属性 基本概要
このページの内容
属性について 基本概要
属性とは、文書を何らかの方法で特徴付ける性質である。属性の一般的な例としては、作者名や作成日などがあります。
プロジェクト用にカスタム属性を作成することができます。また、さまざまなシステム属性も用意されている。また、ドキュメントのテキストに基づいて属性を自動的に検出するインテリジェント・エンティティを設定することもできます(たとえば、顧客のフィードバックでブランドや製品が言及された場合など)。
属性を追加した後、さらに派生属性を作成してデータをさらに理解することが可能です。また、属性を属性セットに整理することで、これらの属性に関するレポートが容易になります。
属性フィールドタイプ
属性では以下のフィールドタイプがサポートされている:
- テキスト
- 数字
- 日付
属性へのアクセシビリティ
属性はプロジェクトレベルで管理される。プロジェクトの属性にアクセスする:
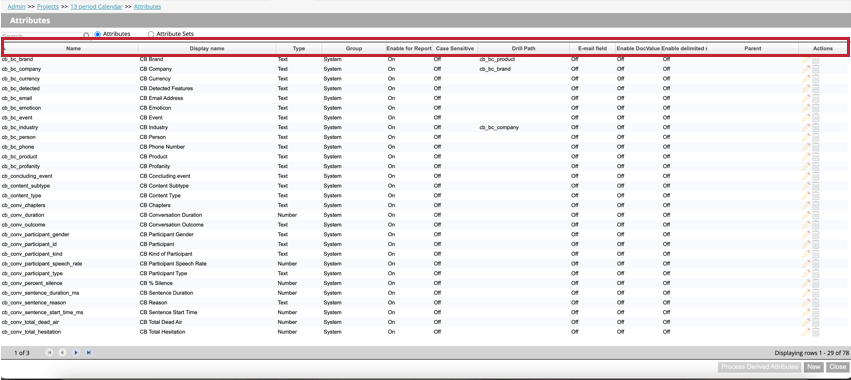
プロジェクトの各属性に関する以下の情報を含む属性テーブルが開きます:
{kind=link}

- 名前:属性のシステム名。命名要件については属性命名を参照のこと。
- 表示名:レポートやフィルターなどに表示される属性の表示名。命名要件については属性命名を参照のこと。
- タイプ:属性のタイプ。標準属性の場合、値はText、Number、Dateのいずれかになります。派生属性の場合、値は「Dimensional Lookup」、「Range Rollup」、「Satisfaction Score」、「Derived From Category」のいずれかになります。
- グループ:属性グループ:属性の起源と使用目的を表すグループ。値は以下のいずれか:
- カテゴリー由来:モデルまたはカテゴリーに由来する属性。
- システム:システム属性。
- 顧客定義:選択肢のデータソースから利用可能なすべてのカスタム属性(ディメンジョン・ルックアップ、レンジ・ロールアップ、満足度スコアを含む)。
- スコアカード:インテリジェントスコアリングに使用される属性。
- レポート用に有効にする:属性がレポート用に有効(オン)か無効(オフ)かをレポートする。
- 大文字と小文字を区別します:ドキュメントエクスプローラー、ソース強調表示、カスタムエクスポート、センテンスプレビューエクスポートで値を表示する際に、属性が大文字と小文字を区別するようにマークされているかどうかを表示します。
- ドリルパス:カスタムドリル経路が定義されている場合は、それが表示されます。カスタム・ドリル・パスがない場合、このフィールドは空白になります。
- E-mailフィールド:属性にメールアドレスが含まれているかどうかを表示します。
- DocValueを有効にする:この属性にElasticSearchのDOC値を使用するかどうかを示します。
- 区切り複数値を有効にする:この属性で複数の値が有効かどうかを示します。
- Parent: 属性が派生属性の場合、このフィールドは “parent” と表示されます。カスタム属性と標準属性の場合、このフィールドは空白になる。
- アクション属性に対して以下のパフォーマンスを実行する:
- 属性の編集
- 派生属性の作成
- 属性を削除する。
属性セットのマネージャー
属性セットを表示するには、ページの上部にある「属性セット」トグルを使用します。これにより、新しい属性セットを作成したり、既存の属性セットを削除したりすることができる。属性を選択すると、各自の属性が表示されます。
{kind=link}
システム属性
XM Discoverにアップロードされた各文書には、Document DateやSource IDなどのシステム属性が自動的に適用されます。これらの属性は、XM Discover内でフィードバックを管理するだけでなく、NLPエンジンによってdiscoverされたXMデータでフィードバックをリッチ化するのに役立ちます。
以下は、さまざまなシステム属性を、属性のカテゴリーごとに分類した表である。この表には、各属性に関する以下の情報が含まれている:
- 名前:属性名:レポートやフィルターなどに表示される属性名。
- システム名:属性のシステム名で、データのクエリーやフィルターに使用する。
- タイプ:属性タイプ。
- 説明:属性の意味と目的の簡単な説明。
- 粒度:属性に関連するデータの粒度のレベル。例えば、Sentence Word Countは文レベルのみに関連し、Document Dateは文書とその文書内の各文章の両方に関連する。
IDとリファレンス
| 名前 | システム名 | タイプ | 説明 | 粒度 |
|---|---|---|---|---|
| ドキュメントID | _id_document | 数値 | 文書に固有のシステムID。Natural IDとは異なり、Document IDはXM Discoverが自動的に生成します。 | 文書と文 |
| ナチュラルID | natural_id | text | ドキュメントの固有のナチュラルID。ドキュメントIDとは異なり、ナチュラルIDはドキュメントをアップロードする際に指定されたフィールドから生成されます。Natural IDは複製検出で使用され、XM Discoverの外部でドキュメントのソースをトレースする際にも役立ちます。 | 文書と文 |
| センテンスID | _id_sentence | 数値 | 文の固有ID。このIDは自動的に生成されます。  ; | センテンス |
| セッションID | _id_batch | 数値 | ドキュメントがXM Discoverに読み込まれたアップロードセッションの一意のID。このIDは自動的に生成される。 | 文書と文 |
| ソースID | _id_source | text | データソースの名前。データソースによって、自動的に生成されるか、文書をアップロードするときに指定したフィールドから生成されるかのどちらかになります。 | 文書と文 |
| バーベイタムID | _id_verbatim | 数値 | 逐語訳の固有ID。このIDは自動的に生成される。 | 逐語と文 |
| バーベイタムタイプ | _verbatimtype | text | 逐語フィールド名。この属性により、データ内の異なる逐語フィールドで文章を区別することができます。 | 逐語と文 |
日時
| 名前 | システム名 | タイプ | 説明 | 粒度 |
|---|---|---|---|---|
| CB 作成日 | cb_date_created_utc | 日付、ミリ秒単位のエポックタイム | ドキュメントがXM Discoverに追加された日付。この日付は自動的に生成される。 | 文書と文 |
| CB更新日 | cb_date_updated | 日付、ミリ秒単位のエポックタイム | 文書の最終更新日。更新にはカテゴライズの変更は含まれない。この日付は自動的に生成される。 | ドキュメント |
| 書類日付 | _doc_time | 日付、ISO 8601、秒単位 | 文書の主な日付。レポート、トレンドレポート、アラートなどで使用されます。この日付は、文書をアップロードする際に指定したフィールドから生成されます。 | 文書と文 |
| ドキュメント 日付 時間なし | _doc_date | 日付、yyyy-mm-dd形式 | タイムスタンプを除いた文書の日付。 この日付は、文書をアップロードする際に指定したフィールドから生成されます。 | 文書と文 |
| タイミング | time_of_day | テキスト、hh:mm 形式 | 時間単位で表示される文書のタイミング。例えば、9:09と9:59に投稿されたコメントは、両方とも9:00にロールアップされます。この属性は自動的に生成される。 | 文書と文 |
単語数とポジション
| 名前 | システム名 | タイプ | 説明 | 粒度 |
|---|---|---|---|---|
| CB文書の単語数 | cb_document_word_count | 数値 | 文書内の単語数。文書の単語数は、すべての文の単語数の合計である。  ; | 文書と文 |
| CBセンテンス四分位数 | cb_sentence_quartile | 数値 | 文が逐語的に入る部分。この属性は以下の値のいずれかを持つ:1、2、3、4。各セクションは、逐語全体の長さの25%を表します。 | センテンス |
| CBセンテンスの単語数 | cb_sentence_word_count | 数値 | 文中の単語の数。 | センテンス |
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!