ピボットテーブル
このページの内容
ピボットテーブルについて
ピボットテーブルを作成すると、大幅にカスタマイズ可能なクロスタブのような表で、変数同士を比較することができます。テーブルのセル値は、さまざまな方法でデータを表示するために変更することができます。
Qtip:ワークスペースには750枚までカードを置くことができます。この制限に達した場合、新しいカードを作成しようとするとエラーが表示され、最も古いカードが削除されることを警告します。
ピボットテーブルカードの変数の選択
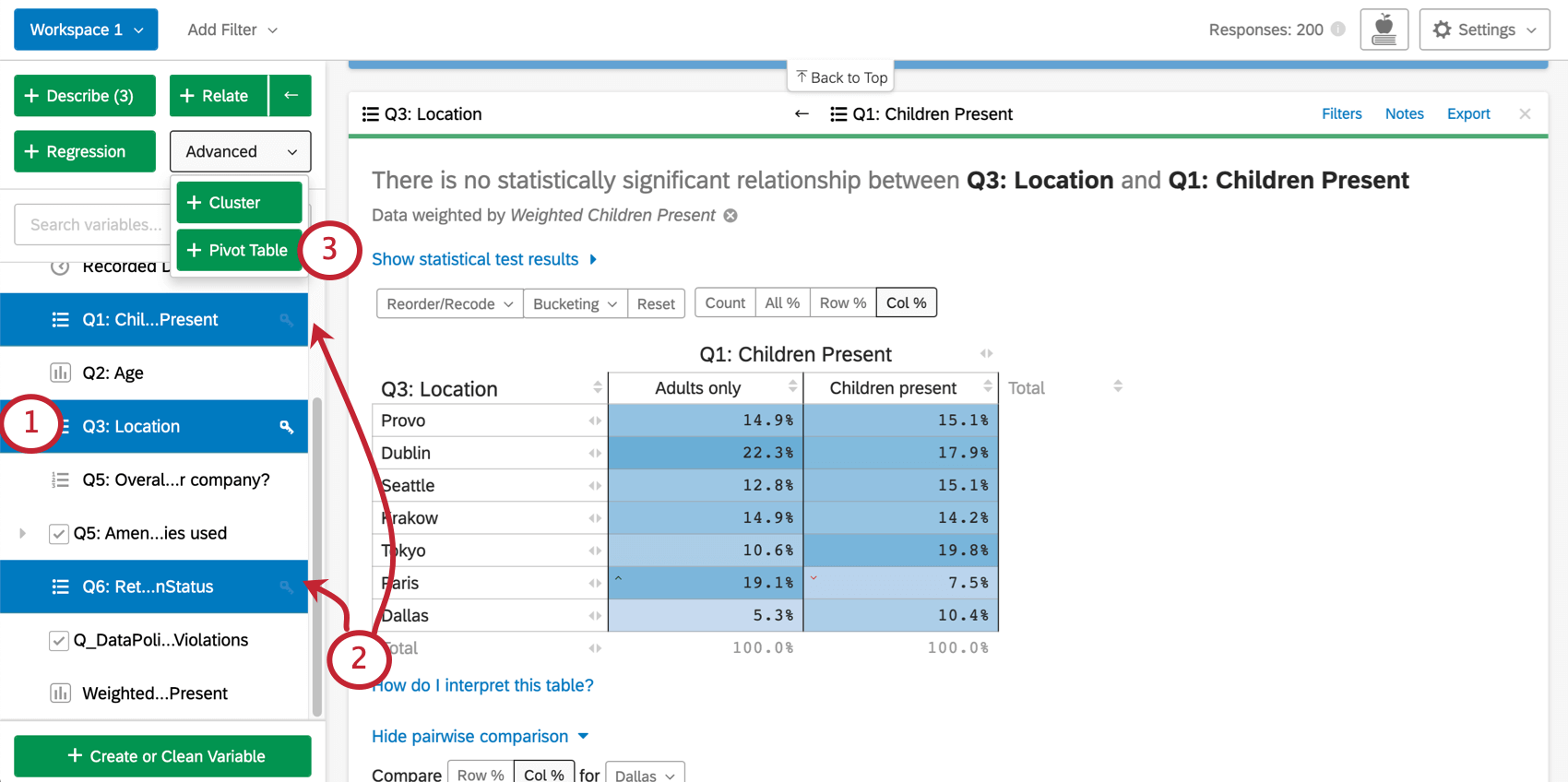{kind=link}

Qtip: テーブルを作成した後に変更するのは簡単なので、変数を選択するときにすべてを正しくすることを心配しないでください。入れたい変数を選んでピボットテーブルを作成し、満足のいくように編集するだけです。
行と列の追加
ピボットテーブルを作成したら、テーブルの上にある[行]または[列]ドロップダウンをクリックすると、テーブルの行または列に変数を追加できます。変数が追加されるごとに表が分割され、変数値の組み合わせごとに行または列が存在するようになる。
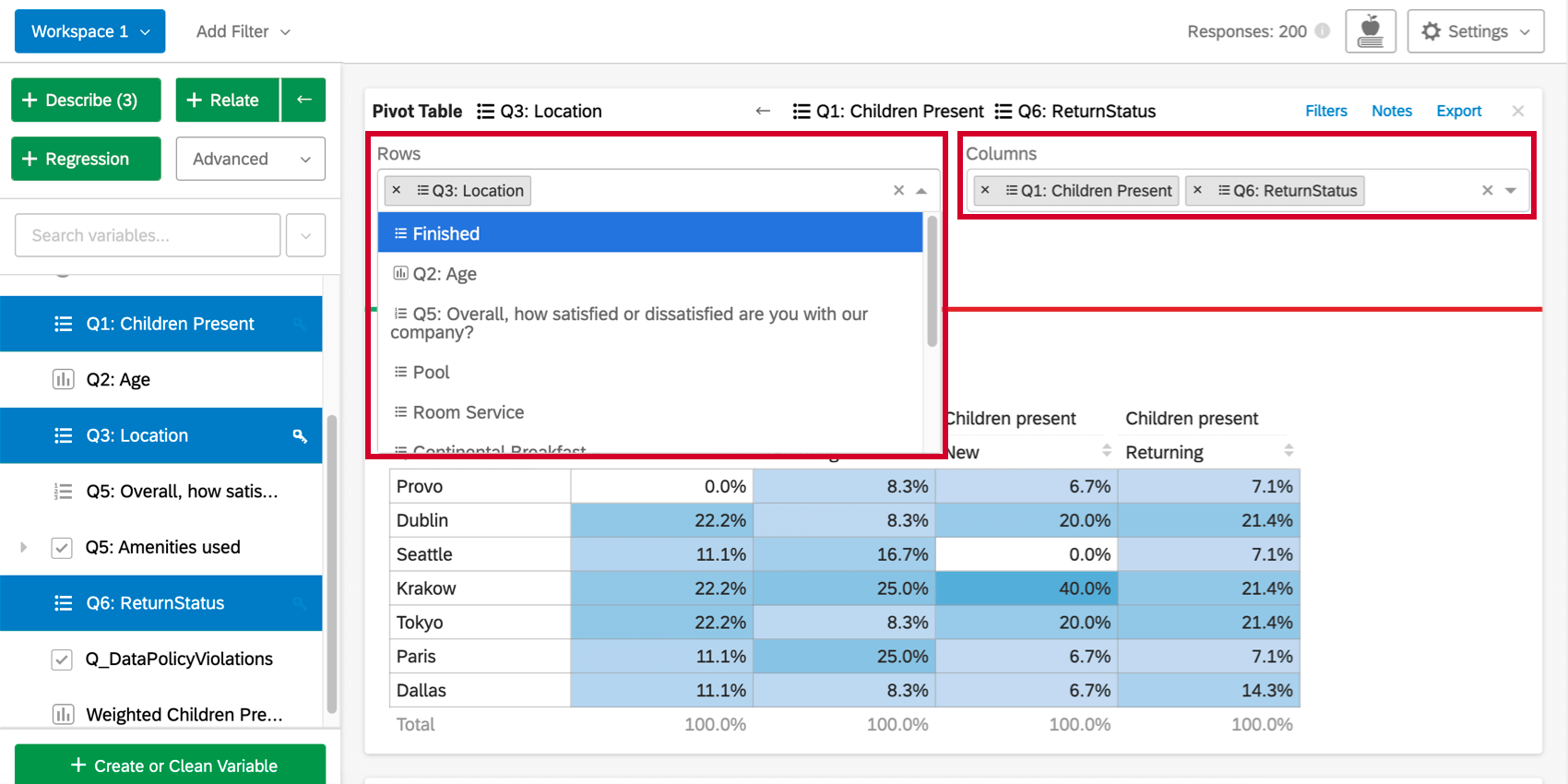{kind=link}
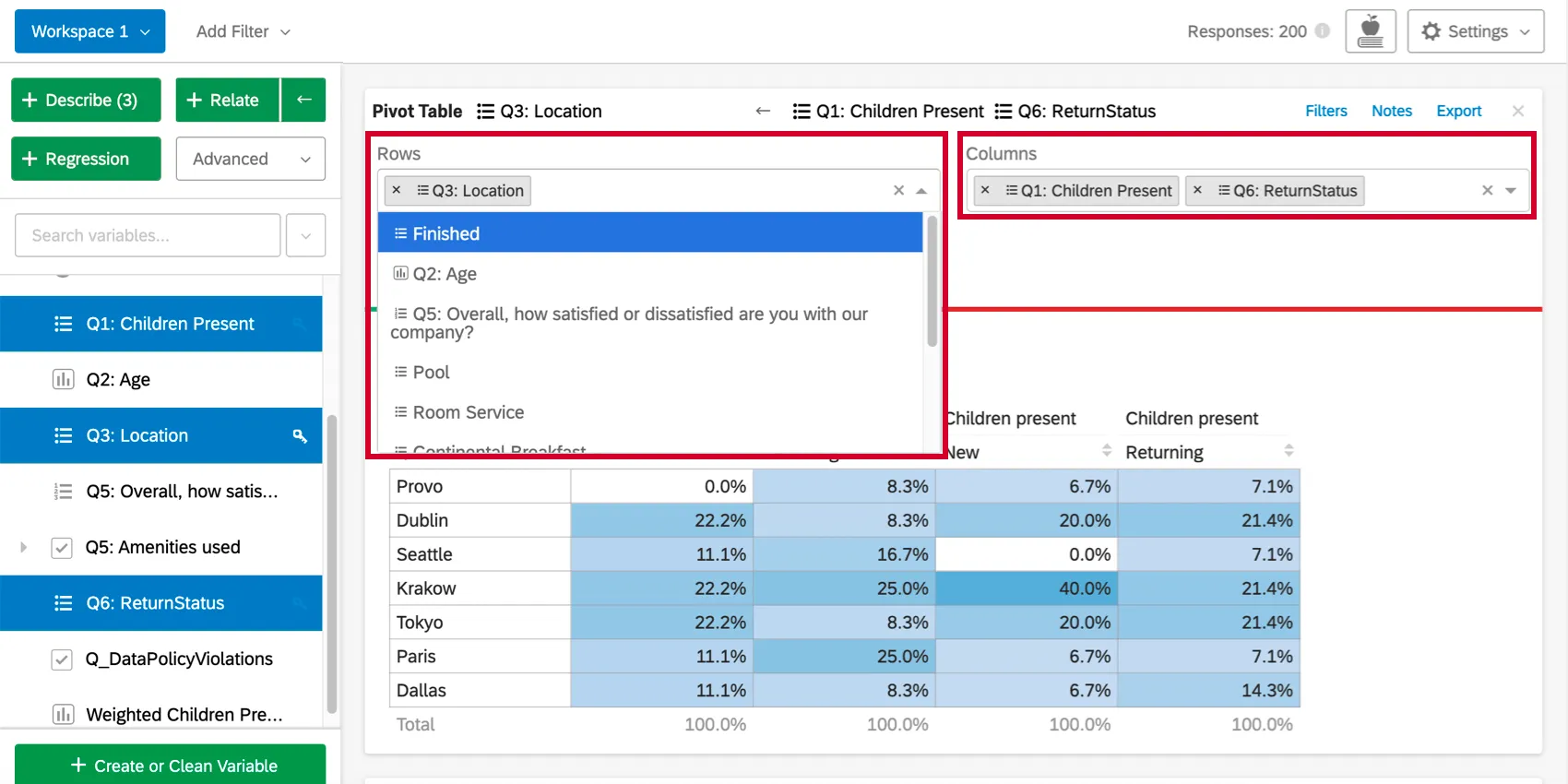
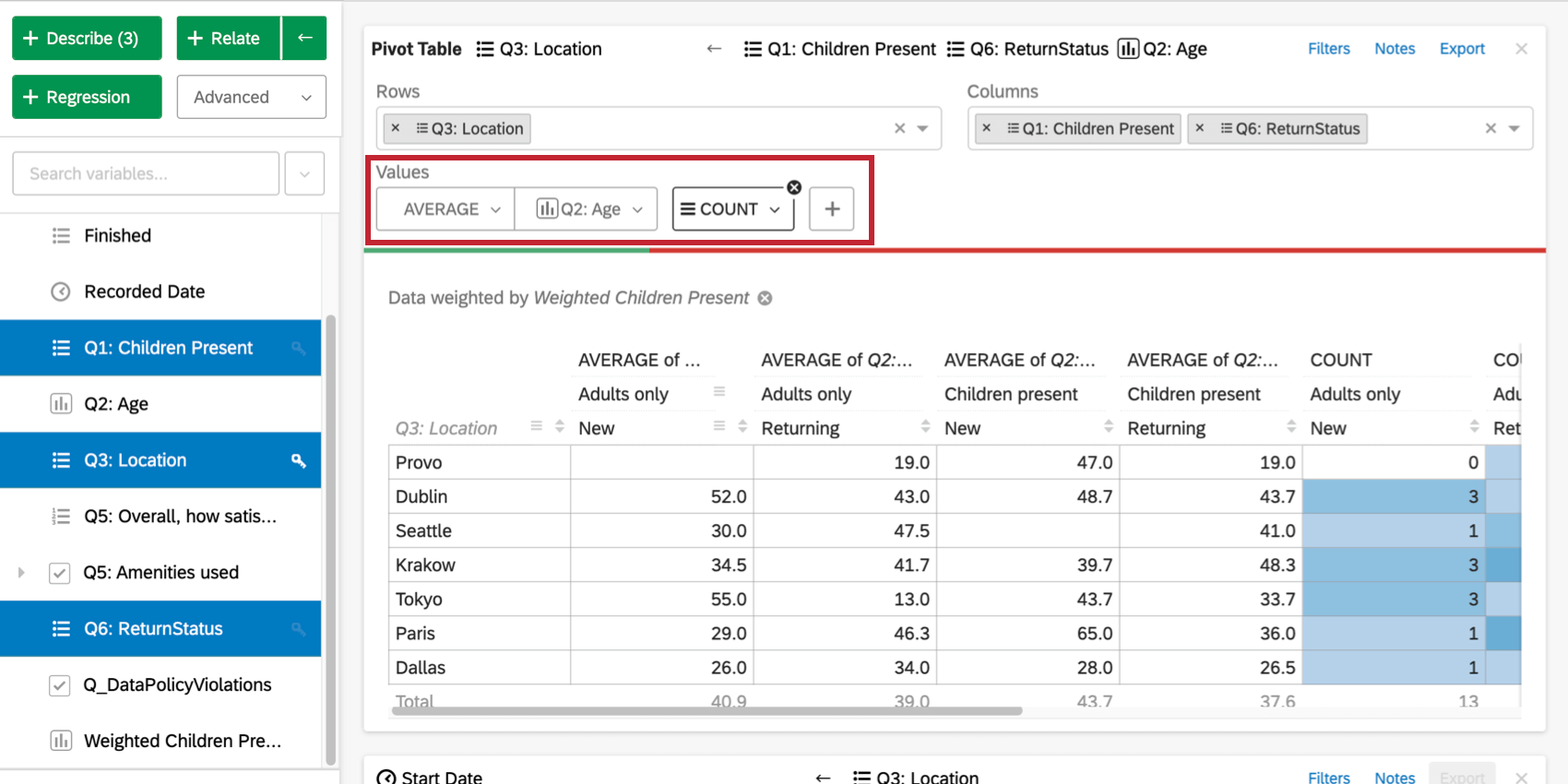
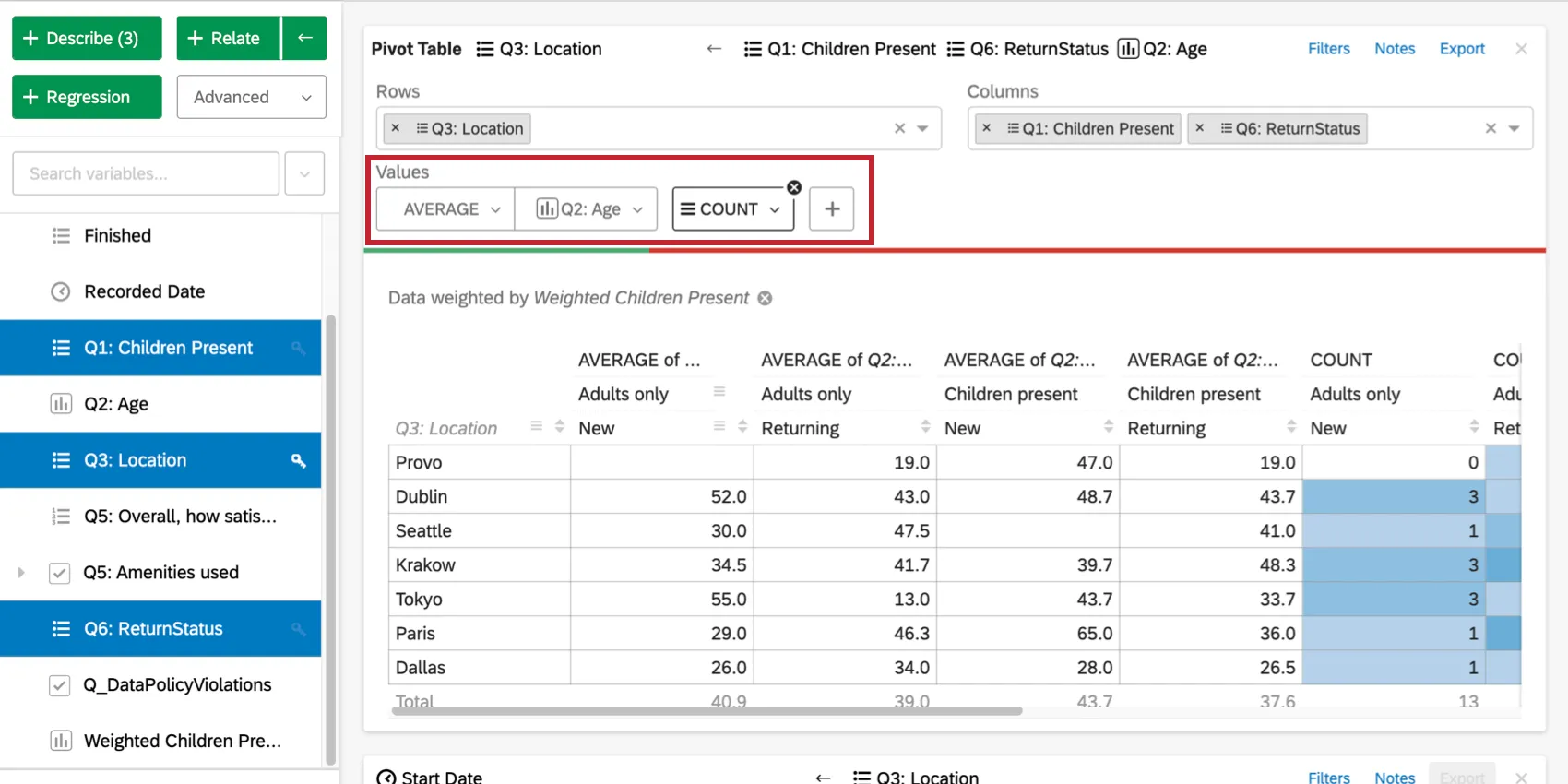
セル値の変更
既定では、ピボットテーブル・カードのセルには列のパーセンテージ (各列が各行の値に占める割合) が表示されます。この値は、「値」の下にあるドロップダウンをクリックするか、最初に数値変数を含めることで変更できる。セル値のオプションの最初のセットは、選択された行と列のデータを使用する。
{kind=link}

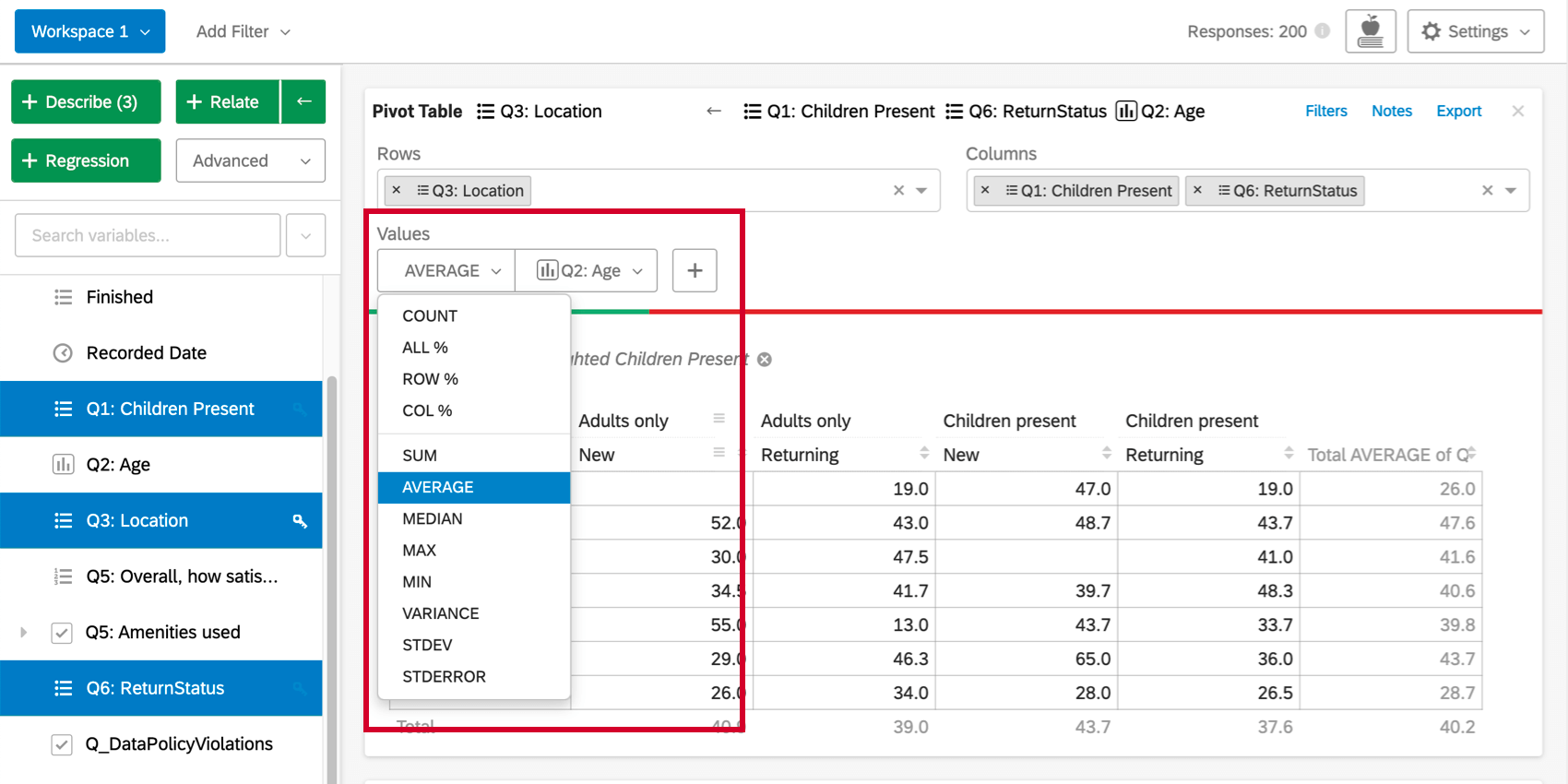
オプションの2番目のセット(合計、平均、中央値、最大、最小、分散、標準偏差)は、データセット内の他の変数の統計値をテーブル・セルに使用することを可能にする。例えば、あるセルに該当する回答者の平均所得を求めることができます。
プラス記号(+)をクリックして、データテーブルに追加することもできます。値の上にカーソルを置くと、並べ替えや削除ができます。
{kind=link}
Stats iQピボットテーブル vs. IQピボットテーブル通常のクロス集計
Stats iQのピボットテーブルは、Data & Analysisのクロス集計セクションで作成されるような、従来のクロス集計とは異なります。
- 従来の「バナーとスタブ」のクロスタブとは異なり、Stats iQピボットテーブルの列に複数の変数を追加すると、すべての列変数の値の組み合わせごとに列が作成されます。伝統的なクロスタブでは、各変数値ごとに列が作成され、ある変数の値が他の変数の値の並列になり、その下に入れ子になることはない。
- Stats iQでは、表のセルで他の(行や列以外の)変数の値を使用することができます。これにより、より幅広い情報が表示される可能性が生まれる。
ピボットテーブル内の統計検定
ピボットテーブルの各セルの有意矢印は、2 つのカテゴリ変数を関連付けるときに作成される表と同じ方法で決定されます。具体的には、矢印は各セルの調整残差によって決定される。Stats iQは、調整残差から計算されたP値に応じて、最大3つの矢印を表示します。結果の重要度に応じて、異なる数の矢印が表示される。具体的には、P値がアルファ値(?)(ここで、? = (1 – 信頼水準)(信頼水準は分析設定の下で設定される)より小さい場合は1つの矢印が表示され、P値が?/5より小さい場合は2つの矢印が表示され、P値が?/50より小さい場合は3つの矢印が表示される。
例えば、信頼水準が95%に設定されていた場合:
- P値 <= .05:1つの矢印
- P値 <= .01:2つの矢印
- P値 <= .001:3つの矢印
FAQs
Stats iQの変数を新規に作成する方法を教えてください。
Stats iQの変数を新規に作成する方法を教えてください。
Stats iQでデータを分析する際のオプションは何ですか?
Stats iQでデータを分析する際のオプションは何ですか?
- Describe:リストから変数を選択し、Describe をクリックすると、その変数に含まれるデータを視覚化することができます。ある変数のデータがどのように分布しているかを確認したい場合に使用します。
- Relate:2つの変数を選択し、Relateをクリックすると、2つの変数間の関係の統計分析が実行されます。2つの変数がどの程度強く相関しているかを知りたいときに使用します。
- ピボットテーブル:2 つ以上の変数を選択してピボットテーブルをクリックすると、変数の値を行と列で表示する表が作成されます。セルには、列や行のパーセンテージ、Sum、Varianceなど、さまざまな情報を表示するように設定することができます。変数の特定の値間の重なりを比較したい場合に使用します。
- Regression:2つの変数を選択し、回帰をクリックすると、変数間の数学的関係が表示されます。ある変数の値から別の変数の値を予測したい場合に使用します。
- クラスター:2~10個の人口統計変数を選択し、「クラスタ」をクリックすると、一緒に発生する可能性が最も高い形質のグループ分けが表示され、データに含まれる人口層が明らかにされます。
この統計用語の意味がわからない。教えてもらえますか?
この統計用語の意味がわからない。教えてもらえますか?
- 統計テスト:ANOVA、T-test、カイ二乗はすべてStats iQが2つの変数間の関係が有意であるかどうかを検定するために行う統計検定です。これらの検定はP-Valueを生成するために使用されます。
- P-Value:この値は、変数間に相関が存在しない場合に、観測された結果が見られる確率を表しています。P-Valueが低いほど、相関のあるデータであることを意味する。
- 効果量:効果量とは、2つの変数間の相関がどの程度大きいかを示す指標である。これは、実施した統計検定の種類によって異なる方法で測定されます。例えば、Cohenのd、Pearsonのr、Cramerのvなどがあり、効果量の数値が大きいほど、変数の相関が高いことを意味する。
Stats iQに表示されるデータをフィルタリングする方法を教えてください。
Stats iQに表示されるデータをフィルタリングする方法を教えてください。
Stats iQに新しい回答を表示させるにはどうしたらよいですか?
Stats iQに新しい回答を表示させるにはどうしたらよいですか?
Stats iQ Workspaceでは、分析カードはどのように並べられるのですか?
Stats iQ Workspaceでは、分析カードはどのように並べられるのですか?
Stats iQって何?/ スタットウィングはどこ?
Stats iQって何?/ スタットウィングはどこ?
What do I do if my data isn't loading properly?
What do I do if my data isn't loading properly?
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!