-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
重みの設定と適用
重み設定について
Stats iQでは、ユーザーが重み設定を適用することができるため、特定のタイプのアンケート回答者が少なかったり多かったりする場合、Stats iQにデータの1行を1つの回答よりも多くカウントしたり少なくカウントしたりするよう指示することができます。重み設定を有効にするには、データに必要な重みを含む変数が必要です。この変数は、左下にあるCreate Variableオプションを使用して追加することができる。
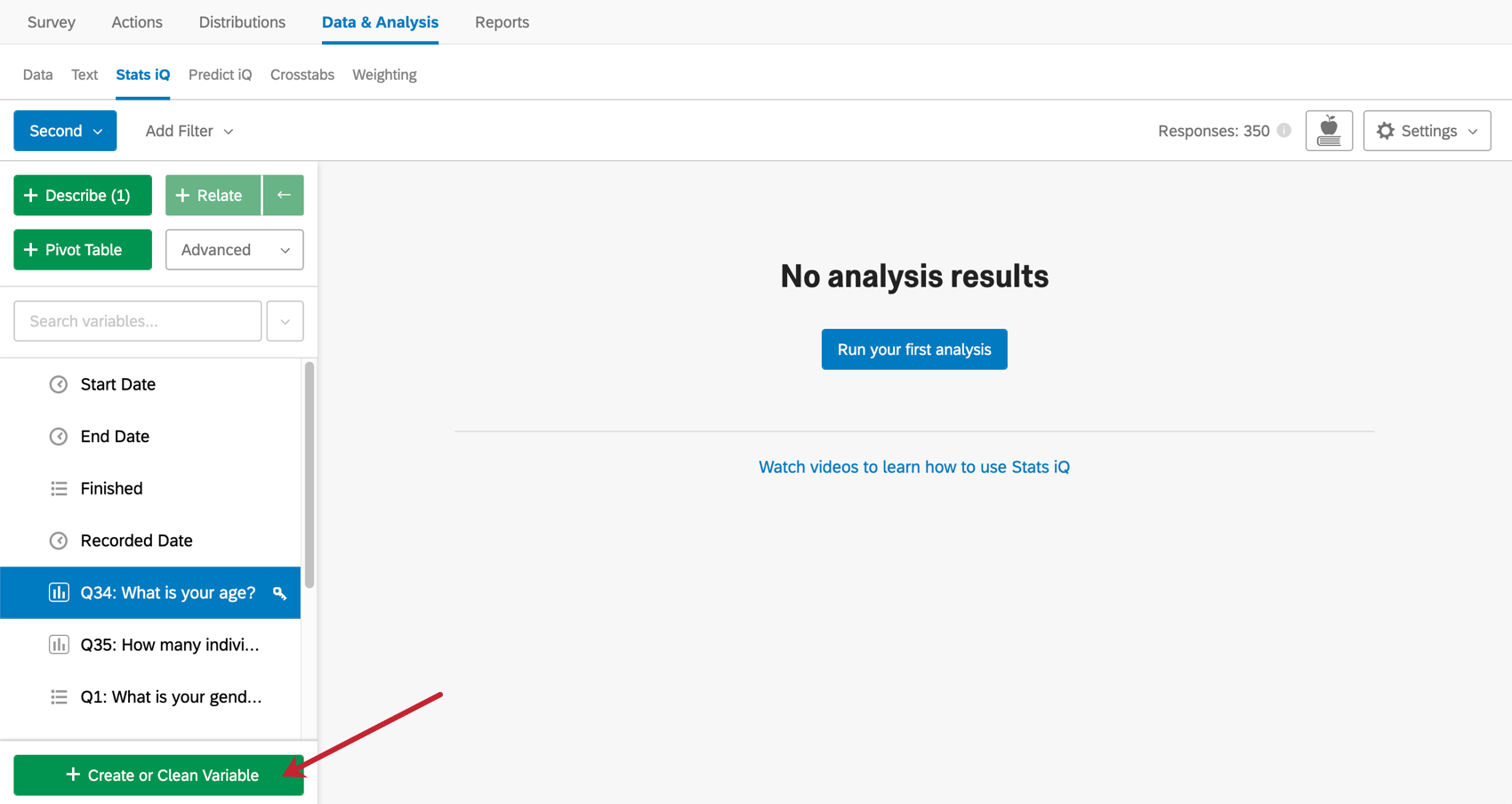
重み設定変数の作成
データセットから任意の数値変数を重み設定として使用することができるが、多くの場合、必要な重みはデータ収集後でないと決定できない。この場合、重み設定変数を手動で作成する必要がある。重み設定変数を作成する最も一般的な方法は、Create VariableメニューのLogicオプションを使用することです(Stats iQでの変数作成の詳細については、変数作成のページをご参照ください)。
ロジック(Logic)」では、数値による重み設定と、重み設定が適用される条件を指定する。例えば、あるホテルの満足度調査で、子供のいる家族からの回答が子供のいない家族より多かったが、本当の割合は半々であるべきだとわかっている場合、データに重み設定を適用して、「子供あり」の回答の割合を減らし、「大人だけ」の回答の割合を増やすように調整することができます。
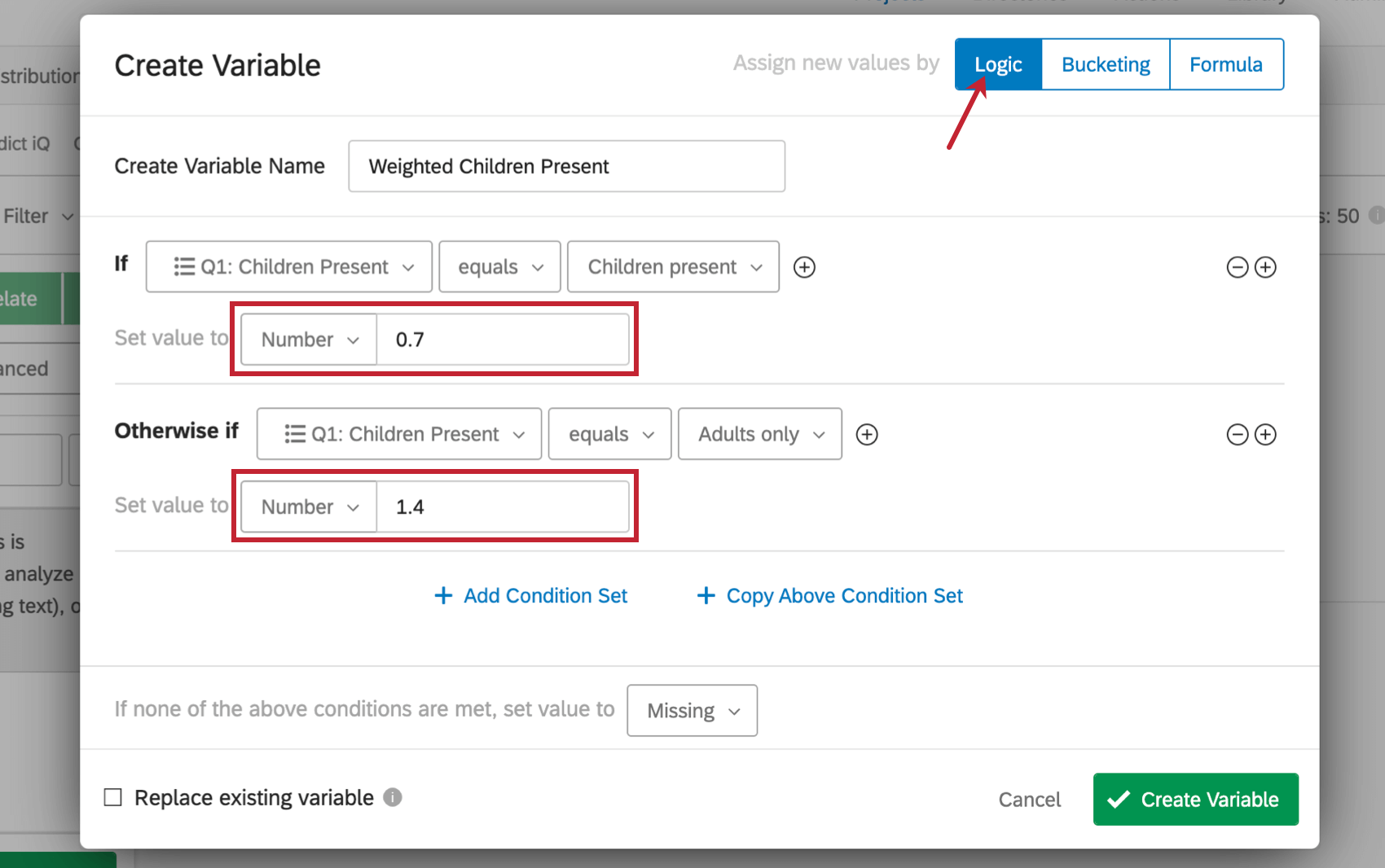
重み設定変数のデータセットへの適用
データセットに重み設定変数が存在すると、分析設定メニューの重み設定ドロップダウンを使って、この変数の重みを適用することができる。分析設定メニューの詳細については、分析設定のページを参照してください。
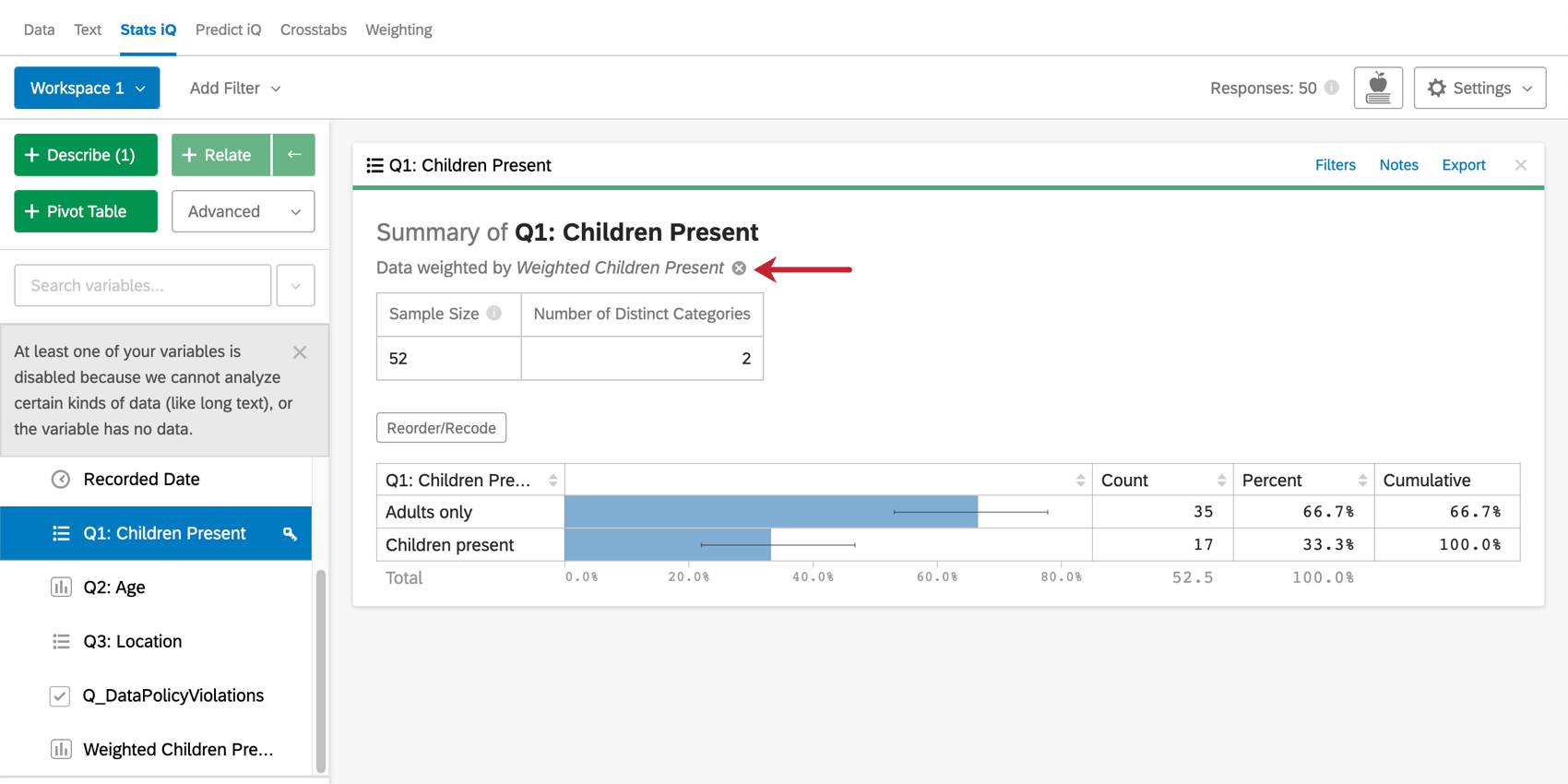
デフォルトでは、重み設定は、分析設定で重み設定変数を選択した後に作成されたすべてのカードに適用されます。特定のカードの重み設定を解除したい場合は、適用されている重みの右側にある「×」をクリックしてください。
重み設定の詳細
データと分析(Data & Analysis)」の「重み設定(Weighting)」セクションでは、希望する回答者のパーセンテージを指定すると、自動的に重みが計算されます。Stats iqでは、重み設定変数を作成する前に、重みを手動で決定する必要があります。これにより、変数の適用方法に関して多くのオプションが可能になるが、重み設定の計算方法を理解する必要がある。このセクションでは、標準的な状況における重み設定の簡単な例を説明する。
通常、重み設定は、アンケート調査のデータ(サンプル)が一般母集団と一致しない場合に計算される。例えば、アンケートの回答者の60%に子供がいて、40%に子供がいなかったとしても、実際には母集団が半々に近いことが分かっている場合、一般的な母集団と一致するようにサンプルを調整するために重みを設定することができます。
これに対する最も基本的なアプローチは、サンプルに占める割合と母集団に占める割合に基づいて、各グループの乗数を計算することである。
子供がいる場合:50% / 60% = 0.5 / 0.6 = 0.83
子供がいない場合:50% / 40% = 0.5 / 0.4 = 1.25
重み設定変数の値は、子供がいる回答者は0.83、子供がいない回答者は1.25となる。