-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
クロス集計
クロス集計について
クアルトリクスでは、一度に2つ以上の変数について多変量解析を行うためのクロス集計ツールを提供しています。このツールには、カイ2乗統計やANOVAを計算する機能を含む、クロス集計をカスタマイズするための多くのオプションが含まれています。
このページでは、変数を設定したり計算を行ったりするさまざまな方法に加えて、クロス集計を設定するための基本的なことを説明します。その他の機能については、クロス集計オプションを参照してください。
Qtip:クロス集計は統計的検定です。クロスタブ理論についてもっと見る
各選択肢の選択回数を表示するテーブルをお探しなら、クロス集計ではなく、(結果レポートの)標準テーブルか(詳細レポートの)データテーブルをご覧ください。基本的な平均値、最小値、最大値、その他の統計情報を1問だけ知りたい場合は、クロス集計ではなく、統計テーブル(結果テーブル)または統計テーブル(詳細)をご覧ください。
クロス集計によるプロジェクトの種類
クロス集計は、いくつかの異なるプロジェクトタイプで利用可能です。組織で何にアクセシビリティがあるかにもよるが、クロス集計は以下のものと互換性がある:
- アンケートプロジェクト
- 多くのXMソリューションのご案内
- インポートされたデータプロジェクト
- エンゲージメント
- ライフサイクル
- アドホック従業員調査
- コンジョイントプロジェクトとMaxDiffプロジェクト
注意コンジョイントプロジェクトとMaxDiffデータはクロス集計に表示されますが、同じプロジェクトで記録した基本的な調査データと同様に、クロス集計では機能しない場合があります。
クロス集計は360、Pulse、上記以外のプロジェクトとは互換性がありません。
クロス集計の情報(テーブル、重み設定、カスタムフィールドなど)を、ダッシュボードを含む他のレポートに取り込むことはできません。
新しいクロス集計の作成
- [データと分析]タブに移動します。
- クロス集計 iQ をクリックする。
- 初めて作成する場合は「新しいクロス集計を作成 」をクリックし、別のクロス集計を作成する場合はドロップダウンメニューから「新しいクロス集計を作成 」を選択してください。
- 左側は変数です。これには、質問、埋め込みデータ、メタデータ、テキスト分析結果などのアンケート調査データが含まれます。
- リストから変数を選択し、それを列(バナー)ボックスにドラッグして列を作成する。通常、これらは年齢、収入、性別などの人口統計学的変数または「入力」変数である。
 Qtip:数値自由回答の質問は列や行として機能しません。Qtip:複数の変数を選択する場合は 命令 キーまたは コントロール キーを押しながら選択したい変数をクリックする。を押し続けることで、多くの変数を連続して選択することもできます。 シフト キーボードのキーを押しながら、選択したい変数の最初と最後をクリックする。
Qtip:数値自由回答の質問は列や行として機能しません。Qtip:複数の変数を選択する場合は 命令 キーまたは コントロール キーを押しながら選択したい変数をクリックする。を押し続けることで、多くの変数を連続して選択することもできます。 シフト キーボードのキーを押しながら、選択したい変数の最初と最後をクリックする。 - リストから変数を選択し、それを行(スタブ)ボックスにドラッグして行を作成する。通常は、満足度などの評価や「出力」変数である。
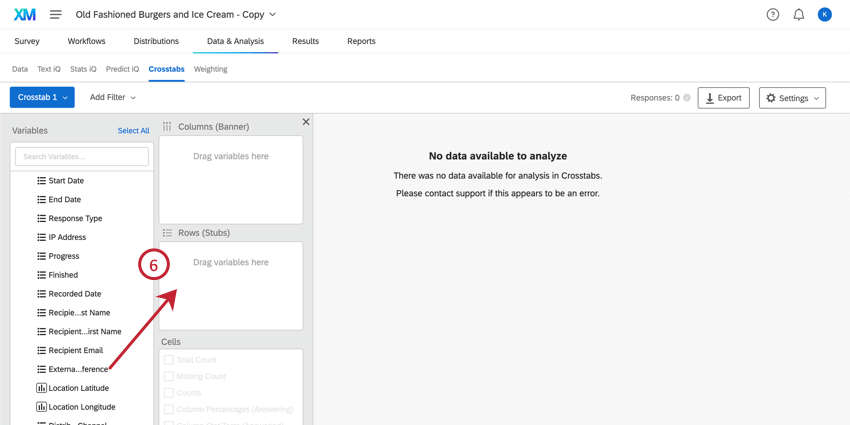
- これで、クロス集計に追加したい情報のセルを追加できます。これらのオプションの詳細を「利用可能な計算」のセクションで見てください。
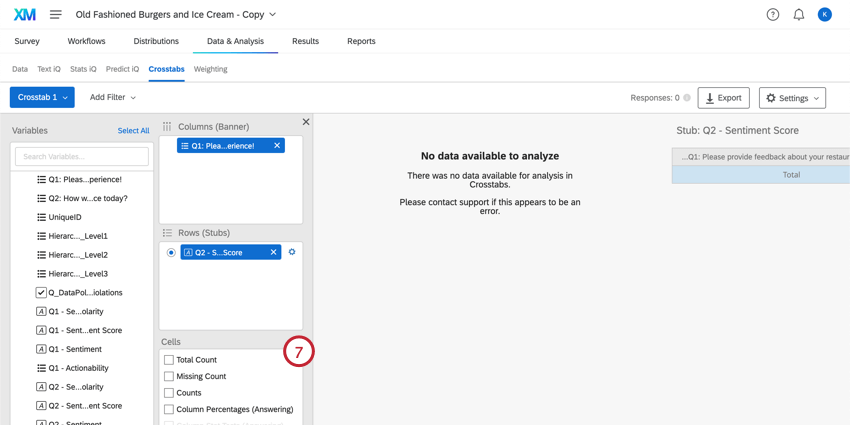 Qtip:セルの一部がグレーアウトしていませんか?データの一部を再コード化するか、他のオプションを選択する必要がある可能性が高い。必要なことについては、「利用可能な計算」のセクションを参照してください。
Qtip:セルの一部がグレーアウトしていませんか?データの一部を再コード化するか、他のオプションを選択する必要がある可能性が高い。必要なことについては、「利用可能な計算」のセクションを参照してください。 - これでクロス集計ができた!このクロス集計のセル、列、行はいつでも編集できます。
クロス集計への新しい回答の追加
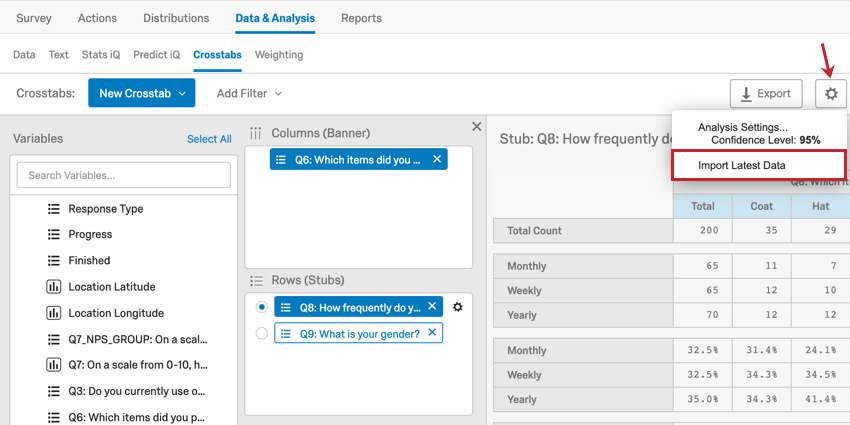
より多くの回答を収集すると、クロス集計を再計算する必要があります。右上の設定タブをクリックし、最新データのインポートを 選択して、新しい回答をデータセットに追加します。再計算中はクロス集計はご利用いただけません。
クロス集計における重み設定
また、クロス集計データに重み設定を適用することもできる。これは、回答の重み設定に基づいて、またはデータの既存の数値変数の1つに基づいて行うことができます。
- データに必要な重み設定を適用したら、クロス集計 iQセクションに移動します。
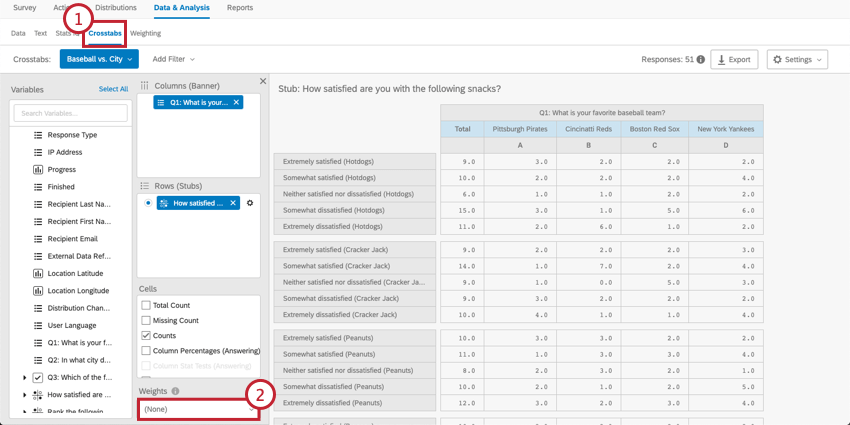
- 重み設定 セクションの下にあるドロップダウンメニューをクリックします。これにより、利用可能な数値変数と重み設定が表示されます。
QTip:「クアルトリクス重み設定」とは、「重み設定」タブで作成された重み設定のことです。データに重み設定を適用していない場合、この変数はクロス集計メニューに表示されません。
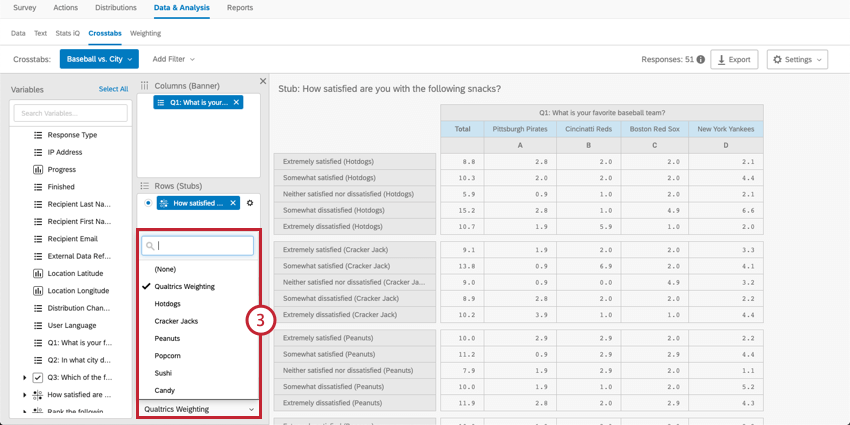
- データに適用したい数値変数を選択します。
列と行の移動
カラム(バナー)は「入力」変数である。これには、性別、収入、年齢などの人口統計が含まれる。列は、不変または独立として扱う変数とする。
行(スタブ)は「出力」変数である。これには、満足度、CSAT、CES、Npsなどのような評価変数が含まれる。行には、調査の条件によって変化すると思われる変数を入れます。
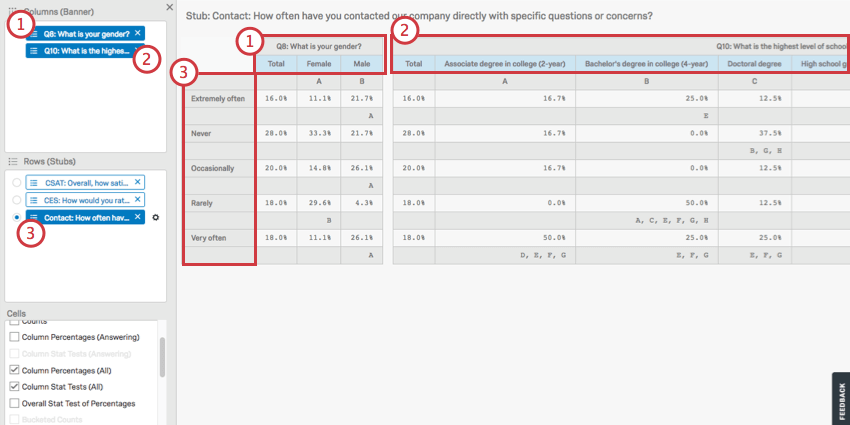
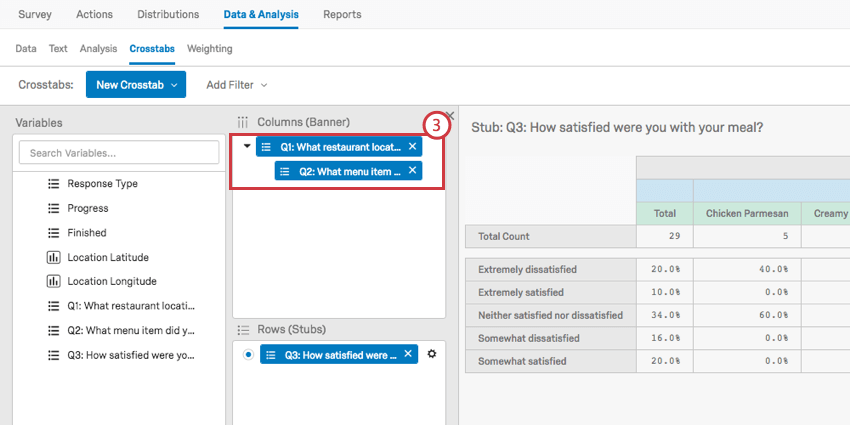
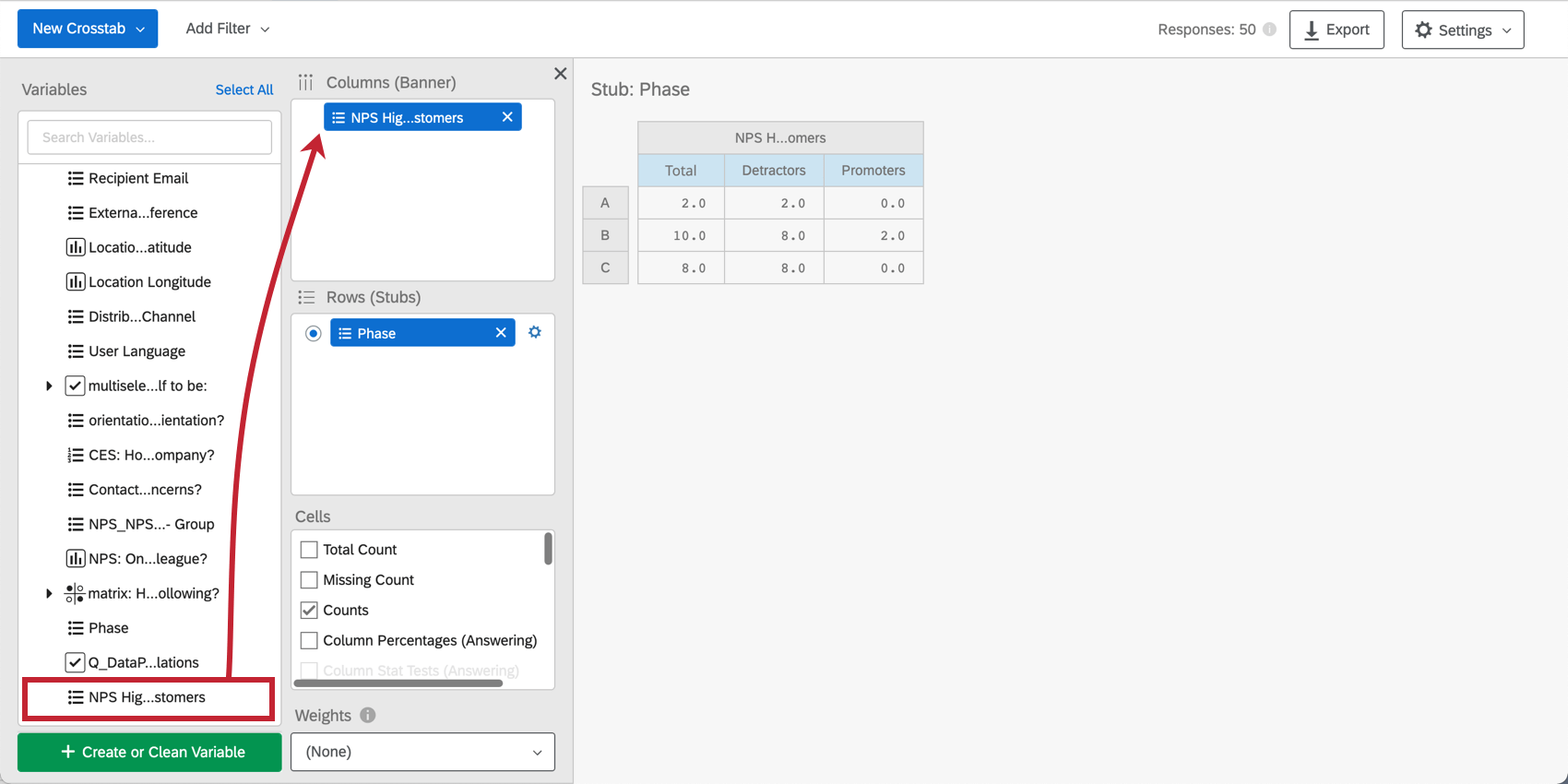
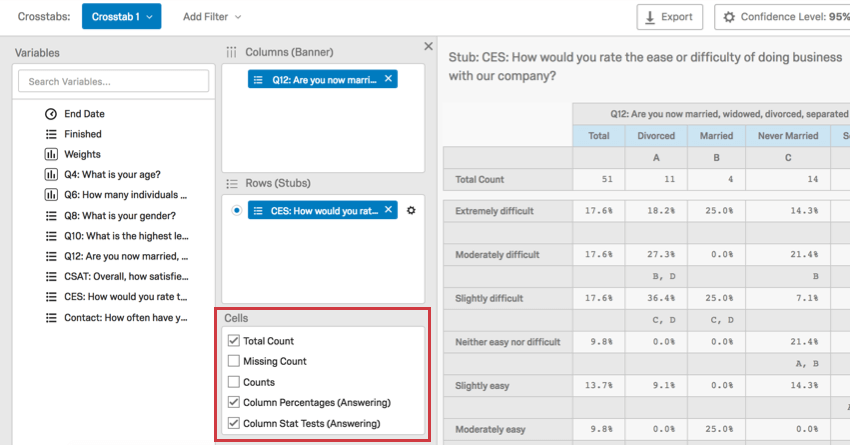
上の図は、以下の要素からなるクロス集計である:
- という欄があり、男性と女性に分かれている。
- という欄があり、教育レベルごとに分かれている。
- という行があり、それぞれの頻度レベルに分かれている。
行に複数のフィールドを追加することはできるが、それらを一度に表示することはできない。行の各フィールドは、選択された列に対して別々の計算で実行されるため、これらの計算は互いに分離されている。行をクリックすると、その行の計算が表示されます。
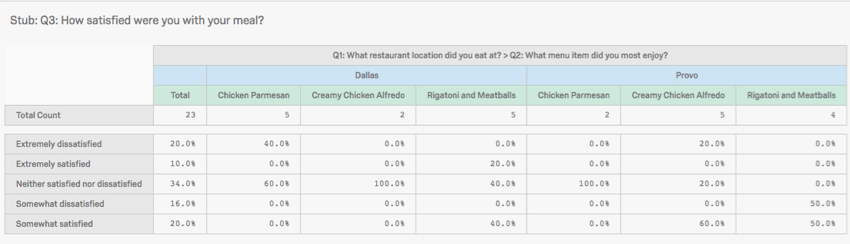
列の入れ子
列を入れ子にすることで、1組の変数を別の変数に分割することができる。つまり、高所得者と低所得者、そして米国とカナダという分け方ではなく、高所得者-米国、高所得者-カナダ、低所得者-米国、低所得者-カナダという分け方になる。
- 列(バナー)の下に最初の変数を追加します。
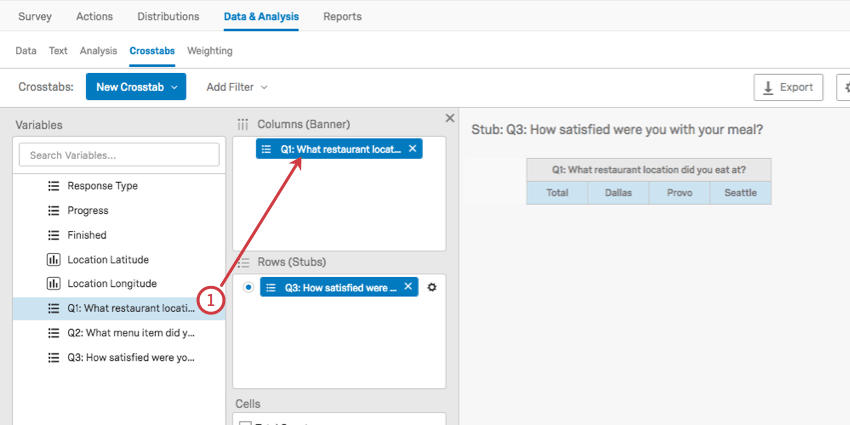
- 2つ目の列の変数を最初の1の上にドラッグする。
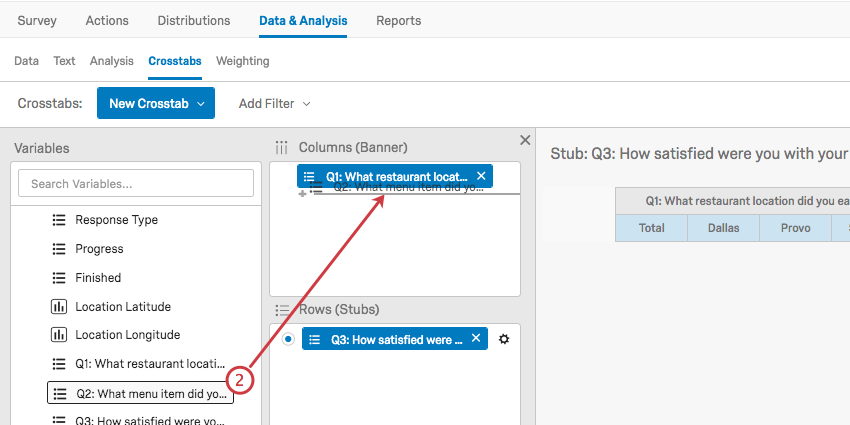
- これが成功すれば、2つ目の変数は1つ目の変数の下にネストされる。
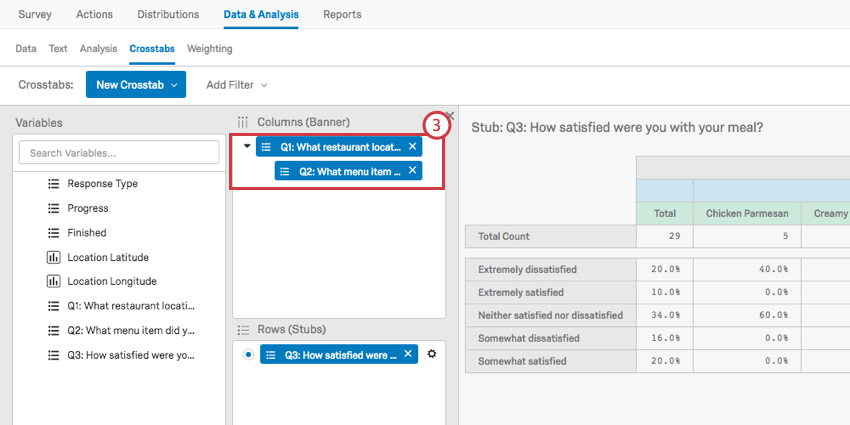
- 行(スタブ)を追加します。
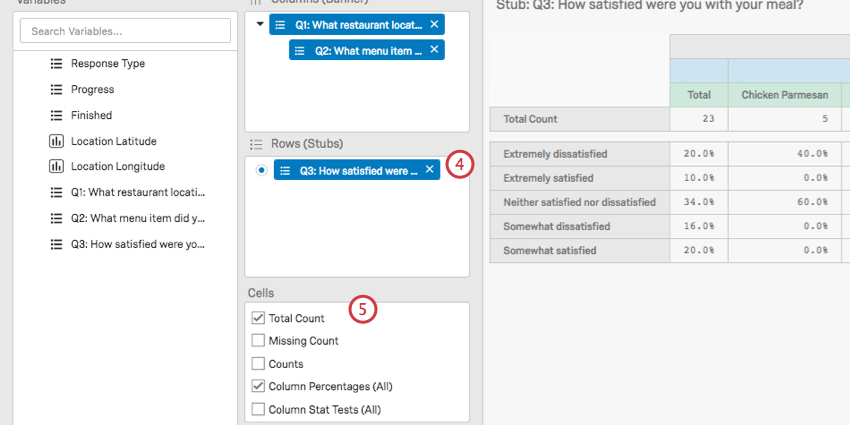
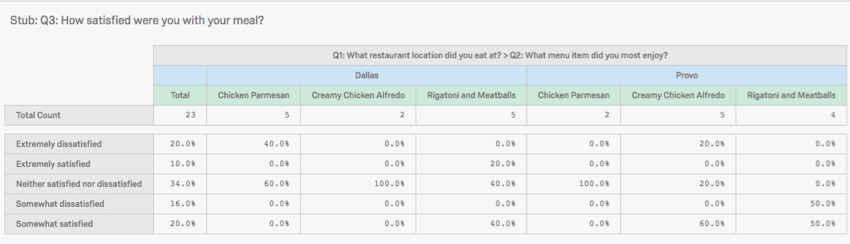
- セルを選択してください。
- クロス集計の列は、可能な回答の組み合わせごとに分割されます。
カスタム・カラムの作成
クロス集計では、回答グループのパターンを分析するために、データポイントを組み合わせた新しい列変数を作成できます。
- Create or Clean Variableをクリックする。
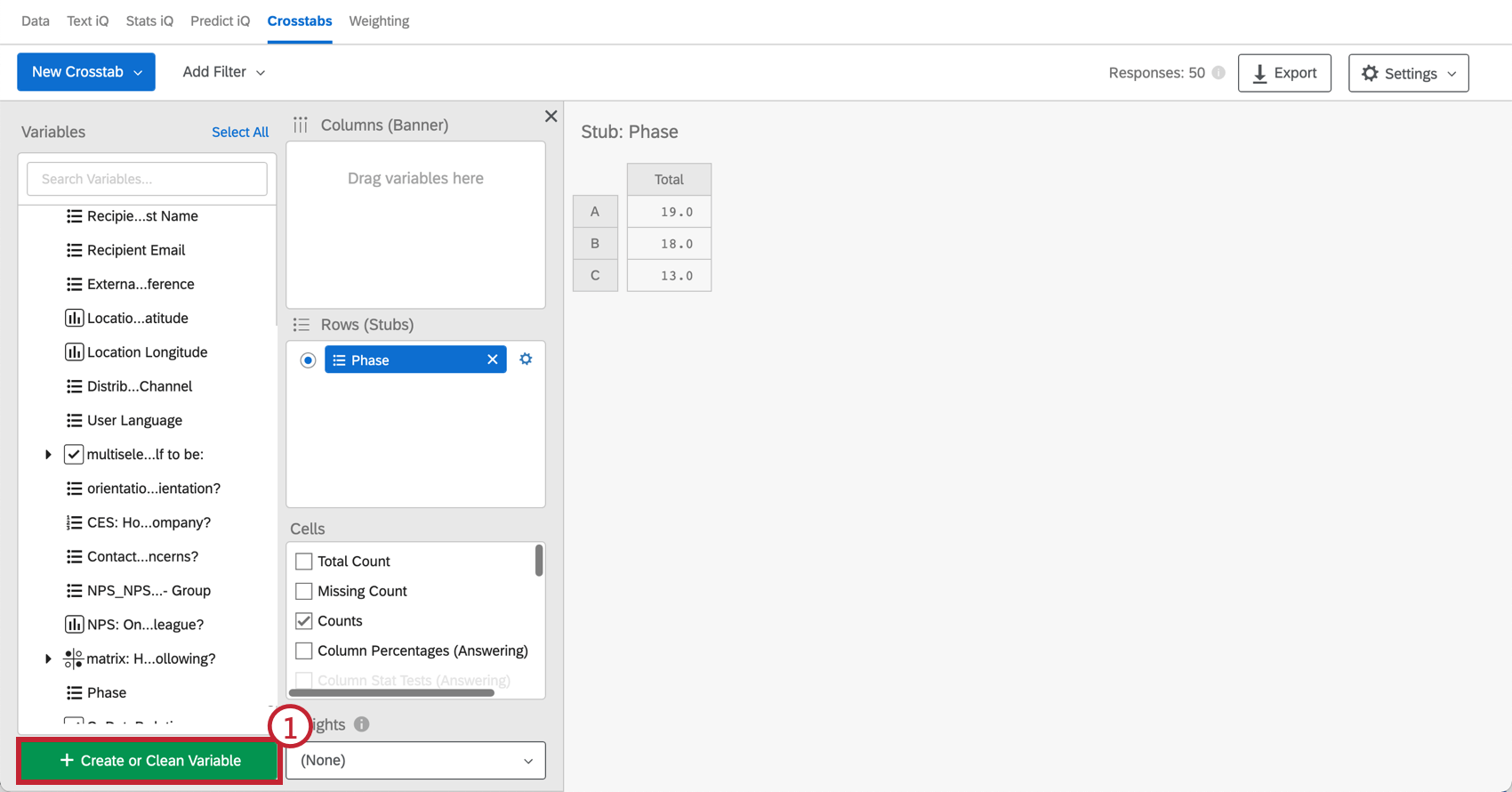
- カスタム・カラムの名前を作成します。
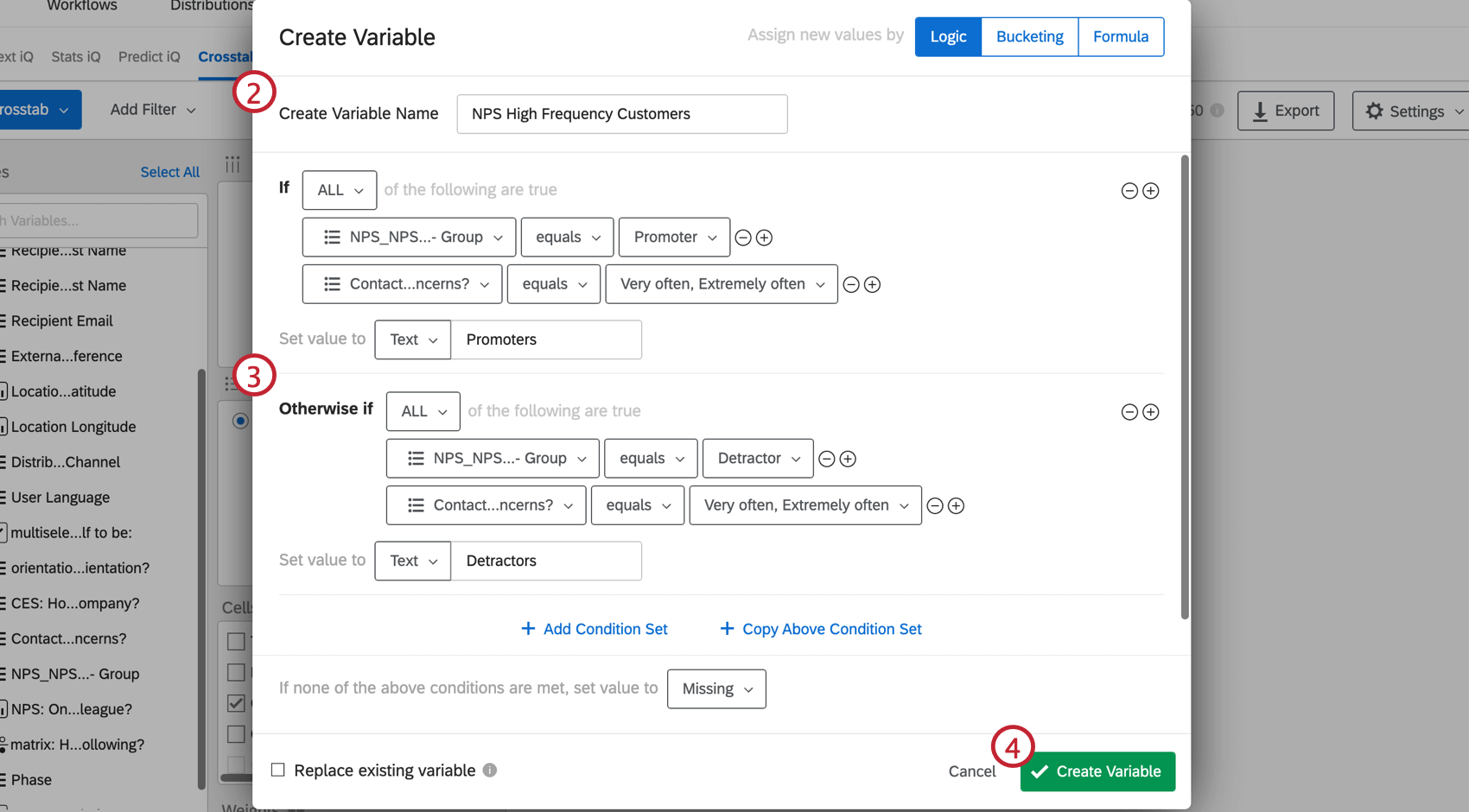
- ロジック・ステートメントを利用して、結合変数を作成する。ロジックを使って新しい変数を作成する方法の詳細については、変数作成のページをご覧ください。
例ウェブサイトを頻繁に訪問する顧客のNpsデータを見たいとします。2つのグループを作り、それぞれのグループは、回答者があなたのウェブサイトを非常に頻繁に、または非常に頻繁に訪問することを条件とすることができます。ただし、第1群はNpsが高く、第2群はNPSが低いことを条件としている。このロジックでは、高頻度訪問者のみを含む変数が2つのNpsグループに分割されます:推奨者と批判者。
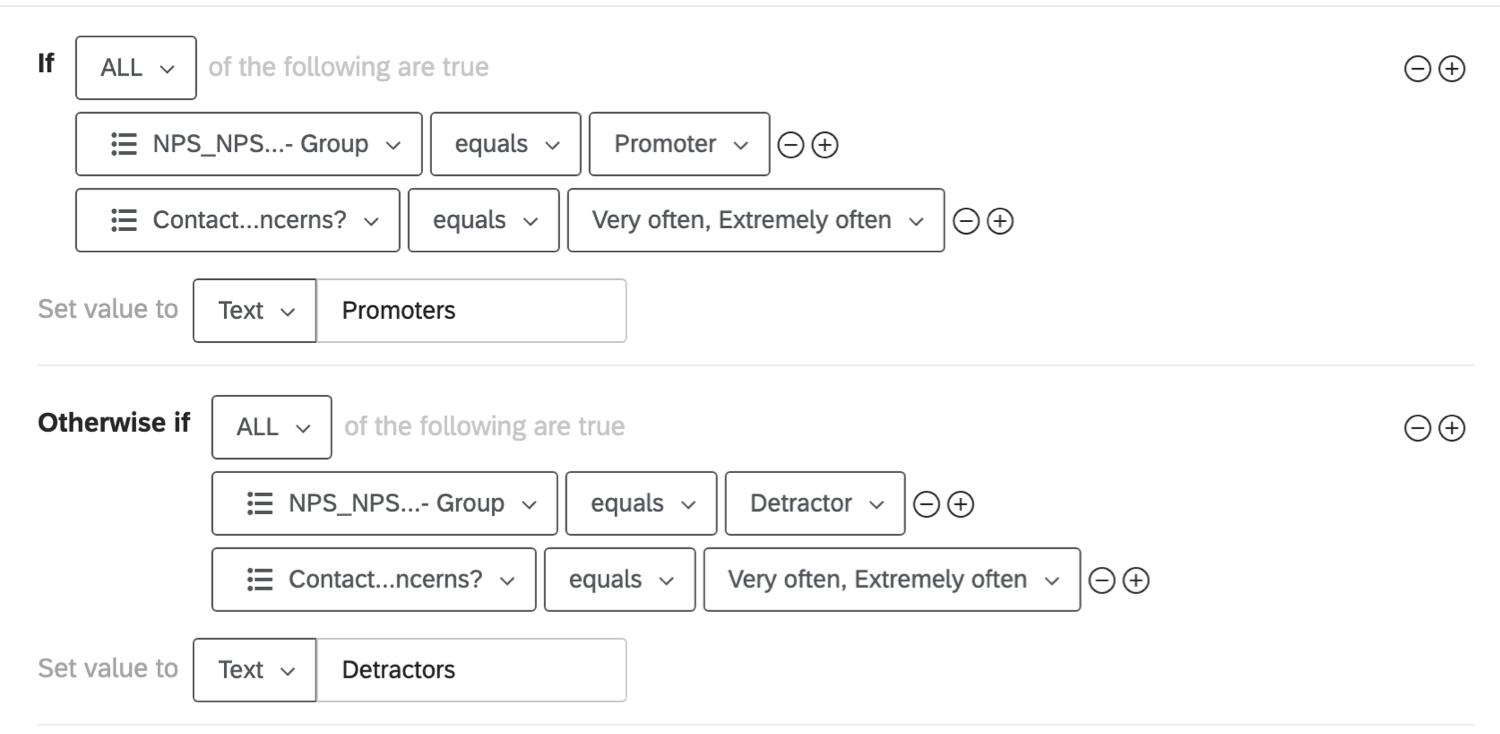
- Create Variableをクリックする。
- 新しい変数は、変数リストの一番下にある。変数を表示するには、それを列(バナー)セクションにドラッグする。
識別値の割り当て
平均を求めたり、ANOVAを行うなど、特定の統計量を生成する前に、クロス集計が変数が数値であることを認識できるように、変数を再コード化する必要があります。
- 再コード化したい列またはバナー変数の次へ歯車をクリックする。
- 必要に応じて選択肢を並べ替えるには、点をクリックして左にドラッグします。これは、選択肢がエスカレーションの少ないものから多いものへと順番に並んでいることを確認するのに役立つ。
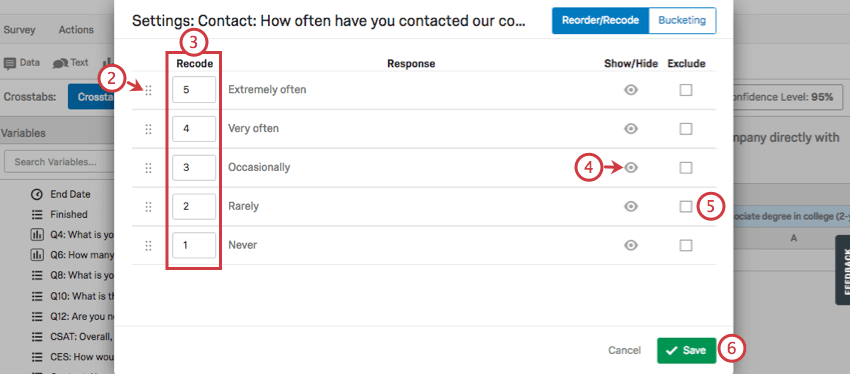
- 各選択肢の値を入力してください。
Qtip:一般的に、これらの値は最も小さいものから最も大きいものへとエスカレートするようにします。したがって、このスクリーンショットでは、「非常によくある」が5で、「まったくない」が1である。
- 目のアイコンをクリックすると、クロス集計のオプションを表示または非表示にできます。これにより、対応する行または列からこのオプションが削除される。
- この選択肢を分析から除外するには、「除外」を選択する。これは “Not Applicable”(該当しない)や “I don’t know”(わからない)という選択肢によく見られる。
- 保存をクリックして終了する。
利用可能な計算
クロス集計で表示できるデータにはさまざまな種類があります。各計算は、列と行を設定した後、Cellフィールドで選択することができます。このセクションでは、各オプションの内容と、それを使用するために満たす必要がある要件について説明します。
標準統計
カラムはカテゴリカルとして扱われますが、行は数値か識別値を割り当てなければなりません。例えば、平均を選択し、列に婚姻状況を追加し、行にCSATを追加すると、平均CSATが婚姻状況別に表示されます。
以下は表示可能な統計情報です。
- 平均
- 中央値
- 標準偏差
- 標準エラー
列数
選択すると、以下の列に回答者数が表示されます。
- 合計数:列と行の両方の質問に回答した人の合計数をリストする列を追加します。
- 未回答数:このアンケートが表示されなかった、またはスキップしたなどの理由で、アンケートの他の部分に答えたが、この質問には答えなかった人の数を示します。クロス集計に列変数がない場合、欠損カウントは行の質問に答えなかった回答者を表します。クロス集計に列変数がある場合、欠損カウントは、行の質問には答えなかったが、列の質問には答えた回答者を表します。
- カウント:列の各カテゴリーから、その行で選択された質問に対して、回答可能な各回答をした人数が表示されます。
- バケット数:選択した行をバケット化した場合、列の各カテゴリーから何人が各バケットに当てはまるかが表示されます。
列の割合
数値は小数点第1位を四捨五入。列の合計はおよそ100%になる。
- 列の割合 (すべて):各列のカテゴリーで、選択された行の各回答をした人の割合を示します。アンケート調査の回答者総数で算出。
- バケット率(すべて): 選択した行をバケットに分類した場合、各列のカテゴリーに属するものが各バケットに属する割合を示す。アンケート調査の回答者総数で算出。
- 列の割合 (回答):これは、表示ロジックが適用されている質問、つまり、質問が表示されないために回答しない回答者がいる場合や、各回答者ごとに多肢選択式の質問がある場合に使用します。各列のカテゴリーで、選択した行の各回答をした人の割合を示す。回答者総数ではなく、質問に対する回答総数を用いて算出。
- バケットパーセンテージ (回答): これは、表示ロジックが適用された質問、つまり、質問が表示されないために回答しない回答者がいる場合や、各回答者ごとに多肢選択式の質問がある場合に使用します。選択した行をバケットに分類した場合、各列のカテゴリーに属する人が各バケットに属する割合を示す。回答者総数ではなく、質問に対する回答総数を用いて算出。
Qtip:列のパーセンテージ(回答)がオプションとして表示されない場合(グレーアウトされているのではなく、リストから完全に除外されていることを意味します)、この機能があなたのアカウントで有効にできるかどうかをサポートに問い合わせることができます。
統計テスト全体のパーセンテージ
パーセンテージの全体統計量検定は、カイ2乗検定として機能する。カイ2乗統計量は、2つのカテゴリー変数の関係を検定する。この検定は、関係が有意か否かを決定するP値を生成する。クロス集計のP値にカーソルを合わせると、検定が有意であったか否かを知ることができる。
例下のスクリーンショットでは、性別と満足度の関係は重要でないことがわかった。
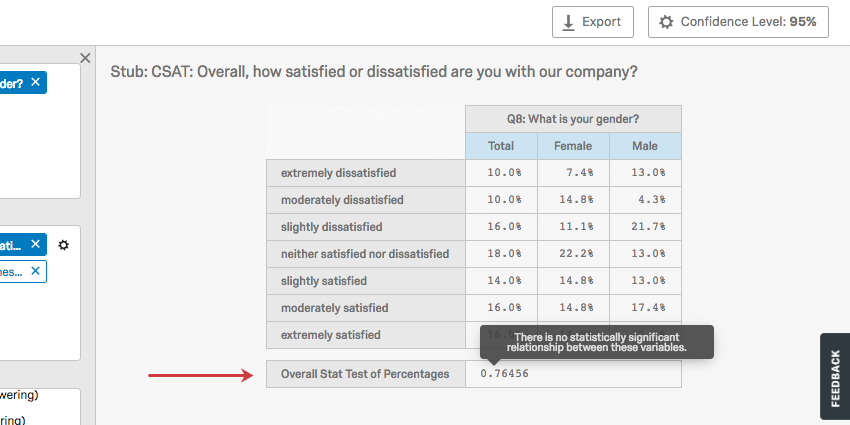
パーセンテージのOverall Stat 検定は、バナーが数値変数で、スタブがカテゴリ変数の場合に最も有用である。信頼水準を調整することで、P値が有意となるタイミングを設定できます。
Qtip:半券を確実にカテゴリー分けするには2つの方法があります:
変数をバケット化し、バケット化されたバージョンでカイ2乗を実施したい場合は、Bucketed Overall Stats Test of Percentages を選択してください。
統計テスト全体の平均
平均の総合統計量検定は,分散分析(ANOVA)として機能する.ANOVA は,2つ以上の平均の間の差を検定することによって,カテゴリ変数と数値変数の間の関係を検定する.この検定は、関係が有意か否かを決定するP値を生成する。クロス集計のP値にカーソルを合わせると、検定が有意であったか否かを知ることができる。
例このANOVAの結果は有意である.
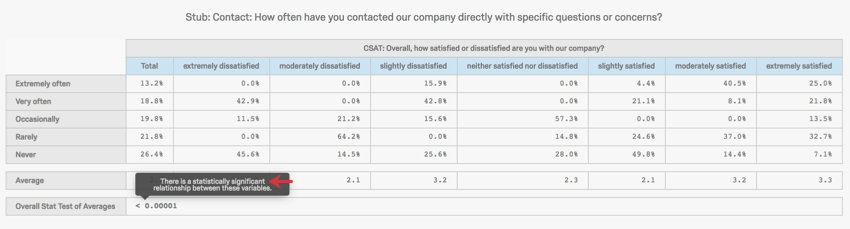
信頼水準を調整することで、P値が有意になるタイミングを設定できる。
列統計検定
列統計検定(すべて)は、一対のz検定である。Z検定は、2つのデータサンプルが互いに異なるかどうかを決定するために標準偏差を使用します。Z検定はT検定に似ているが、サンプルサイズがより大きい(一般に30以上)場合は、Z検定の方が一般的である。
Qtip:Column Stat Tests (All) を選択する前に、Column Percentages (All) を選択してください。
列統計量検定は、バケット列統計量検定(すべて)を選択して、バケット変数で実行できます。
列統計検定(解答)も一対のz検定である。(All)と(Answering)の大きな違いは、(Answering)が回答数に基づくのではなく、質問に対する回答数に基づくことである。これは、表示ロジックが含まれる状況で役に立ちます。回答者が質問を表示しないために、質問に回答しない可能性があるからです。また、多肢選択式の質問では、回答者ごとに質問の選択肢を複数選択することができます。
列の統計テストの平均
列平均の統計検定は、一対のz検定である。Z検定は、2つのデータサンプルが互いに異なるかどうかを決定するために標準偏差を使用します。Z検定はT検定に似ているが、サンプルサイズがより大きい(一般に30以上)場合は、Z検定の方が一般的である。
この場合、列の平均が比較される。
一対のz検定の有意性の解釈
このセクションでは、以下の結果の解釈方法について説明する:
- 列の統計テストの平均
- 列統計テスト(すべて)
- バケットコラムスタッツテスト(全て)
レベルが比較されるとき、設定された信頼水準は、この差が統計的に有意であることをどの程度確信するかを決定するために使用される。どの列が統計的に有意な高い値を持つかを決定するために、すべての列が別の列と比較される。
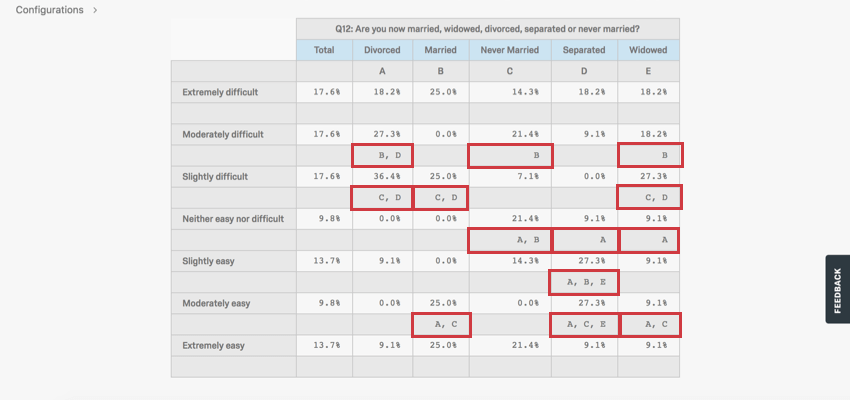
上記の例では、異なる結婚ステータスの回答者が、共通の職場で休暇を申請するのがどの程度簡単であったかを評価している。この結果からいくつかの結論を導き出すことができる。
- A列の「離婚経験者」では、「中程度の難易度」の行にBとDの文字が見える。つまり、既婚回答者(B)と別居回答者(D)は、離婚回答者に比べて、そのプロセスを「中程度に困難」と表現する割合が有意に低かった。
- B列の「既婚者」では、「中程度に難しい」の行が空欄になっている。これは、Bに関する有意な結果がなかったことを意味するものではないが、B列が「中程度に難しい」と評価される例が有意に多いわけではないことを意味する。
- 非常に難しい」の行には文字がない。つまり、”非常に難しい “と評価する夫婦の割合は、他の夫婦の割合よりも少なかったのである。
バケット変数
バケットを使用すると、既存の質問の選択肢を新しいグループにまとめることができます。例えば、回答者がどの国に住んでいるかを尋ねるアンケートを国際配信するとします。データを収集した後、国別ではなく大陸全体の分析をしたいことに気づく。バケットを使えば、各国を大陸ごとにグループ化できるので、その代わりにデータを分析できる。
バケットを設定するまで、名前に “バケット “が付いているセルはどれも利用できない。
- 再コード化したい列または行変数の次へ歯車をクリックする。
- 右上のバケットを選択。
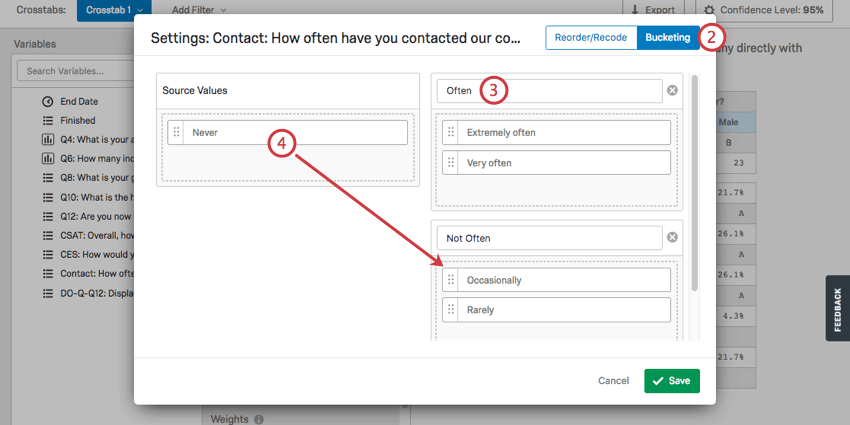
- 希望するグループに名前をつける。
- 左側の値を右側の適切なグループにドラッグする。
- グループを削除するには、名前の次へXをクリックします。
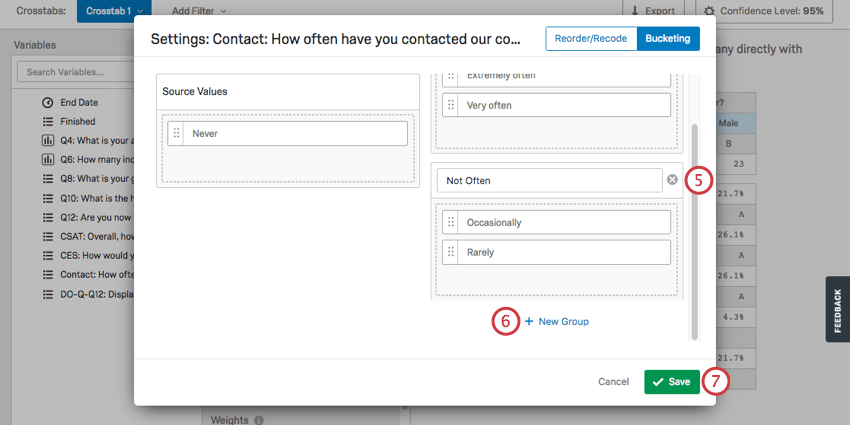
- グループを追加するには、「新規グループ」をクリックします。
- 保存をクリックして終了する。
インポートしたデータをクロス集計で使用する
インポートデータおよび埋め込みデータはクロス集計に対応していますが、最初のクロス集計を作成する前にアンケート調査データに追加する必要があります。クロス集計は、埋め込みデータのテキスト、テキストセット、ナンバーセット、ナンバー、フィルターのみの各フォーマットと互換性があります。