基本変換タスク
このページの内容
基本変換タスクについて
基本変換タスクでは、ローデータを編集、検証し、互換性のある簡略化されたドキュメントにすることができます。データ変換は、パートナーやチームへの送信に適した任意の形式にエクスポートできるよう、データセットを自動的に統一化するのに役立ちます。
ヒント:このタスクはETLワークフローにのみ対応しています。
ヒント:ETLワークフローに適用される一般的な制限については、ワークフローの制限を参照してください。タスク固有の制限については、このページの情報を参照してください
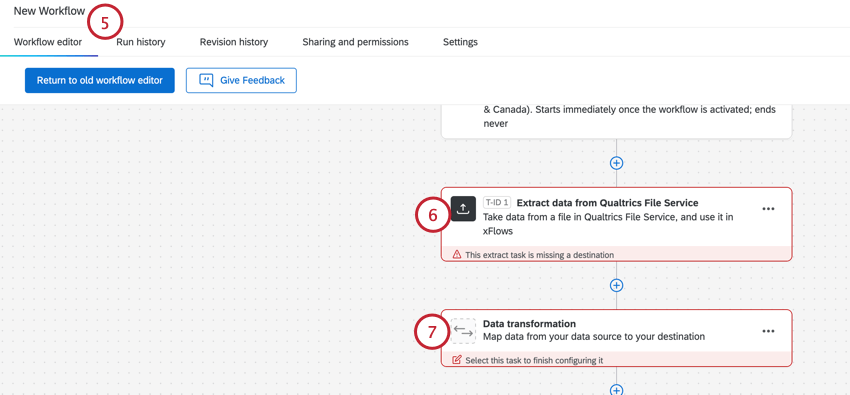
基本変換タスクの設定
![[ワークフロー]ページでETLワークフローを作成](https://www.qualtrics.com/m/assets/support/wp-content/uploads//2023/06/BasicTransformation_1.png)
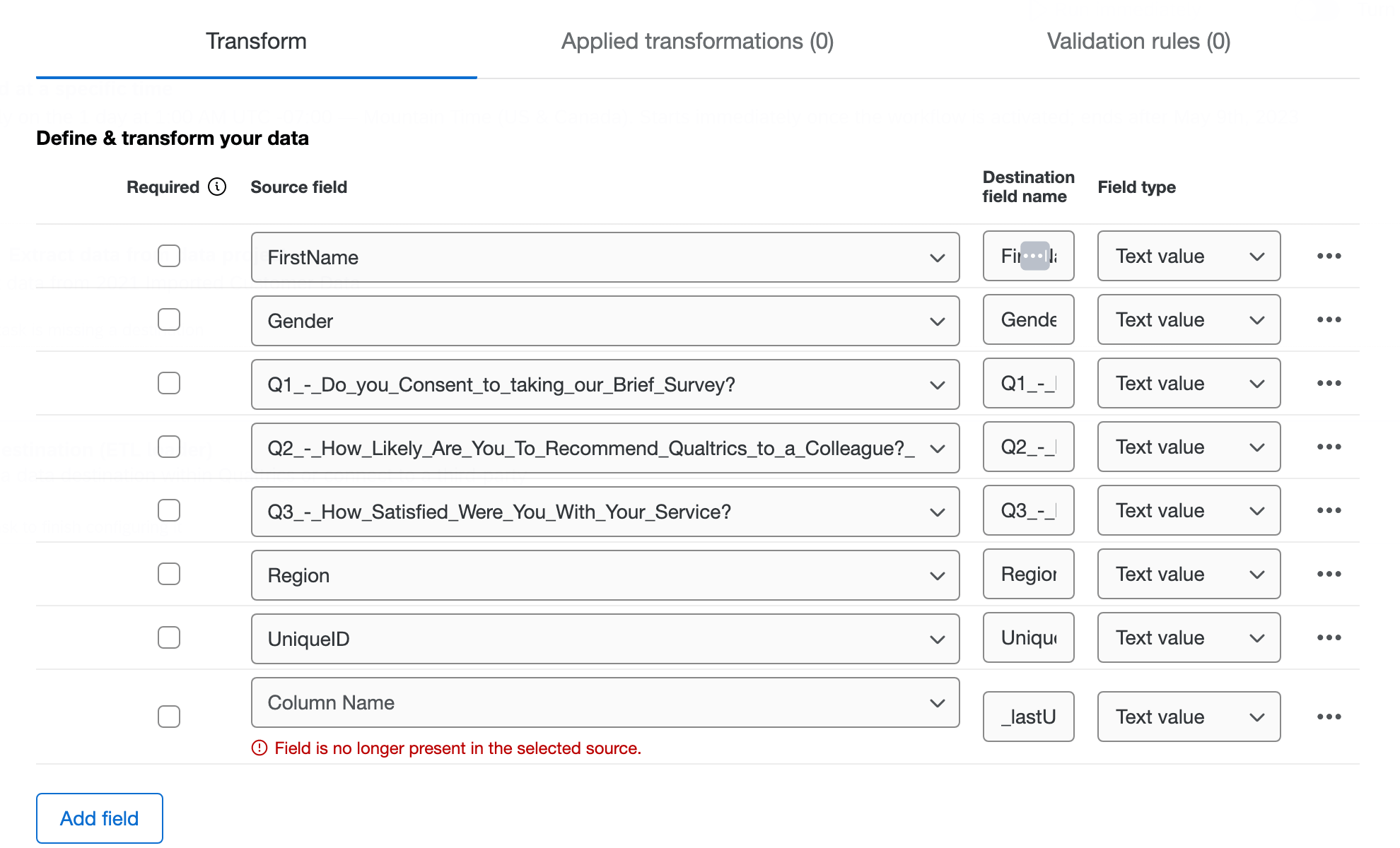
- 必須:このデータが必須な場合は、フィールドの横にあるチェックボックスを選択します。ここににチェックが入っていてそのフィールドにデータがない場合はスキップされます。
- ソースフィールド:抽出タスクのファイルに含まれるフィールドすべてです。新しいフィールドを追加したら、どの列からデータを取得するかをドロップダウンで選択します。
- 宛先フィールド名:変換後のデータセットのフィールド名をどうするかを指定します。ソースファイルのフィールド名とは異なるものに変更したい場合は、この列の名前を編集します。 注意: フィールド名には100文字までの制限があります。

- フィールドタイプ:変換後のデータセット内で抽出したデータをどう扱うかを指定します。フィールドタイプによって、利用できる変換の操作が決まります。
注意: 抽出タスクが会話データを抽出する際、クアルトリクス会話フォーマットフィールドタイプを持つ[トランスクリプトコンテンツ]というソースフィールドが存在します。このフィールドタイプを持つフィールドは変換できない。
![強調表示された[データを変換]とデータ変換のオプションを表示する3点リーダーメニュー。[フィールドを追加]も強調表示](https://www.qualtrics.com/m/assets/support/wp-content/uploads//2023/06/BasicTransformation_6.png)
ヒント:フィールド名の左にマウスカーソルを合わせ、表示されるアイコンをクリックしてフィールドをドラッグすると、フィールドを並べ替えることができます。基本変換タスクでフィールドを並び替えるのは、ETLワークフローのフィールドの順序を変更する唯一の方法です。
![強調表示された[適用済みの変換]タブ](https://www.qualtrics.com/m/assets/support/wp-content/uploads//2023/06/BasicTransformation_7.png)
ヒント: [適用済みの変換]タブに表示された順番、つまり設定された順番で操作が実行されます。同じフィールドに複数の操作が設定されている場合、後続の操作は前の操作の結果に基づいて計算されます。
ヒント: 変換の際にエラーが発生した場合(フィールドの形式が無効な場合など)、その行の後続の操作はすべてスキップされます。
データ変換
フィールドで利用できる変換操作は、宛先のフィールドタイプによって異なります。
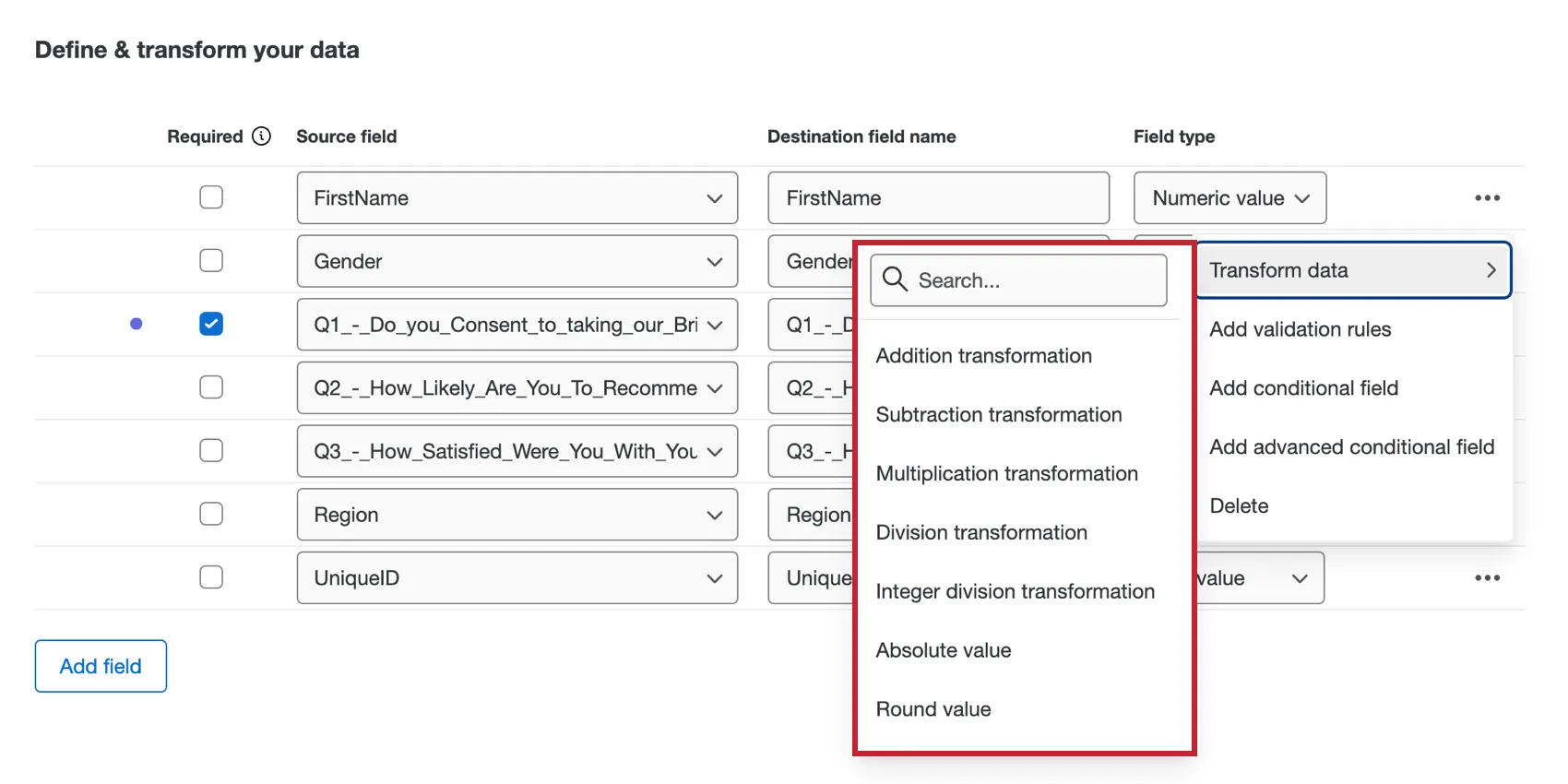
テキスト値、テキストセット、オープンテキストのフィールドでは次の変換を利用できます。
- 接頭辞を追加:各値の先頭にテキストを追加します。
- 接尾辞を追加:各値の末尾にテキストを追加します。
- 連結:複数のフィールドの値を連結します。
- 大文字小文字の形式を設定:フィールド内のすべての値に大文字小文字のある形式(例:UPPERCASE)を適用します。
- マップ値:一致する値に基づいてインプット値を特定のアウトプットにマッピングします。一致しない値についてはオプションでデフォルト値を設定できます。
- 値を置き換え:フィールド内の値を検索して置換します。
- 分割:元のフィールドを区切り文字で分けられた複数のフィールドに分割します。
- 文字数で区切る:先頭または末尾からの文字数を指定して、テキストを2つのフィールドに分割します。
- 部分文字列変換:開始インデックスと終了インデックスを指定して、フィールド内のテキストから部分文字列を作成します。
- 値をトリミング:フィールド内のテキストの先頭、末尾、または両端から指定した文字列または空白を削除します。
複数値のテキストセットフィールドでは、次の変換を利用できます。
- 接頭辞を追加:各値の先頭にテキストを追加します。
- 接尾辞を追加:各値の末尾にテキストを追加します。
- 連結:複数のフィールドの値を連結します。
- 大文字小文字の形式を設定:フィールド内のすべての値に大文字小文字のある形式(例:UPPERCASE)を適用します。
- 値を置き換え:フィールド内の値を検索して置換します。
- 分割:元のフィールドを区切り文字で分けられた複数のフィールドに分割します。
ヒント:複数値のテキストセットフィールドに対する変換は、区切り文字としてコンマを使用するCSVファイルとのみ互換性があります。複数値フィールドにコンマが含まれる場合は、正しい書式を維持するためにバックスラッシュ(\)を含める必要があります。例えば、コンマを含むデータフィールドが2つある場合(例:Doe, JohnとDoe, Jane)、いずれも変換が加えられた4つの別々のフィールドとして処理されます(例:Doe, John, Doe, Jane)。各値のコンマにバックスラッシュを追加すると、データは分離されず、変換処理は2つのフィールドに対して行われます(例:Doe\,JohnとDoe\,Jane)。
数値と数値セットフィールドでは、次の変換を利用できます。
- 絶対値:フィールドの各数値の絶対値を取得します。
- 加算変換:フィールドの各数値に一定の値を足すか、2つのフィールドを加算します。
- 値の平均:各回答について、選択したフィールドの数値の平均を取ります。
- 除算変換:フィールドの各数値を一定の値で割るか、フィールドを別のフィールドで割ります。
- 整数の除算変換:フィールドの各数値を一定の値で割るか、フィールドを別のフィールドで割ります。返すのは整数(integer)のみです。
- 値の最大値:各回答について、選択したフィールドの最大値を取ります。
- 値の中央値:各回答について、選択したフィールドの中央値を取ります。
- 値の最小値:各回答について、選択したフィールドの最小値を取ります。
- 乗算変換:フィールドの各数値に一定の値を掛けるか、2つのフィールドを掛け合わせます。
- 値を丸める:フィールド内のすべての値を切り上げるか切り捨てます。
- 減算変換:フィールドの各数値から一定の値を引くか、フィールドから別のフィールドを引きます。
- 値の合計:各回答について、選択したフィールドの値の合計を取ります。
日付フィールドでは、次の変換を利用できます。
- 日付計算:現在のソースの日付から別の日付までの経過時間を返します。
- 曜日変換:現在のソースの日付からその曜日を判定します。
- 日付/時刻のオフセット:日付/時刻を、指定した時間の分オフセットする。たとえば、インタラクションから5日後の日付を計算できます。
ヒント:オフセットを使う場合、未来の1日も過去の1日も、今日として扱われます。
ヒント:クアルトリクスのシステムはUTCタイムゾーンを使用します。すべての日付の計算とオフセットはUTCに基づいて行われます。
日付/時刻のカスタム書式を入力する場合、次の書式オプションを利用できます。
- 年:yy、yyyy
- 月M、MM、MMM、MMMM
- 日:d、dd
- 年における曜日:DDD
- 午前/午後の時間:K、KK
- 1日の時間:HH
- 分:m、mm
- 秒:s、ss
- 分数秒:S、SS、SSS
- タイムゾーンオフセット:ZZZZ、ZZ:ZZ(+/-を含むことができる)
- 午前/午後:a
- 曜日:E、EE
- タイムゾーン形式:z
ヒント:1ヶ月には30日あるものとして扱われます。
データ検証
検証ルールを追加すると、フィールドのデータが必ず同じ形式となるよう基準や条件を作成することができます。たとえば、無効な電子メールアドレスを持つレコードを削除したいとします。
![[検証ルールを追加]が強調表示された3点リーダーメニュー](https://www.qualtrics.com/m/assets/support/wp-content/uploads//2023/06/BasicTransformation_9.png)
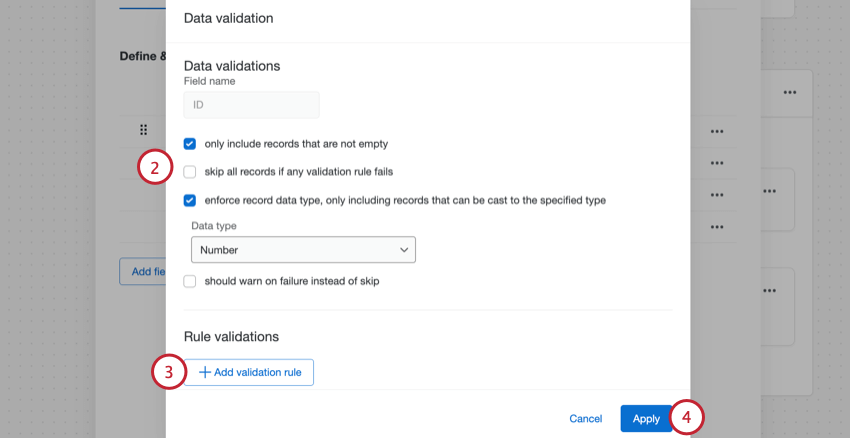
- 空ではないレコードのみを含める:選択したフィールドが空の回答を省きたい場合は、このオプションを有効にします。この設定は、変換テーブルの必須の列と同じ機能を果たします。
- 検証ルールが失敗した場合、すべてのレコードをスキップ:いずれかの検証ルールが失敗した場合、すべてのレコードがスキップされます。
- 指定したタイプにキャストできるレコードのみを含むレコードデータタイプを強制:特定のデータ形式を持つレコードのみを含めます。たとえば、テキスト値の場合、そのデータが数値であるべきかテキスト形式であるべきかを選択できます。このオプションを有効にすると、下の2つ目のオプションが利用できるようになります。
- 失敗した場合はスキップする代わりに警告を表示:このオプションを有効にすると、検証基準を満たさないレコードもデータセットに含まれるようになります。行レポートには、回答がこの基準を見たさなかったことを示す警告が表示されます。このチェックを外すと、そのレコードはスキップされ、新しいデータセットには含まれなくなります。[検証ルールが失敗した場合、すべてのレコードをスキップ]を有効にしている場合は、このオプションを選択することはできません。
検証ルール
検証ルールを追加すると、フィールドのデータを条件に従って検証できます。条件構築の詳細については、「条件構築の基礎」を参照してください。
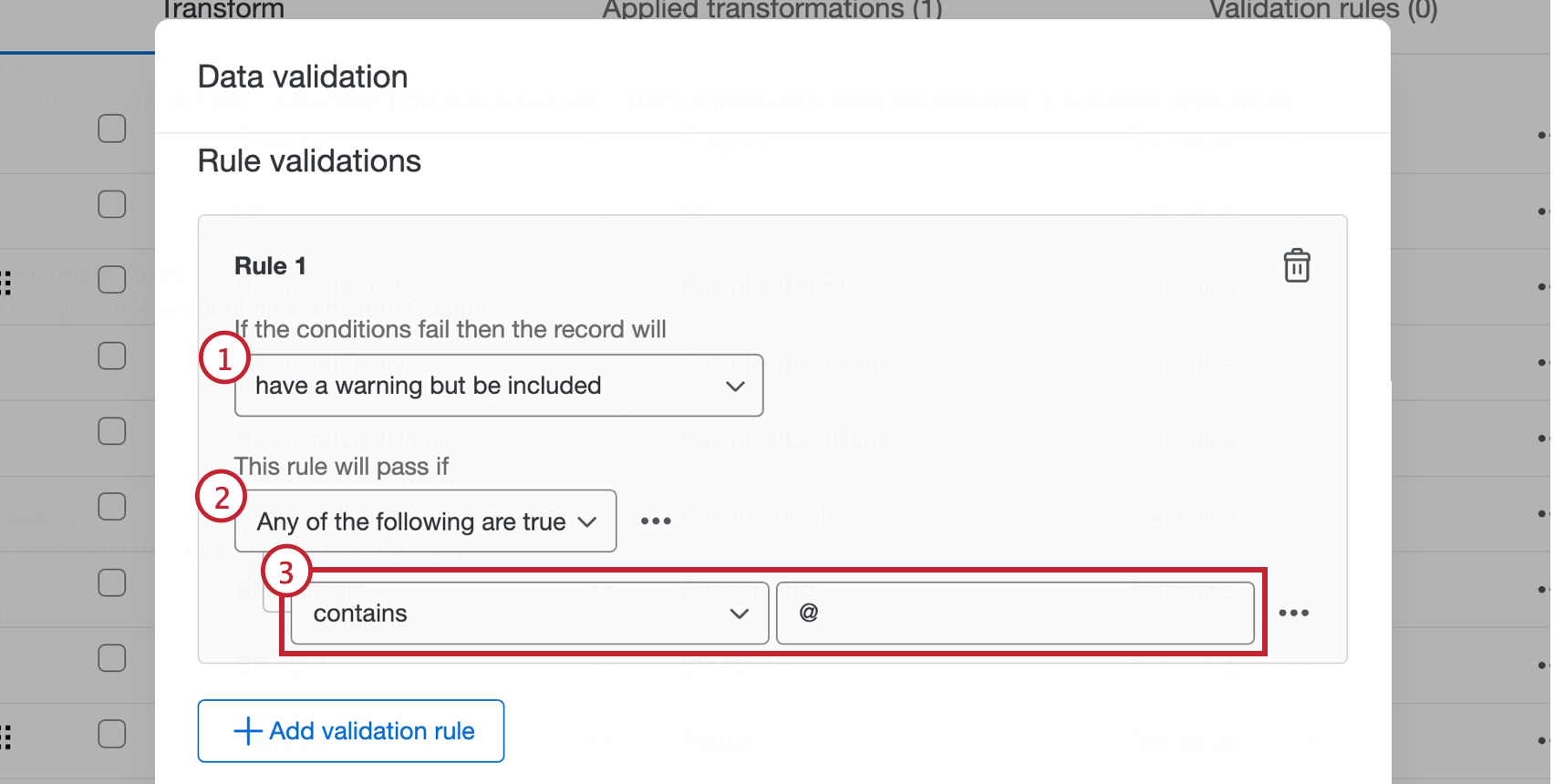
ヒント:別のコンディションを作成したり、既存のコンディションを削除するには、右側の3点リーダーメニューをクリックします。
ヒント:検証ルールを削除するにはごみ箱をクリックします。
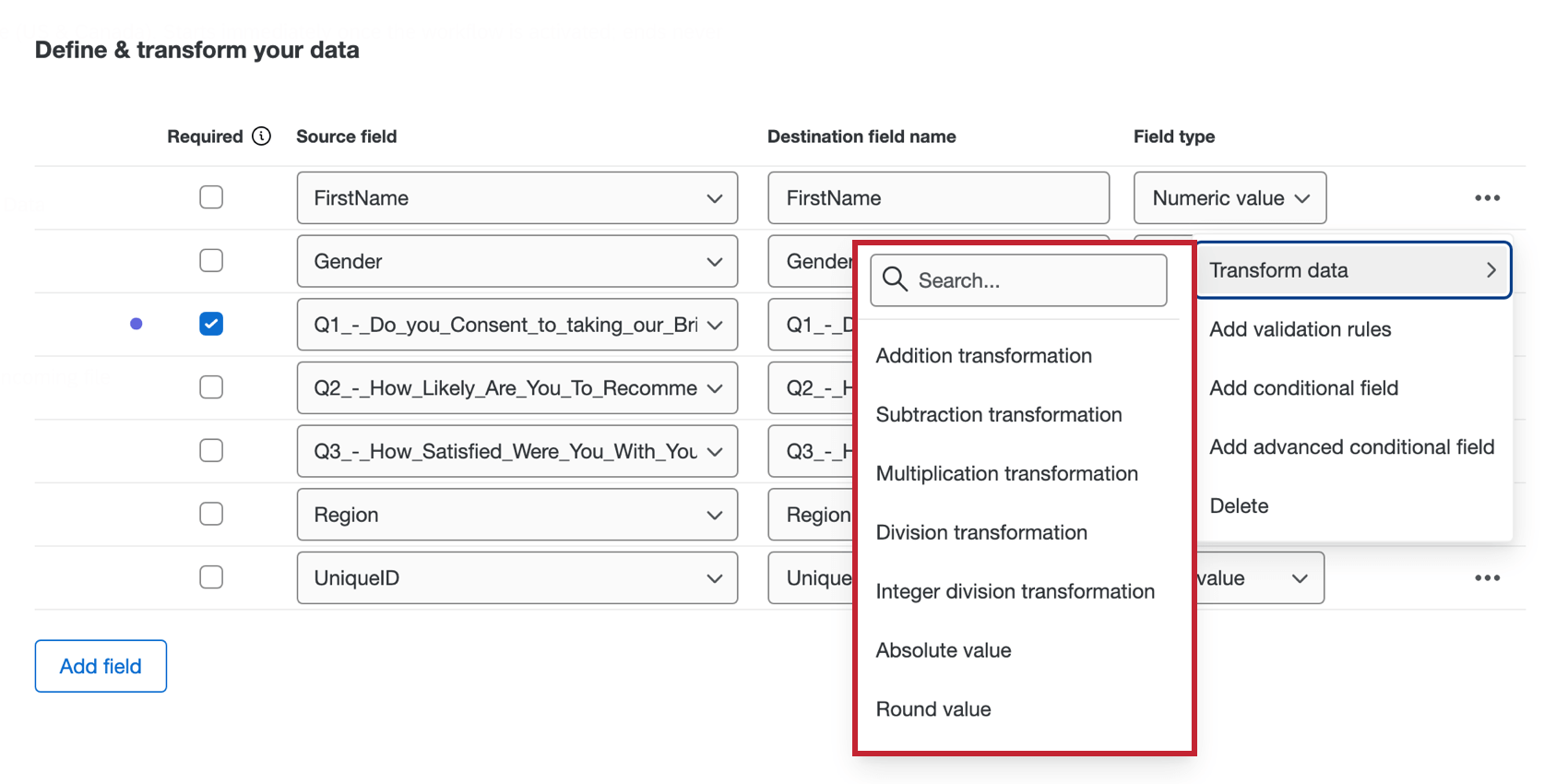
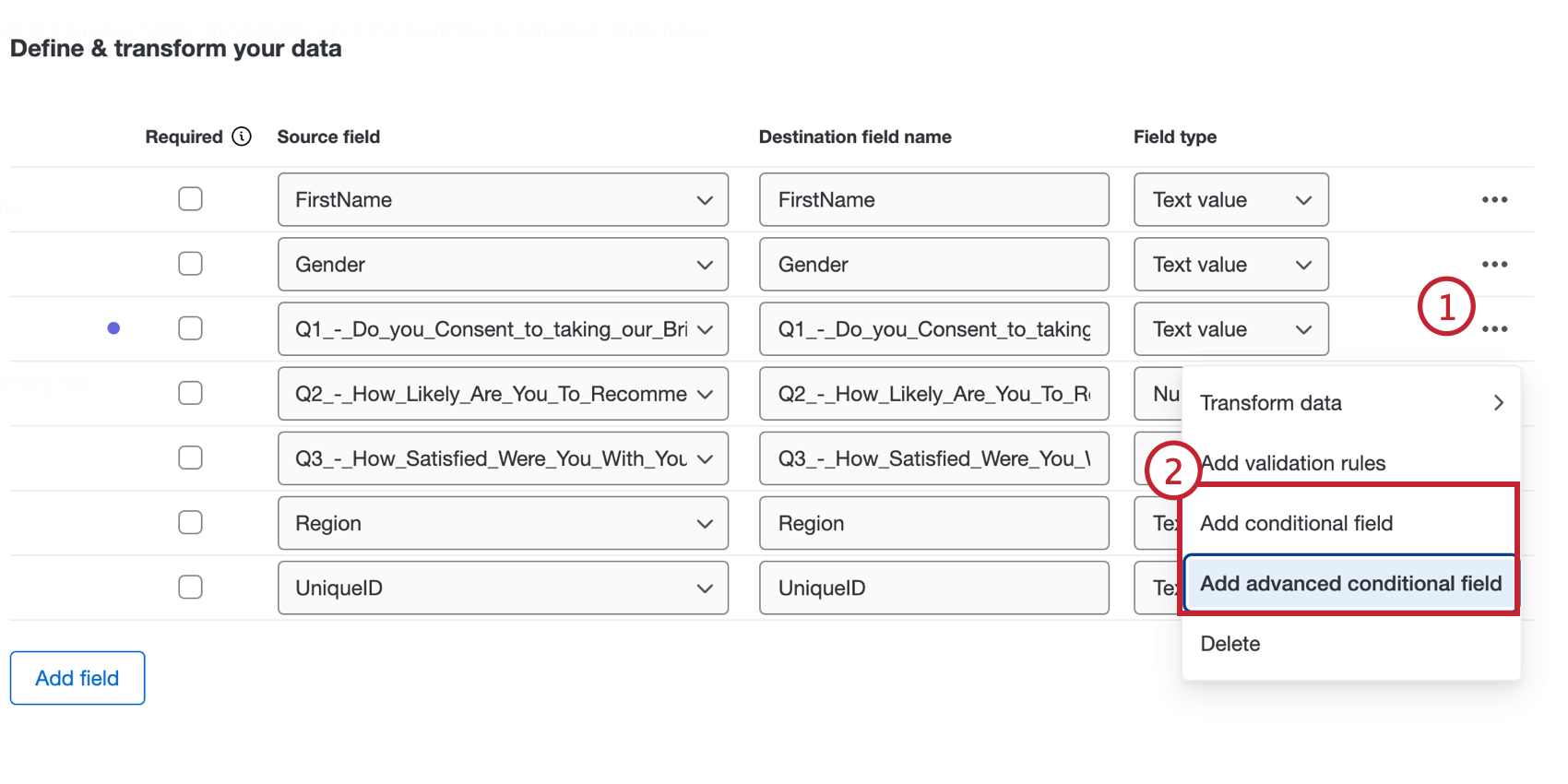
条件付きフィールド
条件付きフィールドを作成するには、ほかのフィールドを利用してフィールドの作成方法を指定するロジック条件を設定します。ソースフィールドの右にある3点リーダーメニューから条件フィールドを追加します。条件構築の詳細については、「条件構築の基礎」を参照してください。
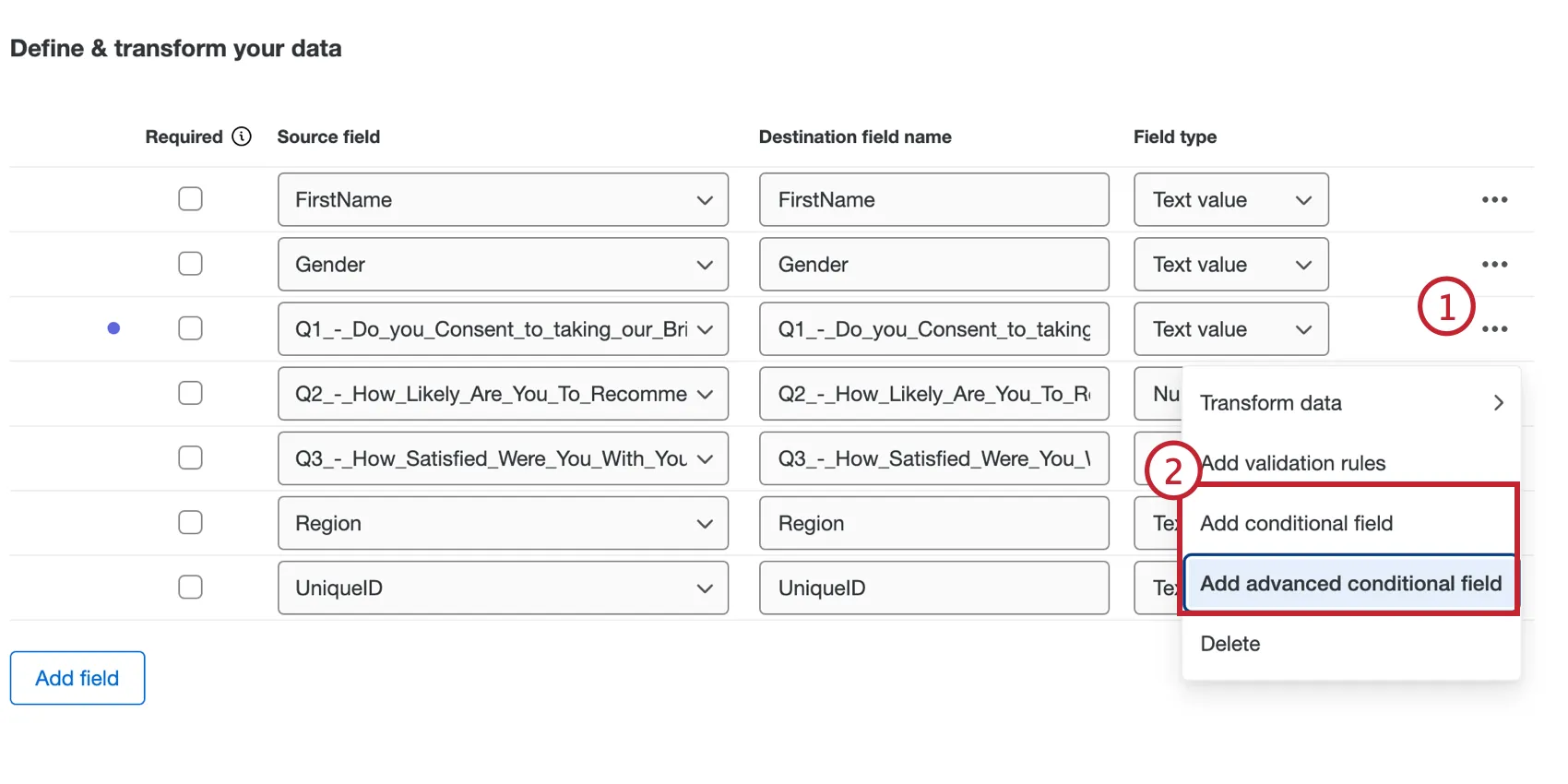
条件付きフィールド
条件付きフィールドは、1つの論理条件に基づいて新しいフィールドを作成します。
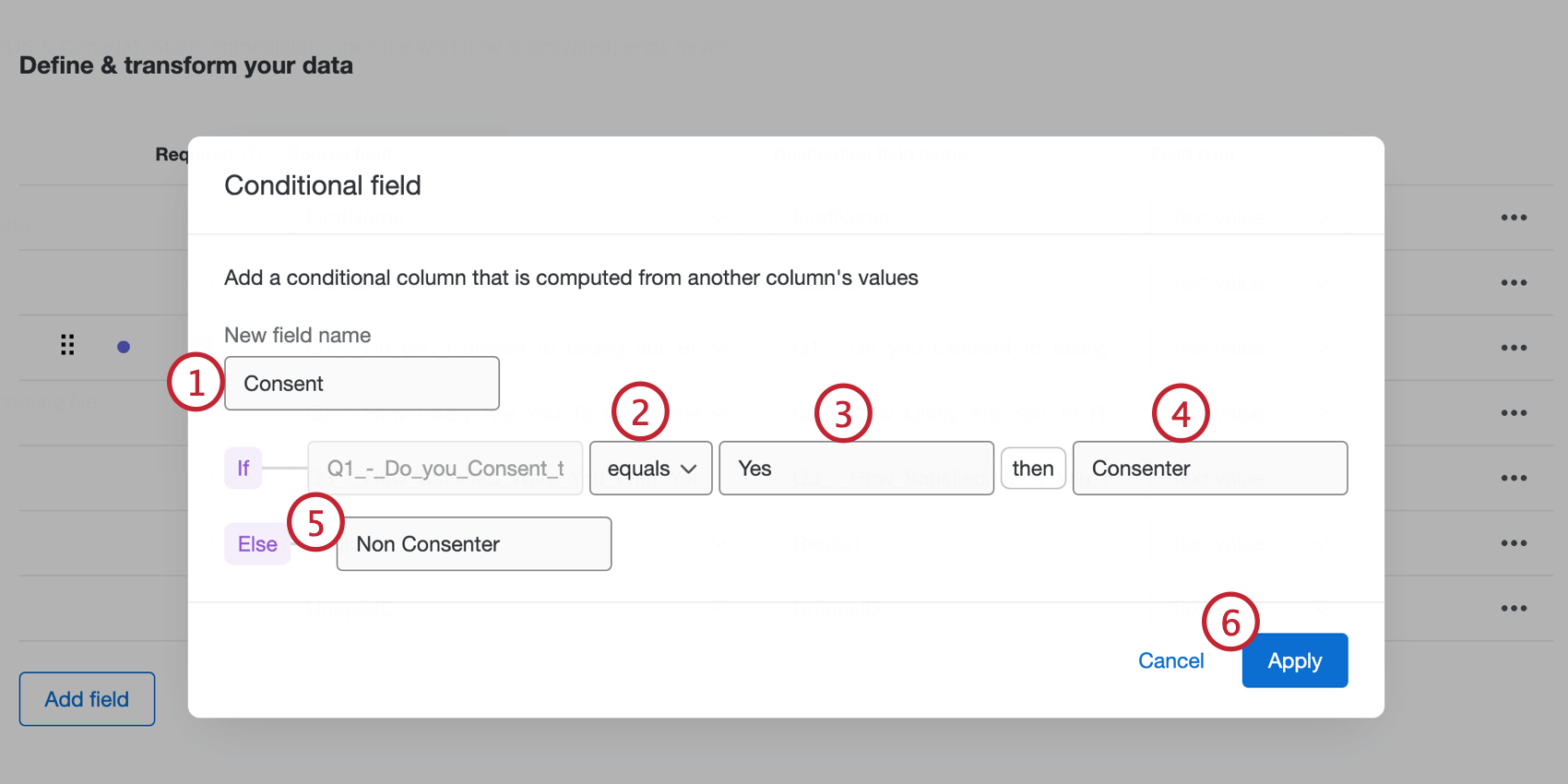
例: 「このアンケートに回答することに同意しますか?」という質問に対する回答者の答えに基づいて、「同意者」または「非同意者」のフィールドを作成したいとします。この場合、条件付きフィールドを作成し、回答が「はい」の場合に値を「同意者」とするロジックを定義します。
詳細条件付きフィールド
詳細条件付きフィールドは、複数の論理条件または条件セットに基づいて新しいフィールドを作成します。
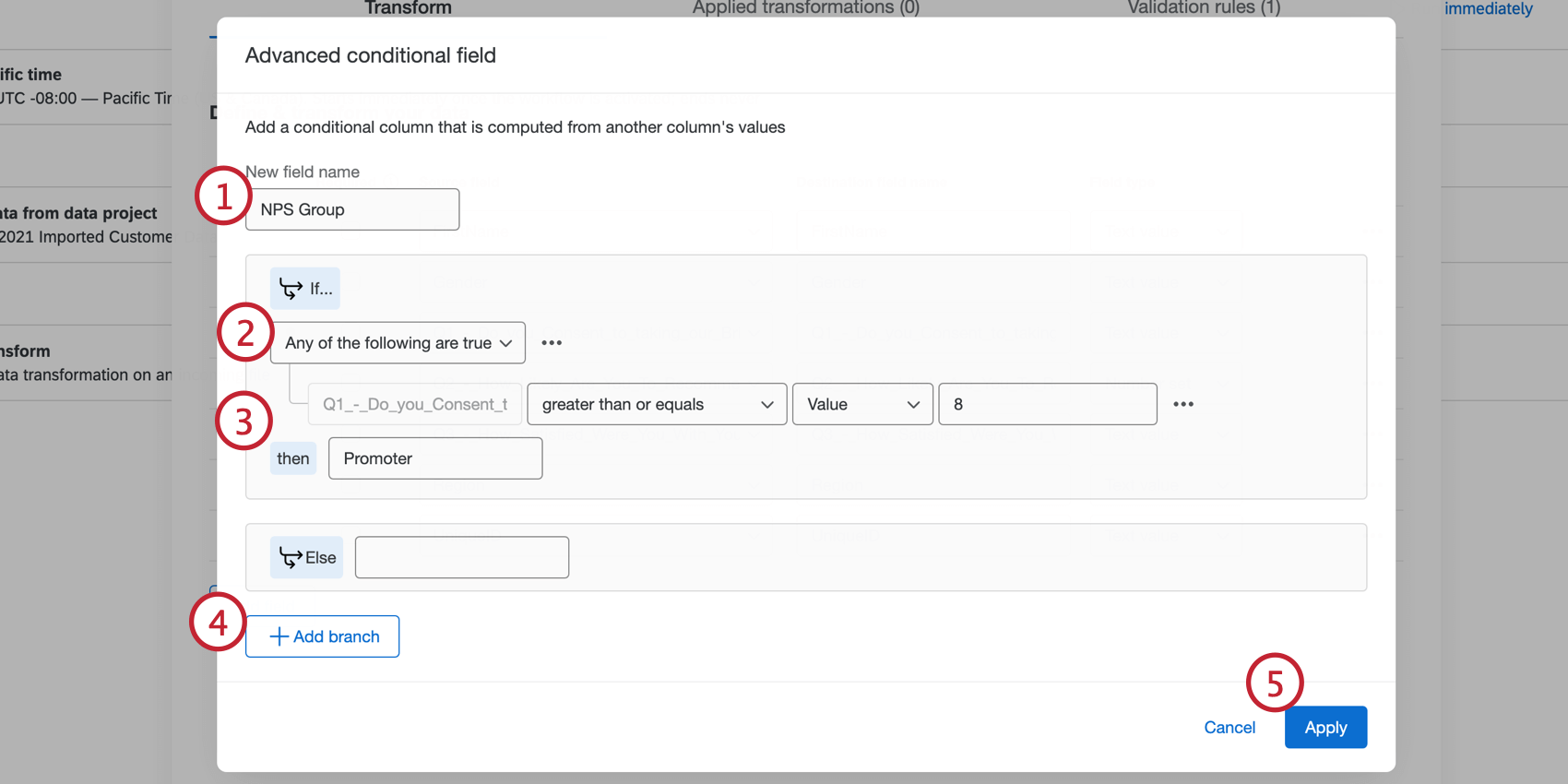
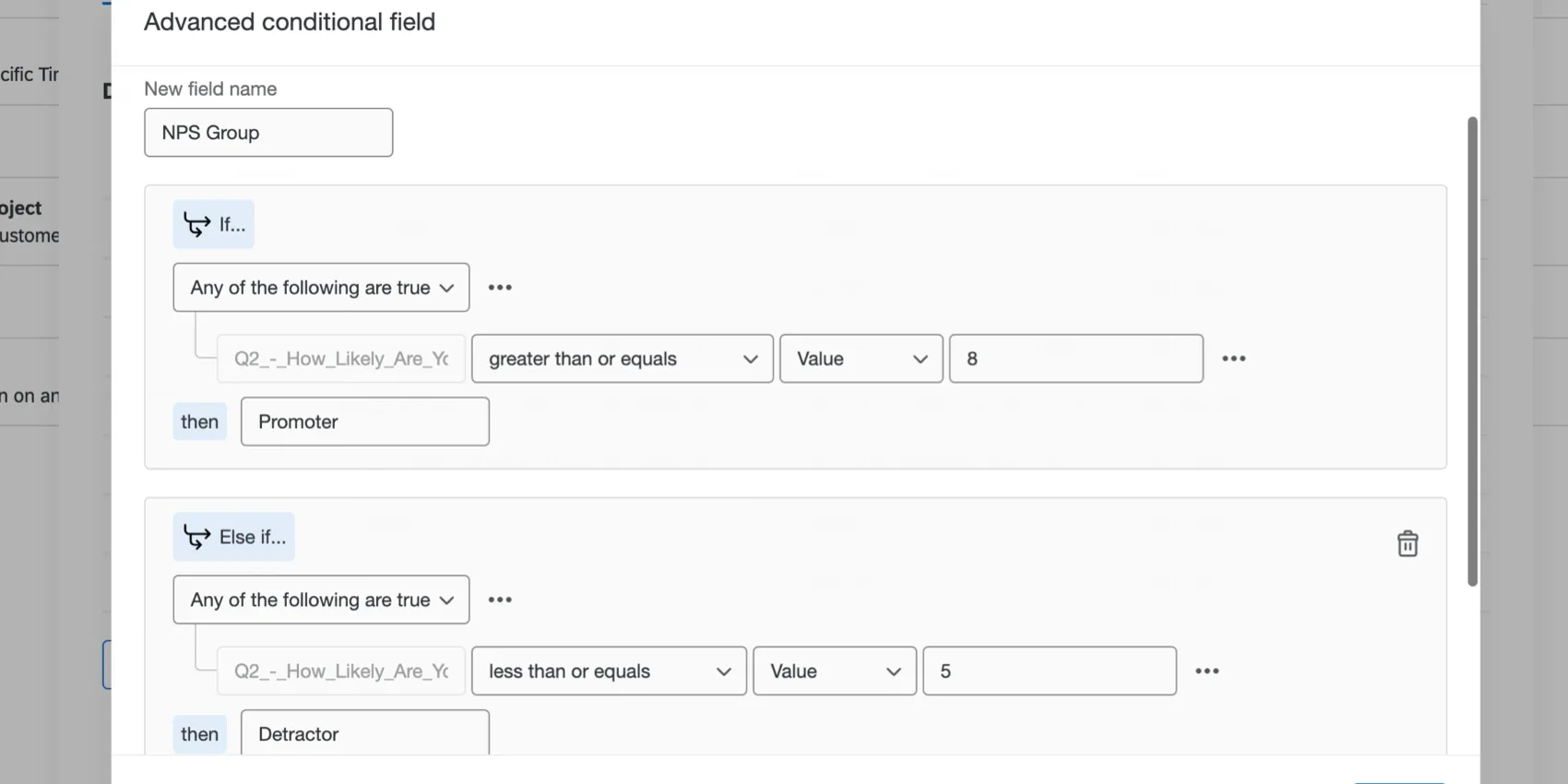
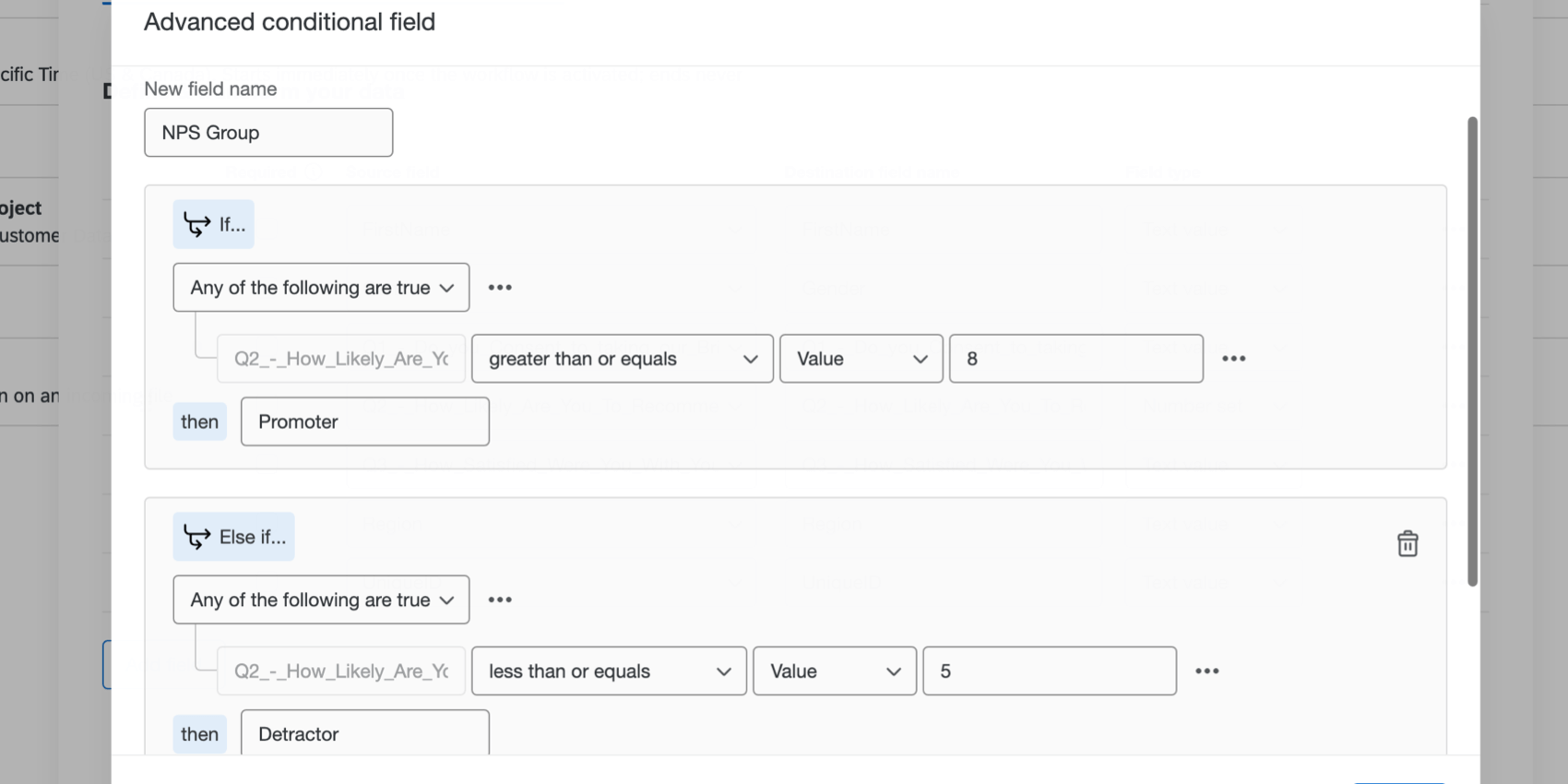
Qtip:15分岐までという制限があります。
例: 回答者が10ポイントの満足度の質問にどのように答えたかに基づいて、「推奨者」または「批判者」のフィールドを作成したいとします。この場合、詳細条件付きフィールドを作成し、Q2が「8以上」の場合に値を「推奨者」とし、Q2が「5以下」の場合に値を「批判者」とする条件を定義します。
{kind=link}
{kind=link}
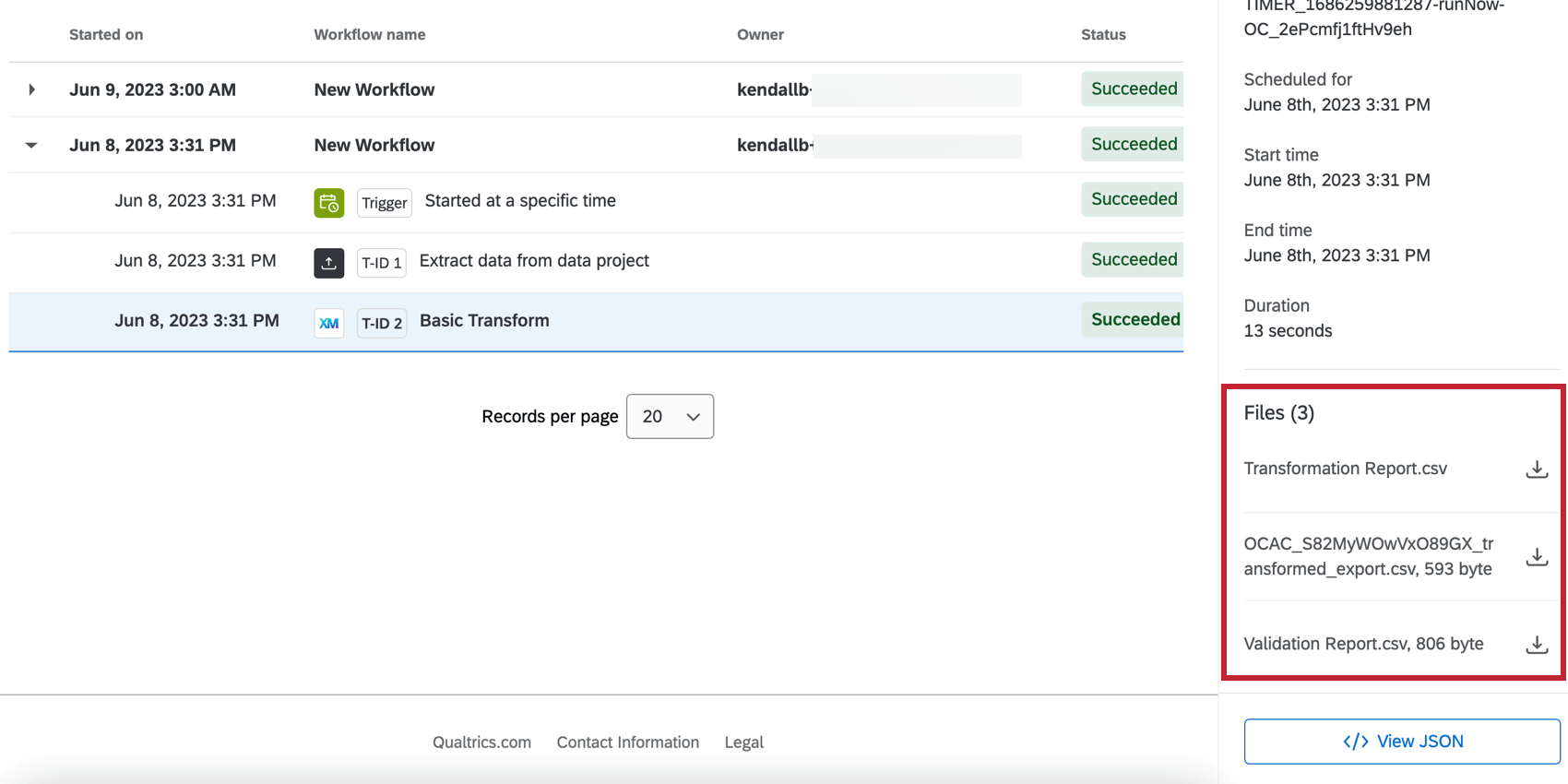
変換後のファイルとレポート
基本変換タスクは、変換後のデータセットを理解するのに役立つ2つのレポートとともに、変換されたファイルを生成します。ワークフローエディターの実行履歴タブで、ワークフロー実行内の基本変換タスクをクリックすると、右側にファイルが表示されます。これらのファイルは、右側にあるダウンロードアイコンをクリックしてエクスポートすることができます。
{kind=link}
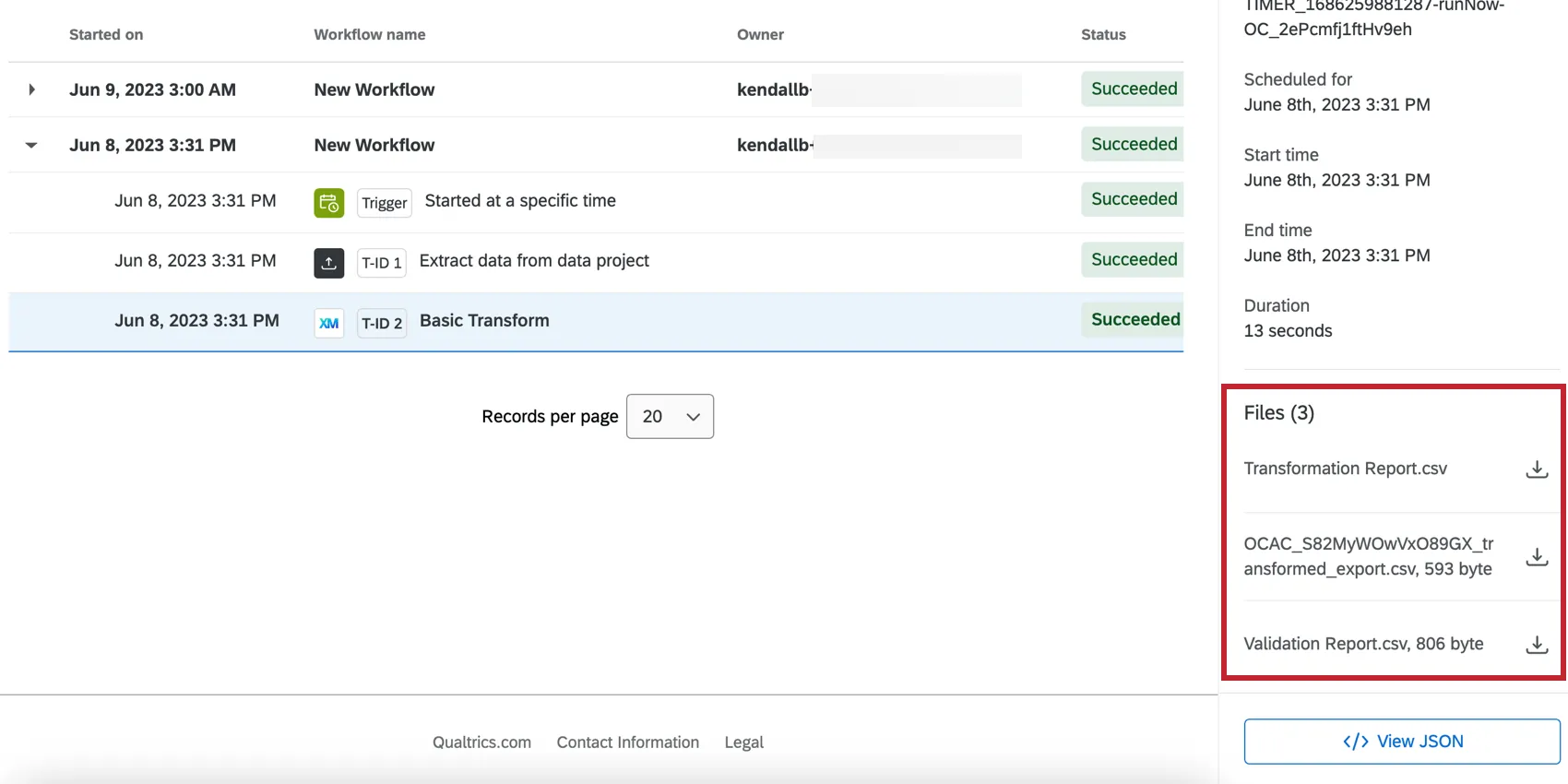
- 変換レポート:ソースファイル内のレコードに対して実行されたすべての変換と、その名前、行番号、ステータス、失敗理由などの詳細。
- 変換ファイル:データ変換の結果。すべての変換および検証が適用された、新しいデータセットを含む。
- 検証レポート:実行された検証のレポート。レコードが除外されたかどうか、また不合格だった検証を含みます。
トラブルシューティング
- ファイルサイズの制限:基本変換タスクが生成するファイルが1GBを超えた場合、ワークフローは失敗します。
- 変換によるファイルサイズの増大:データをどのように変換するかによって、基本変換タスクがファイルにより多くのデータを追加する可能性があります。抽出するファイルがすでに1GBの制限に近い場合、変換によってファイルが大きくなりすぎて処理できなくなる可能性があることに注意してください。
- アンケートフィールドの欠落:ETLが、基本変換タスクの前にアンケートから回答を抽出するタスクで始まる場合、アンケートフィールドが欠落していることに気付くことがあります。これは、アンケートに新しいフィールドを追加した場合、抽出タスクを再度保存してから変換タスクにフィールドを追加する必要があるためです。これを解決するには
- アンケートから回答を抽出タスクを開きます。
- アンケートの列で、新しいフィールドを選択します。([すべてのフィールドをダウンロード]を選択している場合は、次の手順に進み、タスクを保存します。)
- ほかの設定はすべて同じままでタスクを保存します。
- 基本変換タスクを開きます。
- フィールドが表示されるはずです。
- データ読み込みタスクにこの新しいフィールドが含まれているかどうかも確認してください。
- 「EOFが予期せずヒットしたワークフローの実行履歴を見ていると、”EOF unexpectedly hit when reading file. “というメッセージが表示されることがある。ファイルにデータを追加するか、データソースからデータを削除する。” この場合、タスクの失敗を自動的にリトライするようにワークフローを設定することをお勧めします。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!