-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
感情(Discover)
感情について
感情は、XM Discoverのすべてのデータソースで提供されるエンリッチメントです。感情は、個々のコメントがどの程度肯定的か否定的かを測定する。感情化は文レベルで-5~5段階で計算され、3段階または5段階に細分化される:非常に否定的、否定的、中立、肯定的、非常に肯定的。
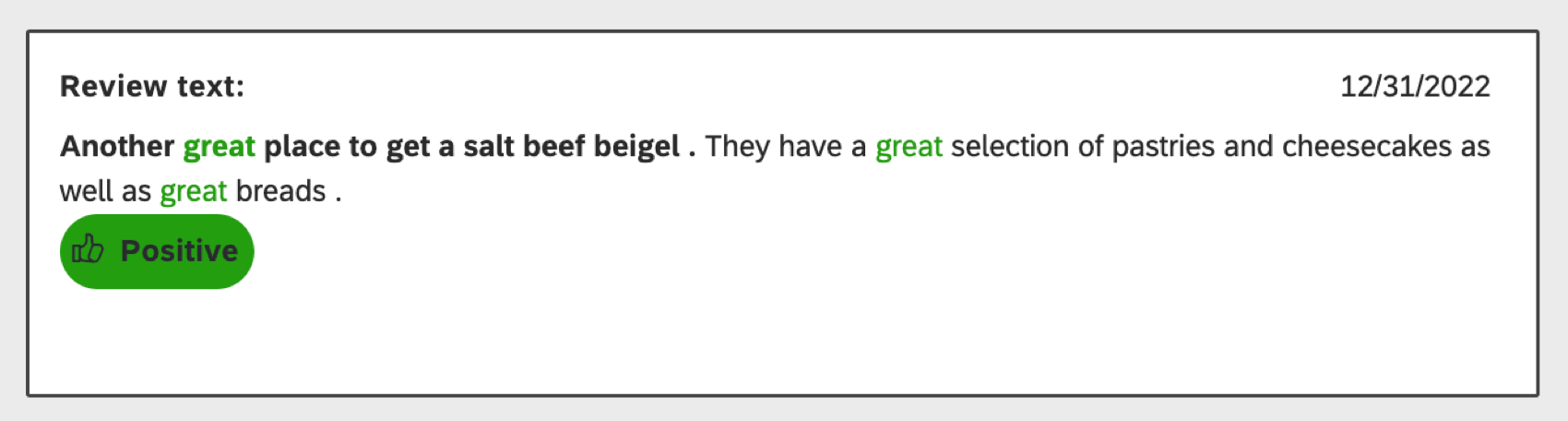
感情の計算方法
XM Discoverは、文章内の単語やフレーズのトーンに基づいて文章の感情を分析します。
- 言葉:Designerには、私たちのエクスペリエンスに基づき、肯定的または否定的なフラグが付けられた何千もの言葉が用意されています。デフォルトのチューニングを使用することも、チューニングによってデータに合うように調整することもできる。
- フレーズ:単語レベルのセンチメントに加えて、Designerはセンチメント修飾語や例外ルールも認識し、サポートされているすべての言語について、センチメントを変化させる最もよく知られた言語パターンをカバーします。デフォルトのルールを管理することも、カスタムルールを作成することもできます。
- 機械学習による感情:Discoverは機械学習を使用してテキストの肯定/否定を評価し、サポートされているすべての言語にわたって文章に感情ラベルを割り当てます。それが可能になれば、この種の感情はブランドのルールベースのアプローチに取って代わる。
感情修飾語
感情修飾語は、感情語の値に影響を与える追加語です。元の単語の感情値を増加させたり、減少させたり、反転させたりすることができる。この言葉はこうだ:
- 非常に:感情値が1増加し、スケールの極端な端に向かう。
例「The food was good」は感情スコア+2、「The food was very good」は感情スコア+3。あるいは、「食べ物がまずかった」の感情スコアは-2であるのに対し、「食べ物がとてもまずかった」の感情スコアは-3である。
- わずかに感情値を1減らし、スケールの中央へ。
例「サービスは良かった」の感情スコアは +2 であるのに対し、「サービスは少し良かった」の感情スコアは +1 です。あるいは、「サービスが悪かった」の感情スコアは-2であるのに対し、「サービスが少し悪かった」の感情スコアは-1である。
- Nothing:感情値を反転させる。
例「私のエクスペリエンスについて悪いことは何もなかった」の感情スコアは +2(「悪い」は通常 -2 であるため)、「良いことは何もない」の感情スコアは -2(「良い」は通常 +2 であるため)。
感情尺度
ウィジェットに感情を追加する場合、多くの場合、3ポイントと5ポイントの尺度を選択できます。3尺度にはネガティブ、ニュートラル、ポジティブしかない。
| 細分化 | デフォルト範囲 | デフォルトカラー |
| 強く否定的 | gt;-2.5未満 | ダークレッド |
| ネガティブ | gt;-2.5と-1の間 | 赤 |
| ニュートラル | から1の間 | グレー |
| ポジティブ | 1~2.5の間 | グリーン |
| 強ポジティブ | 2.5以上 | 深緑色 |
感情計算の例文
このセクションでは、文の感情がどのように計算されるかの例をいくつか示します。文全体の感情は、文中の各感情語の個々の感情スコアの関数です。
感情 単語
文に 1 つの感情単語が含まれる場合、文の感情は単語の感情と等しくなります。
複数の感情語
文に複数の感情語が含まれる場合、文全体の感情は次のように計算されます:
- 文中の感情値が最も高い単語が特定される。これは文感情のベースとして使用される。
- 次に、同じ感情を持つ単語が1つ増えるごとに0.5ポイントが加算される。
- 次に、感情が 1 レベル下がるごとに 0.25 ポイントが加算される。
- 各次の感情レベル (n-1) では、システムは (n) の 1 つ上のレベルからポイントを取り、それらを 2 で区切り、感情 n-1 を持つ単語の数を掛けます。
Qtip:唯一の例外は、感情レベル 0.25 の単語 (+1 または -1 の値を持つ複数の減少修飾語) は感情レベル 0.5 と同じように扱われることです。
例The room wasclean, veryspacious,nicelydecorated, andinexpensive. これらの単語とそのスコアリングは以下の通りである:
- クリーン+3
- 広々としている:+3
- 素晴らしい:+2
- 安い:+1
上記の計算を用いると、文の感情は次のように計算される:3 + 0.5 + 0.25 + 0.125 =3.875.
否定的感情への対応
負の感情値は、(負の数を加算しているため)減算されることを除けば、まったく同じように扱われる。
感情データの活用
感情はXM DISCOVER全体で使用することができ、有益なダッシュボードを構築することができます。関係者に感情を表示し、データをフィルタリングし、組織のニーズに合わせて独自のカスタム感情メトリクスを構築することもできます。
テキスト分析と組み合わせることで、感情分析は多くの点で有益になります:
- 顧客からのフィードバックに優先順位をつけ、大量のフィードバックを一貫して正確に処理する。
- 貴社の製品やサービスから、所在地、広告、競合他社に至るまで、あらゆるものに対する顧客の意見をDiscoverしましょう。
- 顧客があなたやあなたのブランドを好きなもの、嫌いなものを理解する。
- ソーシャルメディア、ウェブサイト、コールセンターの担当者など、ビジネスに役立つ情報を含むあらゆるソースから、顧客の感情的フィードバックを分析する。
- ビジネスのあらゆる側面に対する世論の変化を常に把握する。
- 感情スコアのピークや谷から、製品の改善、営業担当者やカスタマーケア担当者のトレーニング、新しいマーケティングキャンペーンの作成が必要な箇所を特定します。
感情の図表化
感情の図表リングは、センチメントスコアがプロジェクト内の実際の単語やセンテンスにどのように適用されるかを把握するのに役立ちます。
感情の強調表示は以下の情報を強調する:
- 感情を表す言葉
- 感情例外ルール
- 感情修飾語
- 文章全体の感情
感情を表す言葉
感情計算は、感情を含む単語のシードリストに基づいている。
すべての単語は、-5 (最も否定的な感情) から +5 (最も肯定的な感情) までの感情スコアを持つことができます。感情スコアの範囲は5つの感情バンドに分類される。中立でない単語は、感情バンドに従って色付けされる:

- 深紅:非常にネガティブ
- 淡い赤:陰性
- 淡い緑色:陽性
- 深い緑:ネガティブ
感情例外ルール
感情例外ルールは、言葉の背後にある意図された感情が標準と異なる慣用的な表現の感情計算を調整するために使用されます。例外ルールの一部である単語には下線が引かれ、中心トークン (ルールによって感情スコアが修正される単語) はさらに斜体で表示されます。
次の例を考えてみよう:
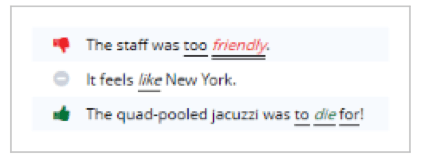
- “スタッフがフレンドリーすぎた”
- “ニューヨークって感じ”
- 「クワッドプールのジャグジーは最高だった。
これらは感情例外ルールによってフラグが立てられる:
- 「フレンドリー」はポジティブな言葉だが、ポジティブなものが多すぎるとネガティブな意味合いになる。
- 動詞としての “like “は肯定的だが、前置詞としての “like “は中立的である。
- “Die “は否定的な言葉だが、”to die for “というフレーズで使われる場合は違う。
感情修飾語
さらに、感情が否定された(感情が反対に反転した)、強まった(感情が中立からさらに遠ざかった)、弱まった(感情が中立になることなく中立に近づいた)単語には二重の下線が引かれている。例えば、次の文章を考えてみよう:

- 「このホテルには派手さはない。
“空想 “という言葉の感情(デフォルトではポジティブ)は、直前の “何もない “という言葉によってネガティブに変化する。
感情を表す単語が修飾語によって弱められ、結果的に中和されると、その単語はグレーのフォントで表示される。例えば、次の文章を考えてみよう:

- 「唯一の欠点は朝食がついていないことだった。
この場合、”downside”(デフォルトでは-1)の感情は、直前の修飾語 “only “によって中立(0)に変更される。
文章全体の感情
文の全体的な感情は、感情を表す単語、例外規則、感情修飾語をアカウントに含めます。文の感情は、感情バンドに従って色付けされた親指のアイコンで表されます。デフォルトでは、これは個々の感情語と同じ配色です。
感情によるウィジェットデータのグループ化
スタジオでウィジェットを作成する際、感情別にデータをグループ化できます。 データを感情でグループ化する場合、Studio の文レベルとレコードレベルの感情の以下の違いに注意することが重要です:
- 各文には 1 つの感情スコアしかありませんが、文書には文の数だけ感情スコアがあります。
- つまり、1つの文書に1つの肯定的な文章と1つの否定的な文章が含まれていれば、それは肯定的な文書と否定的な文書の両方とみなされる。
- このため、データを感情別にグループ化した場合、総カウント数は各帯域の全レコードの合計よりも少なくなるのが普通である。下のウィジェットをご覧ください。
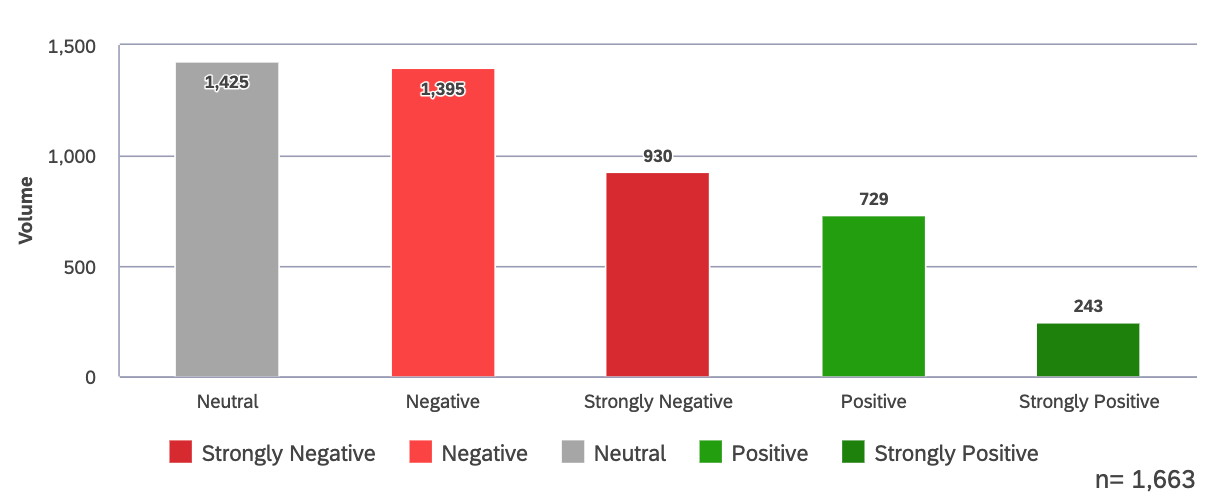
データが感情によってグループ化されると、ウィジェットの色は感情バンドに設定されたデフォルトと一致します。データのグループ化に別のフィールドが使用されている場合、色がこれらの設定と一致しないことがあります。
機械学習ベースの感情
機械学習ベースの感情は、「非常に否定的」から「非常に肯定的」までのラベルを文章に割り当てます。
- 名前感情
- システム名XM_sentiment
- タイプ数値
- スケール:-2~2
Qtip:センテンスに感情を表す単語が含まれていない場合、”N/A” という値が与えられます。データポイント内の他のすべてのセンテンスも「N/A」である場合、ウィジェットで感情によってカラーリングされるとき、感情は「Neutral」とラベル付けされます。
- 粒度: センテンス
- フィードバックの種類すべて
- 対応言語すべて
ルールベースの感情
Designerの感情属性に関する情報はこちら:
- 名称 CB度感情指数
- システム名 度数指標
- タイプ 数値
- スケール:- 5~5
- 粒度: センテンス
- フィードバックの種類すべて
- 対応言語 Discoverアカウント担当者にご相談ください。