-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
データマッピング(Discover)
Discoverのデータマッピングについて
データマッピングの目的は、XM Discoverプロジェクトのデータの構造とフォーマットを定義することです。XM Discoverにデータをアップロードする場合、外部ソース(サードパーティ・サービスやファイルなど)のデータフィールドをXM Discoverプロジェクトのデータフィールドにマッピングする必要があります。
XM Discoverでデータをマッピングする場合、以下のことが可能です:
- XM Discoverのデフォルトデータフィールドの値を定義します。
- どのデータフィールドを新しい属性としてアップロードし、どのデータフィールドを既存の属性に接続するかを選択します。
- 新規フィールドのデータタイプを設定する。
- アップロードしたくないフィールドはスキップしてください。
データマッピングへのアクセシビリティ
ジョブのデータマッピングオプションにアクセスする方法は2つあります:
- ジョブの作成時Map Desired Fields into XM Discover ページで、初期データマッピング設定を行うことができます。
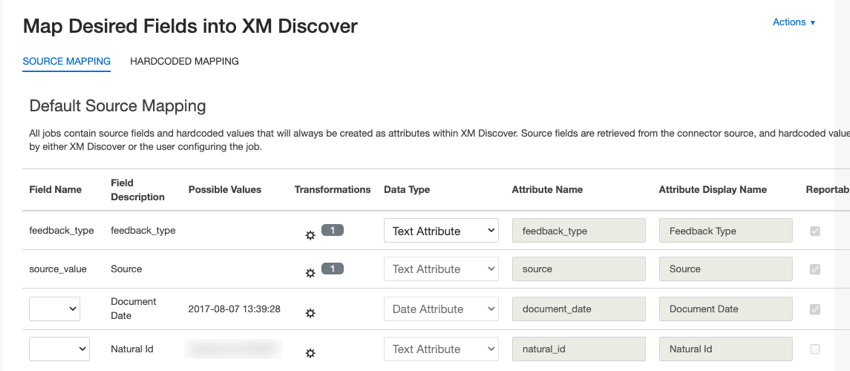
- 既存のジョブの場合:ジョブのアクションメニューからデータマッピングオプションを選択することで、データマッピング設定にアクセスできます。
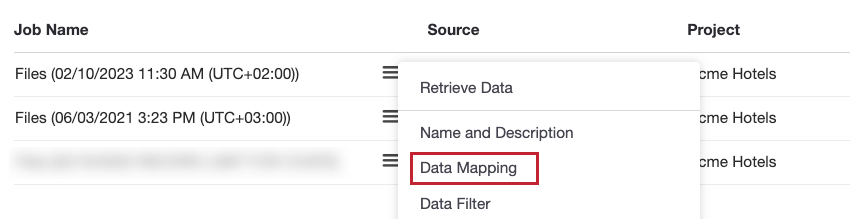
データのマッピング
XM Discoverでデータをマッピングする場合は、このセクションの手順に従ってください:
- デフォルトのソース・マッピングには、コネクタのデフォルトの必須フィールドがすべて含まれます。このセクションにリストされているフィールドの追加や削除はできません。
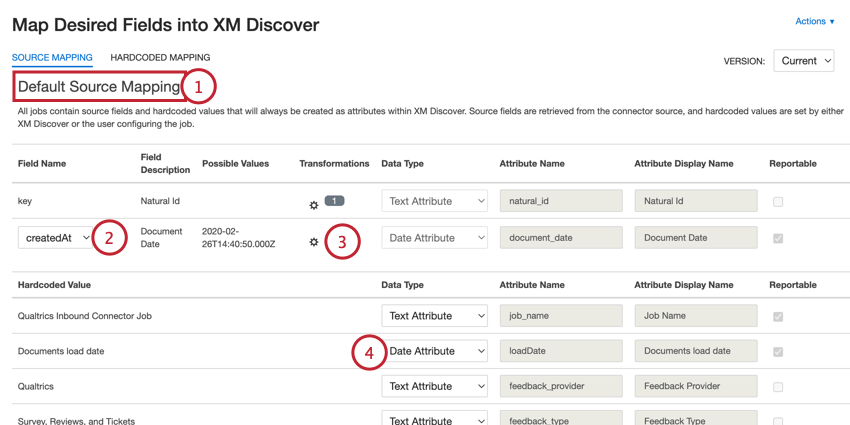
- フィールドによっては、複数のソース・フィールドから選択できるものもあります(例えば、どの日付フィールドがドキュメントの日付を表すかを決定する場合など)。それが可能であれば、ドロップダウンメニューが表示され、希望するフィールドを選択することができます。
- フィールドによっては、記録されたフィールド値を変更するカスタム変換を適用することができます。カスタム変換を追加するには、歯車のアイコンをクリックします。
- 必要に応じて、新しく追加されたフィールドのデータタイプを調整することができます。一部のフィールドは必須であり、そのデータタイプを変更したり、”Do Not Map “に設定したりすることはできない。
Qtip:既存のフィールドのマッピングを解除したい場合は、そのデータタイプを “Do Not Map” に変更してください。
- ソース・マッピング・セクションでは、コネクタから追加のフィールドをマッピングできます。これらは、デフォルトの必須フィールドと一緒に含めたいオプションフィールドです。
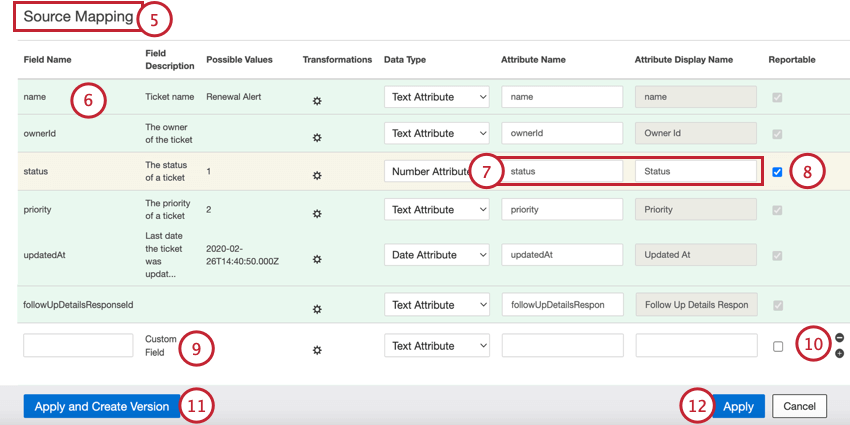
- デフォルト以外のフィールドは以下のように色分けされている:
- 白:このフィールドは新しい属性にマッピングされています。つまり、XM Discoverはこのフィールドに一致する属性をプロジェクト内で発見していません。
- 緑:フィールドは既存の属性にマッピングされ、同じ名前が付けられている。
- 黄色:フィールドは既存の属性にマッピングされているが、フィールド名が完全に一致しない。
例例:ソースにNAMEというフィールド名があり、NAMESという既存の属性がある場合、ほとんどの場合、黄色の背景にマッピングされます。
- 赤:フィールドにデータ型の不一致や不正な名前などのマッピング上の問題がある。
例フィールドのデータ型が “Text Attribute “に設定されているが、同じ名前のフィールドがすでに “Number Attribute “としてXM Discoverに存在している。この問題を解決するには、「データタイプ」ドロップダウンメニューから正しいデータタイプを選択します。
- 新しいフィールドを追加する際、属性名列と属性表示名列に、よりユーザー属性に近いフィールド名を追加することができます:
- 属性名:XM Discoverに保存されるフィールド名。このフィールド名にはスペースを含めることはできず、構造化データフィールドの場合は21文字、逐語フィールドの場合は30文字を超えることはできない。
Qtip:新しいフィールドを既存のフィールドにマッピングしたい場合は、この欄に既存の属性名を入力してください。
- 属性表示名:ユーザーに表示されるフィールド名(レポートなど)。この名前にはスペースを含めることができ、99文字を超えることはできない。
Qtip:逐語フィールドの場合、属性表示名は自動的に属性名と一致するように設定されます。
- 属性名:XM Discoverに保存されるフィールド名。このフィールド名にはスペースを含めることはできず、構造化データフィールドの場合は21文字、逐語フィールドの場合は30文字を超えることはできない。
- Reportable(レポート可能)列のチェックボックスを有効または無効にすると、レポート用の新しいフィールドを有効または無効にすることができます。すでに存在するフィールドについては、この設定を変更することはできません。
- 必要であれば、カスタム変換を使用してカスタムフィールドを作成できます。
- プラス(+ )と マイナス(–)記号を使用して、必要に応じてカスタムフィールドを追加および削除します。
- 適用とバージョンの作成」をクリックすると、データマッピングが新しいバージョンとして保存され、必要に応じてマッピングを元に戻すことができます。
- 適用]をクリックして、今後のジョブ実行に変更を適用します。
ハードコードされたデータマッピング
必要であれば、ハードコードされたデータマッピングを追加することができ、ジョブ経由でアップロードされたすべてのレコードに指定されたハードコードされた値が適用されます:
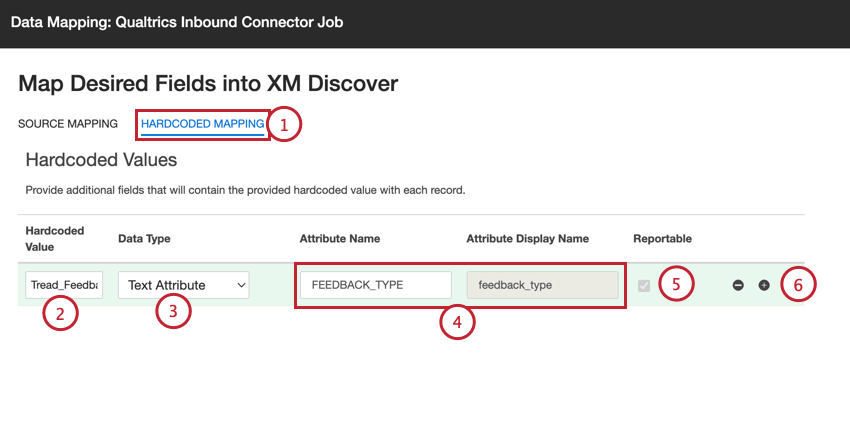
- データ・マッピング・ウィンドウで、ハードコード・マッピングをクリックする。
- このジョブでアップロードされたすべてのレコードに適用される「ハードコード値」を入力してください。
- フィールドのデータタイプを選択する。
- 属性名フィールドでは、既存のフィールドを選択するか、名前を入力して新しいフィールドを作成する。新しいフィールドを追加する場合は、属性表示名を設定することもできます。
- 新しいフィールドを追加する場合、レポート用フィールドを有効にするにはReportableチェックボックスを選択し、レポート用フィールドを無効にするにはチェックを外します。
- 必要に応じて、プラス (+) およびマイナス (–) 記号を使用して、ハードコードされた値を追加します。
会話フィールドのマッピング
このセクションでは、通話やチャットなどの会話データのための会話フィールドをマッピングする方法について説明します。ソースマッピング・セクションでは、以下の会話データフィールドを設定することができま す:
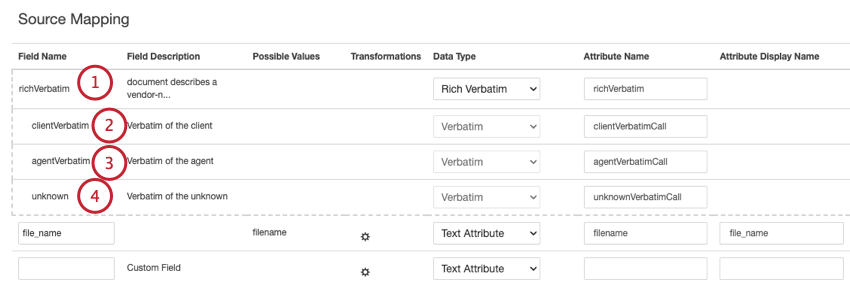
- richVerbatim:会話データ(通話やチャットなど)の場合、XM DiscoverはrichVerbatimフィールドに会話逐語形式を使用します。このフォーマットは、会話の図表(話し手の交代、沈黙、会話イベントなど)やエンリッチメント(開始時間、継続時間など)を解除するために必要な、ダイアログ固有のメタデータの取り込みをサポートします。この逐語フィールドには、クライアント側と代理人側の会話を追跡するための「子」フィールドが含まれる:
- clientVerbatim:クライアント側の会話を追跡する。
- エージェントバーベイタム:エージェント側の会話を追跡します。
- unknown:話し手が誰であるかが明確でない、または話し手が依頼人でも代理人でもない会話の他の部分を追跡する。
Qtip:同じ逐語訳を異なるタイプの会話データに使用することはできません。プロジェクトで複数のタイプの会話をホストしたい場合は、会話のタイプごとに会話文のペアを分けてください。
- clientVerbatim:通話やチャットでのクライアント側の会話をトラッキングします。デフォルトでは、このフィールドがマッピングされる:
- clientVerbatimChatでデジタル交流。
- clientVerbatimCall 通話インタラクション用。
- エージェントバーベイタム通話やチャットのやり取りにおいて、担当者(エージェント)側の会話をトラッキングします。デフォルトでは、このフィールドがマッピングされる:
- agentVerbatimChatでデジタル交流。
- agentVerbatimCallはコールインタラクションのためのものです。
- unknown: 通話やチャットでの未知の会話をトラッキングします。デフォルトでは、このフィールドは
- デジタル交流のためのunknownVerbatimChat。
- unknownVerbatimCallはコールインタラクション用。
データタイプ
XM Discoverでフィールドを定義する場合、フィールドのデータタイプを次のいずれかに設定できます:
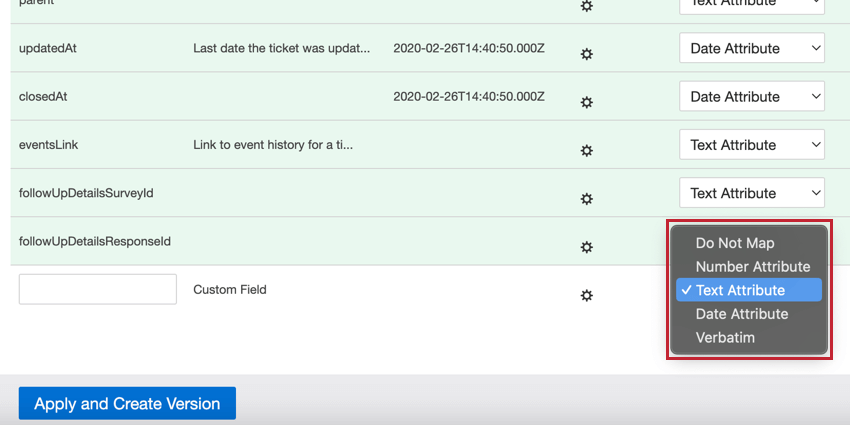
- マップしない:このフィールドをXM Discoverにアップロードしないでください。
- 数字属性:数値フィールド用。これらの属性に対して計算を行うことができる。
Qtip:この数値に対して計算を行いたい場合のみ、「数値属性」を選択してください。数値属性の良い例は年齢で、アンケート調査参加者の平均年齢を見るのは興味深いかもしれません。数値属性の悪い例として、車の年式がありますが、これはテキスト属性として選んだ方が良いでしょう。
- テキスト属性:離散的な値の集合を持つテキスト・フィールド用。
Qtip:Connectorsが新しいテキスト属性を作成する場合、デフォルトでは大文字と小文字が区別されます。大文字と小文字を区別しない属性にしたい場合は、まずDesignerで作成してください。
- 日付属性:日付フィールド用。
- 逐語:逐語フィールドとテキストコメント用。XM Discover NLPエンジンで処理したい非構造化データのフィールドには、逐語訳を使用します。
データ・マッピング・アクション
アクションメニューでは、以下のタスクを実行できます:
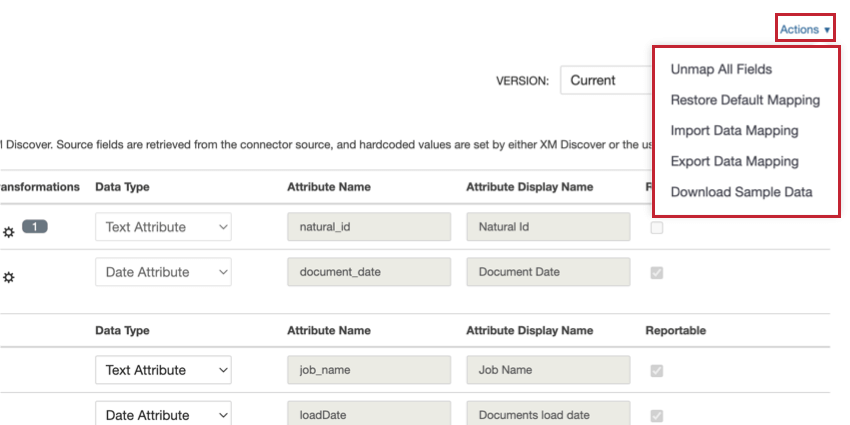
- すべてのフィールドのマッピングを解除します:データマッピングの “ソースマッピング” セクションのすべてのフィールドのマッピングを削除し、すべてのフィールドを “マッピングしない” に設定する。
- デフォルト・マッピングの復元カスタムフィールドマッピングを削除し、コネクタのデフォルトデータマッピングを復元します。
- データマッピングのインポート:データマッピングを含むファイルをインポートできます。詳しくはデータマッピングのインポートとエクスポートを参照。
- データ・マッピングのエクスポート:データマッピングを含むファイルをエクスポートできます。詳しくはデータマッピングのインポートとエクスポートを参照。
- サンプルファイルからマッピングを更新します:このオプションは、XM Discover LinkおよびFilesコネクタでのみ使用できます。XM Discoverデータ形式のサンプルファイルをアップロードすることで、マッピングを更新できます。
- サンプルデータのダウンロード:サードパーティのサービスからデータフィールドをマッピングする場合、サンプルデータを含むExcelスプレッドシートをダウンロードして、プロジェクトで期待されるデータのタイプをよりよく理解することができます。このスプレッドシートには2枚のシートが含まれています:
- 標準データ:標準データ:デフォルト名と値を持つマッピングされていないソース・フィールド(マッピング前)。
- マッピングされたデータ:マッピングされたデータ:(マッピング後に)変換されたフィールド名と値を持つマッピングされたフィールド。
データマッピングのインポートとエクスポート
データマッピングをExcelスプレッドシートにエクスポートすることで、XM Discoverの外でもマッピングを変更することができます。その後、このファイルをインポートしてマッピングを更新することができます。これらのオプションは、ジョブ間でデータマッピングをすばやく再利用することも可能にします。
- ActionsメニューでExport Data Mappingを選択する。
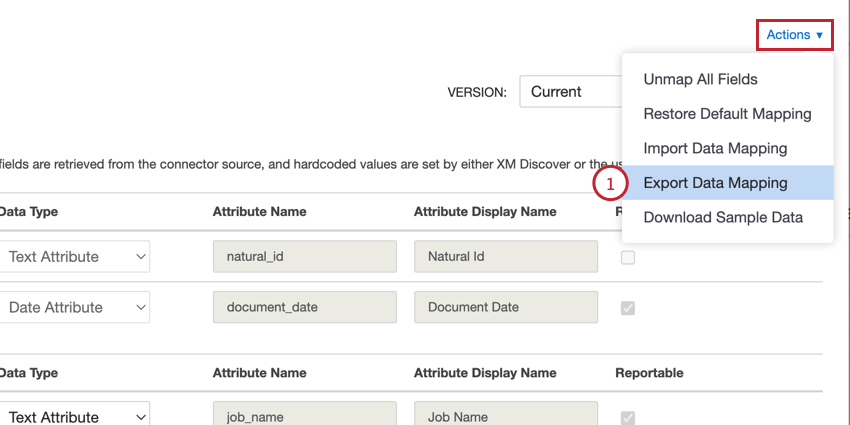
- 必要に応じてマッピングを編集してください。ファイルを編集する際は、以下のガイドラインに従ってください:
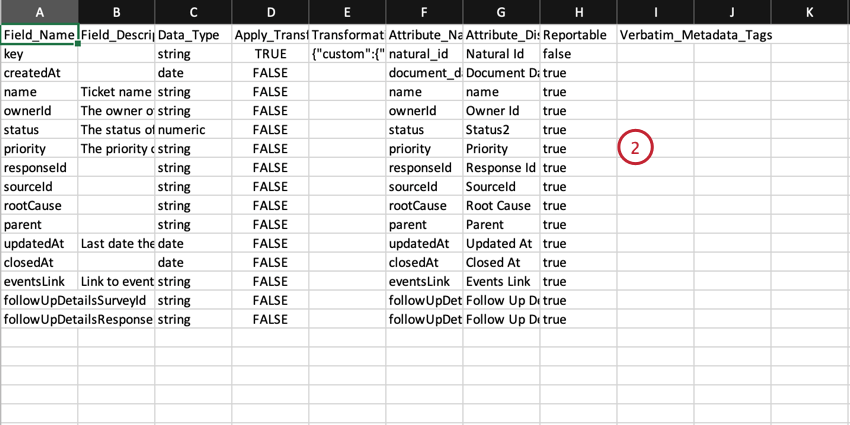
- 列名は、Discoverのデータマッピングウィンドウに表示される列と一致する。
- 新しい行を追加することで、新しいカスタムフィールドを作成できます。
- 新しい列は追加しないでください。
- ファイルをXLSまたはXLSXファイルとして保存します。
- Actionsメニューで、Import Data Mappingを選択する。
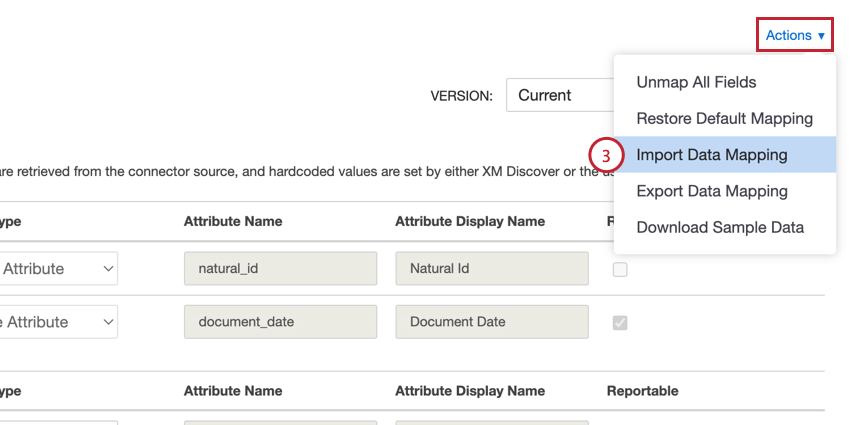
- ファイルのアップロードをクリックし、コンピュータに保存されているファイルを選択します。
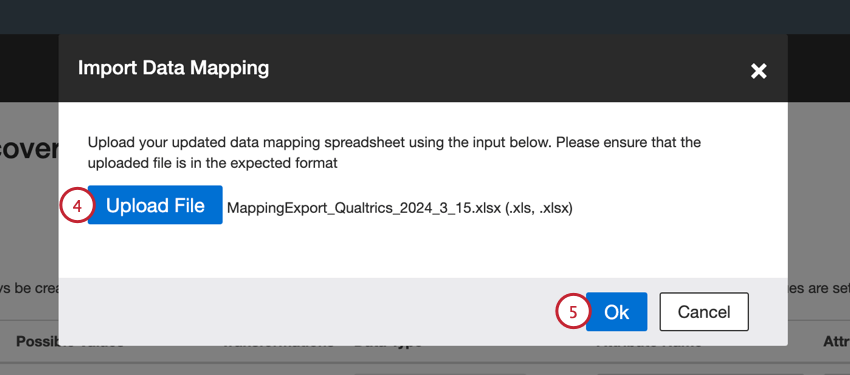
- Okをクリックする。
データマッピングのバージョン
ジョブのデータマッパーは、ジョブのデータマッピングの最近保存されたバージョンを30個まで記録します。必要に応じて、これらの保存されたデータマッピングを復元することができます。
以下の手順でデータマッピングのバージョンを切り替える:
- データをマッピングしたら、適用とバージョンの作成をクリックします。これは、変更を元に戻す必要がある場合に備えて、現在のデータマッピングを新しいバージョンとして保存します。
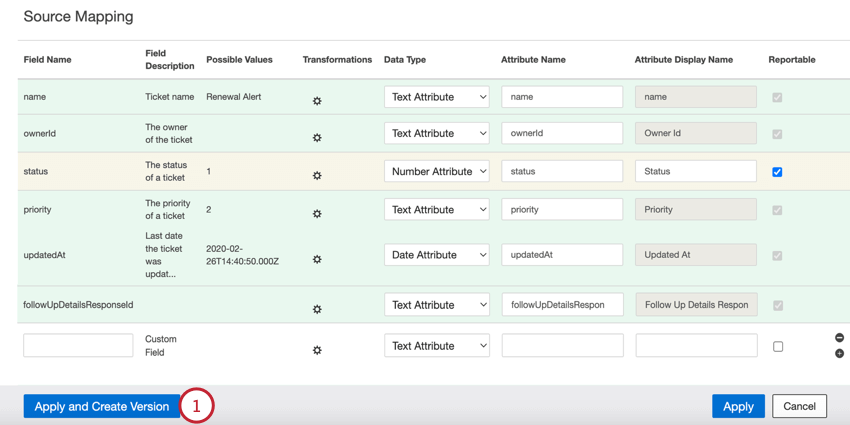
- バージョンのドロップダウンを使用して、切り替えたいバージョンを選択します。
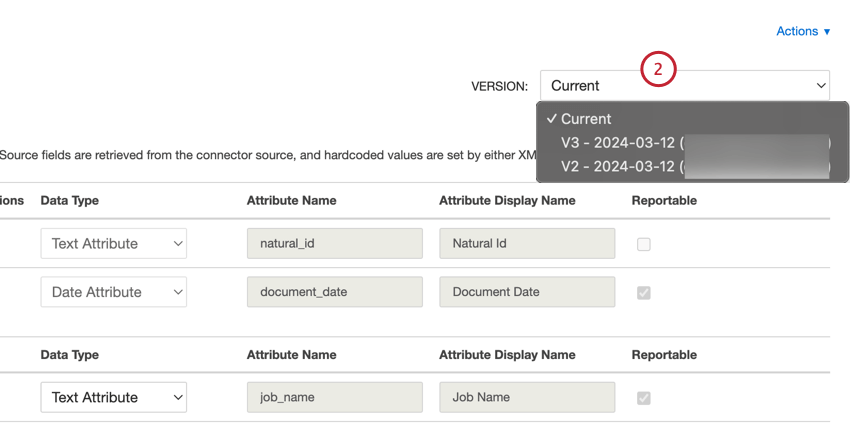
- ページ上部にバナーが表示され、どのバージョンを使用しているかをお知らせします。続行する前にマッピングを再チェックする。
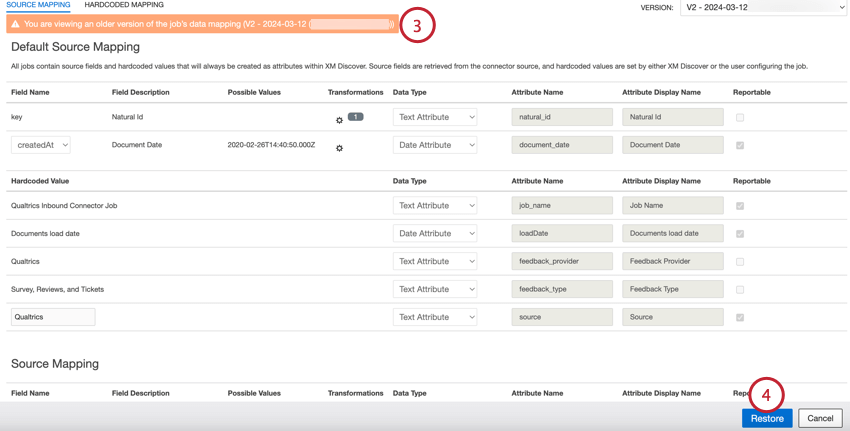
- Restore をクリックする。
- Okをクリックする。
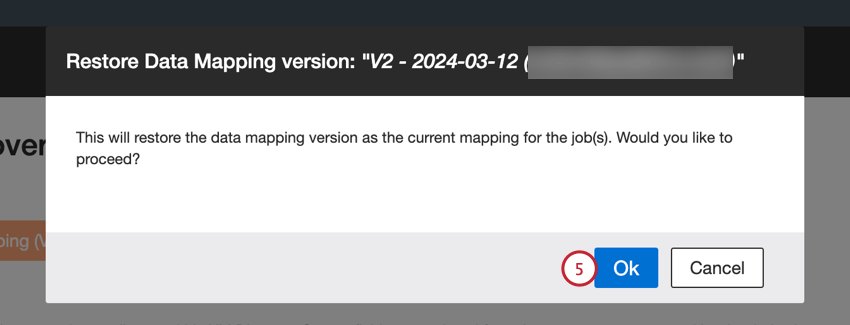
- このステップは、最初のマッピングを新しいバージョンとして保存していない場合にのみ表示されます。現在のデータ・マッピングに未保存の変更が含まれている場合は、その未保存のバージョンをどうするかを選択します:
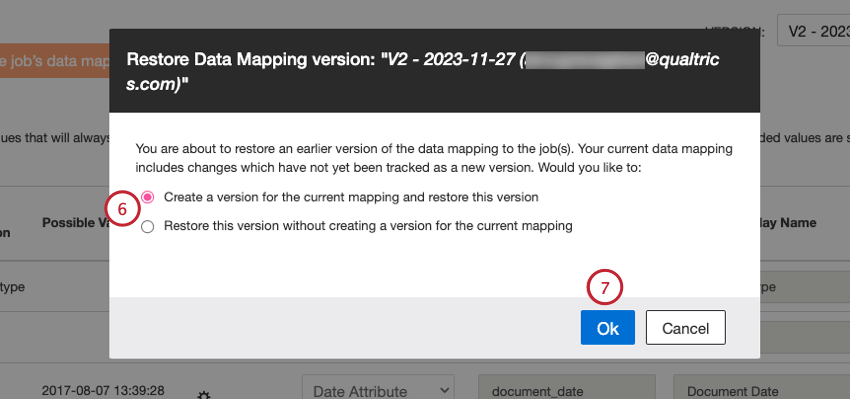
- 現在のマッピングのバージョンを作成し、このバージョンをリストアする:未保存のマッピングを別のバージョンとして保存し、選択したバージョンを復元する。
- 現在のマッピングのバージョンを作成せずに、このバージョンを復元する:未保存のマッピングを削除し、選択したバージョンを復元する。
- Okをクリックする。
データマッパーレポート
データマッパーレポートでは、自動生成されたマッピングファイルを使用して、クロスソースマッピングを検証することができます。
- ジョブ]タブで、テーブルにレポートに含めたいジョブが含まれるまで、ジョブをフィルタします。
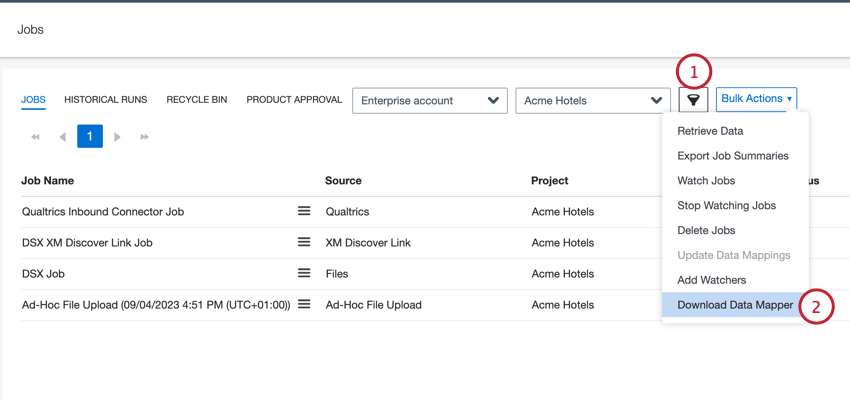 Qtip:データマッパーをダウンロードできるのは、選択したすべてのジョブが同じプロジェクト内にある場合のみです。
Qtip:データマッパーをダウンロードできるのは、選択したすべてのジョブが同じプロジェクト内にある場合のみです。 - 一括アクション] メニューで、[データマッパーをダウンロード]を選択する。
- XLSXまたはCSVのいずれかのエクスポート形式を選択します。
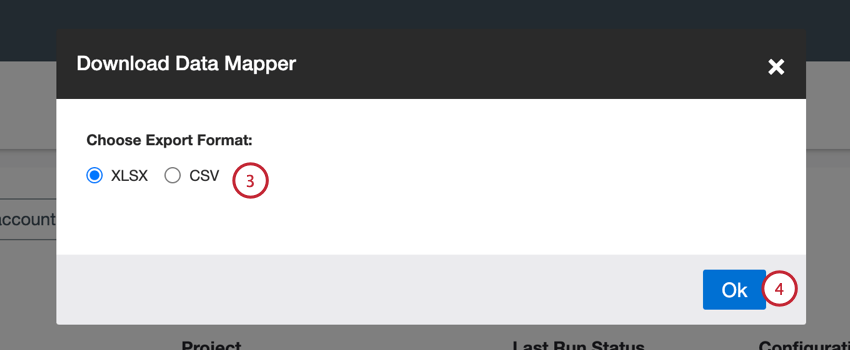
- Okをクリックする。
ファイルがダウンロードされると、レポートで以下のフィールドが利用可能になります:
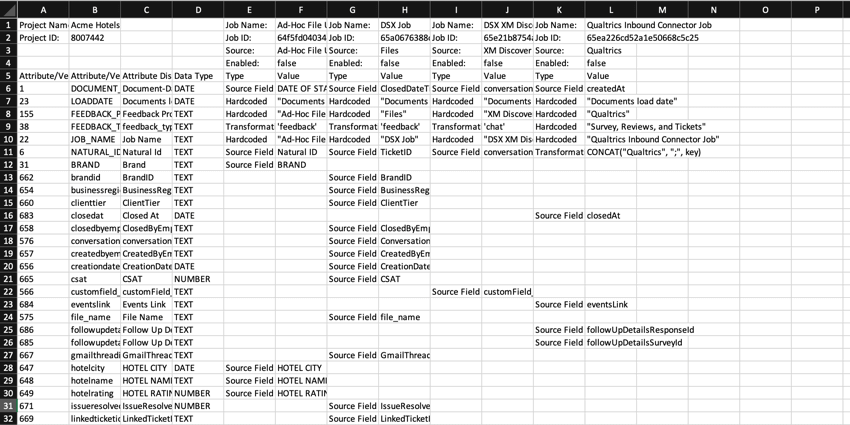
- プロジェクト名:データをアップロードするXM Discoverプロジェクトの名前。
- プロジェクトID:プロジェクトのID。
- 仕事名:ジョブの名前。
- ジョブID:ジョブのID。
- ソース:このジョブが設定されているデータソース。
- 有効:ジョブが有効かどうかを示すステータス。
- 属性/逐語タイプID:属性/逐語のID。
- 属性/バーベイタム名:XM Discoverによって保存された属性/バーベイムのシステム名。
- 属性表示名:XM Discoverによって保存された属性の表示名。ユーザー属性名」と同じにすることもできるし、よりユーザーフレンドリーなものを用意することもできる。
- データ型:属性のタイプ。可能な値は以下の通り:
- NUMBER:数値タイプのフィールドには自動的に設定される。
- TEXT:テキストタイプのフィールドに自動的に設定される。
- DATE:日付タイプのフィールドに自動的に設定される。
- VERBATIM:逐語的なフィールドとテキストコメントに設定する。
- タイプ:タイプ:マッピングされたデータフィールドのタイプ。可能な値は以下の通り:
- ソースフィールド:このジョブを介してアップロードされるすべてのドキュメントに追加される共通属性のデフォルトソースマッピングを持つデータフィールドのタイプ。
- ハードコード:レコードごとに値がハードコードされたデータフィールドのタイプ。
- 変換:Transformations: 変換および変更されたソースフィールド値を持つデータフィールドのタイプ。
- 値:属性の値。