-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
アンケート調査タスクからの回答の抽出
アンケート調査からの回答の抽出について
クアルトリクスのアンケート調査データを定期的に選択肢の場所に自動的にアップロードするワークフローを作成できます。これにより、データを何度も手作業でエクスポート、インポートすることなく、データを必要な場所に簡単に送ることができます。
この種のワークフローは、”アンケート調査からの回答抽出” というETL データ抽出タスクを使用して作成されます。アンケート調査からデータを抽出するたびに、ETLデータローダタスクを使用して送信先を選択する必要があります。
例クアルトリクスのアンケート調査から定期的にデータを抽出し、Sftpサーバーにアップロードすることができます。
注意回答をエクスポートする場合、1 時間以上前の回答のみがエクスポートされます。
Qtip:ワークフローが回答を抽出する場合、最後に実行されてから収集された回答のみが抽出されます。たとえば、ワークフローが水曜日に実行される場合、先週の水曜日以降にアンケートが収集した回答のみを選択した送信先にアップロードします。
注意抽出されたアンケートの列の順番は保証されておらず、いつでも変更される可能性があるため、この順番に基づいてソリューションを構築するべきではありません。列の順序が重要な場合は、基本変形タスクを使用して列の順序を変更する必要があります。
アンケート調査からの回答の抽出
Qtip:このタスクを使用して抽出されたアンケートの回答は、アカウントのタイムゾーンではなく、常に UTC+0 になります。
- ETLワークフローを作成する。
- データソース(ETL抽出器)を選択します。
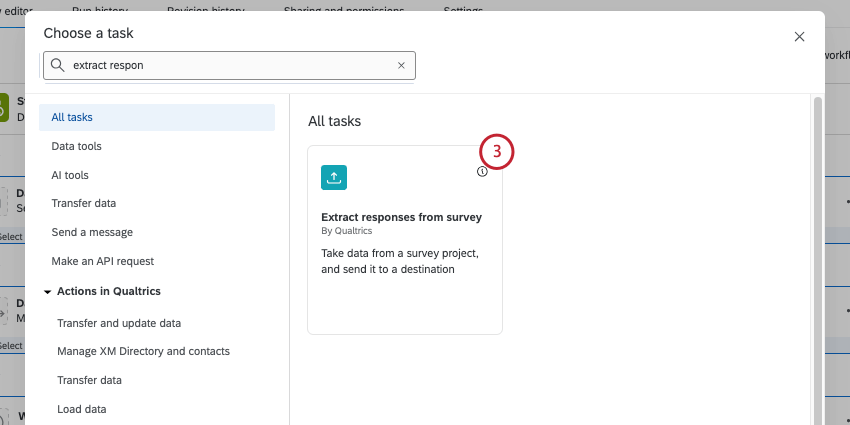
- アンケートを検索して選択するアンケート調査から回答を抽出します。
- 回答を抽出するアンケート調査プロジェクトを選択します。
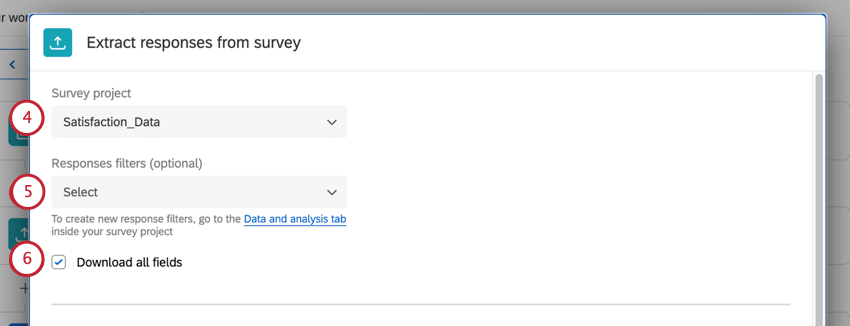
- 必要であれば、保存された 回答フィルターから選択する。これにより、特定の条件に一致する回答のみが抽出されます。
例未完成または除外を含む回答をフィルタします。注意このタスクでは、前回の実行以降に収集された回答のみが抽出されます。このタスクに追加されたフィルターは、前回の実行以降に新たに記録された回答にのみ適用されます。エクスポートされたデータセットに期待した回答が含まれない可能性があるため、開始日、終了日、記録された回答などの時間フィールドに基づいてフィルタを作成することはお勧めしません。qtip:フィルターはあなたのアカウントのタイムゾーンではなく、UTC+0のタイムゾーンを使用します。
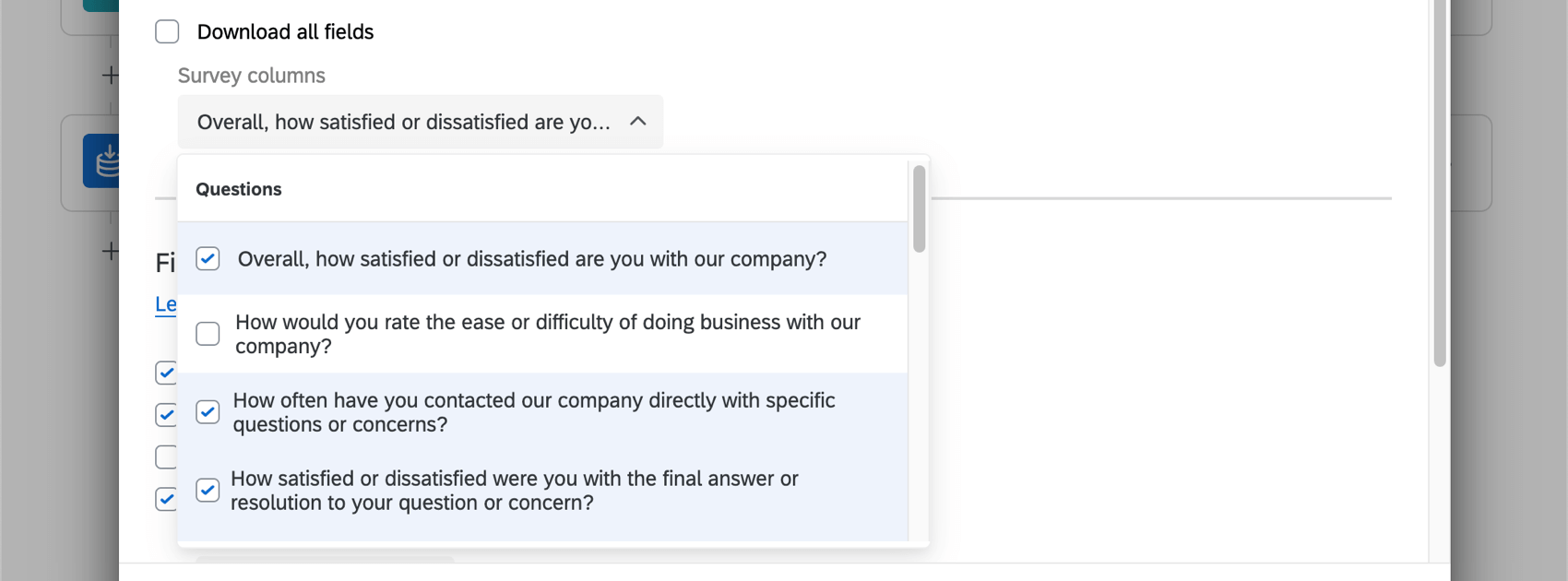
- すべてのフィールドをダウンロードしたい場合は、Download all fieldsを選択してください。このオプションを選択解除すると、代わりに保存する特定のアンケート調査フィールドを選択できるようになります(下図)。
Qtip: アンケートフローに設定されている質問または埋め込みデータフィールドを選択することができます。つまり、アンケートフローで埋め込みデータとして設定されていない限り、デフォルトでは回答者の連絡先情報は含まれません。
- 処理後のデータのファイルタイプを選択します:
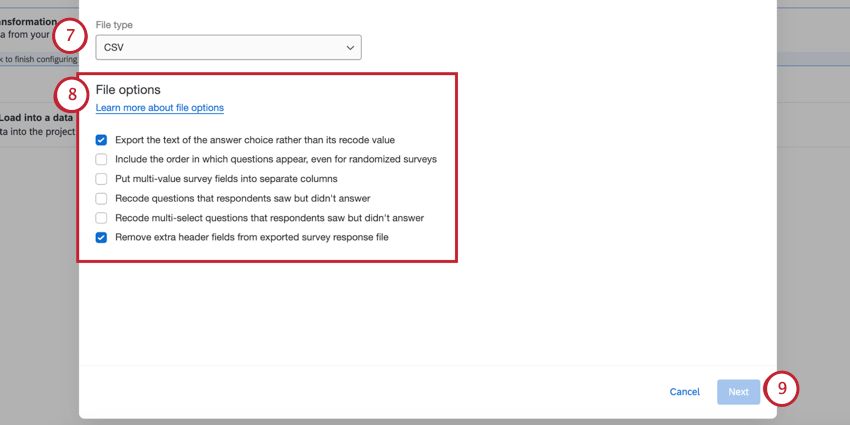
- CSV
- TSV
- JSON
- NDJSON
- SPSS
- XML
Qtip:通常はCSVを選択します。他のファイルタイプオプションをサポートできるロードデータタスクは、Load to SFTPとLoad to Amazon S3だけです。
- 利用可能なファイルオプションから選択します。必要であれば、複数選択することもできる。
- 識別値を割り当てずに、選択肢のテキストをエクスポートします:このオプションが有効な場合、テキストで答えを取得します (カスタム変数名を設定した場合、カスタム変数名が表示されます。そうでない場合、デフォルトで答えのテキストが表示されます)。このオプションを無効にすると、各回答の数値のみが表示されます。
Qtip:一度クアルトリクスから抽出されたデータは、他の場所にアップロードされると、もはや動的ではなくなります。つまり、クアルトリクスで識別値を割り当てるなどの編集を行っても、SFTPサーバーや、回答をエクスポートしたその他の場所には変更が反映されません。
- 質問の表示順を含める(ランダム化機能のあるアンケートも含む):このオプションは、質問がランダム化されているアンケートの場合に最も便利です。これは、ランダム化調査の閲覧順データのエクスポートと同じ機能です。
- 複数値のアンケート調査フィールドを別の列に分割します:複数値のフィールドを列に分割するを参照してください。
- 回答者が見たが回答しなかった質問を再コード化してください:見たが未回答の質問を-99としてRecodeを参照してください。
- 回答者が見たが回答しなかった複数選択の質問を再コード化します:見たが回答しなかった複数値フィールドを 0 として識別値を割り当ててください。
- エクスポートされたアンケート回答ファイルから余分なヘッダーフィールドを削除します: 通常、クアルトリクスからエクスポートされたデータファイルには 3 行のヘッダーがあります。 このオプションを選択すると、以下のようにヘッダーの行が1つだけ表示されます。
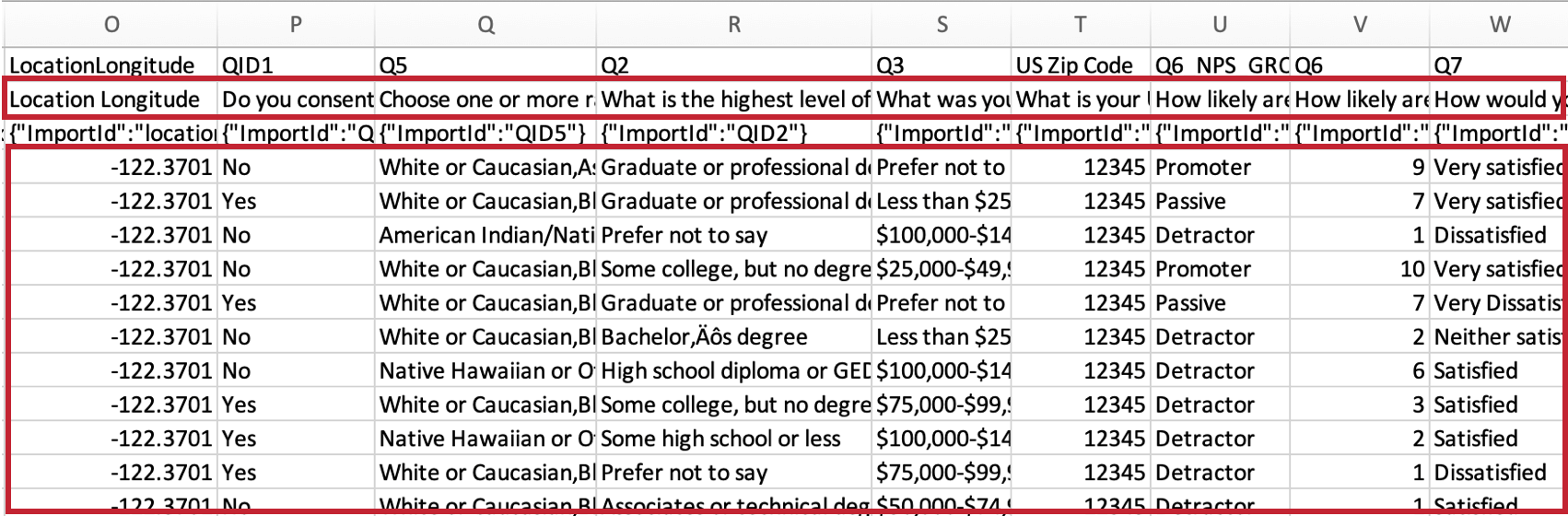 Qtip:ファイルオプションで「エクスポートされたアンケート回答ファイルから余分なヘッダーフィールドを削除する」オプションの選択を解除すると、ヘッダーにアンケート質問文が含まれるようになります。つまり、初期設定後にアンケート調査の文言を変更すると、このタスクの出力が変更されます。ワークフロー設定の更新がないと、これらの変更により、後続のロードタスクは失敗する。
Qtip:ファイルオプションで「エクスポートされたアンケート回答ファイルから余分なヘッダーフィールドを削除する」オプションの選択を解除すると、ヘッダーにアンケート質問文が含まれるようになります。つまり、初期設定後にアンケート調査の文言を変更すると、このタスクの出力が変更されます。ワークフロー設定の更新がないと、これらの変更により、後続のロードタスクは失敗する。
- 識別値を割り当てずに、選択肢のテキストをエクスポートします:このオプションが有効な場合、テキストで答えを取得します (カスタム変数名を設定した場合、カスタム変数名が表示されます。そうでない場合、デフォルトで答えのテキストが表示されます)。このオプションを無効にすると、各回答の数値のみが表示されます。
- [次へ]をクリックします。
- インポートされるフィールドのリストと、各フィールドの値の例が表示されます。リストをスクロールして正しいことを確認し、ファイルを変更する必要がある場合は[戻る]ボタンを押してください。
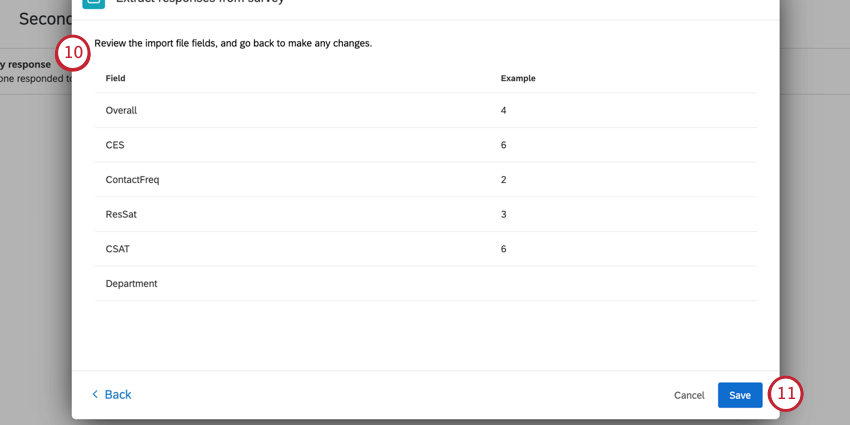
- 終了したら、Saveをクリックします。
Qtip: 回答の抽出タスクは、回答の作成日に基づいています。既存の回答を更新した場合、その回答は新しいエクスポートには含まれません。
Qtip:アンケートの回答を抽出した後に基本的な変換タスクを追加することで、出力フィールドの順序を変更することができます。これは、ワークフローの出力で特定のフィールドの順序を保証する唯一の方法です。
アンケート調査データのアップロード先の指定
データ抽出タスクを保存すると、ワークフローに戻ります。次へ、抽出したデータをどこかにアップロードするためのタスクをワークフローに追加する。たとえば、Sftp サーバーにアンケート調査データをアップロードすることができます。
すべてのデータ・アップロード・タスクのリストは、Available Loader Tasksにあります。
抽出できるプロジェクトの種類
以下のようないくつかのタイプのプロジェクトからデータを抽出することができます:
- アンケートプロジェクト
- XMソリューション
- エンゲージメント
- ライフサイクル
- アドホック従業員調査
- 個別パルスサーベイ調査
- 360
Qtip: ConjointおよびMaxdiff固有のデータを抽出することができますが、全文ではなく数値形式で表示されます。
アンケート調査からの回答の抽出タスクを使用して、インポートされたデータプロジェクトからデータを抽出することはできません。代わりに、データプロジェクトタスクからデータを抽出してみてください。