-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
XM Discover Link インバウンドコネクター
XM Discover Link Inbound Connectorについて
XM Discover Link Inbound Connectorを使用すると、フィールドマッピング、変換、フィルター、ジョブ監視など、Connectorsフレームワークが提供するすべての機能を活用しながら、REST APIエンドポイントを介してXMデータをXM Discoverにプッシュできます。
対応データ形式
以下のデータタイプは、JSONフォーマットでのみサポートされています:
コネクタを設定する前に、XM Discoverにインポートするフィールドを表すサンプルファイルを作成します。必須項目とファイル形式の詳細については、上記のリンク先のページをご覧ください。
また、特定のデータ形式用のテンプレートファイルもコネクタ内でダウンロード可能です:
- チャット
- チャット(デフォルト):標準的なデジタル対話データに使用する。
- Amazon Connect:Amazon Connectチャットに特化したデジタルインタラクションに使用します。
- 電話
- Call(デフォルト):標準的な通話記録データに使用する。
- ベリントVerint固有の通話記録に使用します。
- フィードバック
- Dynamics 365:Microsoft Dynamicsのデータに使用します。
XM Discover Link Inbound Connectorジョブの作成
- ジョブ]タブで[新規ジョブ]をクリックします。
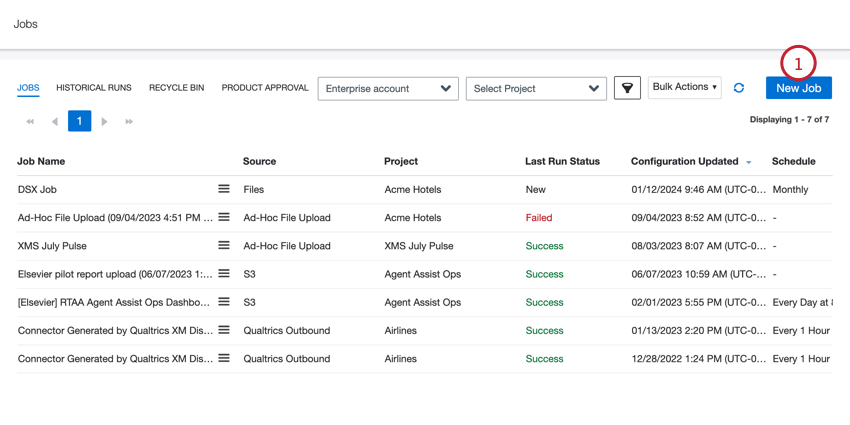
- XM Discover Linkジョブをクリックします。

- 自分の仕事に名前をつけて、ITと識別できるようにする。
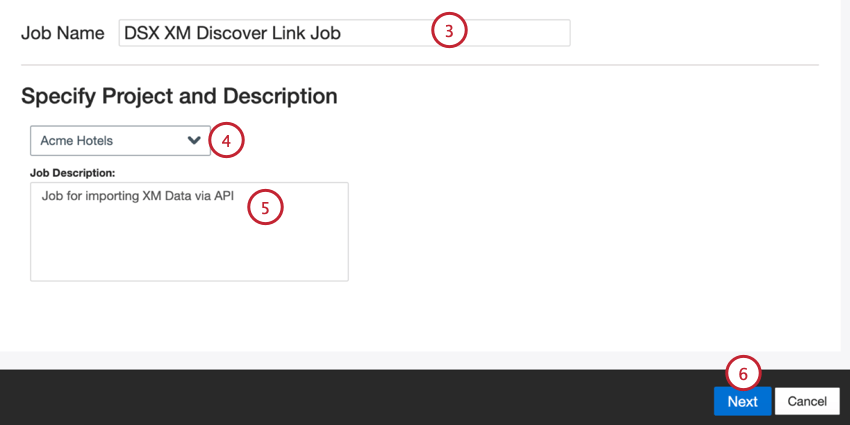
- データをロードするプロジェクトを選択します。
- 自分の仕事を説明し、その目的がわかるようにする。
- [次へ]をクリックします。
- 認証モード、またはXM Discoverへの接続方法を選択します:
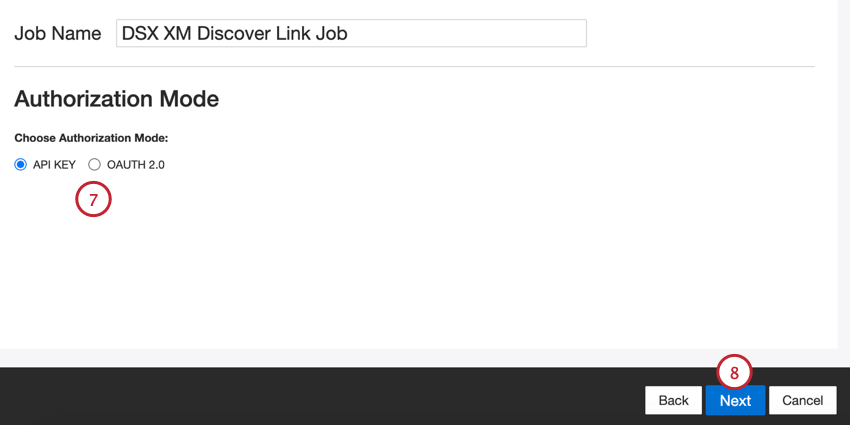
- APIキー:XM Discover API トークンを使用して接続します。
- OAuth 2.0:XM Discover認証サービスから提供されるクライアントIDとクライアントシークレットを使用して接続します。この方法をご希望の場合は、カスタマーサクセスマネージャーにご連絡ください。
- [次へ]をクリックします。
- データ形式をお選びください:チャット(デジタル)、コール、フィードバック。
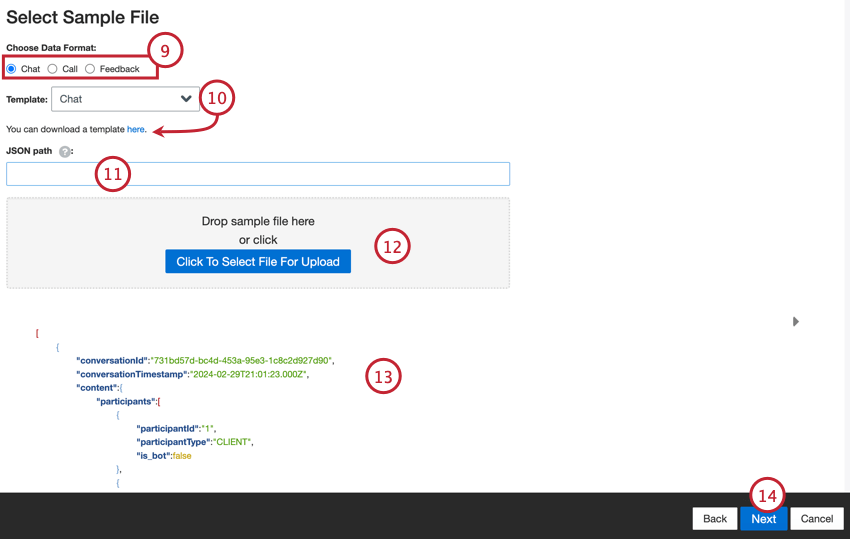
- 必要であれば、テンプレートを選択し、こちらのリンクをクリックしてテンプレートファイルをダウンロードしてください。
- ドキュメント・ノードを含むJSONのサブセットへのJSONパスを入力します。ドキュメントがルートノードレベルにある場合、このフィールドは空白にしてください。
- Click To Select File For Upload」ボタンをクリックし、コンピューター上のサンプルファイルを選択します。
- ファイルのプレビューが表示されます。プレビューではなく、エラーメッセージや未加工データの内容が表示される場合は、選択したデータ形式オプションに問題がある可能性があります。ファイルのトラブルシューティングについては、サンプルファイルエラーを参照してください。
- [次へ]をクリックします。
- 必要であれば、データマッピングを調整する。XM Discoverのフィールドマッピングの詳細については、データマッピングのサポートページを参照してください。デフォルト・データ・マッピング」には、このコネクタに固有のガイダンスが記載されています。
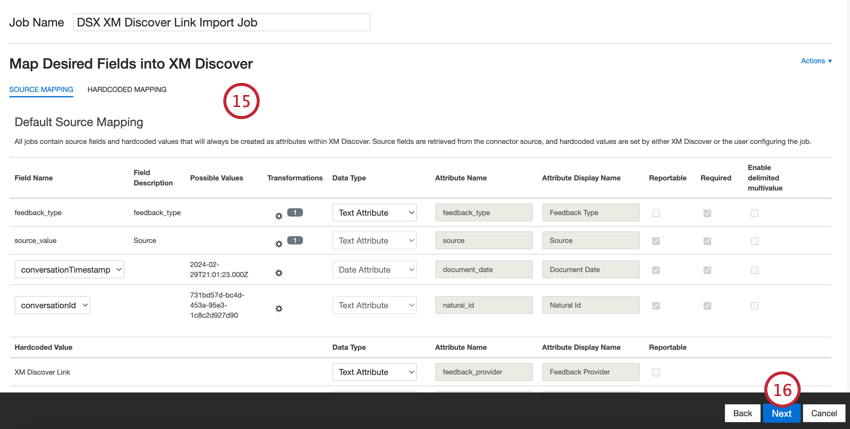
- [次へ]をクリックします。
- 必要であれば、データの置換や再編集ルールを追加して、機密データを隠したり、顧客フィードバックやインタラクションの特定の語句を自動的に置き換えたりすることができます。詳しくは、データ置換と再編集のサポートページをご覧ください。
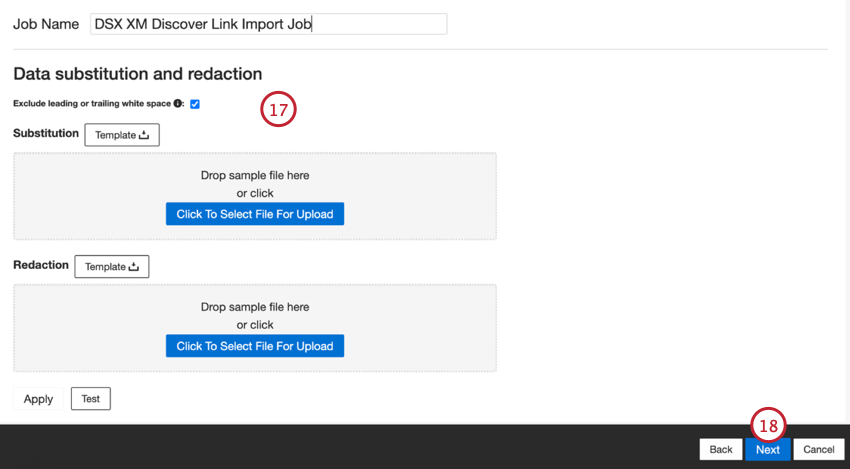
- [次へ]をクリックします。
- 必要であれば、コネクタ・フィルタを追加して受信データをフィルタリングし、インポートするデータを制限できます。
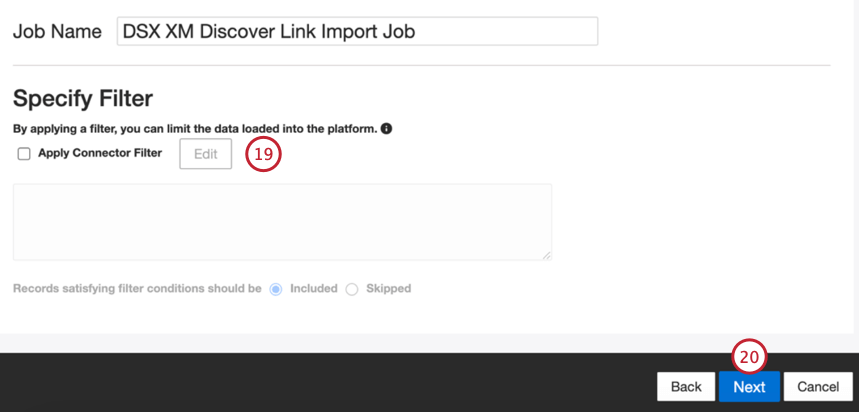
- [次へ]をクリックします。
- 複製文書の処理方法を選択します。詳しくは複製処理を参照。
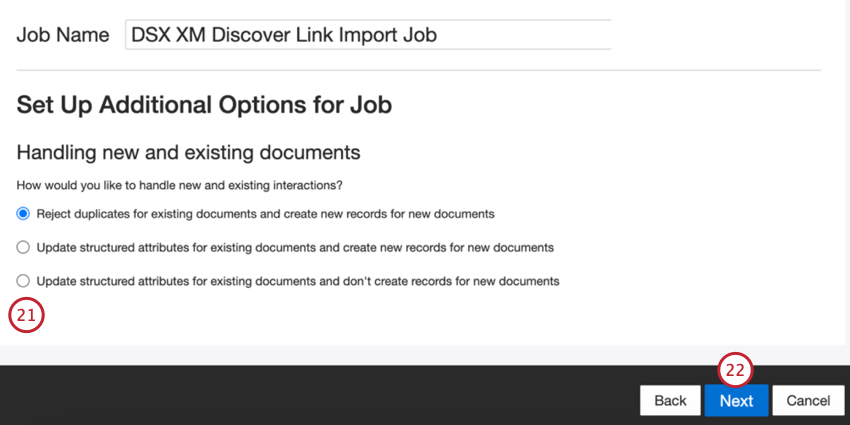
- [次へ]をクリックします。
- セットアップを評価する。特定の設定を変更する必要がある場合は、[Edit]ボタンをクリックして、コネクタ設定のそのステップに移動します。
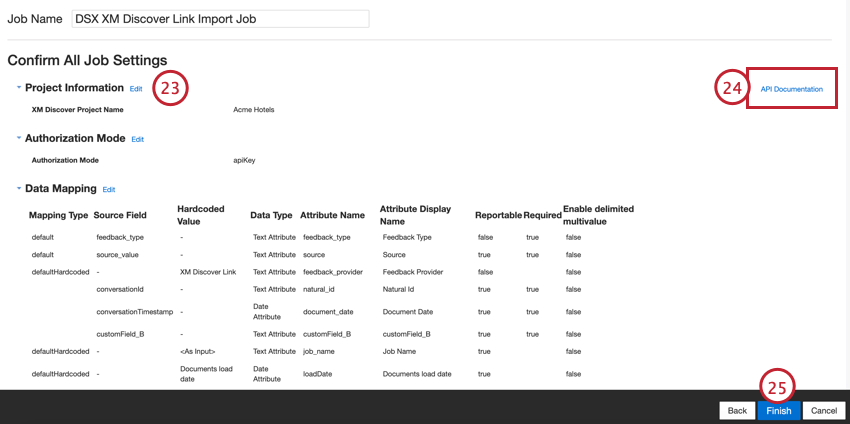
- API Documentationリンクには、XM Discoverへのデータ送信に使用するAPIエンドポイントが含まれています。詳細については、APIエンドポイントへのアクセスを参照してください。
- Finishを クリックして設定を保存します。
デフォルトのデータマッピング
このセクションでは、XM Discover Inbound Linkジョブのデフォルト・フィールドについて説明します。
フィールドをマッピングする際、以下のデフォルトフィールドが利用可能です:
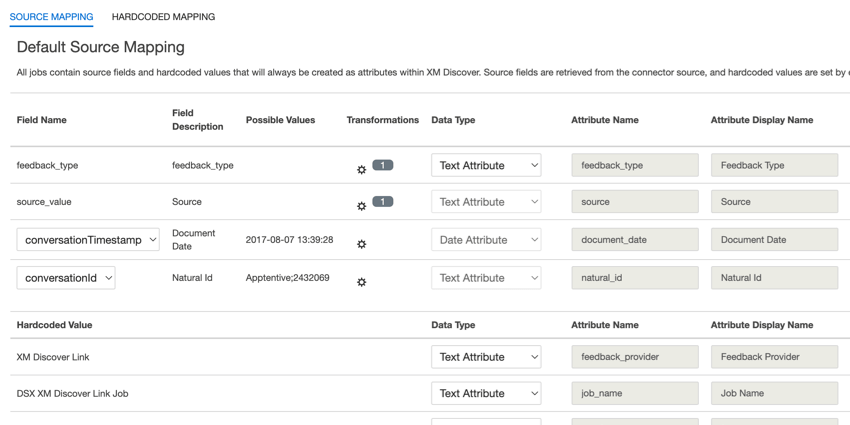
- feedback_type:フィードバック・タイプは、データの種類に基づいてデータを識別するのに役立ちます。これは、プロジェクトに異なるタイプのデータ(例えば、アンケート調査とソーシャルメディアフィードバック)が含まれている場合のレポートに便利です。このフィールドは編集可能である。デフォルトでは、この属性の値は次のように設定されている:
- 「通話記録のための「通話
- 「デジタル交流のための「チャット
- 「個別フィードバックのための「フィードバック
- カスタム変換を使ってカスタム値を設定することができます。
- ソース:ソース:特定のソースから取得したデータを識別するのに役立ちます。これは、アンケート調査やモバイルマーケティングキャンペーンの名前など、データの出所を示すものであれば何でもかまいません。このフィールドは編集可能である。デフォルトでは、この属性の値は “XM Discover Link “に設定されています。カスタム変換を使ってカスタム値を設定することができます。
- richVerbatim:このフィールドは会話データ(通話やチャットのトランスクリプトなど)に使用され、編集はできません。XM Discoverでは、richVerbatimフィールドに会話形式の逐語訳を使用しています。このフォーマットは、会話の図表(話し手の交代、沈黙、会話イベントなど)やエンリッチメント(開始時間、継続時間など)を解除するために必要な、ダイアログ固有のメタデータの取り込みをサポートします。この逐語フィールドには、クライアント側と代理人側の会話を追跡するための「子」フィールドが含まれる:
- clientVerbatimは、クライアント側の会話を追跡します。
- agentVerbatimは、代表者(エージェント)側の会話を追跡します。
- unknownは会話の未知の側面を追跡する。
-
Qtip:変換は会話逐語フィールドではサポートされていません。異なるタイプの会話データに同じ逐語を使うことはできない。プロジェクトで複数のタイプの会話をホストしたい場合は、会話のタイプごとに会話文のペアを分けてください。
- clientVerbatim:このフィールドは会話データに使用され、編集可能である。このフィールドは、通話やチャットでのクライアント側の会話をトラッキングします。デフォルトでは、このフィールドは
- clientVerbatimChatでデジタル交流。
- clientVerbatimCall通話インタラクション用。
- エージェントバーベイタム:このフィールドは会話データに使用され、編集可能である。このフィールドは、通話やチャットにおける担当者側の会話をトラッキングします。デフォルトでは、このフィールドは
- agentVerbatimChatでデジタル交流。
- agentVerbatimCallはコールインタラクションのためのものです。
- unknown:このフィールドは会話データに使用され、編集可能である。このフィールドは、通話やチャットでの会話の不明な並列を追跡します。デフォルトでは、このフィールドは次のようにマップされます:
- デジタル交流のためのunknownVerbatimChat。
- unknownVerbatimCallはコールインタラクション用。
- document_date: 文書の日付は、文書に関連付けられた主要な日付フィールドです。この日付はXM Discoverのレポート、トレンド、アラートなどで使用されます。文書の日付は、以下のオプションのいずれかを選択します:
- conversationTimestamp(会話データ用):会話全体の日時。
- データソースに他の日付フィールドが含まれている場合は、フィールド名のドロップダウンメニューから選択することで、それらのフィールドのいずれかを文書の日付として設定することができます。
- カスタムフィールドを追加することで、特定の日付を設定することもできます。
- natural_id:自然IDは文書の一意な識別子として機能し、複製を正しく処理することができます。ナチュラルIDについては、以下のオプションのいずれかを選択する:
- conversationId(会話データ用):会話全体の一意なID。
- データから任意のテキストまたは数値フィールドをフィールド名で選択します。
- カスタムフィールドを追加してIDを自動生成。
- フィードバックプロバイダー:フィードバックプロバイダは、特定のプロバイダから取得したデータを識別するのに役立ちます。XM Discover Linkアップロードの場合、この属性の値は「XM Discover Link」に設定され、編集することはできません。
- job_name: ジョブ名は、データをアップロードするために使用されたジョブの名前に基づいてデータを識別するのに役立ちます。この属性の値は、ページ上部のジョブ名ボックスまたはジョブオプションメニューで変更できます。
- ロード日付:ロード日付は、ドキュメントがXM Discoverにアップロードされた日付を示します。このフィールドは自動的に設定され、編集することはできません。
上記のフィールドに加えて、インポートしたいカスタムフィールドをマッピングすることもできます。カスタムフィールドの詳細については、データマッピングのサポートページを参照してください。
APIエンドポイントへのアクセス
APIエンドポイントは、JSON形式のREST APIリクエストでデータを送信することにより、XM Discoverにデータをアップロードするために使用されます。
ジョブページからエンドポイントにアクセスできます:
- ジョブオプションメニューでSummaryを選択します。
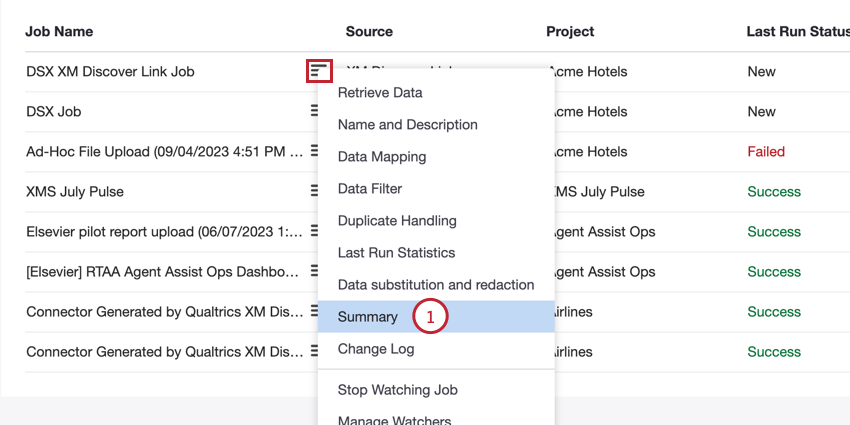
- API Documentationリンクをクリックします。

- 印刷ボタンをクリックすると、このウィンドウのすべての情報が印刷可能なPDFとしてダウンロードされます。
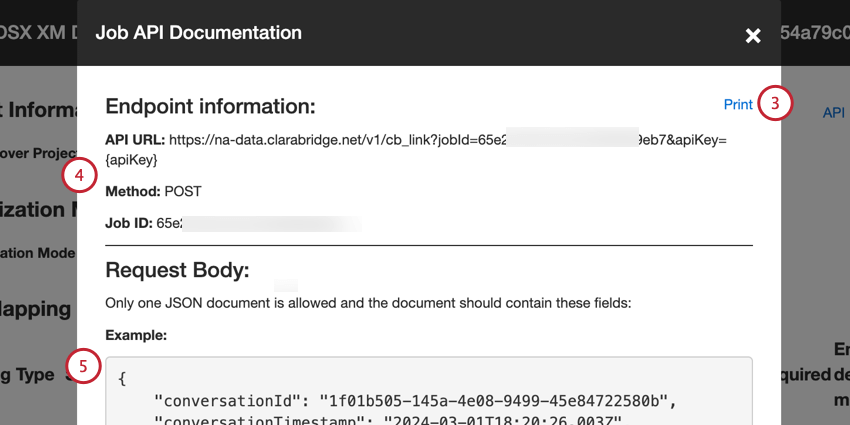
- エンドポイント情報には以下が含まれます:
- API URL:API リクエストに使用される URL。
- メソッドを使用します:XM Discoverにデータをロードするには、POSTメソッドを使用します。
- ジョブID:現在選択されているジョブのID。
- JSONペイロードの例は、リクエストボディのセクションに含まれている。APIリクエストは1つのドキュメントのみを含み、ペイロード例のフィールドのみを含むべきである。
- 回答セクションには、APIリクエストの成功とエラーの回答がリストされます。
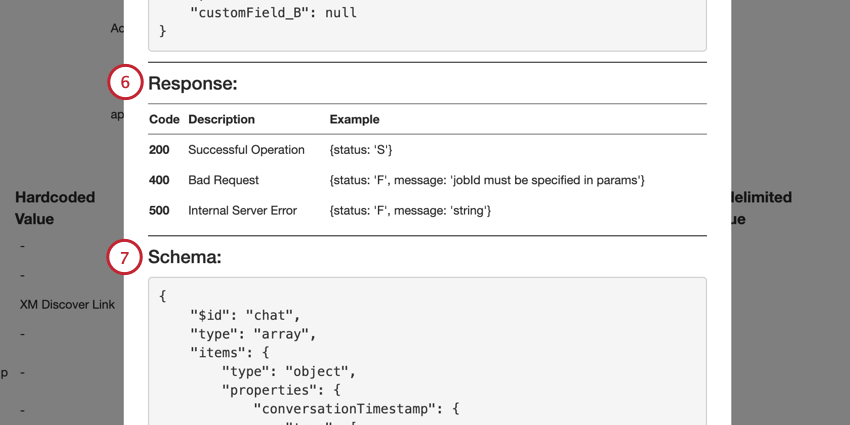
- Schemaセクションにはデータスキーマが表示されます。必須フィールドは必須配列の中にあります。
API 経由での XM Discover Link ジョブの監視
ステータスAPIエンドポイントを呼び出すことで、XM DiscoverにログインせずにXM Discover Linkジョブのステータスを監視できます。これにより、最新のジョブ実行ステータス、特定のジョブ実行のメトリクス、または特定の期間の累積メトリクスを取得できます。
ステータス・エンドポイント情報
ステータス・エンドポイントを呼び出すには、以下のものが必要だ:
- API URL: https://na-data.clarabridge.net/v1/public/job/status/<jobID>?apiKey=<apiKey>
- <jobId> はモニターしたいXM Discover LinkジョブのIDです。
- <apiKey> はAPIトークンです。
- タイプREST HTTPを使用します。
- HTTPメソッド:データを取得するにはGETメソッドを使用します。
入力要素
以下のオプションの入力要素を使用して、ジョブに関する追加のメトリクスを取得できます:
- historicalRunId:特定のアップロードセッションのID。この要素が省略され、日付範囲が提供されない場合、APIコールは最新のジョブ実行ステータスを返します。この要素を省略し、日付範囲を指定すると、API 呼び出しは指定された期間の累積メトリッ クスを返します。
- 開始日:データを返す開始日を定義します。
- endDate:最後のアップロードに基づくデータを返す終了日を定義します。この要素が省略され、startDateが指定された場合、endDateは自動的に現在の日付に設定される。
出力要素
必要な入力要素が入力されていれば、以下の出力要素が返される:
- job_status:ジョブのステータス。
- job_failure_reason: ジョブに失敗した場合、失敗の理由。
- run_metrics:ジョブが処理したドキュメントに関する情報。以下の指標が含まれる:
- 正常に作成されたドキュメントの数:正常に作成されたドキュメントの数。
- 正常に更新されたドキュメントの数:正常に更新されたドキュメントの数。
- skipped_as_duplicates:複製としてスキップされたドキュメントの数。
- FILTERED_OUT:ソース固有のフィルターまたはコネクターフィルターのいずれかによってフィルタリングされたドキュメントの数。
- BAD_RECORD:クアルトリクスの会話フォーマットと一致しなかったデジタル対話の数。
- SKIPPED_NO_ACTION: 複製でないとしてスキップされた文書の数。
- failed_to_load:読み込みに失敗したドキュメントの数。
- TOTAL: このジョブの実行中に処理されたドキュメントの総数。
エラーメッセージ
ステータスAPIリクエストでは、以下のエラーメッセージが表示される可能性があります:
- 401 認証されていません:自分らしくいられること認証に失敗しました。別のAPIキーを使用してください。
- 404 見つかりません:指定されたIDのジョブが存在しません。別のジョブIDを使用してください。
サンプルリクエスト
以下は、ジョブのステータスを取得するリクエストの例で
ある:curl --location --request GET 'https://na-data.clarabridge.net/v1/public/job/status/62da736987c9788b830918e0?apiKey=02e7a0e26b592632dd50f623e974fff6'
サンプル回答
以下は失敗したジョブの回答サンプルで
ある:{
"job_status":"Failed",
"job_failure_reason":"{"problem":[{"requestId": "RQ-MOB-f339aa58-71b6-4a1d-a67c-12b8d3439321", "severity": "ERROR", "description": "Length limit of 900 characters for attribute supportexperienceresp has been exceeded, length is 1043"}], "status": "ERROR"}",
"run_metrics":{
"successfully_created":10,
"failed_to_load":1,
"total": 11
}
}.
ペイロードの例
このセクションには、サポートされる構造化データのタイプ (フィードバック、チャット、コール) ごとに、1 つの JSON ペイロード例が含まれています。
- フィードバック例のペイロードはこちらをクリックしてください。
curl --location --request POST 'https://na-data.clarabridge.net/v1/cb_link?apiKey=887fc11663c456f9f34844a8a8bdff64&jobId=5f4e583f9142ae48a1090a76' \
--header 'Content-Type: application/json'
--data-raw '{
"dataSource":"Standard JSON",
"Row_ID":"id43682",
"store_number":"226,1,1,0,0",
"address":「5916 W Loop 289 Lubbock, TX 79424",
"phone_number":"806-791-4384",
"reviewer_name":"Mariposa",
"review_rating":2,
"Review_Date":"03.03.2019",
"Employee_Knowledge": 2,
"Price_value": 3,
"Checkout_process":1,
"comments":"久しぶりにベストバイで最高のエクスペリエンスでした。これからも頑張ってください。",
"LTR":10,
"state":"TX",
"Rewards_Member":"MyBestBuy"
}'.
- チャットのペイロード例を見るには、ここをクリックしてください。
curl --location --request POST 'https://na-data.clarabridge.net/v1/cb_link?apiKey=887fc11663c456f9f34844a8a8bdff64&jobId=5f4d77656afa99b0396ef959' ˶
--header 'Content-Type: application/json' ˶
--data-raw '{
"conversationId":"37854",
"conversationTimestamp":"2020-07-30T12:42:15.000Z",
"content":{
"contentType":"CHAT",
"participants":[
{
"participantId":"1",
"participantType":"AGENT",
"is_bot": true
},
{
"participantId":"2",
"participantType":"CLIENT",
"is_bot": false
}
],
"conversationContent":[
{
"participantId":"1",
"text":"Hello, how may I help you?",
"timestamp":"2020-07-30T12:42:15.000Z",
"id":"3785201"
},
{
"participantId":"2",
"text":"Hi, are you open today?",
"timestamp":"2020-07-30T12:42:15.000Z",
"id":"3785202"
},
{
"participantId":"1",
"text":"We are open from 17:00 till 23:00.",
"timestamp":"2020-07-30T12:42:15.000Z",
"id":"3785203"
},
{
"participantId":"2",
"text":"I would like to make a reservation.",
"timestamp":"2020-07-30T12:42:15.000Z",
"id":"3785204"
},
{
"participantId":"1",
"text":"Absolutely!どんな名前を使えばいいですか?",
"timestamp":"2020-07-30T12:42:15.000Z",
"id":"3785205"
}
]
},
"city":"Boston",
"source":"Facebook"
}'.
- ペイロードの例を見るには、ここをクリックしてください。
curl --location --request POST 'https://na-data.clarabridge.net/v1/cb_link?apiKey=887fc11663c456f9f34844a8a8bdff64&jobId=5f4e564d9242ae6e6308ff04' ˶
--header 'Content-Type: application/json' ˶
--data-raw '{
"conversationId":"462896",
"conversationTimestamp":"2020-07-30T10:15:45.000Z",
"content":{
"contentType":"CALL",
"participants":[
{
"participant_id":"1",
"type":"AGENT",
"is_ivr": false
},
{
"participant_id":"2",
"type":"CLIENT",
"is_ivr": false
}
],
"conversationContent":[
{
"participant_id":"1",
"text":"This is Emily, how may I help you?",
"start": 22000,
"end":32000
},
{
"participant_id":"2",
"text":"Hi, I have a couple of questions.",
"start":32000,
"end":42000
}
],
"contentSegmentType":"TURN"
},
"city":"Boston",
"source":"Call Center"
}'.