-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
関連データ
関連データについて
関係は変数間の関係を探る。2つの変数を選択し、Relateを選択すると、Stats iqはデータの構造に基づいて適切な統計検定を選択し、その検定を実行し、結果をシンプルでわかりやすい説明に変換します。
3つ以上の変数を選択すると、Stats iQは各変数を、そのキーがそばにある1つの変数に関連付け、最も強い関係を一番上に持ってきます。一度に何十もの変数を選択できるので、多くの関係を素早くふるいにかけることができる。
キー変数
変数ペインから最初に選択された変数がキー変数となる。キー変数には2つの役割がある:
- 2つ以上の変数が選択された場合(上記のように)、キー変数でない各変数は、1つのキー変数に関連する(例えば、10個の変数を選択した場合、1つのキー変数は、他の9つの変数に関連し、9つの別々の関連カードになる)。
- キー変数はデフォルトで「output」変数である。例えば、”Age “と “Location “を選択した場合、”Age”(入力)が “Location”(出力)に影響を与えることはあり得るが、”Location “が “Age “に影響を与えることは意味がない。(多くの分析では、この区別は重要ではありませんが、入力変数と出力変数は、カードを作成した後でいつでも入れ替えることができます)。キー変数を出力変数ではなく入力変数にしたい場合は、Relateボタンの右側にある小さな矢印を選択します。
数字と変数の関係
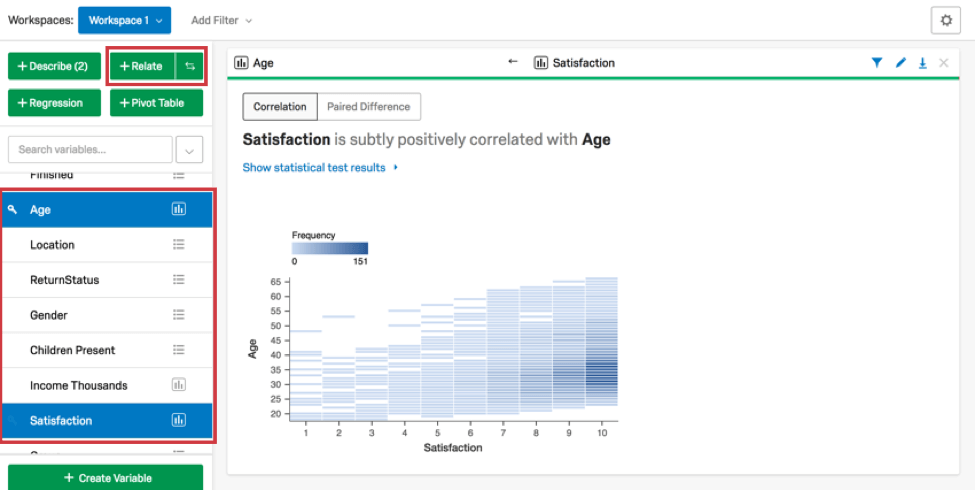
2つの数値変数(再コード化されたカテゴリーを含む)を関連付けると、通常、Stats iQは相関を実行し、散布図を作成して2つの変数の関係を視覚的に表示します。
変数が散布図上で重複している点が多い場合、Stats iQは代わりに「ビン化」散布図を表示し、濃い矩形は結果のクラスタが大きいことを示します。Stats iQがベストフィットの直線を表示するのは、データがその直線が有用であることを示している場合です(具体的には、データに直線を狂わせるような外れ値がない場合)。
relate」分析結果の統計的詳細を見るには、「Show statistical test results」をクリックする。2つの数値変数を関連付ける場合、Stats iQはP値と(効果量について)PearsonのrまたはSpearmanのrhoを計算します。Stats iQがどのように統計検定を選択するかについての詳細は、「統計検定の前提条件と技術的詳細」のページをご覧ください。
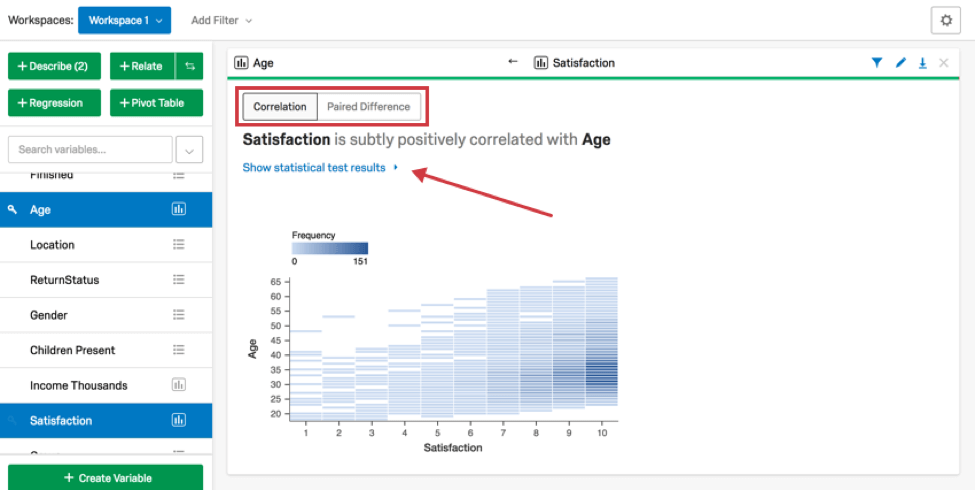
変数が相関しているかどうかにはあまり興味がなく、どの変数が平均的に高いかにより興味がある可能性がある。2つの変数が同じような尺度にある場合、Stats iqは、CorrelationからPaired Differenceに切り替えるオプションを上部に提供し、平均を比較することができます。
数字とカテゴリー変数の関係
数値変数とカテゴリー変数を関連付けると、Stats iQは統計テストを実行し、各カテゴリーのカウント、平均、中央値、数値変数の配信を表示するテーブルを作成します。
例えば、子連れの宿泊客とそうでない宿泊客のどちらが平均的に満足度が高いかを調べたい場合があります。この場合、”Children Present “変数はカテゴリー変数であり、”Satisfaction “は数値である。
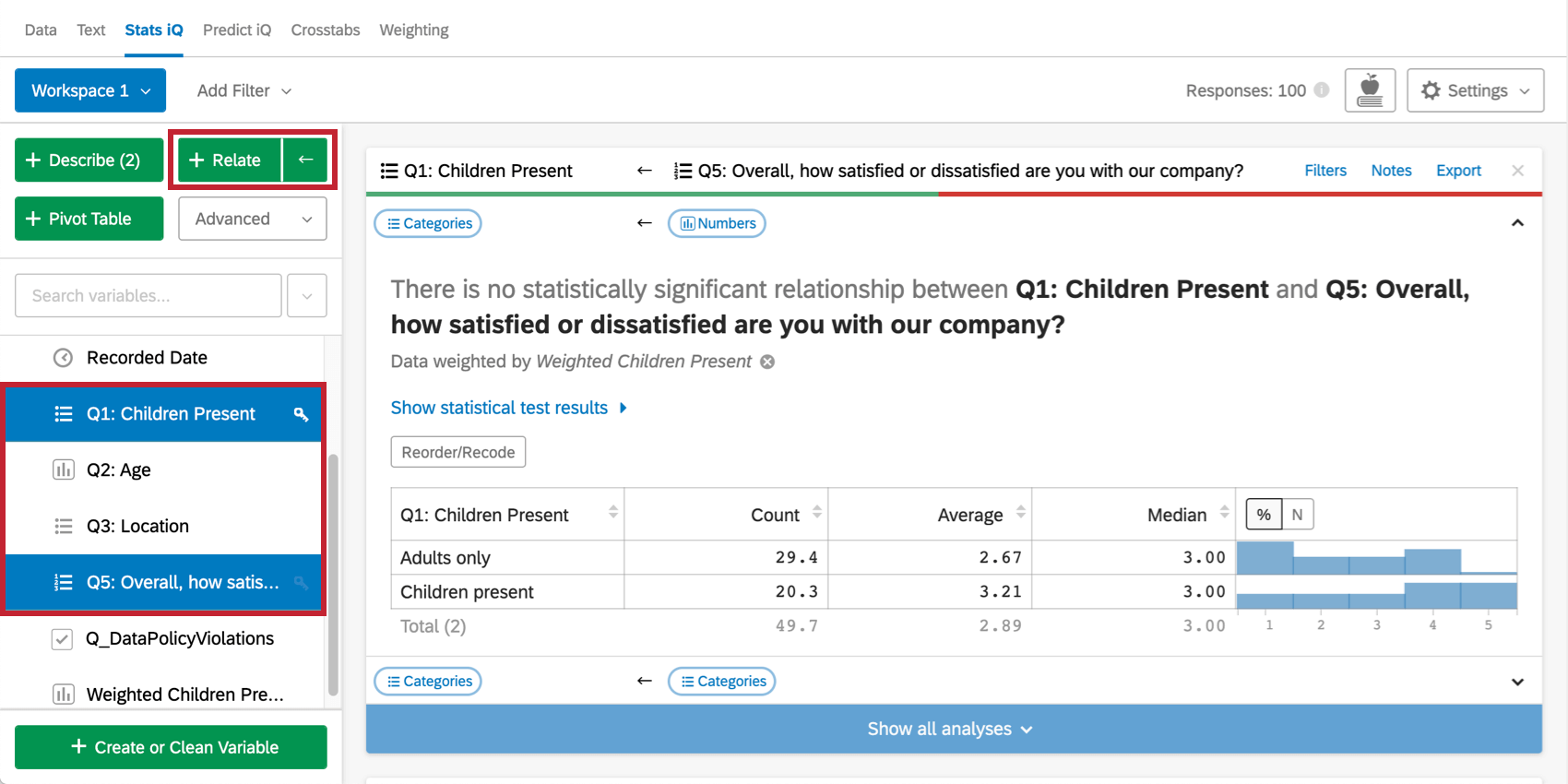
この統計テストの結果は、カードの「統計テスト結果を表示」をクリックすることで見ることができる。カテゴリー変数に
のカテゴリーが2つしかない場合、Stats iQはt検定または順位付きt検定を実行する。それ以上の場合は、Stats iQは、ANOVAまたは順位付け分散分析、およびGames-Howell事後検定を実行します。Stats iQがどのように統計検定を選択するかについての詳細は、「統計検定の前提条件と技術的詳細」のページをご覧ください。
カテゴリーとカテゴリー変数の関係
カテゴリー変数とカテゴリー変数を関連付けると、Stats iQは統計検定を実行し、クロスタブを作成します。
クロスタブの各列の合計は100%になる。下の例では、”USA “の回答者の69%が “Returning”、31%が “New “である。行の合計を100%にするには「行 %」、各セルの生のカウントを見るには「カウント」、表全体の合計を100%にするには「すべて %」を選択する。また、分析結果の上部にある←を選択することで、行と列を完全に反転させることもできる。
以下の例では、列の合計が100%になるため、「USAの回答者の何パーセントがリピーターか?Row %を選択すると(あるいは列と行を入れ替えると)、”リピーターの何パーセントがアメリカ人ですか?”という質問になる。この場合、どちらの質問も有効だろう。本当に意味のある質問は1つだけということもある。
セル内の緑と赤の矢印は、セルの値が、変数間に関係がない場合に予想される値よりも統計的に高いか低いかを示します。Col %が選択されている場合、矢印はそのセルの数値をその行の他の数値と比較する。矢印が多いほど統計的有意性が高い。数値の高い細胞は他の細胞より暗く見える。
下の例では、75.2%がその行の他の数字の合計よりも高いので、英国は一般的なリピーターの割合よりも高い。
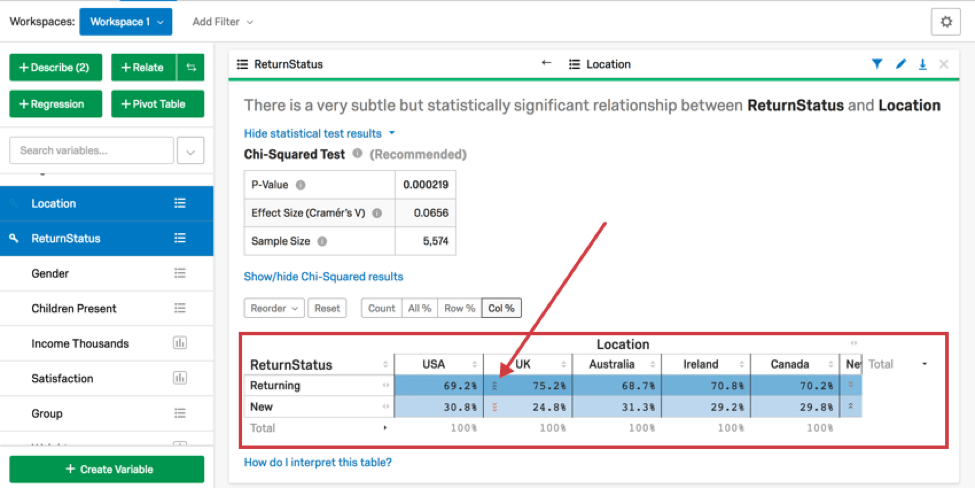
統計テストの出力は、カードの「統計テスト結果を表示 」をクリックすることで見ることができる。Stats iQは、2つのカテゴリー変数が関連している場合、Fisherの正確検定またはカイ2乗検定を実行します。セルの調整残差から計算されたP値に応じて、1つのセルに最大3つの矢印が表示される。Stats iQがどのように統計検定を選択するかについての詳細は、「統計検定の前提条件と技術的詳細」のページをご覧ください。
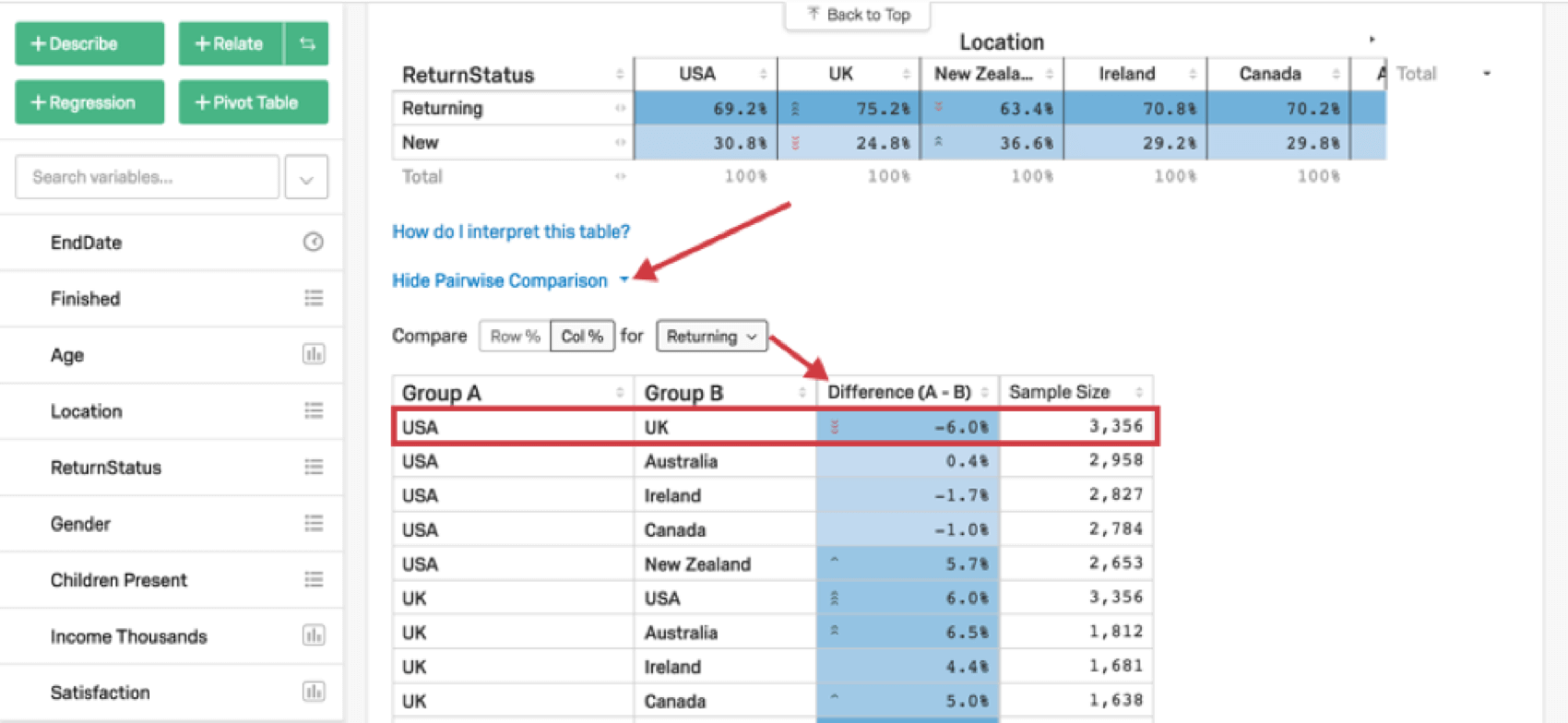
一般的なクロス集計に加えて、Stats iQは、与えられた行のカテゴリのペアの値を比較するペアワイズ比較表も生成します。例えば、以下のクロス集計は、各地からのリピーター客の割合を示している。例えば、ペアワイズ比較表では、英国は米国よりもリピーターの割合が6%ポイント高い。セル上の緑と赤の矢印は、統計的に有意な差を示す。
チェックボックスと数値変数の関係
チェックボックス変数と数値変数を関連付けると、Stats iqは統計検定を実行し、サマリーテーブルを作成します。
Stats iQは、チェックボックスごとに2行の表を表示します。1行はチェックボックスがチェックされている場合、もう1行はチェックされていない場合です。たとえば、チェックボックスの 1 つがプールを利用したかどうかを表す場合、プールを利用した (チェックを入れた) 行と利用しなかった (チェックを入れない) 行があり、その 2 つのグループのいずれかに該当する回答者の平均満足度スコアが表示されます。
この表は、Stats iQの他の表と同様、並べ替えが可能である。例えば、平均値で並べ替えたり、ボックスにチェックが入っているかどうかで並べ替えたりしたい。列のヘッダー(例:平均)をクリックすると、その列の値で表をソートできます。
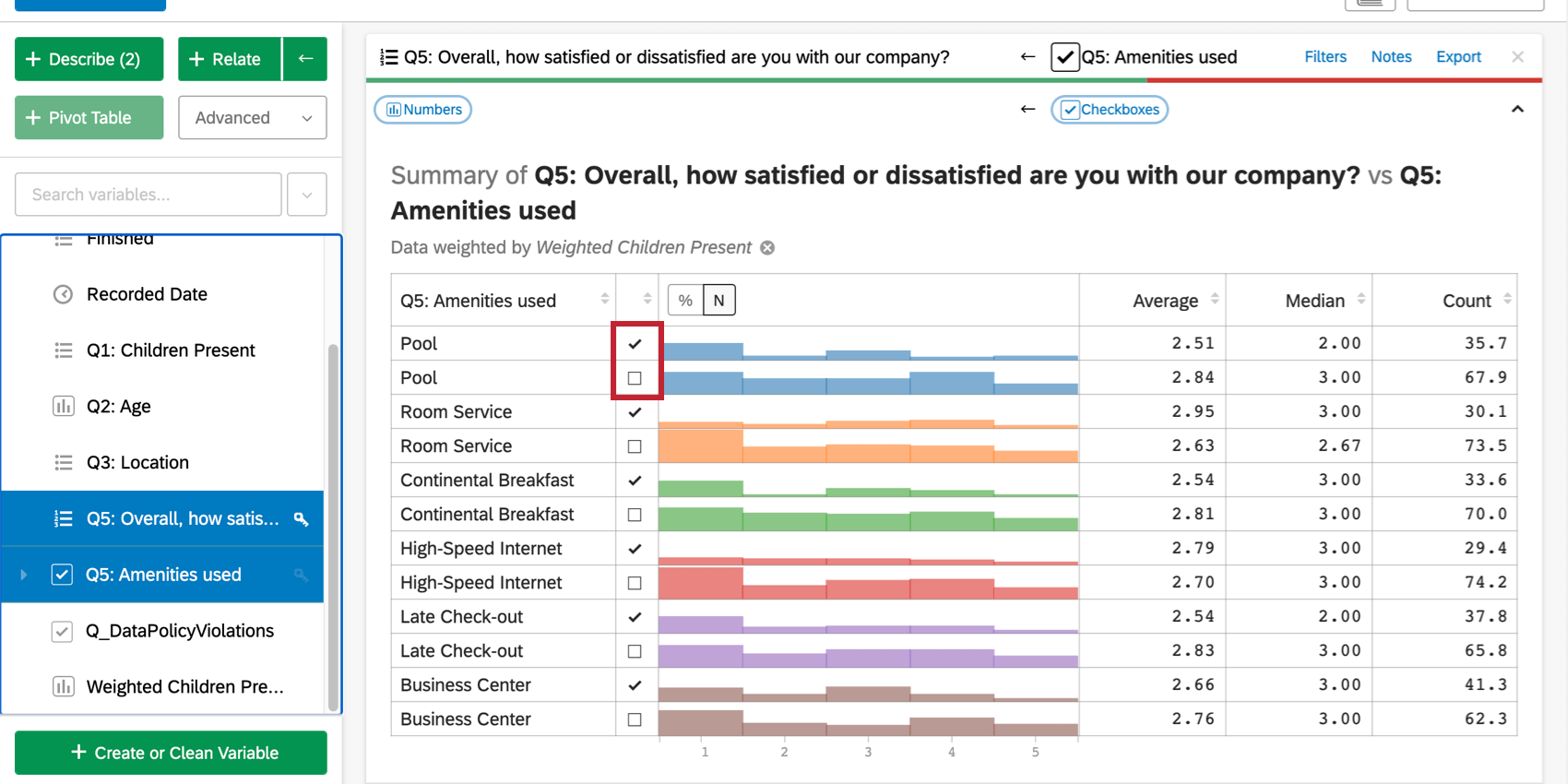
統計テーブルには中央値や平均値などの統計情報が表示されるが、この状況では統計検定は行われない。プールを利用した人と利用しなかった人の平均を比較する別の分析を行うこと:
- 変数ペインの “アメニティ“チェックボックスグループのドロップダウン矢印(v)をクリックする。
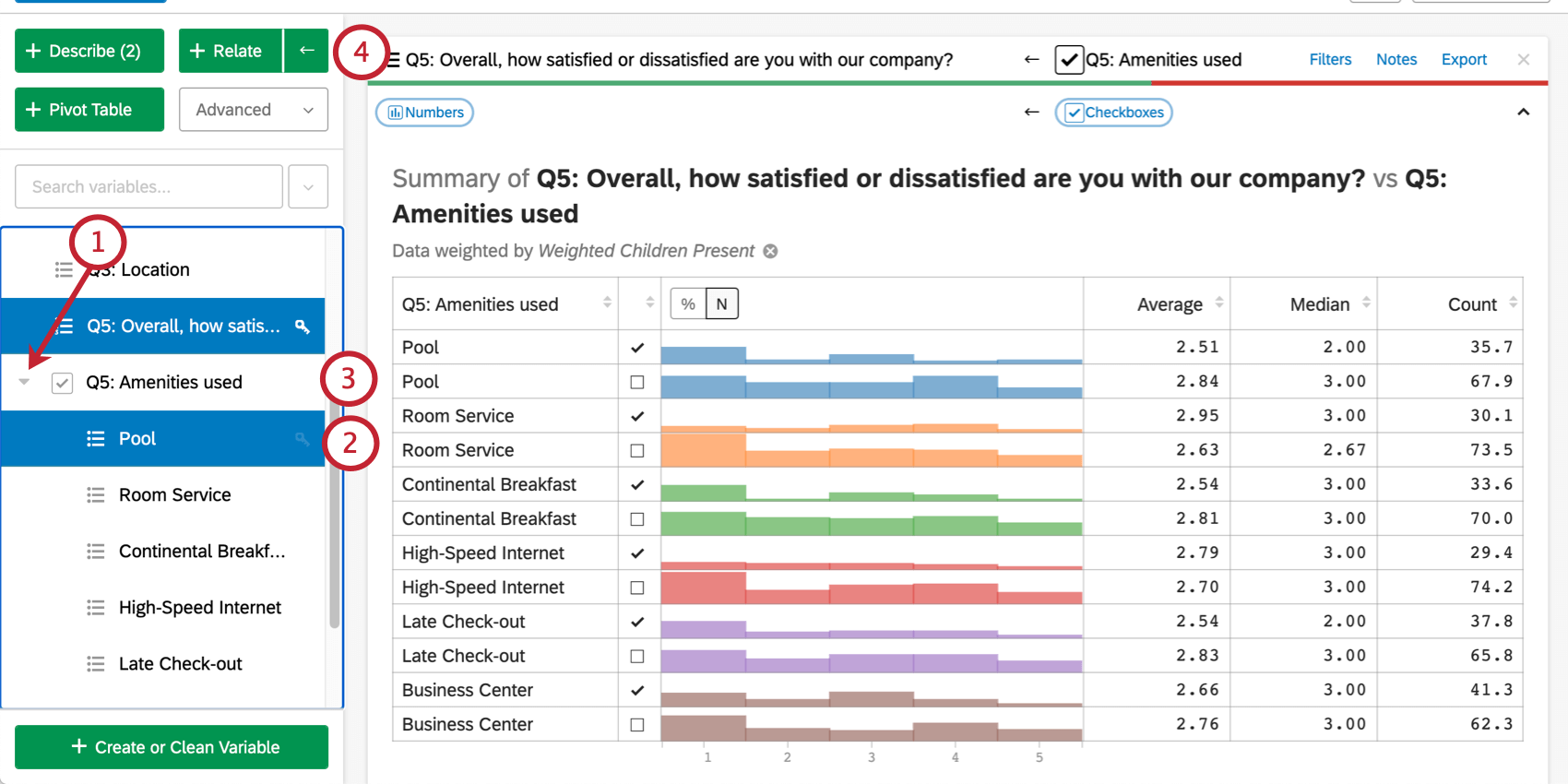
- プール」サブ変数を選択する。
- アメニティ」チェックボックス変数の選択を解除する。
- クリックリレート
チェックボックスとカテゴリー変数の関係
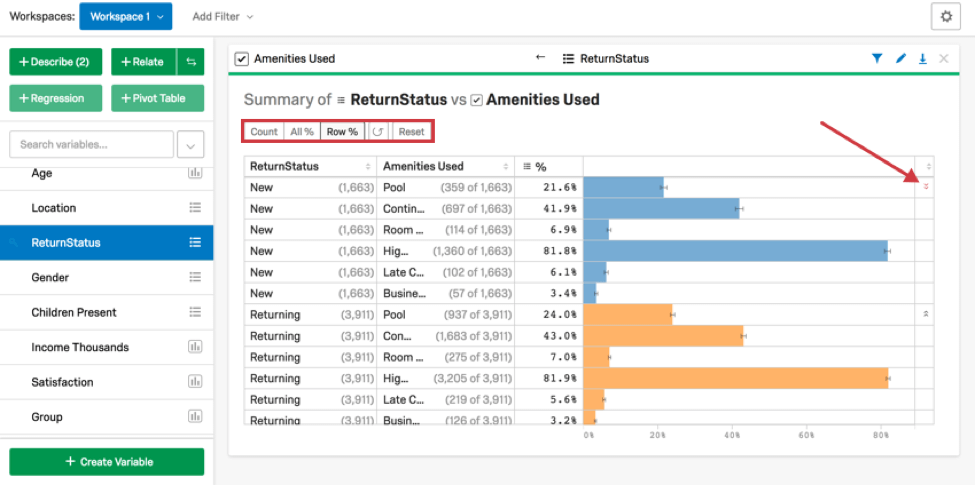
チェックボックス変数とカテゴリー変数を関連付けると、Stats iqは統計検定を実行し、サマリーテーブルを作成します。
どの変数がキーを持つかによって、最初の2列のうちの1列がカテゴリ変数オプションを含み、もう1列がチェックボックスオプションを含む。%」列は、最初の列グループのうち、2番目の列グループを選択した人の割合を示す。
以下の例では、最初の行は以下を示している:
- 新規顧客の回答者は1663人だった。
- 回答者1663人のうち、プールを利用したのは359人だった。
- つまり、回答者1663人のうち21.6%がプールを利用したことになる。
- 最後の欄の赤い矢印は、この割合が一般的な割合よりも低いことを示している。
最後の列の矢印は、前述のカテゴリー変数のクロス・タブと同じ方法で計算される。
数字とタイムズ変数のタイミング
数値変数と回数変数を関連付けると、Stats iQは数値変数の経時変化を示すグラフを作成します。ビンのサイズを変更するには(例えば、日単位から週単位へ)、チャートの上にある「ビンのサイズ」をクリックします。
Stats iqは、日付のビンに加え、特定の統計値を経時的に線で表示します。デフォルト値は平均値。グラフの上部にある別のオプション(中央値、最小値、最大値)を選択すると、グラフ上で線として表現される値が変わる。グラフの下にあるスライダーを調整すると、表示される日付の範囲が狭まります。
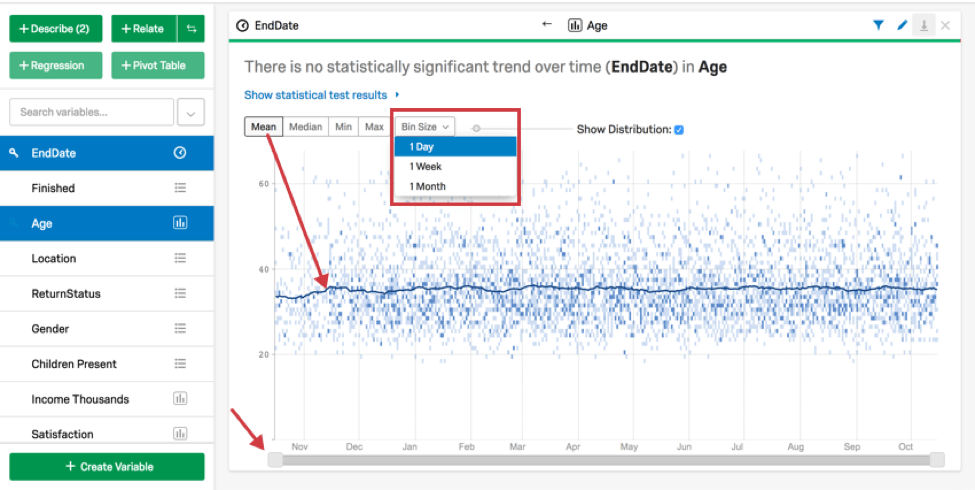
この統計テストの結果は、カードの「統計テスト結果を表示」をクリックすることで見ることができる。Stats iQが実行する統計検定は、タイム変数が数値変数であった場合に実行されるものと同じである。特に、これはStats iqが変数間の相関を実行することを意味する。
タイミングとカテゴリー変数の関係
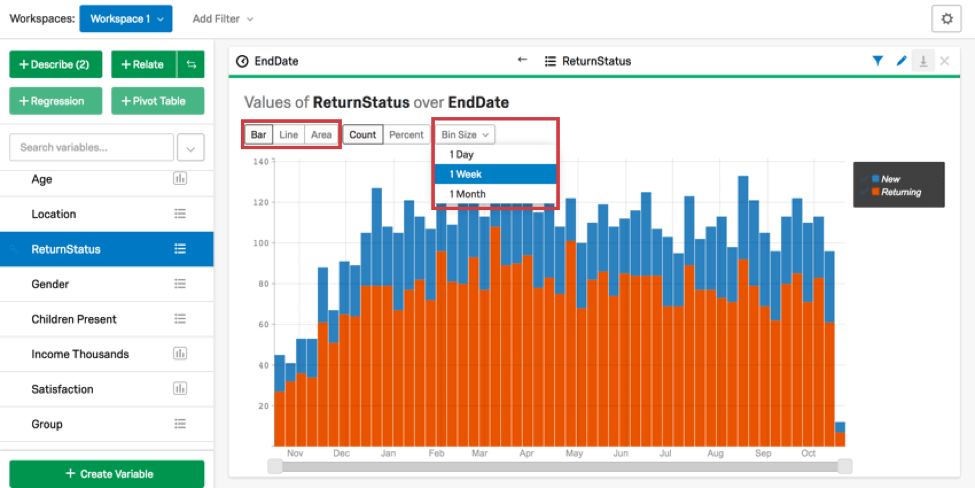
回変数とカテゴリー変数を関連付けると、Stats iQは、それらのカテゴリーのカウントが時間とともにどのように変化したかを示すチャートを作成します。ビンのサイズを変更するには(例えば、日単位から週単位へ)、チャートの上にある「ビンのサイズ」をクリックします。
このタイプのカードでは、表示されるチャートのタイプを選択するオプションがあります。棒グラフ、線グラフ 、エリアチャートのいずれかを選択すると、チャートの種類が変更されます。チャートは、チャート上部で選択されているオプションに応じて、パーセントまたはカウントとしてデータを表示する。パーセンテージは、グループの配信が時間とともにどのように変化したかを見るのに特に役立つ。このタイプのカードについては、統計的なテストは行っていない。
Stats iQの統計検定
Stats iQは、分析対象の変数タイプと列の構造に基づいて統計検定を選択します。参考までに、Stats iQの非回帰統計検定と効果量測定の全リストを示します:
- T検定(2カテゴリーvs. 数字)
- ANOVA(3つ以上のカテゴリーvs. 数字)
- Games-Howellの事後検定(3カテゴリー以上vs. 数字)
- コーエンのF
- 相関性(数字対数字数字)
- ピアソンの相関関係
- スピアマン相関
- 点 双列相関
- コーエンのD
- 一対t検定(数字 vs. 数字数字)
- フィッシャーの正確検定(2カテゴリー対2カテゴリー)
- カイ二乗(3つ以上のカテゴリー vs.カテゴリー)
- クレーマーのV
- Z検定(カテゴリー対カテゴリーカテゴリー)
- タイミング分析
- 差の差(DID、DD)
統計的検定の選択
Stats iQは、データ(変数が数値変数かカテゴリー変数かなど)を理解した上で、正しい統計検定を選択します。ただし、変数タイプを変更して別の結果をトリガーすることはできる。
例えば、1/0と1~7のスケールを関連付けることができる。1/0をカテゴリーとみなした場合、結果はt検定となる。数値とみなされる場合は、結果は相関となる(これら2つの分析結果は非常に似ている)。
Stats iqは、数値データが正規分布していない場合や外れ値がある場合に「ランク付け」関係を実行します。順位なし」の関係(またはその逆)を見たい場合は、統計検定結果でそのオプションが利用できる。ランク付けされたテストの詳細については、統計的テストの仮定と技術的詳細のページをご覧ください。
比較問題
キー変数以外の変数を多数選択して “relate “分析を使用すると、多重比較の問題が発生することがある。この分析では、結果のうち5つほどは、純粋な運によって統計的に有意であると示される可能性が高く、必ずしも意味のある関係ではない。これは統計分析が機能するために必要な結果である。
Stats iqでは、一度に多くの分析を実行し、P値が狭く有意な結果(例えば、0.00004ではなく0.03)が出た場合、これらの相関は必ずしも有意ではないことを示す良い兆候です。
統計を文章化する
Stats iQは、Relateの分析結果を、統計の専門知識がなくても理解しやすいように説明しています。
P値が統計的有意性のしきい値(Stats iQのデフォルトは0.05)を下回っていない場合、統計的に有意な関係がないことを説明する文章が表示されます。
P値がしきい値以下であれば、Stats iqは効果量を調べる。効果の大きさに応じて、Stats iQは「弱い」や「強い」といった言葉を文に加え、関係を特徴づける。効果量とP値の解釈の詳細については、「統計検定結果を表示する」の下にある情報(i)ボタンをクリックすると表示されます。
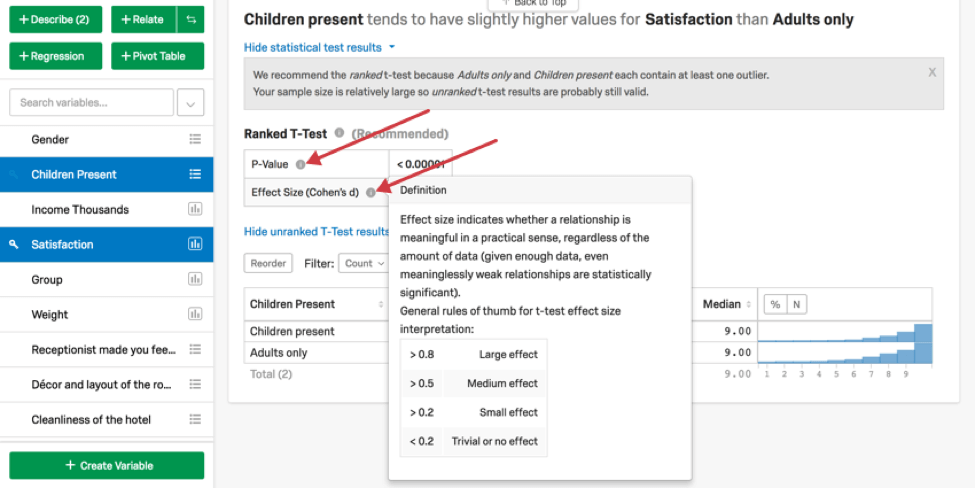
下の表は、効果量に基づくT検定において、変数の関係をどのように記述するかの概要である。
| 効果の大きさ | エフェクトサイズの解釈 | Stats iQ 言語 |
| 0.2以下 | 軽微または影響なし | 変数間には統計的に有意な関係はない。 |
| 0.2以上0.5未満 | 小さな効果 | 変数は統計的に関連している。二人の関係を表すのに余計な形容詞は使わない。 |
| 0.5から0.8の間 | 中程度の効果 | 変数は統計的に関連している。二人の関係を表すのに余計な形容詞は使わない。 |
| 0.8以上 | 大きな効果 | 変数は「強く」関連している。 |
使用する統計検定の種類によって、効果量のしきい値は若干異なる。しかし、同じ一般的なパターンが適用される。