データローダー(デザイナー)
スイート
Customer Experience
製品
Qualtrics
このページの内容
データローダーについて
データローダーは、リアルタイムのAPIサービスを介してXM Discoverのプロジェクトにデータをインポートするために使用されます。データローダーにアクセスするには、管理ページに移動し、プロジェクトを選択し、データローダータブに移動します。
注意: クアルトリクスのテクニカルコンサルタントが、お客様のプロジェクトにデータをインポートするためのデータローダーをセットアップします。テクニカル・コンサルタントに相談せずにデータ・ローダーの設定を変更しないでください。データローダーの設定が正しくない場合、XM Discoverへのデータのインポートに失敗することがあります。
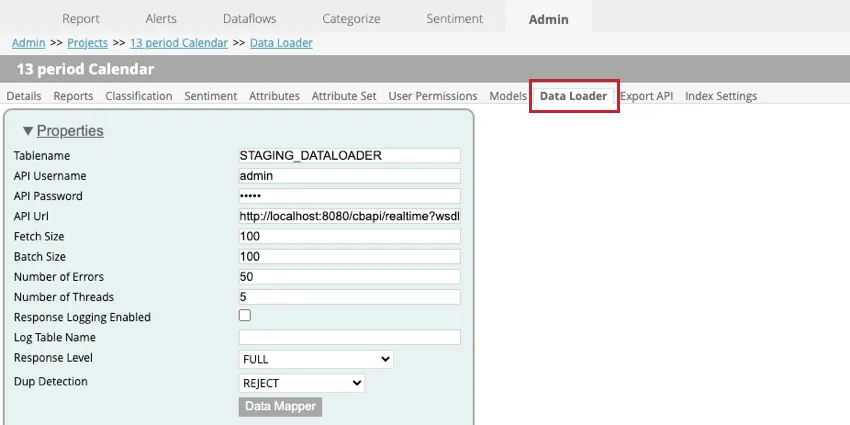
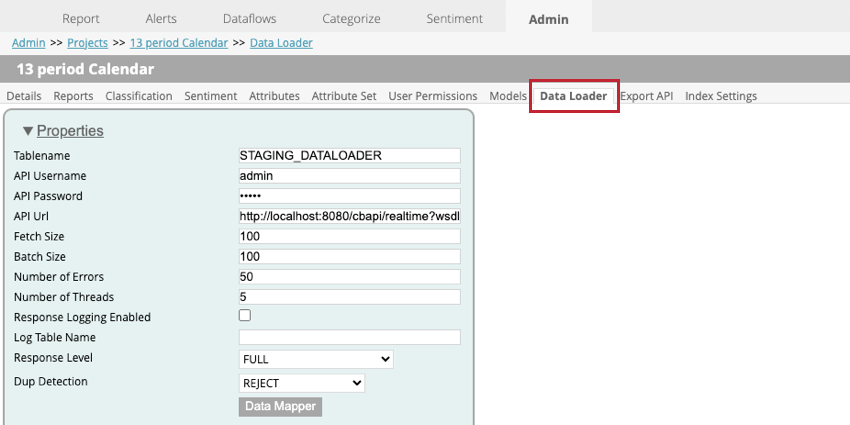
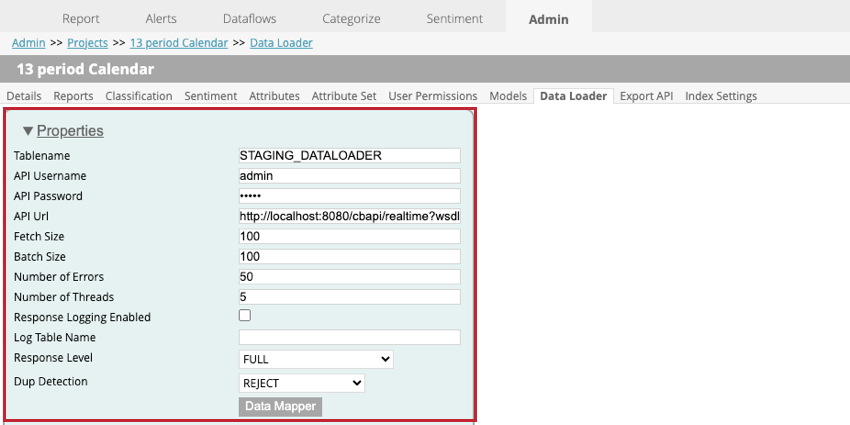
データローダーの設定
プロジェクト内でデータローダーを設定する場合、以下の設定が可能です:
- Tablename: XM Discoverにインポートするデータを含むステージングテーブルの名前を入力します。
- APIユーザー名:APIコールを実行できるAPIユーザーのユーザー名を入力します。
- APIパスワード。APIユーザーのユーザー名を入力してください。
- API Url:データの取得に使用するAPIサービスのUrlを入力します。
- フェッチ・サイズ:インポートする行数を指定します。
- バッチサイズ:1バッチでインポートする行数を指定します。バッチサイズがフェッチサイズより大きい場合、すべてのデータがインポートされるまで複数回の呼び出しが実行されます。
- エラーの回数:エラー数:エラーによってインポートに失敗した場合、何回呼び出しを再試行するかを指定できます。
- スレッド数:1 つのトランスフォーマインスタンスで実行するスレッドの最大数を入力します。
- 回答ログ有効:このオプションを有効にすると、文書処理結果のログを作成できます。
- ログテーブル名:結果を記録する場合、新しいテーブルが作成されます。このフィールドにテーブル名を入力する。 Qtip:このフィールドに何かを指定する必要があるのは、[回答ログ有効]が選択されている場合のみです。

- 回答レベル:このオプションはSAVE ONLYに設定してください。
- 重複検出:複製をどのように処理するかを選択します。オプションは次のとおりです。
- なし:複製がインポートされます。
- 拒否する:複製は拒否される。
- 属性を更新する:構造化属性のみ複製を更新する。
- データマッパー:データマッパーは、XM Discoverで使用するためにステージングテーブルから抽出されるフィールドを選択するために使用されます。詳細は以下のデータマッパーのサブセクションを参照。
データマッパー
データマッパーは、XM Discoverで使用するためにステージングテーブルからデータを抽出するために使用されます。データマッパーはステージングテーブルにあるフィールドのみを含めます。
データローダーの設定で、データマッパーをクリックします。
データソースを示すフィールドを選択します。
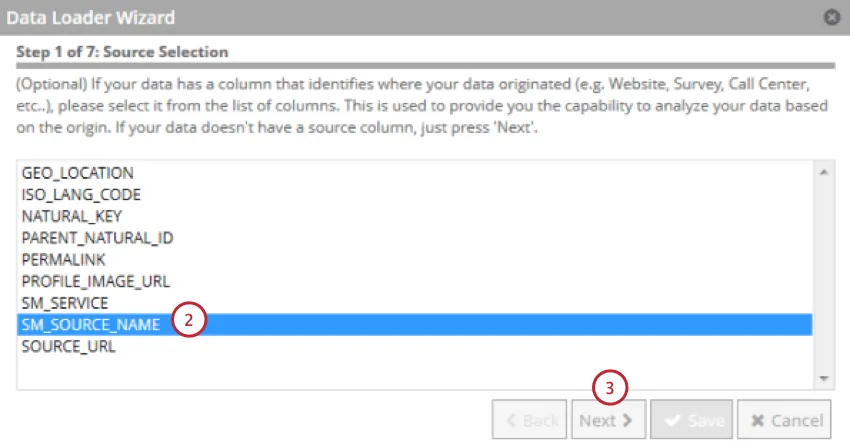
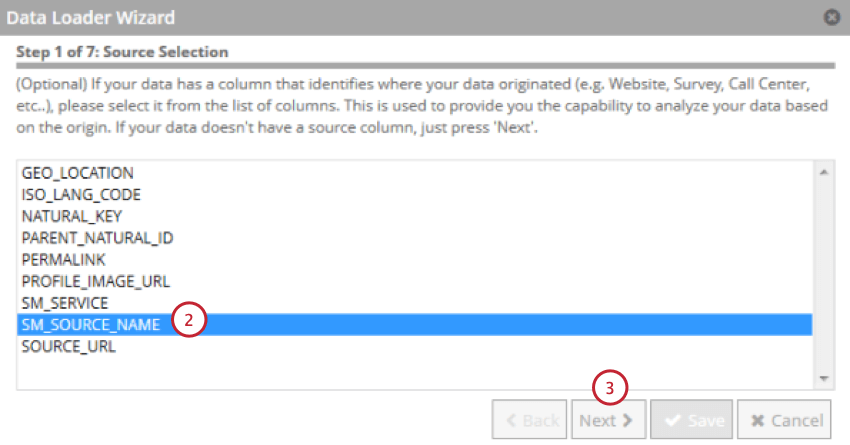
[次へ]をクリックします。
ナチュラルキーとして使用するフィールドを選択し、右向きの矢印(>)をクリックします。複数のフィールドを選択することができ、ナチュラル・キーは選択した順番にフィールドを連結したものになる。
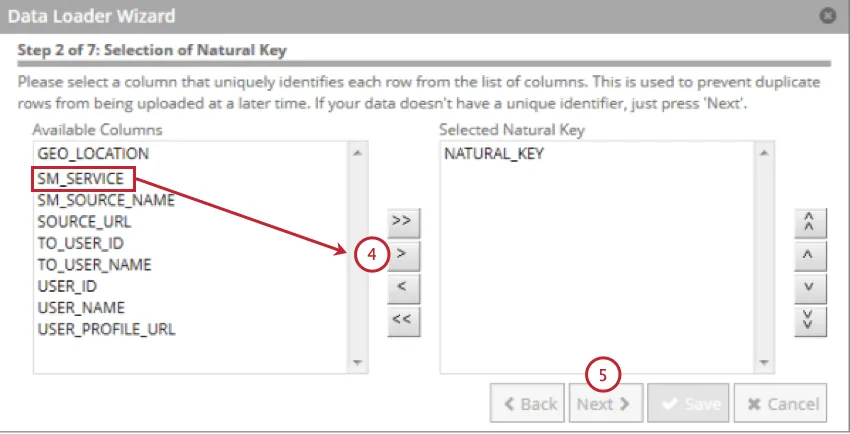
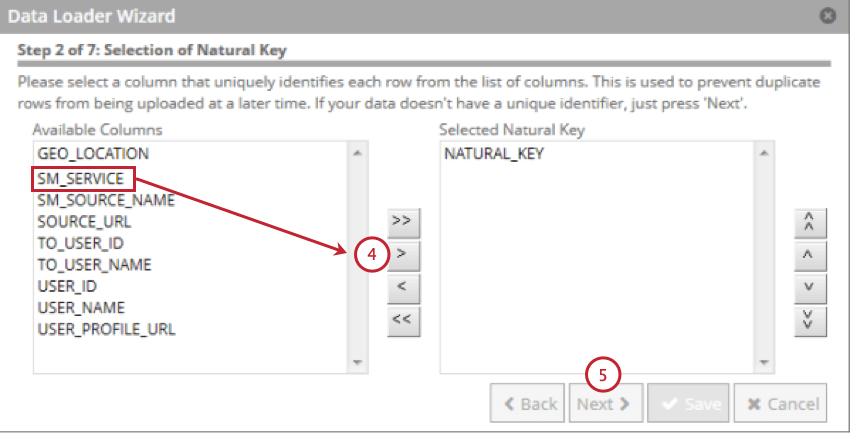
Qtip:256文字以上のフィールドは除外されます。自然キーは256文字に切り捨てられる。
[次へ]をクリックします。
カスタマーの逐語表現が含まれるフィールドを選択し、右向きの矢印(> )をクリックします。

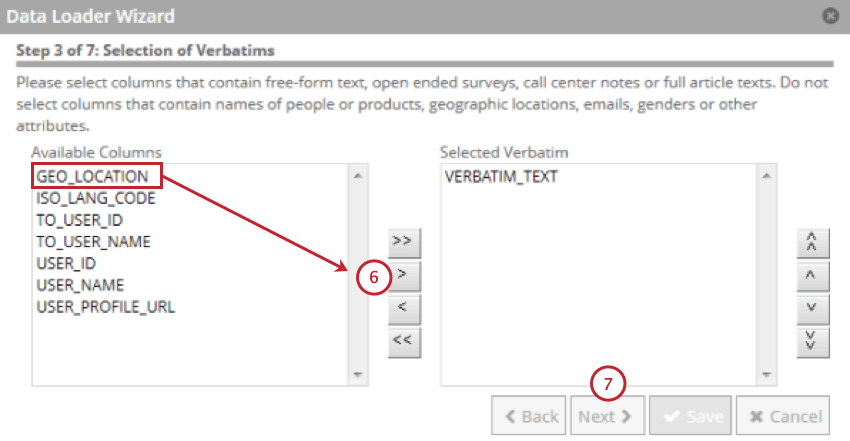
[次へ]をクリックします。
構造化属性を含むフィールドを選択し、右向きの矢印(>)をクリックします。最大500の構造化属性を選択できる。
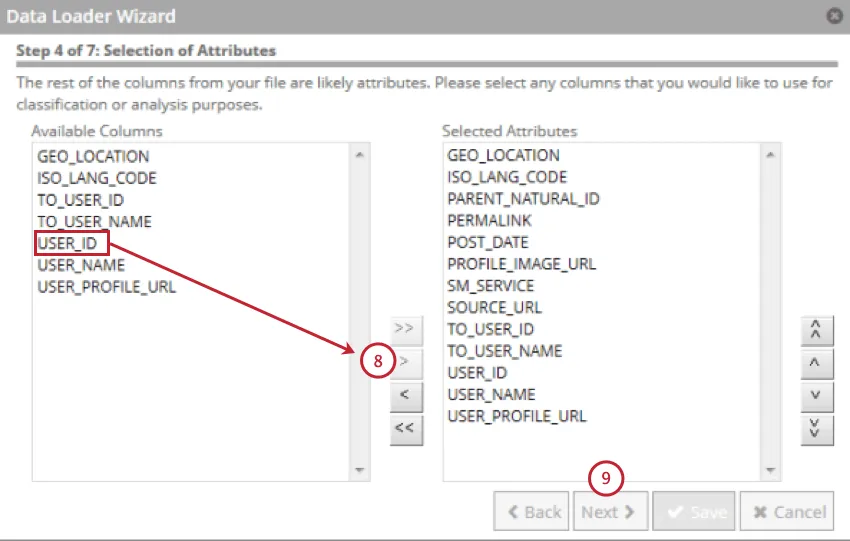
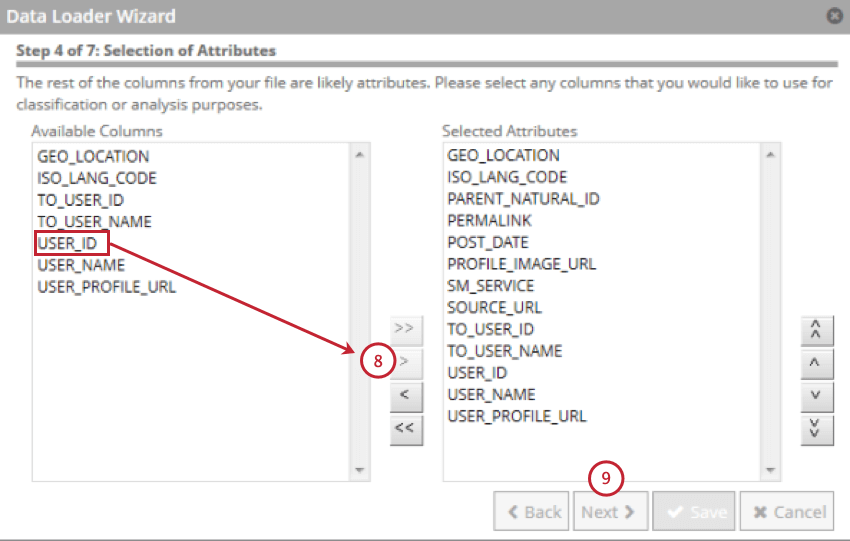
[次へ]をクリックします。
自分の属性を見直し、必要に応じて変更する。属性の表示名、タイプ、レポート可否を変更し、フィールドがEメールであるかどうかを示すことができます。
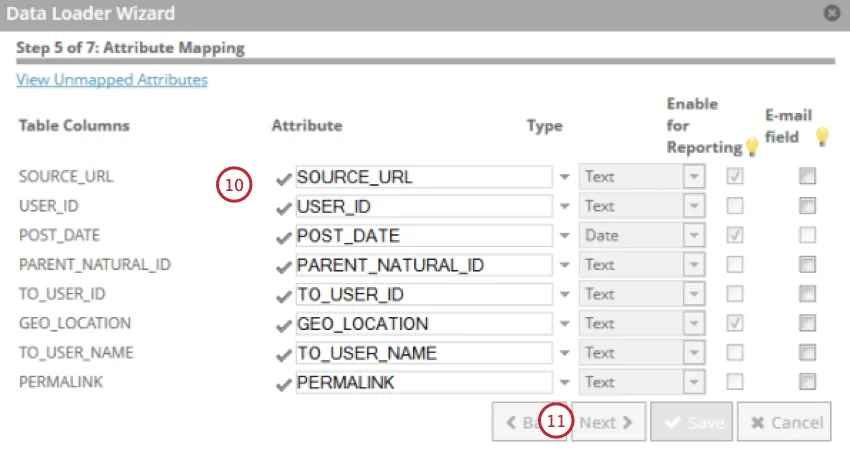
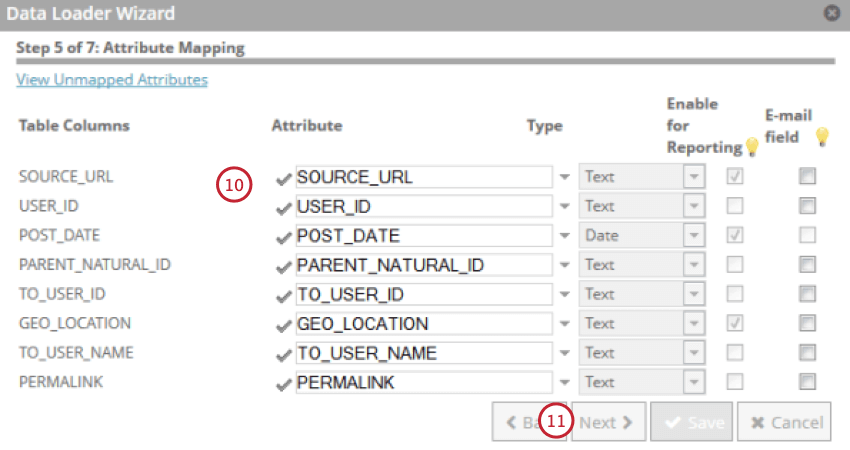
[次へ]をクリックします。
文書が作成された日付を含むフィールドを選択します。これはXM Discoverの基準日として使用されます。
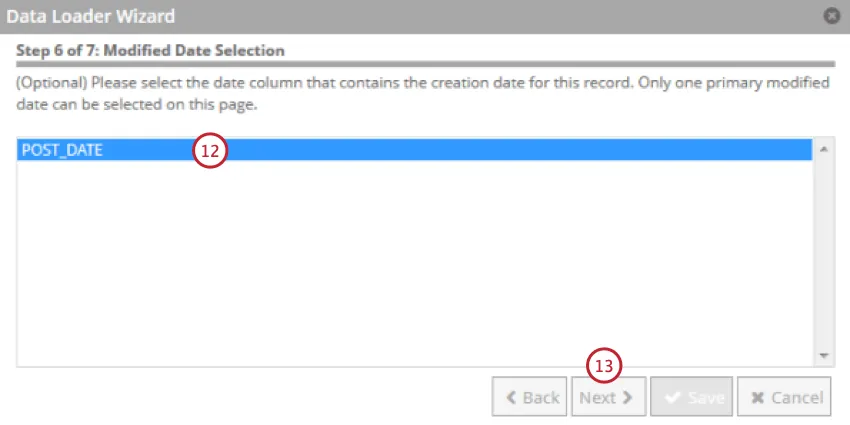
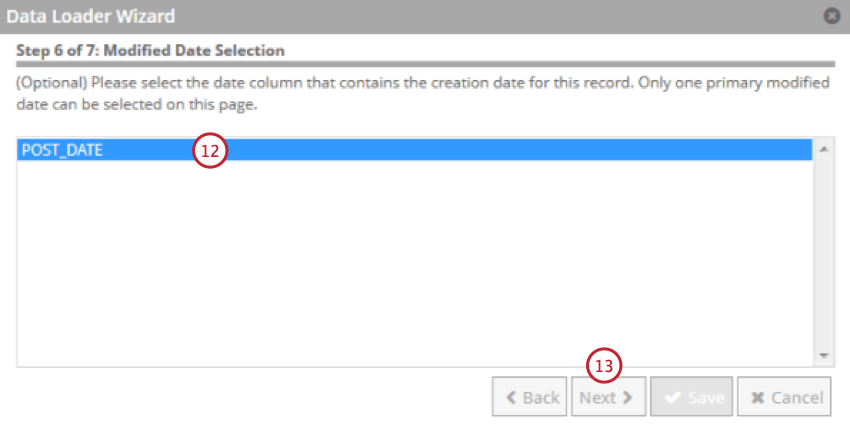
[次へ]をクリックします。
文書の言語を含むフィールドを選択します。
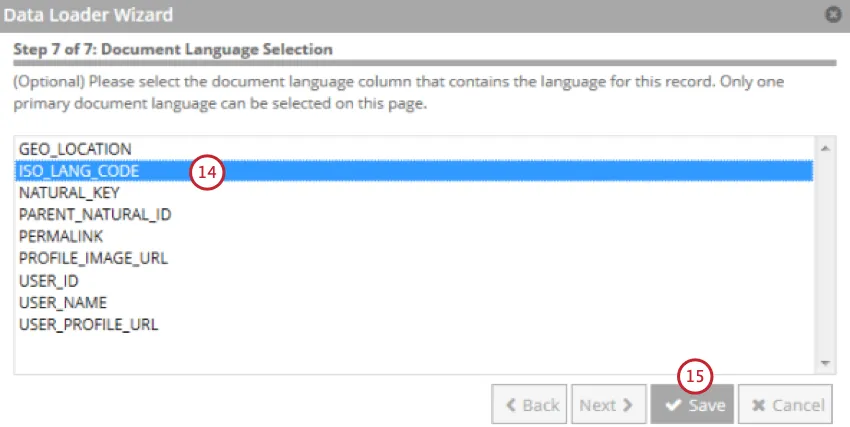
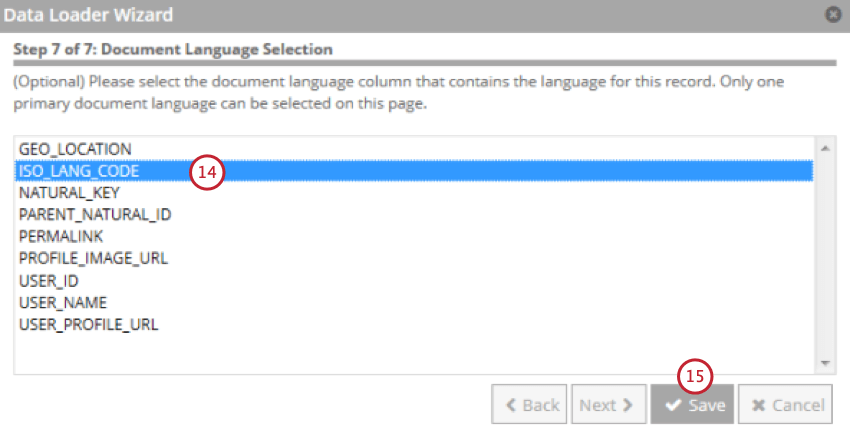
[保存]をクリックします。
データローダーでデータをインポートする
データローダーでデータをステージングテーブルにロードした後、そのデータを加工してXM Discoverで使用することができます。このセクションでは、データが常に最新の状態に保たれるように、自動データ・ロード・プロセスを設定する方法について説明します。
データフロー 」タブを開く。
![データフロー]タブの[データローダーの開始]をクリックします。](https://www.qualtrics.com/sites/default/files/styles/standard_xl_retina/public/migrations/dsx/content/data-loader-1-2_4.png.webp?itok=ys-fVtv0)
![データフロー]タブの[データローダーの開始]をクリックします。](https://www.qualtrics.com/m/assets/support/wp-content/uploads//2023/09/data-loader-1-2.png)
Start Data Loaderをクリックします。
DataflowsのScheduledセクションに移動する。
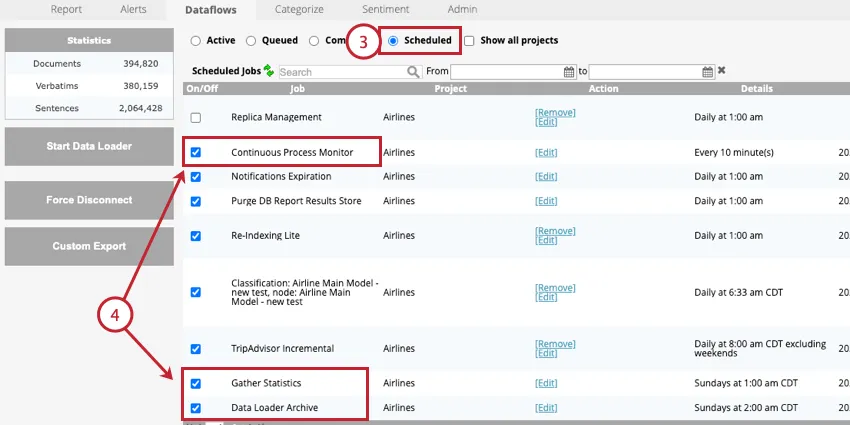
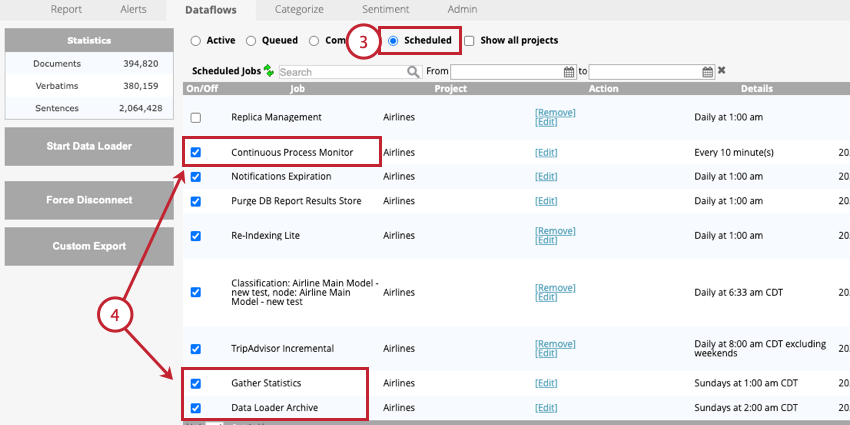
以下のジョブを有効にする:
- 連続プロセスモニター:この仕事は必須です。このデータフローは、リアルタイム・ダウンストリームを定期的に実行し、データ処理を確定する。
- データ・ローダー・アーカイブ:この作業はオプションですが、強くお勧めします。このデータフローは、データローダーによって処理されたレコードをアーカイブする。データローダーの頻度に合わせて、このジョブの頻度を更新する必要がある。
- 統計を収集する:この仕事はオプションである。このジョブは週に1回実行することを推奨する。このデータフローは以下のプロジェクト統計を更新する:
- Dataflowsタブに表示されるドキュメント、逐語訳、センテンスの総数。
- 感情タブに表示される単語の出現回数の合計。
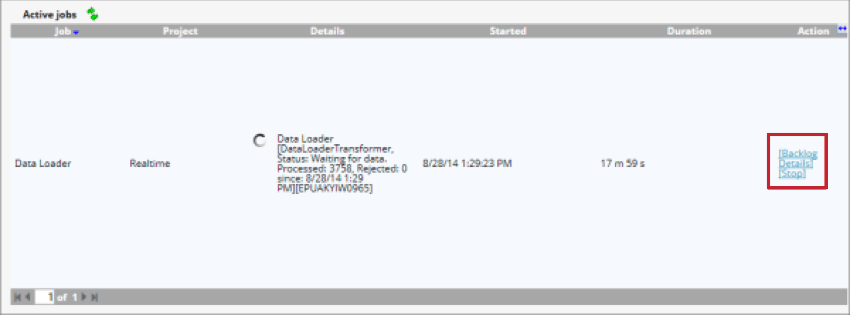
データ・ローダー・オプション
データローダーが起動したら、以下のオプションでジョブを管理できます:
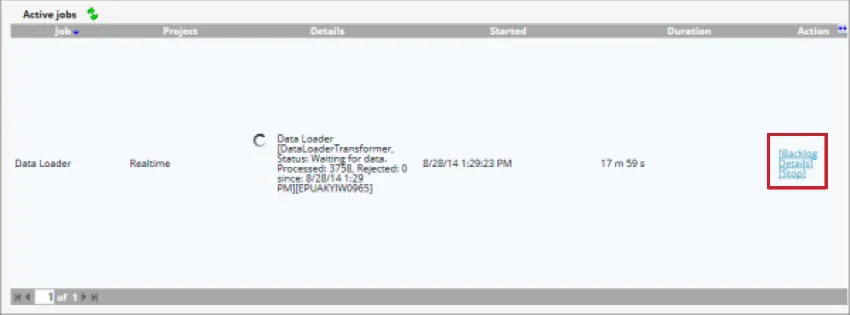
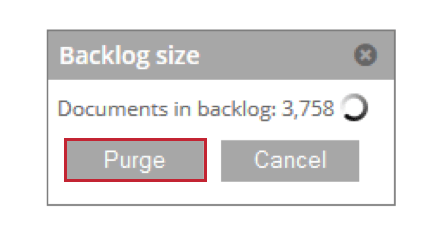
- バックログ:処理待ちの文書数を表示します。これらの文書をステージング・テーブルから削除するには、[Purge]をクリックします。
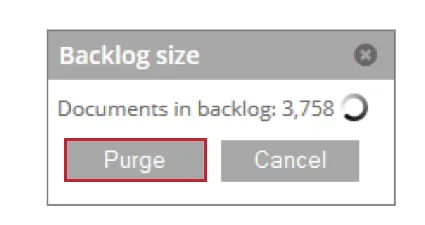
- 詳細:複製設定によりスキップされたドキュメントの詳細を表示します。
- Stop:データローダーによるデータ処理を停止する。
{kind=link}
{kind=link}
{kind=link}
プロジェクトデータの削除
プロジェクトのデータを削除することができます。これには、逐語訳や構造化された属性値が含まれる。プロジェクトデータを削除する場合、特定のセッション中にアップロードされたすべてのデータを削除するか、プロジェクト内のすべてのデータを削除することができます。
Qtip:データの削除はデータのクリーニングとも呼ばれます。
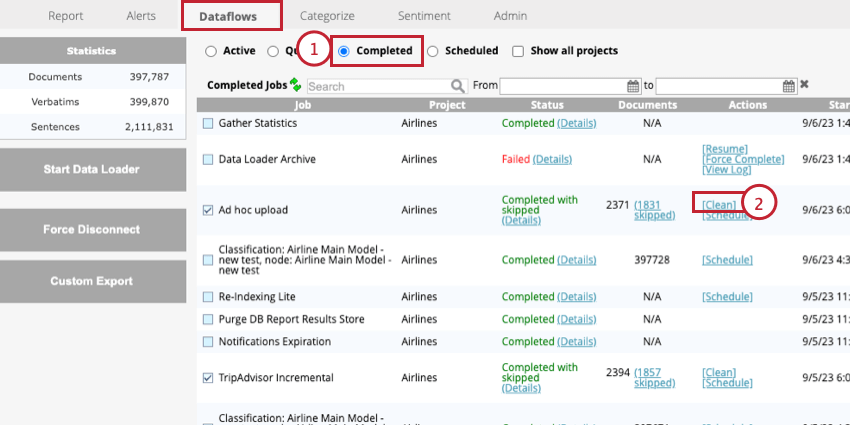{kind=link}
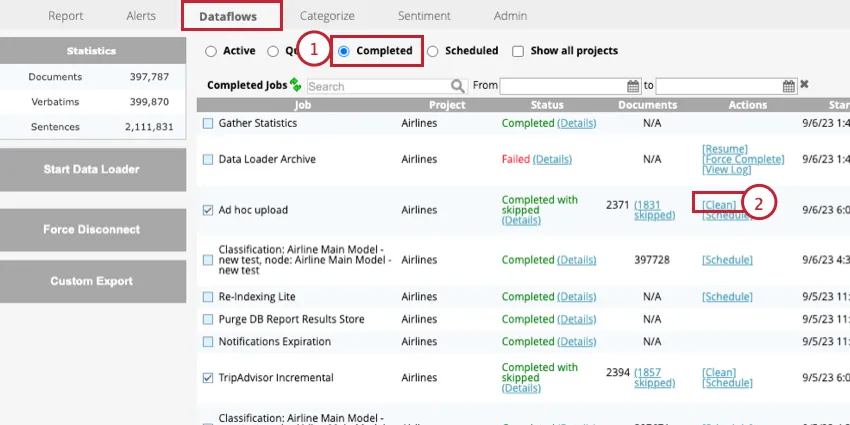
これにより、選択したアップロード中に追加されたすべてのデータが削除されます。
当サポートサイトの日本語のコンテンツは英語原文より機械翻訳されており、補助的な参照を目的としています。機械翻訳の精度は十分な注意を払っていますが、もし、英語・日本語翻訳が異なる場合は英語版が正となります。英語原文と機械翻訳の間に矛盾があっても、法的拘束力はありません。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!