Amazon S3タスクからのデータ抽出
このページの内容
Amazon S3からのデータ抽出について
Amazon Simple Storage Service(別名Amazon S3)は、データを保存できるサービスです。ワークフローを使用すると、クアルトリクスで使用するためにAmazon S3からのデータ抽出を簡単に自動化できます。
例: 従業員の連絡先情報を最新のスプレッドシートにしてAmazon S3に保存している。この従業員データを定期的にクアルトリクスにアップロードして、従業員エクスペリエンスプログラムに使用したいと考えています。
Qtip:ETLワークフローに適用される一般的な制限については、ワークフローの制限を参照してください。タスク固有の制限については、このページの情報を参照のこと。
始める前に
Amazon S3からのデータ抽出を始める前に、以下の点を考慮してください:
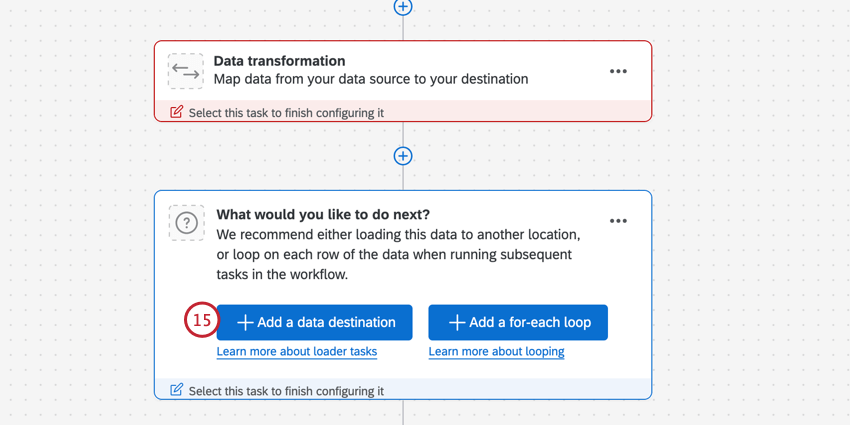
- データを使って何をしたいのか?オプションのリストについては、利用可能なローダータスクを見てください。
- ファイルの形式は統一されていますか?例えば、同じワークフローでインポートしたいファイルは、たとえ値が異なっていても、同じヘッダー/カラム/フィールドを持つべきです。
例: Amazon S3からXM DIRECTORYに連絡先を定期的にアップロードするワークフローを設定します。どのファイルにもFIRSTNAME、LASTNAME、Email、Phone、UniqueID、Locationのカラムがあります。
クアルトリクスとAWSの接続
IAMロールに必要なS3パーミッション
IAMロールは、AWSアカウントに接続するために、以下のS3権限を持っている必要があります。S3のアクセス管理の詳細については、AWSのドキュメントを参照してください。
- s3:DeleteObject
- s3:GetObject
- s3:ListBucket
- s3:PutObject
- s3:AbortMultipartUpload
- s3:ListMultipartUploadParts
例: 以下はロールポリシーのサンプルです。s3:ListBucket “アクションでは、関連するリソースはバケット全体を指すべきです。バケット名の後にスラッシュやワイルドカードを付けることはできません。
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Action":[
"s3:ListBucket"
],
"リソース":[
"arn:aws:s3:::s3bucketname"
]
},
{
"Effect":"Allow",
"Action":[
"s3:DeleteObject",
"s3:GetObject",
"s3:PutObject",
"AbortMultipartUpload",
"s3:ListMultipartUploadParts"
],
"リソース":[
"arn:aws:s3:: s3bucketname/QualtricsPrefix/*"
]
}
]
}.
例: 以下は信託ポリシーのサンプルです:
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Action":"sts:AssumeRole",
"Principal":{
"AWS":"604163242721"
},
"条件":{
"StringEquals":{
"sts:ExternalId":"60ebef7bdexternalidc38d36bc2a6b75cd14f02c73"
}
}
}
]
}.
iamユーザーに必要なs3リソース
IAMユーザーは、AWSアカウントに接続するために以下のS3リソースを持っている必要があります。S3のアクセス管理の詳細については、AWSのドキュメントを参照してください。
- arn:aws:s3:::bucket-name/*
- arn:aws:s3:::bucket-name
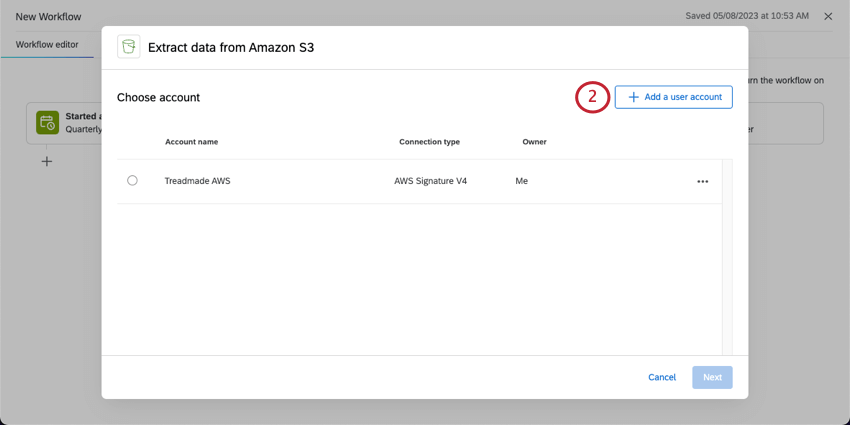
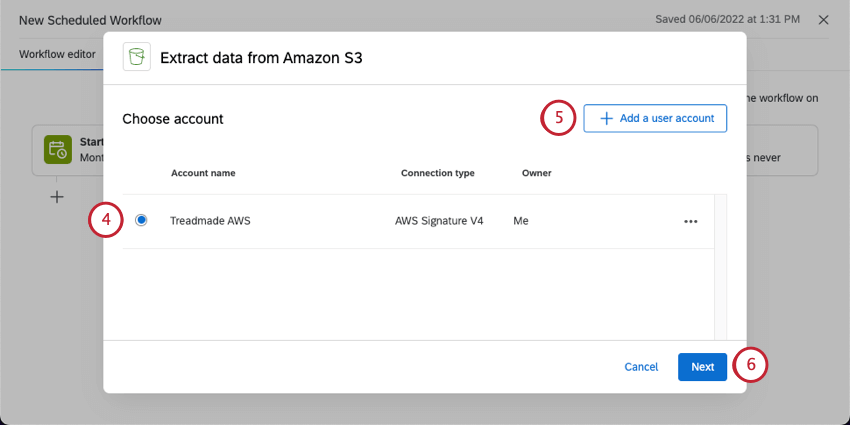
AWSアカウントの追加
この手順では、クアルトリクスアカウントをAmazon Web Services(AWS)アカウントに接続する方法を説明します。
Qtip:AWSのアクセスキー、シークレットキー、IAMポリシーについては、AWSのドキュメントを参照してください。
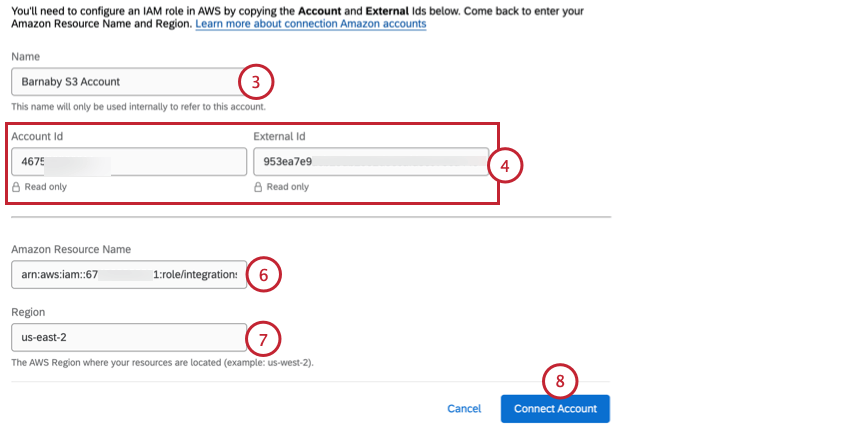
Qtip: アクセスキーとシークレットキーを使った認証機能は廃止されました。過去のクレデンシャルを表示および使用することはできますが、編集することはできません。すべての新しい認証情報は、上記のように AWS IAM Role を使用して設定する必要があります。
ブランド管理者としてアカウントに接続する
ブランド管理者として、ライセンス内の複数のユーザーと共有するAWSアカウントを追加できます。共有AWSアカウントを追加するには、AdminタブのExtensionsセクションに移動し、アカウントを追加したいAWSエクステンションを検索します。
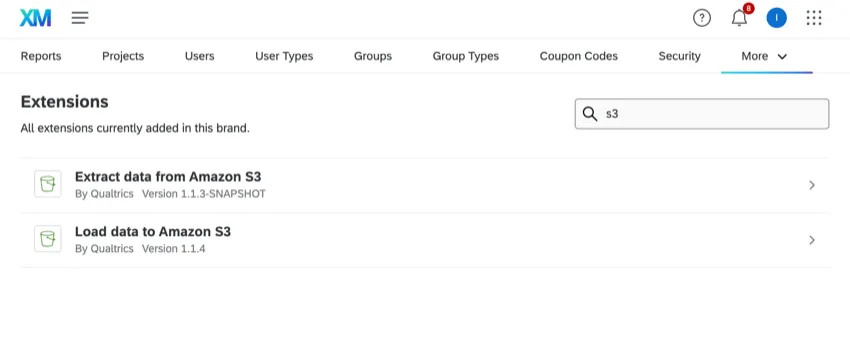
拡張機能を選択したら、上記の手順に従ってAWSアカウントを追加します。また、どのユーザーがアカウントにアクセシビリティを持つかを選択することもできます。
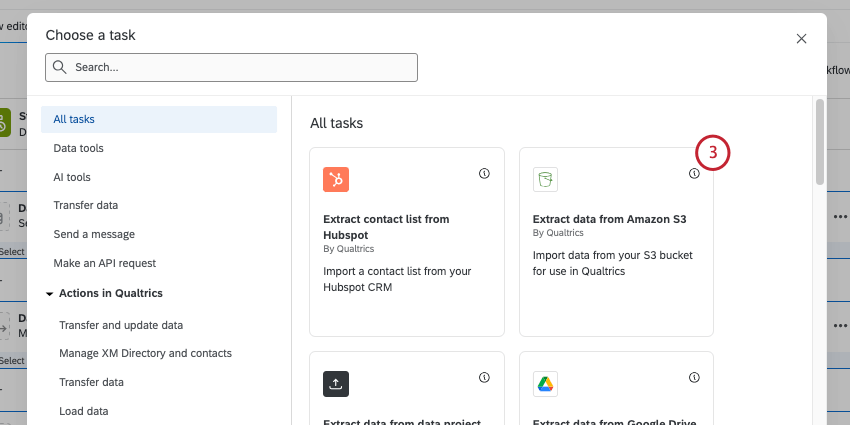
Amazon S3からのデータ抽出タスクの設定
Qtip:5GBのファイルサイズ制限があります。
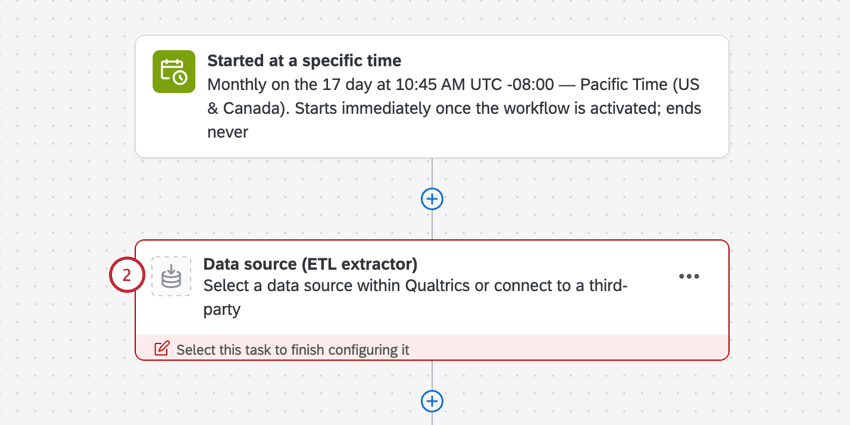
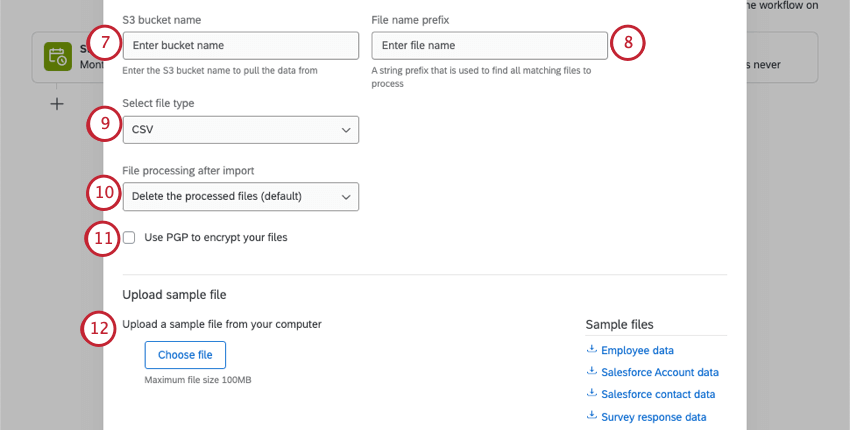
- CSV(コンマ区切り)
- TSV(タブ区切り)
- 処理したファイルを削除する(デフォルト):抽出後、AWSからファイルを削除する。
- 処理したファイルを移動する:処理したファイルを別のバケットに移動します。このオプションを選択すると、処理したファイルを保存するS3バケット名を入力するよう求められます。

- 処理されたファイルの名前を変更する:処理後のファイル名を変更します。このオプションを選択すると、処理後のファイル名に追加するプレフィックスを指定するよう求められます。



Qtip:もしよろしければ、タスクにあるサンプルファイルをダウンロードするか、Example Filesセクションにあるファイルをダウンロードしてください。サポートされているファイルエンコーディング形式はUTF-8のみです。表計算ソフトの中には、UTF-8とは異なるUnicode UTF-8としてファイルを保存するものがあり、予期せぬエラーが発生する場合があります。UnicodeのUTF-8ではなく、UTF-8形式でエクスポートしていることを確認してください。その他のトラブルシューティングステップについては、CSV &; TSV Upload Issuesを参照してください。
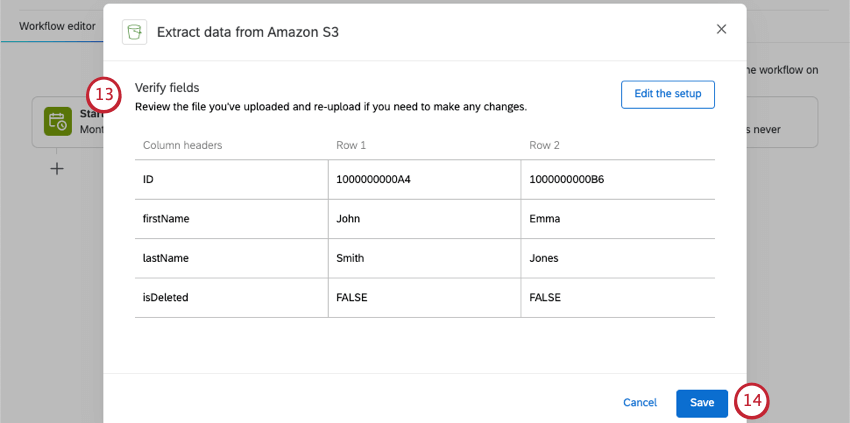
Qtip:別のファイルをアップロードしたり、その他の変更を加えたい場合は、Edit the setupをクリックしてください。
{kind=link}
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!