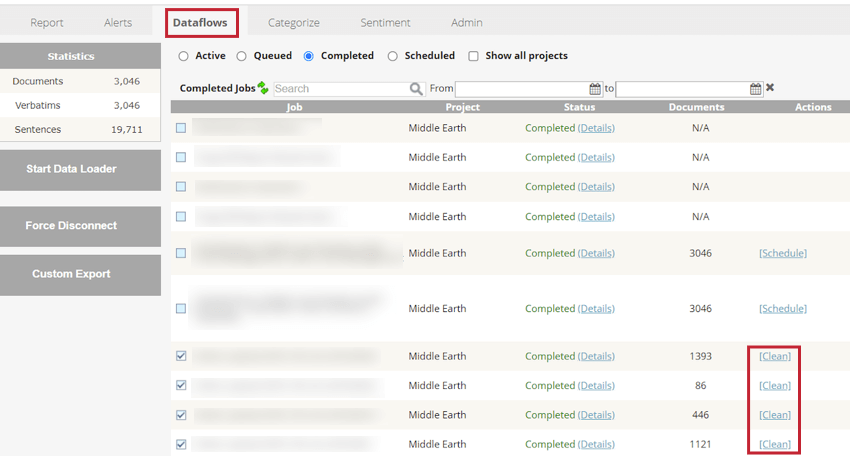
- Dataflowsタブで、特定のアップロードセッション中にアップロードされたクリーンデータを、構造化属性とともに表示します。

- Categorize]タブで特定のセッションの文章をカテゴリーレベルでプレビューする:[プレビュー]セクションのフォルダアイコンをクリックし、[セッション]チェックボックスを選択し、特定のアップロードセッションをクリックし、[適用]をクリックします。
- インクリメンタルデータは、プロジェクトのカテゴリーモデルに分類されるべきである。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
増分アップロードの分類の詳細については、増分アップロードの分類を参照してください。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!