-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
表現の構築
ビルディング・エクスプレッションズについて
XM Discoverでは、データのフィルタリングやデータフィールドの変換に式を使用します。たとえば、式を使用して日付フィールドの書式を変更したり、空のレコードのデータを評価したり、数学的計算を実行したりすることができます。
式は4つの要素を含むことができる:
定数
定数とは、数値、文字列、日付のことで、演算機能や比較に使用することができます。たとえば、年次CXアンケートを開始した日など、一定の日付を使用して、アンケート回答者の回答が何歳であるかを計算することができます。
定数の使用に関する注意事項
- 文字列は大文字と小文字を区別して扱われる。大文字と小文字の区別の回避策として、UPPER関数またはLOWER関数を使用する。
- 文字列と日付は引用符で囲んでください。
- 数字に引用符は必要ない(引用符の中の数字はテキストとして扱われる)。
フィールド
フィールドは、受信データ・コネクタから利用可能なデータ・フィールドです。これには数値フィールド、文字列フィールド、日付フィールドがあり、これらを使って演算機能や比較を行うことができる。例えば、データセットに顧客の誕生日フィールドがあれば、その顧客の年齢を計算することができます。
フィールドを追加するには、フィールドセクションから式ボックスにドラッグします。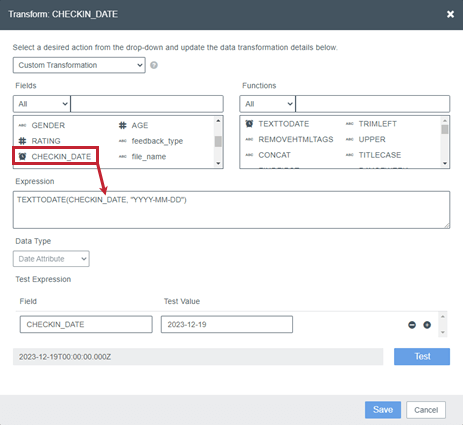
フィールドタイプには以下のアイコンが表示される:
 日付フィールド用
日付フィールド用 数値フィールドの場合
数値フィールドの場合 テキストおよび逐語フィールド用
テキストおよび逐語フィールド用
機能
このセクションにリストされている数値、テキスト、日付関数を使用できます。
関数を追加するには、FunctionsセクションからExpressionボックスにドラッグします。
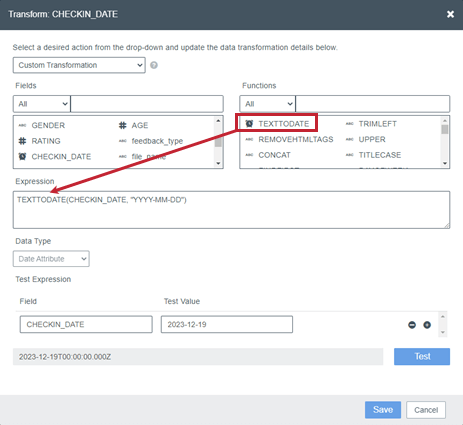
ファンクションタイプには以下のアイコンが付いている:
- 日付関数用
- 数値関数用
- テキスト関数用
ABS
絶対値関数は、数値の絶対値を返します。
構文ABS(数値)
コールセ
リスト内の NULL でない最初の値を返します。
構文COALESCE(value1, value2, value3)
天井
四捨五入した数値を返します。
構文CEILING(数値)
コンキャット
複数のテキスト文字列を1つに結合する。
構文CONCAT(“文字列1”, “文字列2”, “文字列3”)
含まれるもの
テキスト文字列(”within text”)が別のテキスト文字列(”find text”)を含む場合に真を返す。そうでなければ偽を返す。
構文CONTAINS(“テキスト内”, “テキストを見つける”)
タイムゾーンに変換
日付と時間をあるタイムゾーンから別のタイムゾーンに変換します。
構文:CONVERT_TO_TIMEZONE(“date and time”, “time zone to convert from”, “time zone to convert to”)
日付書式に関する注意事項:
- tzデータベース名を使ってタイムゾーンを指定する。
- 日時をISO 8601またはyyyy-mm-dd hh:mm:ssで入力してください。
- 日付と時刻がタイムゾーン情報とともに提供された場合、それは無視され、「変換元タイムゾーン」パラメータが優先される。
- 変換された日付はISO 8601形式を使用します。変更する必要がある場合は、TODATE関数を使用する。
データナンバー
日付フィールドをUnixタイムスタンプに変換します。
構文DATETONUMBER(“日付”)
データテキスト
日付フィールドを要求された形式の日付文字列に変換します。
構文DATETOTEXT(“日付”, “日付フォーマット”)
週日
日付に対応する曜日を返します。
構文DAYOFWEEK(“日付”)
ダイナミック・ルックアップ
動的に読み込まれるルックアップテーブルを使ってフィールドの値を置き換える。ルックアップ値は、第1引数(”フィールド名”)で指定されたフィールドから取得される。
構文DYNAMICLOOKUP(“フィールド名”, “値”)
エレメント・ファレイ
配列から n 番目の値を抽出し、配列の値を XM Discover の属性にマッピングします。
構文ELEMENTOFARRAY([“array element 1”, “array element 2”, “array element 3”], number)
注意:
- 入力が配列でない場合、この関数はエラーを投げる。
- 数値が配列のサイズより大きい場合、この関数はnullを返す。数字は0から始まる。
フィールド
スペースやドットを含むフィールド名を折り返す。
構文FIELD(“フィールド名”)
ファインド
あるテキスト文字列(”find text”)が別のテキスト文字列(”within text”)の中にあるかどうかを調べ、”within text “の最初の文字から “find text “の開始位置の番号を返す(1から始まる)。
検索を開始する「テキスト内」の文字の順番を指定できる(1から始まる)。order_numberを省略した場合、それは1とみなされる。
find text “が “within text “で見つからなければ-1を返す。
構文FIND(“テキストを検索”, “テキスト内”, order_number)
最前線
あるテキスト文字列(”find text”)が別のテキスト文字列(”within text”)内で最初に出現する位置を特定し、”within text “の最初の文字から “find text “の開始位置を(1から始まる)番号で返す。
構文FINDFIRST(“テキスト内”, “テキストを見つける”)
ファインドラスト
あるテキスト文字列(”find text”)が別のテキスト文字列(”within text”)内で最後に出現した位置を探し、”within text “の最初の文字から “find text “の開始位置の番号を返す(1から始まる)。
構文FINDLAST(“テキスト内”, “テキストを見つける”)
フロア
四捨五入した数値を返します。
構文FLOOR(数値)
GENERATE_ID
一意のIDを生成する。この関数は追加のパラメーターを必要としない。
構文GENERATE_ID()
日間
Double関数は、2つの日付間の日数を返します。
構文GETDAYSBETWEEN(“開始日”, “終了日”)
時間
Double関数は、2つの日付間の時間数を返します。
構文GETHOURSBETWEEN(“開始日”, “終了日”)
分
Minute関数は、2つの日付の間の分数を返します。
構文GETMINUTESBETWEEN(“開始日”, “終了日”)
条件
ステートメントが真の場合は1つの値を返し、ステートメントが偽の場合は別の値を返す。
構文IF(ステートメント, “真の場合の値”, “偽の場合の値”)
ISBLANK
フィールドが空のときに TRUE を、空でないときに FALSE を返す。
構文ISBLANK(“フィールド名”)
ジョイナレイ
項目の配列を、指定した区切り文字でひとつの文字列に結合する。
構文JOINARRAY(array, delimiter, escape, skipNull, removeDuplicates)
上記の構文では、以下のようになる:
- array: 結合する文字列あるいは数値の配列。
- delimiter: 配列を連結する際に使用する区切り文字。
- escape: trueの場合、引用符で囲まれた要素を保持する。
- skipNull: trueの場合、nullの要素をスキップします。
- removeDuplicated:trueの場合、複製要素を削除する。
レン
文字列中の文字数を返します。
構文LEN(“テキスト”)
構文LEN([“text1”, text2])
下
テキストを小文字に変換する。
構文LOWER(“テキスト”)
MD5HASH
入力データにMD5ハッシュを適用し、そのデータに基づいて一意のIDを生成する。
構文MD5HASH(“text”)
ミッド
テキスト文字列から指定した文字数を、指定した位置から返します。
ポジション(order_number)は1から始まる。
構文MID(“text”, order_number, characters_number)
MOD
index関数は、ある数値を区切り線で割ったときの余りを返します。
構文MOD(数, 除数)
今すぐ
現在の日付と時刻を返します。この関数は追加のパラメーターを必要としない。
構文NOW()
日付
Unixタイムスタンプを日付フィールドに変換します。Unixタイムスタンプは1970年1月1日からの経過ミリ秒数です。
構文NUMBERTODATE(数値)
NUMBERTOTEXT
数値をテキストに変換する。
構文NUMBERTOTEXT(数値)
捕虜
x の y 乗の結果を返します。
構文POW(x, y)
プロパーケース
テキスト文字列の最初の文字を大文字にする。
構文PROPERCASE(“テキスト”)
例PROPERCASE(“practice makes perfect”) は Practice makes perfect に解決される。
ランダム化機能
この関数は、追加のパラメータを必要としません。
構文RANDOM()
ランダム
RandomNumber関数は、2つの数値の間のランダムな整数値を返します。
構文RANDOMBETWEEN(最小数, 最大数)
REMOVEHTMLTAGS
テキスト文字列から HTML タグを削除します。
構文REMOVEHTMLTAGS(“text”)
リプレース
テキスト文字列の一部 (「古いテキスト」) を、”text” 内での “古いテキスト” の出現回数 (occurrence_number) に基づいて設定された回数 (number_of_replacements) 別のテキスト文字列 (「新しいテキスト」) に置き換える。
構文REPLACE(“text”, “old text”, “new text”, occurrence_number, case_sensitivity, number_of_replacements)
リプレイスインデックス
テキスト文字列の一部(「古いテキスト」)を、指定した文字数に基づいて別のテキスト文字列(「新しいテキスト」)に置き換える。
ポジション(order_number)は1から始まる。
構文REPLACE(“old text”, order_number, characters_number, “new text”)
replacebyregexp(リプレースバイレジェックスプ
正規表現を使ってテキスト値を置き換えます。
構文REPLACEBYREGEXP(“text”, “パターンマッチングの正規表現”, “置換値の正規表現”)
ラウンド
Number関数は、小数点以下を四捨五入した数値を返します。
構文ROUND(数値)
検索
あるテキスト文字列(”find text”)が別のテキスト文字列(”within text”)の中にあるかどうかを調べ、”within text “の最初の文字から “find text “の開始位置の番号を返す(1から始まる)。
検索を開始する「テキスト内」の文字の順番を指定できる(1から始まる)。order_numberを省略した場合、それは1とみなされる。
find text “が “within text “で見つからなければ-1を返す。
構文SEARCH(“テキストを検索”, “テキスト内”, order_number)
スプリット
指定した文字列を、指定した区切り文字に基づいて部分文字列の配列に分割する。この関数は、出力値が文字列でなければならないため、JOINARRAY関数やELEMENTOFARRAY関数のパラメータとして使用することができます。
構文SPLIT(“文字列_to_split”, “_”)
サブスティテュート
テキスト文字列の「古いテキスト」を「新しいテキスト」に置き換える。
どの「古いテキスト」を置き換えるかを指定できる。occurrence_number を指定すると、そのインスタンスの「古いテキスト」だけが置き換えられる。そうでなければ、テキスト中の “old text “はすべて “new text “に変更される。
構文SUBSTITUTE(“テキスト”, “古いテキスト”, “新しいテキスト”, occurrence_number)
サブストール
テキスト文字列の最初の文字から始まり、指定した文字数(1から始まる)までの部分を返します。
構文SUBSTR(“text”, order_number)
タイトルケース
テキスト文字列の各単語の最初の文字を大文字にする。
構文TITLECASE(“テキスト”)
テキスト日付
日付文字列を以下の形式の日付フィールドに変換します:YYYY-MM-DDThh:mm:ssZ。
構文TEXTTODATE(“日付”, “日付書式”)
TEXTTONUMBER
テキストを数値に変換します。
構文TEXTTONUMBER(テキスト)
トランスレート
受信データを翻訳する。
構文:TRANSLATE (“ソース言語コード”, “ターゲット言語コード”, “テキスト”)。
注釈
- この機能は、Google翻訳APIの認証情報を持つアカウントでのみ使用できます。
- サポートされている言語コードの完全なリストについては、Googleクラウド翻訳のドキュメントを参照してください。
トリムレフト
テキスト文字列の左端からスペースを削除する。
構文TRIMLEFT(“テキスト”)
トリムライト
テキスト文字列の右端からスペースを削除する。
構文TRIMRIGHT(“テキスト”)
上
テキストを大文字に変換する。
構文UPPER(“text”)
オペレーター
以下のリストにある算術演算子や比較演算子を使用することができます。
算術演算子
| 演算子 | 説明 |
| + | 追加 |
| – | 減算または否定 |
| * | 乗算 |
| / | 除算 |
例えば、以下の式は2つの数値の平均を返す。
(評価1 + 評価2) / 2
比較演算子
| 演算子 | 説明 |
| == | 等しい |
| ってね; | 次の数より大きい |
| ールド; | 次の数より小さい |
| >= | 次の数以上 |
| <= | 次の数以下 |
| != | 次と等しくない |
例えば、以下の式は、RATINGが3以下の場合は「悪い評価」を返し、RATINGが3以上の場合は「良い評価」を返す。
IF(RATING <= 3, “悪い評価”, “良い評価”)
論理演算子
IF関数やジョブフィルターを使用する際は、論理演算子を使用して複数の条件を指定します。
| 演算子 | 説明 |
| および | and “で区切られた条件がすべて真であれば、条件は真となる。 |
| インチ | 条件は、リストされた値のいずれかと一致する場合に真となる。
構文:in[“値1”, “値2”, “値3”]]。 Qtip:複数の “or “演算子の代わりにこれを使う。
|
| または | or “で区切られた条件のいずれかが真であれば、条件は真となる。 |
例えば、以下の式は、COUNTRYフィールドに指定された値のいずれかが含まれていれば、”Mediterranean “を返す。そうでなければ、”地中海以外 “を返す。
IF(LOWER(COUNTRY) in [“フランス”, “ポルトガル”, “イタリア”, “スペイン”, “ギリシャ”, “マルタ”, “キプロス”], “地中海”, “非地中海”)
構文のヒント
無効な表現を避けるために、以下のヒントに従ってください:
- 1つの式に複数の関数を組み合わせる場合は、開始括弧と終了括弧の数が一致していることを確認してください。
例IF(GETDAYSBETWEEN(feedback_date, response_date) > 3, “delayed”, “not delayed”).
- 式で使用される各関数について、必要な引数がすべて存在する必要がある。例えば、TODATE関数を正しく動作させるには、日付と日付書式の両方の引数が必要です。
- 関数や算術演算、比較演算でサポートされている正しいデータ型を使用するようにしてください。例えば、ABS関数を正しく動作させるには数値が必要であり、テキストや日付フィールドでは動作しない。
- 式の中にドット(”.”)がある場合は、FIELD関数と引用符(”シングル “または “ダブル”)で囲みます。例えば、”agentParticipants.0.agentLoginName “というフィールド名がある場合、これをどのように変換するかは以下のようになります:
IF(CONTAINS(LOWER(FIELD(“agentParticipants.0.agentLoginName”)), “bot”), “YES”, “NO”).