CFPBインバウンド・コネクター
スイート
Customer Experience
製品
Qualtrics
このページの内容
CFPB Inbound Connectorについて
消費者金融保護局(CFPB)インバウンドコネクターを使用して、CFPBからの苦情をXM Discoverにロードすることができます。
Qtip:CFPBのデータに関する詳細は、CFPBの文書を参照してください。
CFPBインバウンド・コネクタ・ジョブの設定
Qtip:この機能を使用するには、”ジョブのマネージャー “権限が必要です。
求人情報ページで、 新規求人をクリックします。
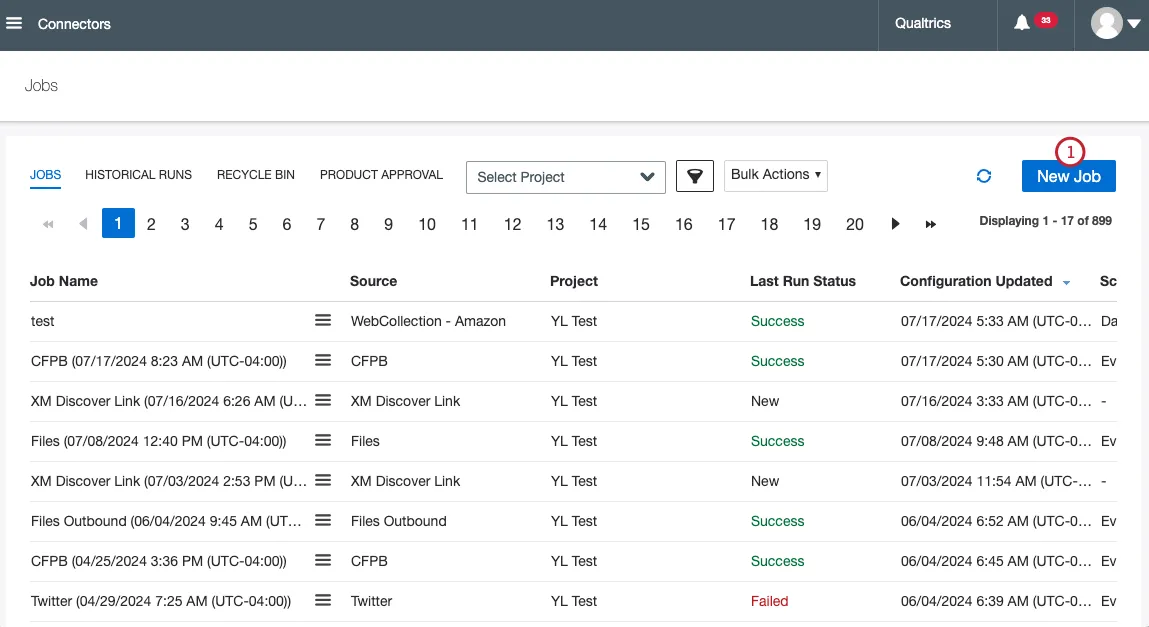
CFPBを選択。


自分の仕事に名前をつけて、ITと識別できるようにする。
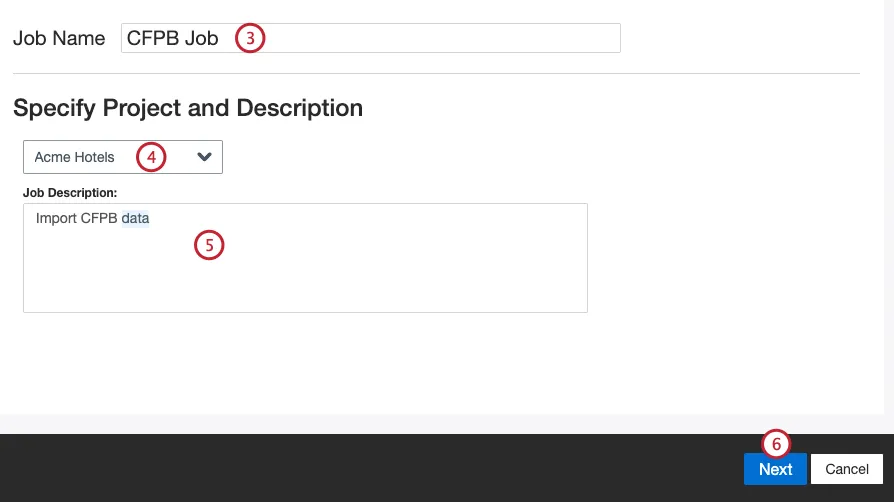
データをロードするプロジェクトを選択します。
自分の仕事を説明し、その目的がわかるようにする。
[次へ]をクリックします。
必要であれば、CFPBデータのフィルタを構築する。ドロップダウンを使ってフィルター条件を選択します。可能なオプションは以下の通り:
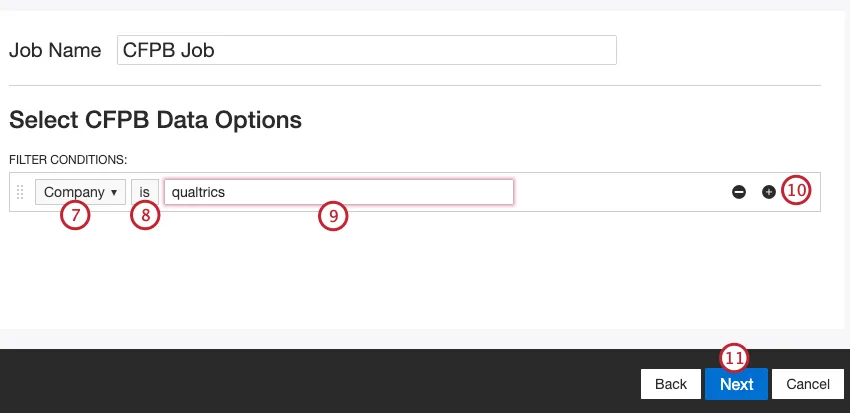
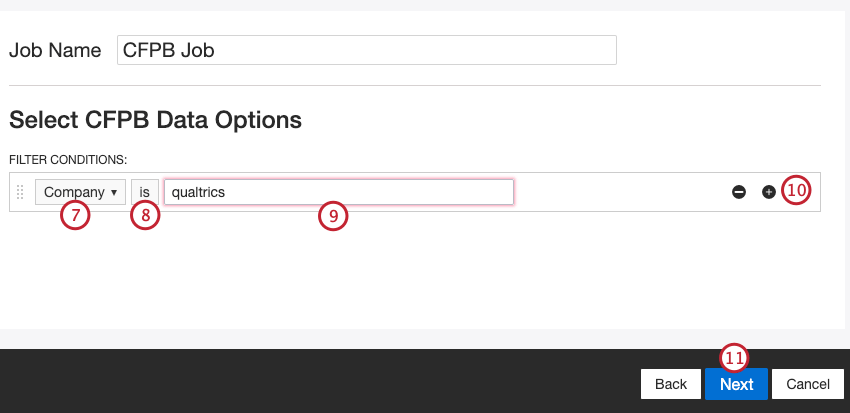
- 製品製品名で検索します。
- 会社会社名で検索
- 苦情の逐語訳があります:フィードバックの有無で検索できます。
フィルター演算子を選択します。
Qtip:デフォルトは “is “ですが、逐語的な文句で検索する場合は “is not “を選択できます。
テキストボックスに値を入力する。
条件を追加または削除するには、右側のプラスとマイナスのボタンを使用します。フィルター条件は3つまで追加できます。
Qtip:ジョブ作成後にソースフィルターを更新することができます。
[次へ]をクリックします。
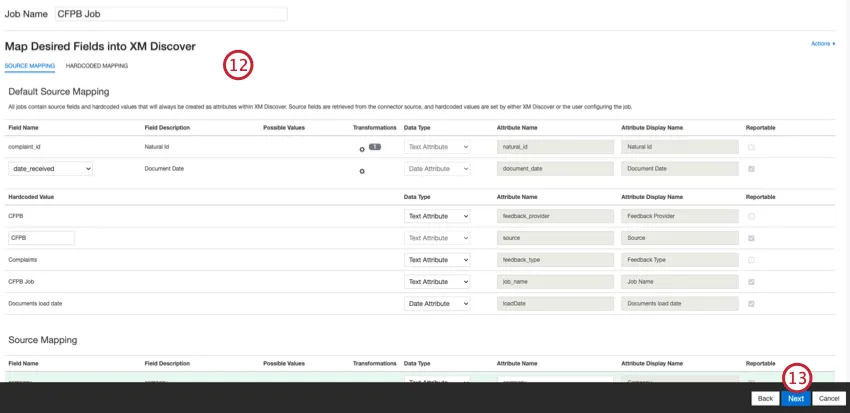
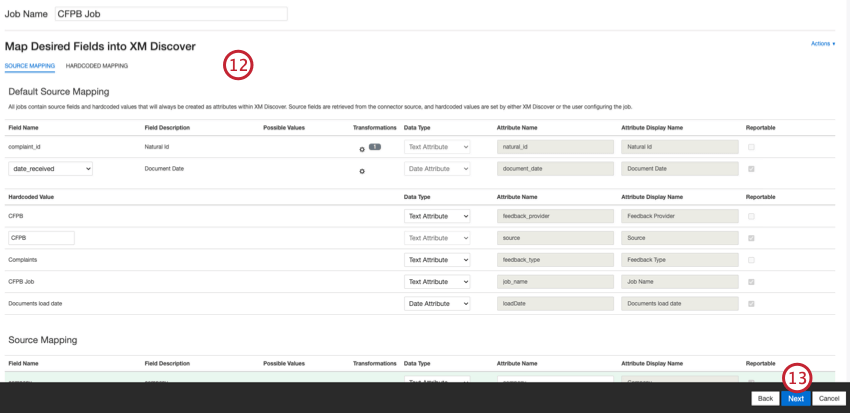
必要であれば、データマッピングを調整する。XM Discoverのフィールドマッピングの詳細については、データマッピングのサポートページを参照してください。デフォルトデータマッピングセクションには、このコネクタ固有のフィールドに関する情報があり、会話フィールドのマッピングセクションには、会話データのデータマッピング方法が記載されています。
次へ」をクリックします。
必要であれば、データの置換や再編集ルールを追加して、機密データを隠したり、顧客フィードバックやインタラクションの特定の語句を自動的に置き換えたりすることができます。データ置換と再編集のサポートページをご覧ください。
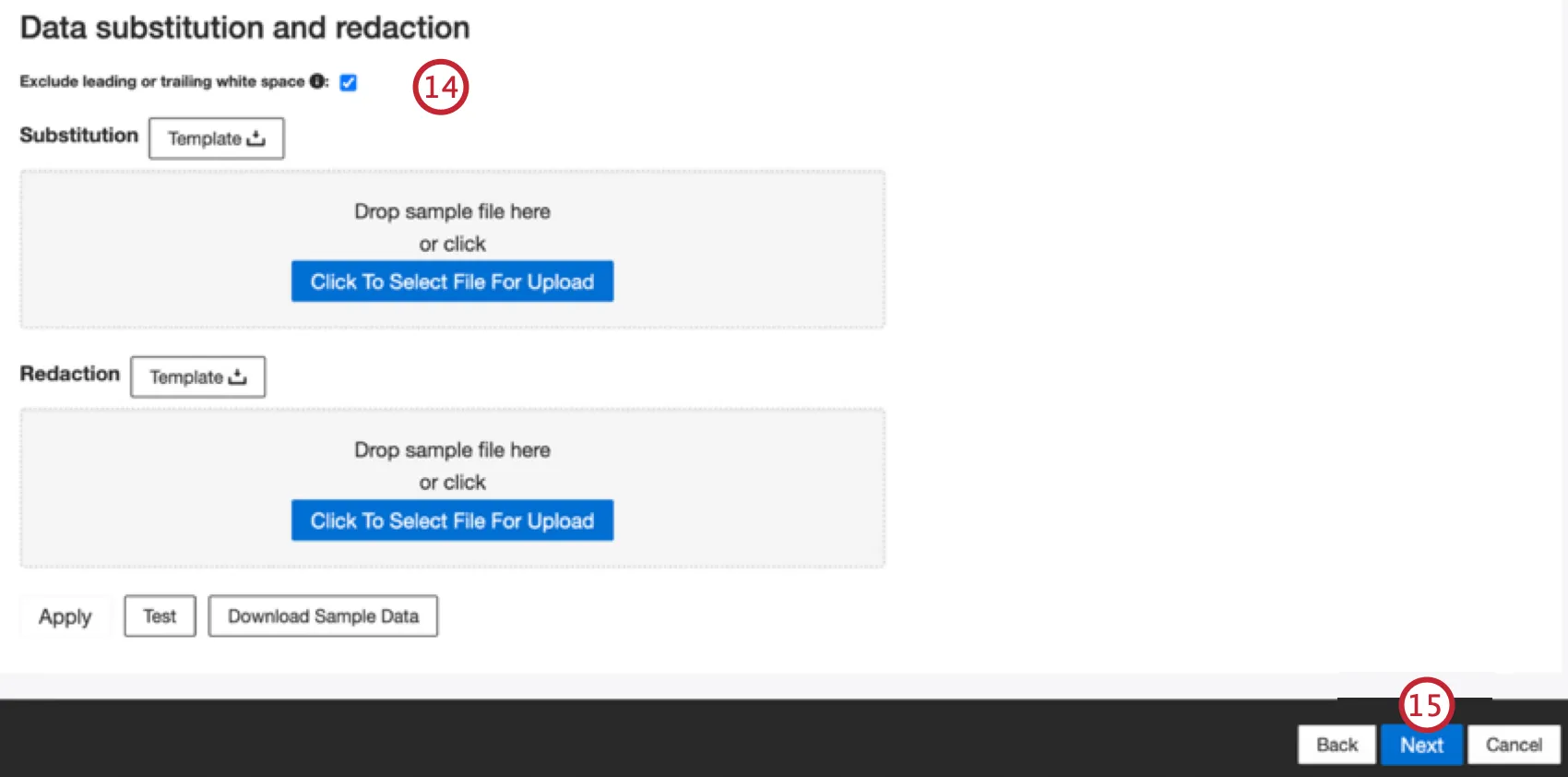
Qtip:サンプルデータのダウンロードをクリックすると、サンプルデータを含むエクセルファイルがコンピューターにダウンロードされます。
[次へ]をクリックします。
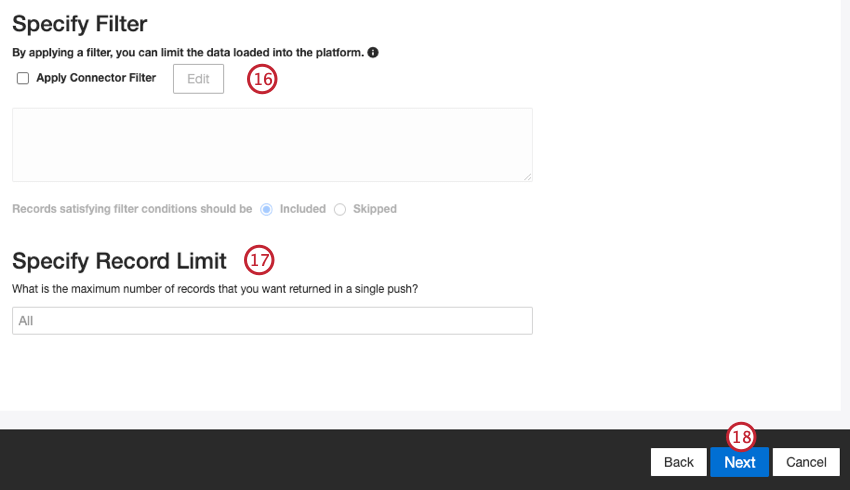
また、Specify Record Limitボックスに数値を入力することで、1回のジョブでインポートするレコード数を制限することもできます。すべてのレコードをインポートする場合は「All」を入力してください。
Qtip:会話データの場合、制限は行ではなく会話に基づいて適用されます。
[次へ]をクリックします。
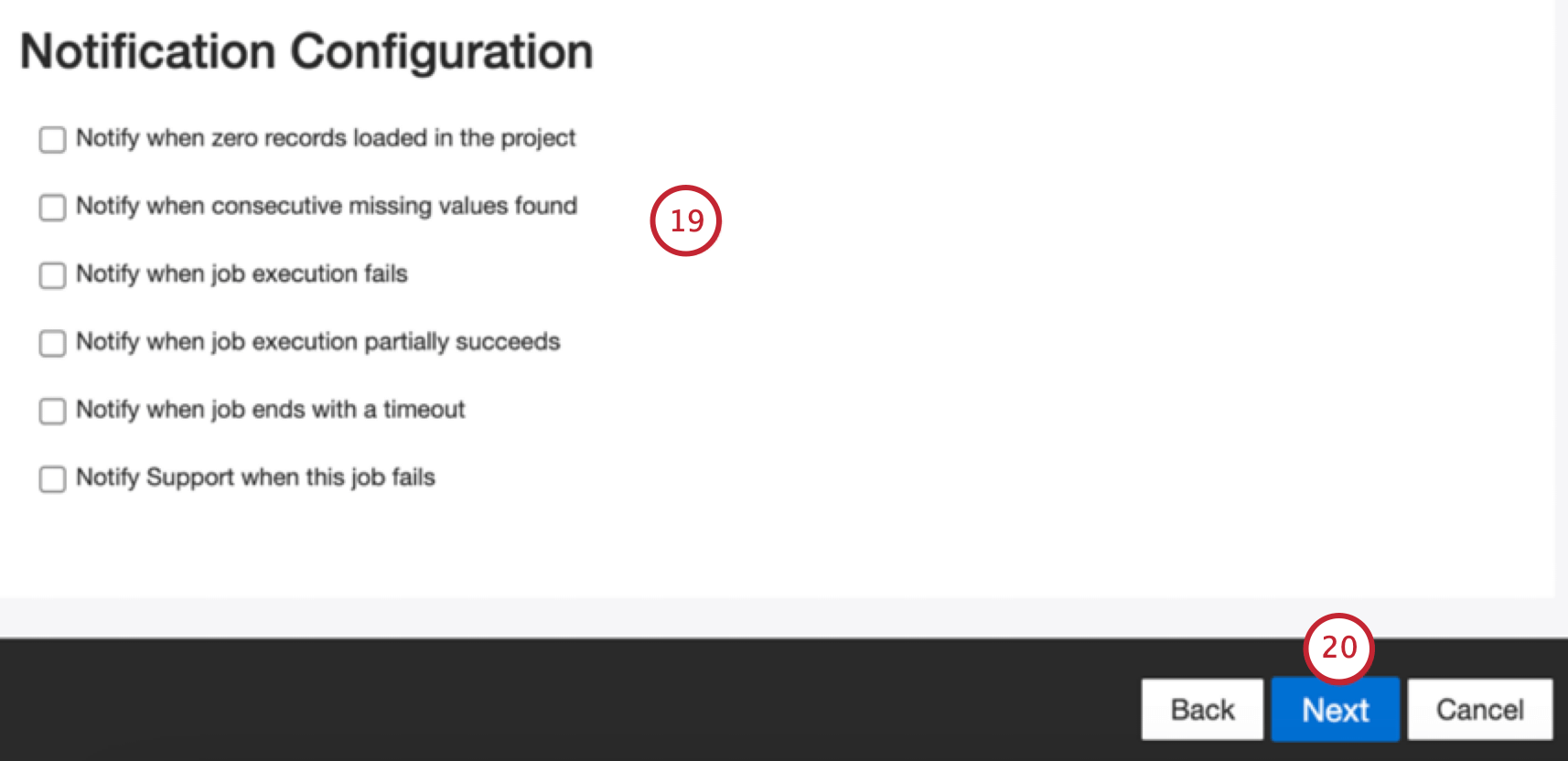
[次へ]をクリックします。
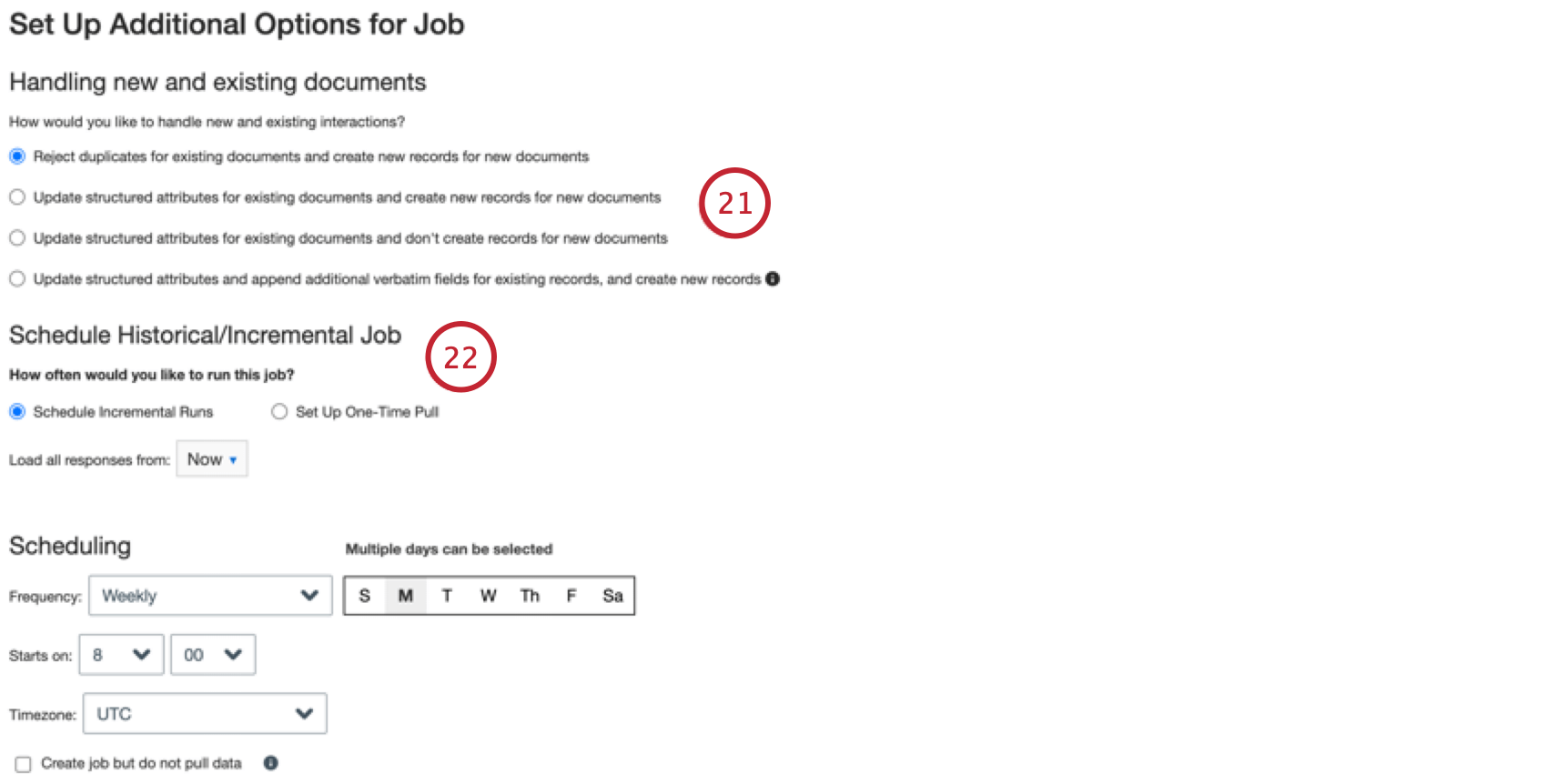
ジョブをスケジュールで定期的に実行したい場合はSchedule Incremental Runsを選択し、ジョブを一度だけ実行したい場合はSet Up One-Time Pullを選択します。詳細はジョブ・スケジューリングを参照。
増分実行を行う場合は、関連するすべての履歴データが処理に利用できるように、追加で取得するデータの期間(日または時間)を指定します。なお、CFPBのシステムには、予想より遅れてデータが届く場合もある。したがって、不完全なデータ取り込みのリスクを減らすために、検索期間を延長することを推奨する。デフォルト値は3日。
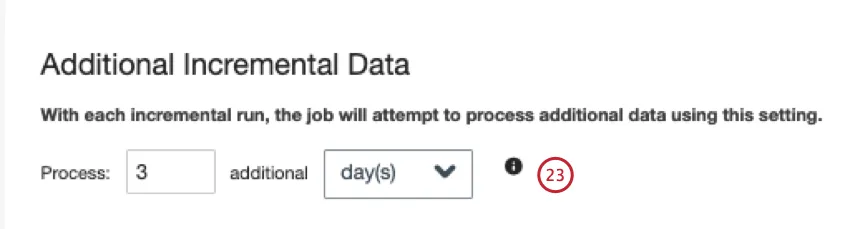
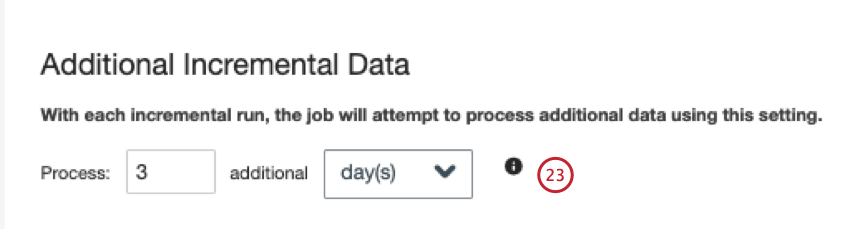
[次へ]をクリックします。
セットアップを評価する。特定の設定を変更する必要がある場合は、[Edit]ボタンをクリックして、コネクタ設定のそのステップに移動します。
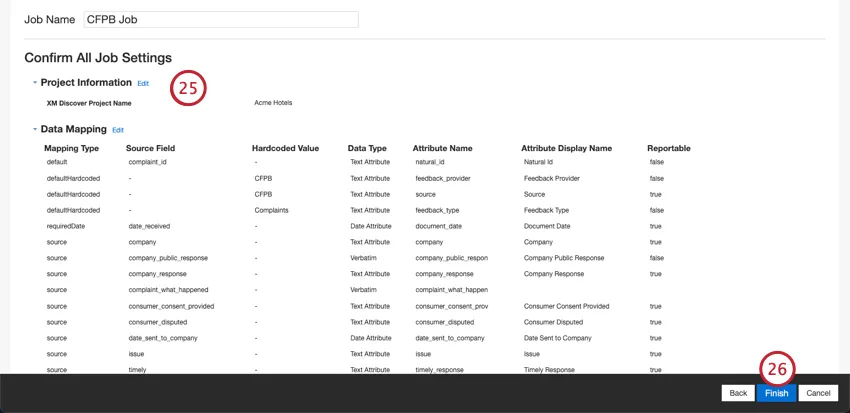
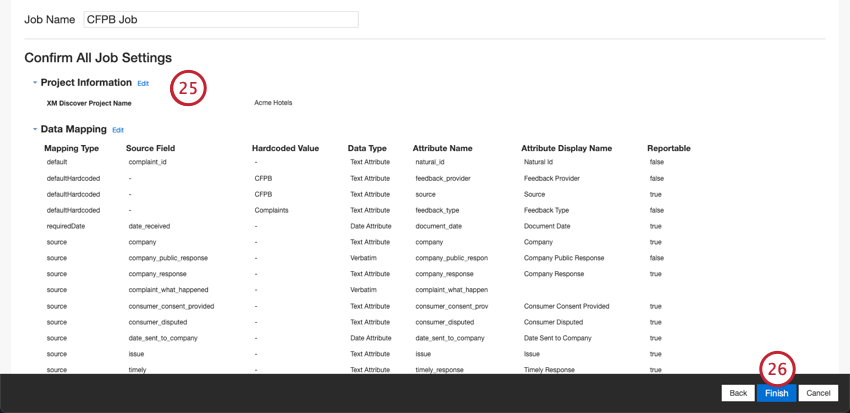
Finishをクリックしてジョブを保存する。
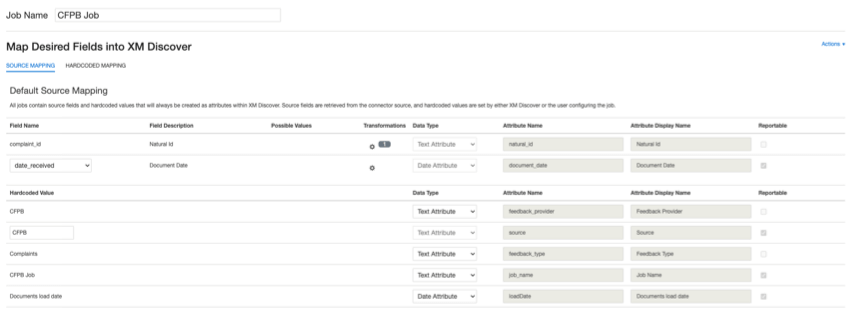
デフォルトのデータマッピング
注意してください:Connectorsではフィールド名の大文字と小文字が区別されるため、データマッピングを正確に行い、ジョブを成功させるには、フィールド名の最初の文字をデータサンプリングに表示されているように大文字にする必要があります。
このセクションでは、CFPBインバウンド・ジョブのデフォルト・フィールドについて説明します。
{kind=link}
- natural_id:文書の一意な識別子。複製を正しく処理するために、各書類に固有のIDを設定することを強くお勧めします。ナチュラルIDでは、データフィールドから任意のテキストまたは数値フィールドを選択できます。また、カスタムフィールドを追加してIDを自動生成することもできます。
- document_date: ドキュメントに関連付けられた主な日付フィールド。この日付はXM Discoverのレポート、トレンド、アラートなどで使用されます。以下のオプションのいずれかを選択できます:
- date_received(デフォルト):CFPBが苦情を受理した日付。
- date_sent:苦情が対応する会社に送られた日付。
- データソースに他の日付フィールドが含まれている場合は、そのいずれかを選択できます。
- また、特定の文書の日付を設定することもできます。
- feedback_provider:特定のプロバイダから取得したデータを識別する。CFPBアップロードの場合、この属性の値は “CFPB “に設定され、変更することはできない。
- ソース:特定のソースから取得したデータを特定する。これは、アンケート調査やモバイルマーケティングキャンペーンの名前など、データの出所を示すものであれば何でもかまいません。デフォルトでは、この属性の値は “CFPB “に設定されている。カスタム変換を使用して、カスタム値を設定したり、式を定義したり、別のフィールドにマッピングしたりします。
- feedback_type:タイプに基づいてデータを識別する。これは、プロジェクトに異なるタイプのデータ(例えば、アンケート調査とソーシャルメディアフィードバック)が含まれている場合のレポートに便利です。デフォルトでは、この属性の値は “Complaints “に設定されている。カスタム変換を使用して、カスタム値を設定したり、式を定義したり、別のフィールドにマッピングしたりします。
- job_name: アップロードに使用されたジョブの名前に基づいてデータを識別します。セットアップ中にこの属性の値を変更するには、セットアップ中に各ページの上部に表示されるジョブ名フィールドを使用します。
- loadDate:ドキュメントがいつXM Discoverにアップロードされたかを示します。このフィールドは自動的に設定され、変更することはできない。
当サポートサイトの日本語のコンテンツは英語原文より機械翻訳されており、補助的な参照を目的としています。機械翻訳の精度は十分な注意を払っていますが、もし、英語・日本語翻訳が異なる場合は英語版が正となります。英語原文と機械翻訳の間に矛盾があっても、法的拘束力はありません。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!