データを記述する
このページの内容
データの記述について
図表は、変数を視覚化して要約し、データがどのように構成されているかを感じ取り、データの問題点を調べ、後で調査する仮説を考えることを可能にします。記述することを選択したときに複数の変数を選択している場合、各変数について1つの分析が作成され、それらは左側の変数ペインに表示されるのと同じ順序で表示される。
Qtip:ワークスペースには750枚までカードを置くことができます。この制限に達した場合、新しいカードを作成しようとするとエラーが表示され、最も古いカードが削除されることを警告します。
Qtip:カードの上部には緑(場合によっては赤)の線が引かれています。クリックすると、特定のカードについて、「含まれている」、「含まれていない」、または「フィルターによって除外されている」とマークされた回答が表示されます。回答が “Missing “と表示されている場合は、回答者が記述されている質問に回答していないことを意味します。
数とランクの記述
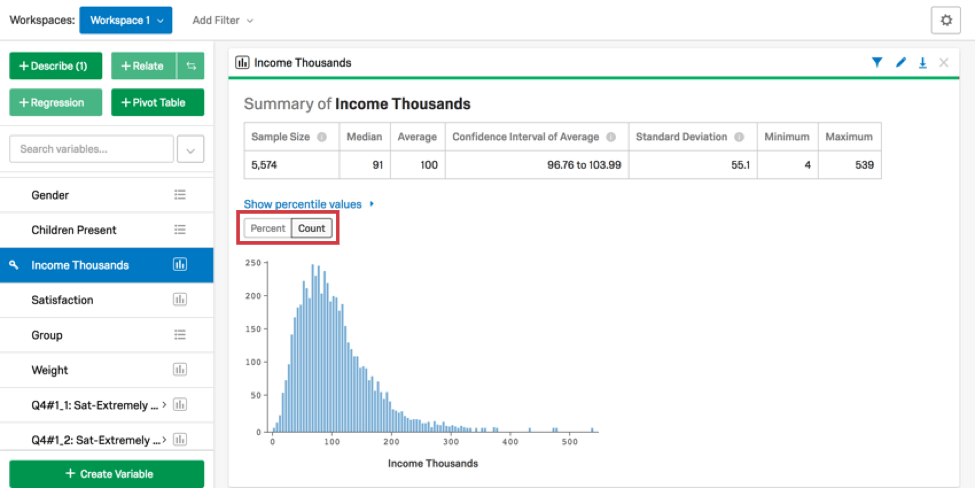
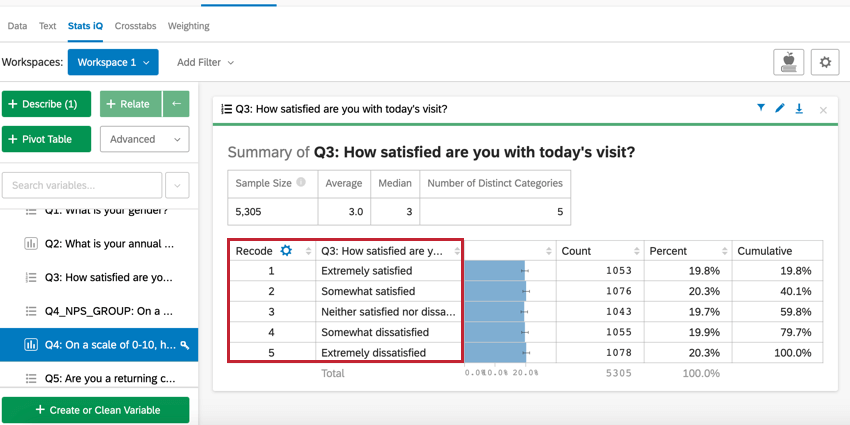
数値変数の説明を選択すると、ヒストグラムと数値サマリーを含むカードが作成される。数値要約には、変数の平均、中央値、最小値、最大値、信頼区間、標準偏差が含まれる。パーセント]または[ カウント]をクリックして、ヒストグラムでのデータの表示方法を変更します。
Qtip: Stats iQでは、CategoriesとCheckbox変数を再コード化できます。再コード化できない変数については、代わりにカスタム変数を作成してみてください。

カテゴリーの説明
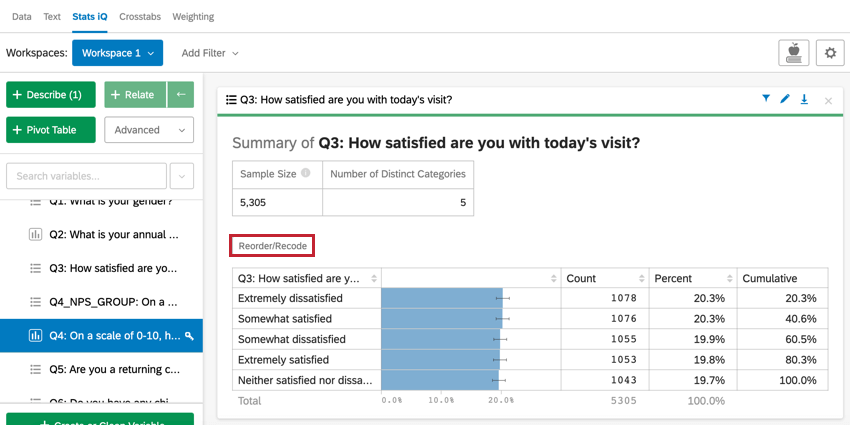
カテゴリ変数を記述するとき、変数中の各カテゴリのカウントと、各レベルの相対的な累積パーセンテージを表示するカードが作成される。
並べ替え/識別値を割り当て
Qtip:変数設定からカテゴリ変数を再コード化することもできます。
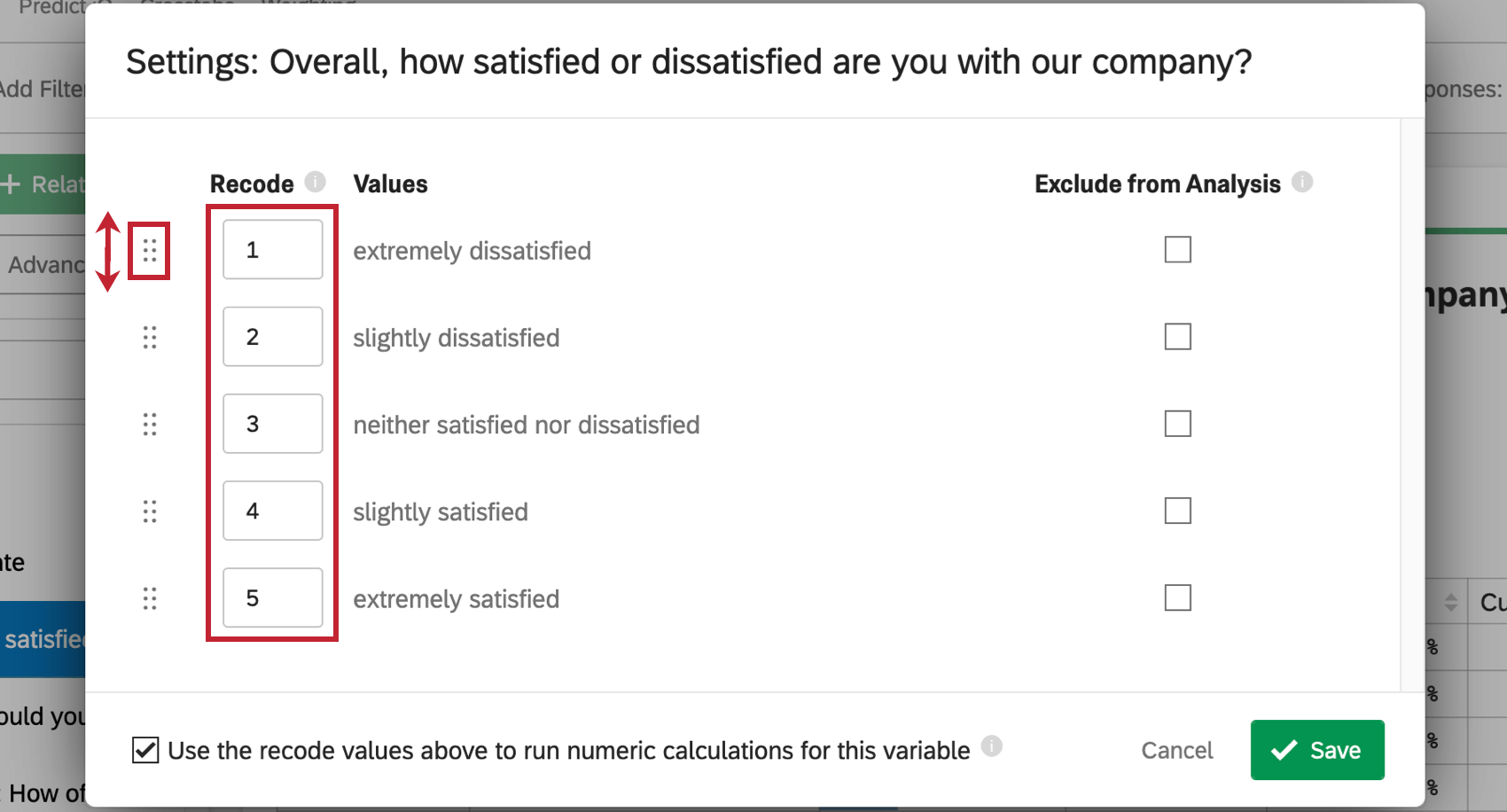
カテゴリーをカードに表示する順番を変更したり、カテゴリーに識別値を割り当てるには、Reorder/Recodeをクリックしてください。これは、例えば “Happy” > “Okay” > “Sad “のように、カテゴリーに特定の順番がある場合に便利です。カテゴリーに識別値を割り当てると、回帰分析などの統計分析も改善されます。
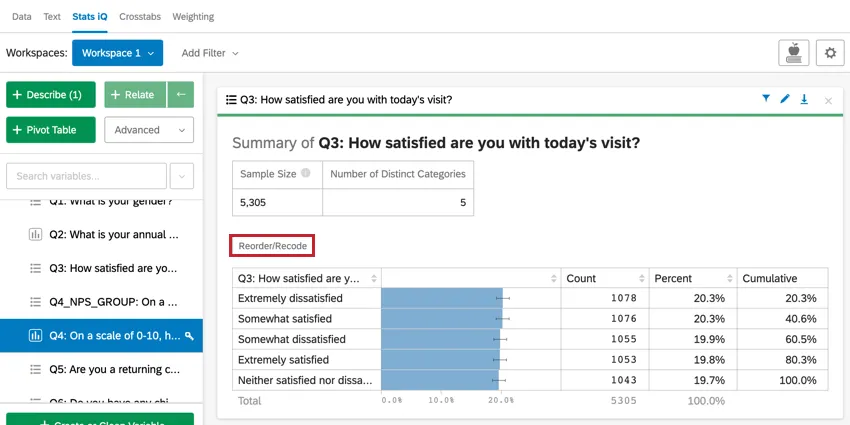
ポップアップが表示され、カテゴリーに識別値を割り当てたり、カードに表示される順序を変更することができます。カテゴリーの次へドットをクリックしてドラッグすると、並び替えができます。カテゴリーに識別値を割り当てるには、Recode ボックスに数値を入力します。

分析からカテゴリーを除外したい場合は、Exclude from Analysis(分析から除外)ボックスをチェックします。これは通常、「該当なし」や「その他」などの回答に使用されます。
また、この変数の数値計算を実行するために、上記の識別値を割り当てを使用するを選択して、これらの識別値がこの変数の他のStats iq分析で使用されるようにすることもできます。
編集が終わったら、Saveをクリックする。これで変数はカード内で並び替えられ、識別値を割り当てた値もカード内に表示されます。

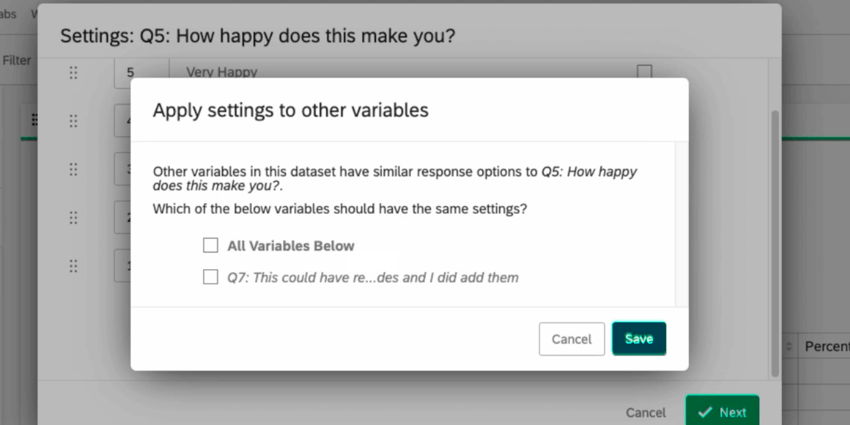
Qtip:“Save “をクリックした後、他の変数に設定を適用するポップアップが表示されるかもしれません。Stats iQは、データセット内の他の類似した変数を認識し、これらの変数に同じ設定を適用しようとします。必要であれば、識別値をこれらの変数にも適用することができる。同じ識別値を割り当てたい変数の次へチェックを入れます。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
日付の記述
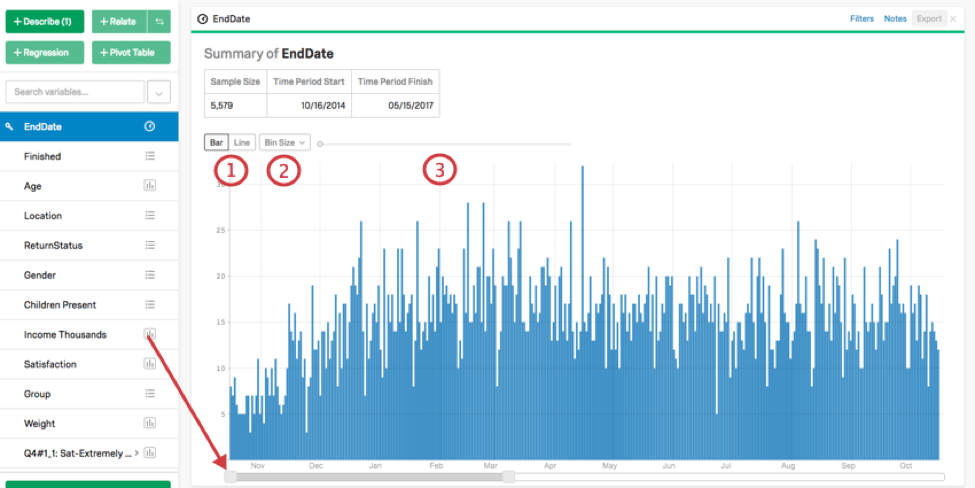
時間変数を記述する場合、与えられた期間内のデータポイントの数を表示するタイムラインを持つカードが作成される。このタイミングの大きさは、グラフの下にあるスライダーを調整することで、カード上で直接変更することができる。
グラフィカル出力の機能を調整するには、左上のオプションを使用します:
チェックボックスの説明
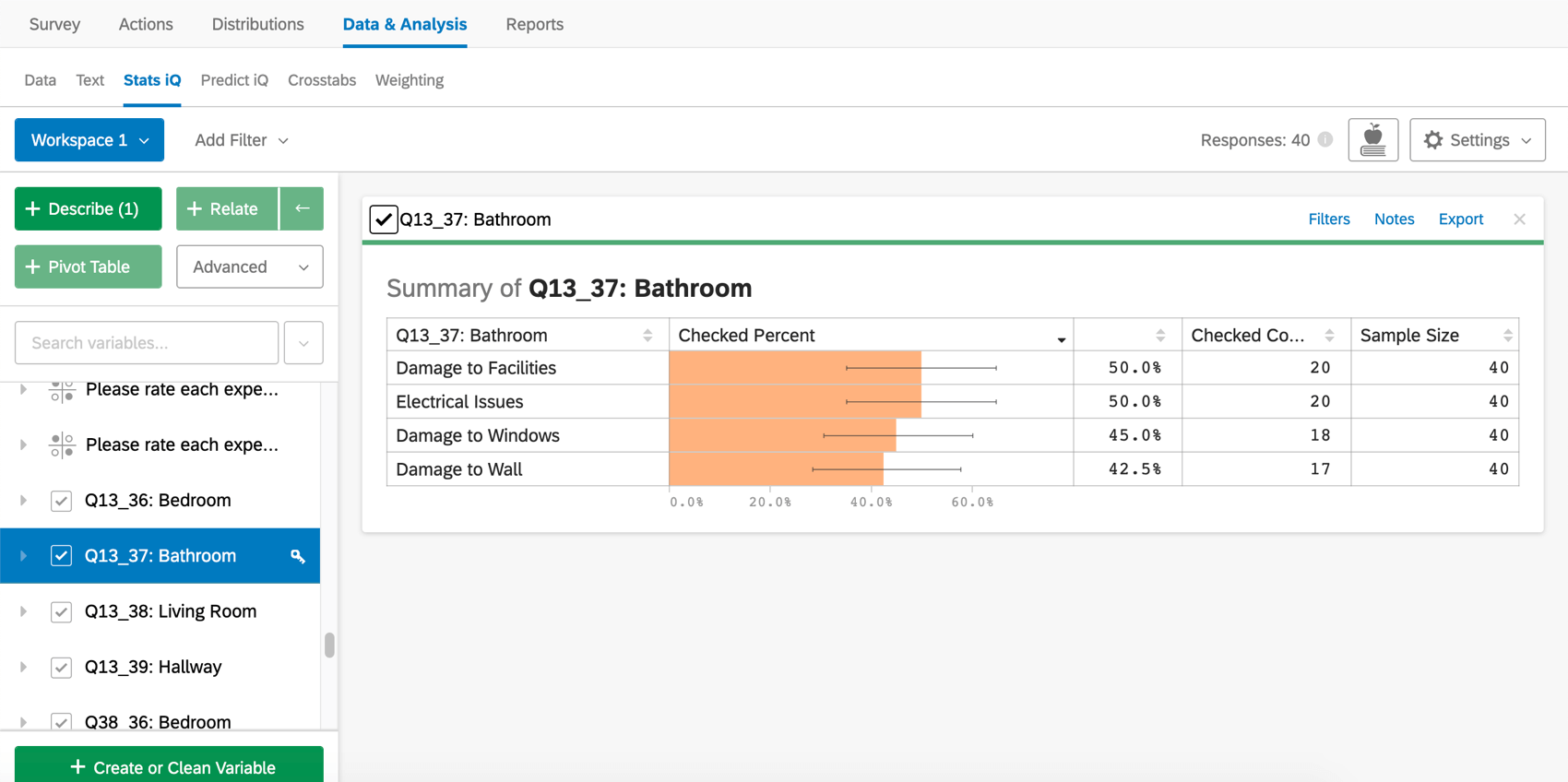
チェックボックス変数を記述すると、カテゴリ変数を記述したときと同じような表を表示するカードが作成される。しかし、チェックボックス変数の場合、回答者が複数の異なるチェックボックスを選択する可能性があるため、パーセンテージの合計は100%にはならない。
{kind=link}

Qtip:チェックボックス変数では、回答者が質問に答えていなくても、サンプルサイズにはデータが含まれます。カードにフィルターを追加してサンプルサイズを変更し、必要に応じて調整することができます。
FAQs
Stats iQでデータを分析する際のオプションは何ですか?
Stats iQでデータを分析する際のオプションは何ですか?
- Describe:リストから変数を選択し、Describe をクリックすると、その変数に含まれるデータを視覚化することができます。ある変数のデータがどのように分布しているかを確認したい場合に使用します。
- Relate:2つの変数を選択し、Relateをクリックすると、2つの変数間の関係の統計分析が実行されます。2つの変数がどの程度強く相関しているかを知りたいときに使用します。
- ピボットテーブル:2 つ以上の変数を選択してピボットテーブルをクリックすると、変数の値を行と列で表示する表が作成されます。セルには、列や行のパーセンテージ、Sum、Varianceなど、さまざまな情報を表示するように設定することができます。変数の特定の値間の重なりを比較したい場合に使用します。
- Regression:2つの変数を選択し、回帰をクリックすると、変数間の数学的関係が表示されます。ある変数の値から別の変数の値を予測したい場合に使用します。
- クラスター:2~10個の人口統計変数を選択し、「クラスタ」をクリックすると、一緒に発生する可能性が最も高い形質のグループ分けが表示され、データに含まれる人口層が明らかにされます。
Stats iQの変数の種類にはどのような意味があるのでしょうか?
Stats iQの変数の種類にはどのような意味があるのでしょうか?
この統計用語の意味がわからない。教えてもらえますか?
この統計用語の意味がわからない。教えてもらえますか?
- 統計テスト:ANOVA、T-test、カイ二乗はすべてStats iQが2つの変数間の関係が有意であるかどうかを検定するために行う統計検定です。これらの検定はP-Valueを生成するために使用されます。
- P-Value:この値は、変数間に相関が存在しない場合に、観測された結果が見られる確率を表しています。P-Valueが低いほど、相関のあるデータであることを意味する。
- 効果量:効果量とは、2つの変数間の相関がどの程度大きいかを示す指標である。これは、実施した統計検定の種類によって異なる方法で測定されます。例えば、Cohenのd、Pearsonのr、Cramerのvなどがあり、効果量の数値が大きいほど、変数の相関が高いことを意味する。
Stats iQに新しい回答を表示させるにはどうしたらよいですか?
Stats iQに新しい回答を表示させるにはどうしたらよいですか?
Stats iQ Workspaceでは、分析カードはどのように並べられるのですか?
Stats iQ Workspaceでは、分析カードはどのように並べられるのですか?
Stats iQって何?/ スタットウィングはどこ?
Stats iQって何?/ スタットウィングはどこ?
What do I do if my data isn't loading properly?
What do I do if my data isn't loading properly?
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!