データモデリングの作成(EX)
このページの内容
ご注意: 2024年11月6日以前に作成されたプロジェクトは古いデータモデルを使用しており、アーカイブ状態に置かれています。アーカイブされたプロジェクトでは、データモデルの編集、公開、更新はできません。過去に公開されたデータ、ダッシュボード、参加者、Stats iQは引き続き利用でき、操作可能ですが、アーカイブされたプロジェクトではダッシュボードの作成とコピーが無効になります。アーカイブされたプロジェクトはコピーできないため、代わりに新しいプロジェクトを作成してください。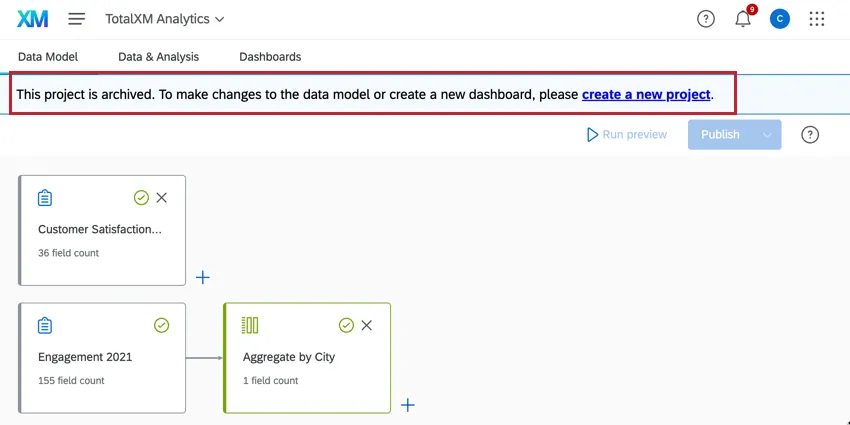
データモデリングの作成について
従業員ジャーニー分析プロジェクトをゼロから新規作成したら、次へ、2つ以上の既存のデータセットを結合するデータモデルを設定します。データ・モデル内では、データ・セットの追加、データ・セットの結合、データのフィルタリング、分析に使用する出力データ・セットの作成が可能です。
あらゆるタイプの従業員エクスペリエンス・プロジェクトのデータを従業員ジャーニー分析モデルにマッピングできます。互換性のあるプロジェクトタイプのリストについては、この表を参照してください。
QTIP: このページでは従業員ジャーニー分析プロジェクトのデータモデルについてのみ説明します。
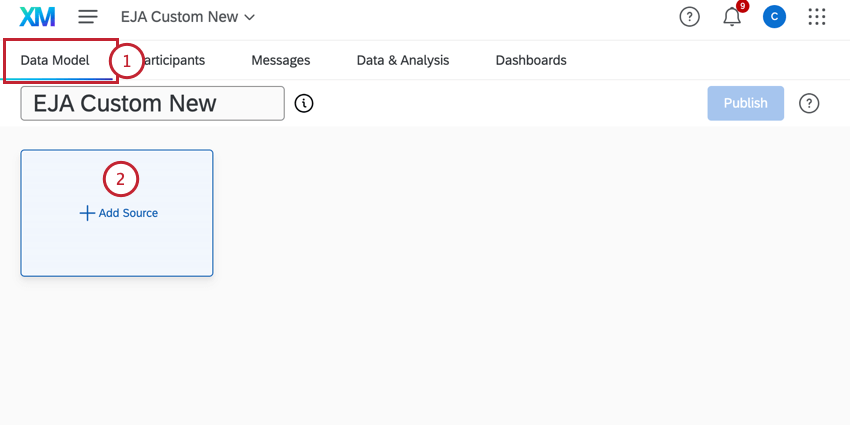
ソースの追加と編集
データ・モデルを作成する際の最初のステップは、ソースを追加することです。
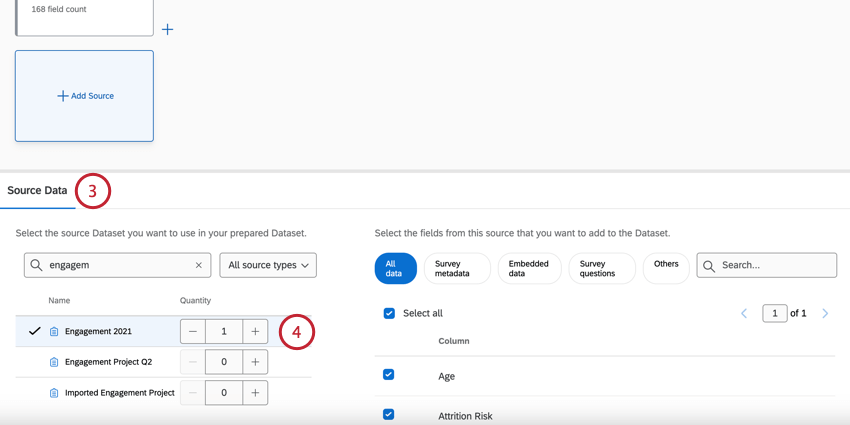
注意: このリストには、あなたがアクセシビリティを持つプロジェクトのみが表示されます。表示されないプロジェクトがあれば、それらがあなたと共有体制にあるかどうかを確認してください。
Qtip:データセット内で別々のユニオンやジョインを実行する場合は、同じソースを複数回追加すると便利です。同じソースの複数のコピーでユニオンやジョインを作成することはできません。
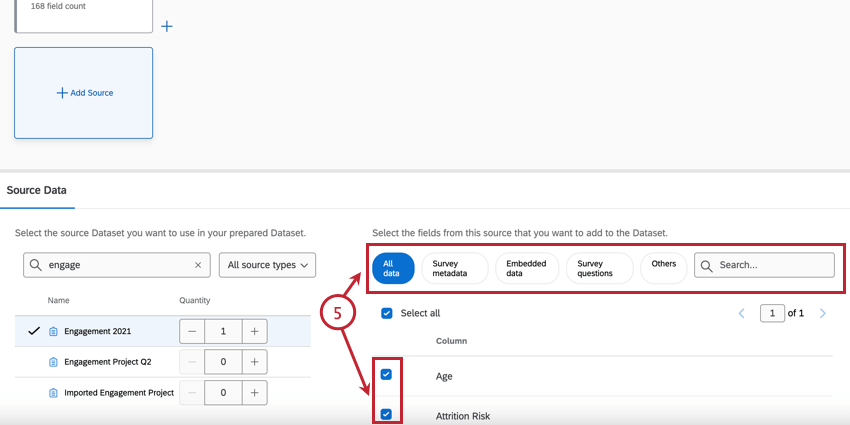
Qtip:データモデルに含めるフィールドを選択するときは、データを分析するときにどのフィールドが重要になるかを考えてください。一般的に含まれるフィールドは、アンケートの質問、重要なメタデータ、データセットを結合するために使用する予定のフィールドです。
Qtip:同じ従業員と組織のデータを含む 2 つ以上のアンケートをデータモデルに追加する場合、このデータを 1 セットだけ含めることができます。同じフィールドを2回含めると、出力データセットとダッシュボードに複製が作成されます。
注意: 各プロジェクトに追加できるソースは最大10個です。
ソースの編集
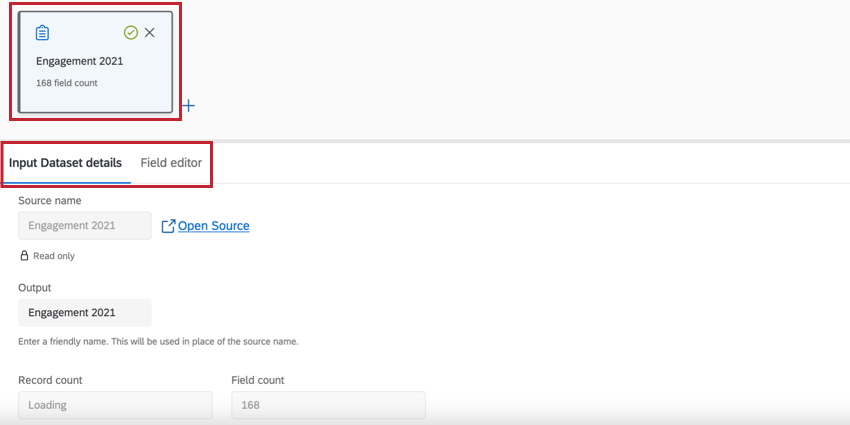
- 入力データセットの詳細:このタブには、データセットのソース名、ソースのレコード数、ソースのフィールド数が表示されます。また、データ・モデルに表示されるソースの出力名を編集することもできる。 Qtip:出力名を編集しても元のソース名は変わりません。

- フィールド・エディタ:このタブには、ソースの追加時に選択したフィールドとそのフィールドタイプが表示されます。フィールドの削除、フィールドの編集、フィールドの再コード化、新規フィールドの追加もここで行うことができる。 注意: ここでの編集により、データソースを変更した接続はリセットされます。フィールドの編集は、データソースを変更する接続を追加する前に行う必要があります。

ソースの削除
データモデルにソースを追加したが、もう必要ないと判断した場合は、xをクリックしてソースを削除してください。

Qtip: ソースがトランスフォームに接続されている場合、ソースを削除することはできません。
注意: ソースを削除すると、マネージャーフィールドで行ったフィールド編集はすべてリセットされます。
データソースの変更
データ・モデルの要素は、行のフィルターや列の編集によって変更することができます。これらのオプションはどちらも、どのデータが結果データセットに表示されるかに影響する。例えば、ソースにフィルタを追加して、過去12ヶ月間のデータのみを表示し、過去1年間の傾向を分析できるようにすることもできます。
Qtip:個々のデータソースと組み合わせたデータソースの両方を修正することができます。
Qtip:一度結合に追加されたデータセットは変更されるべきではありません。フィールドエディタで結合全体を修正することも、結合を削除して個々のデータセットを修正することもできます。
行のフィルター
このセクションでは、データ・モデル内にフィルタを追加する基本について説明します。フィルタおよびフィルタ条件の構築の詳細については、回答のフィルタリングを参照してください。
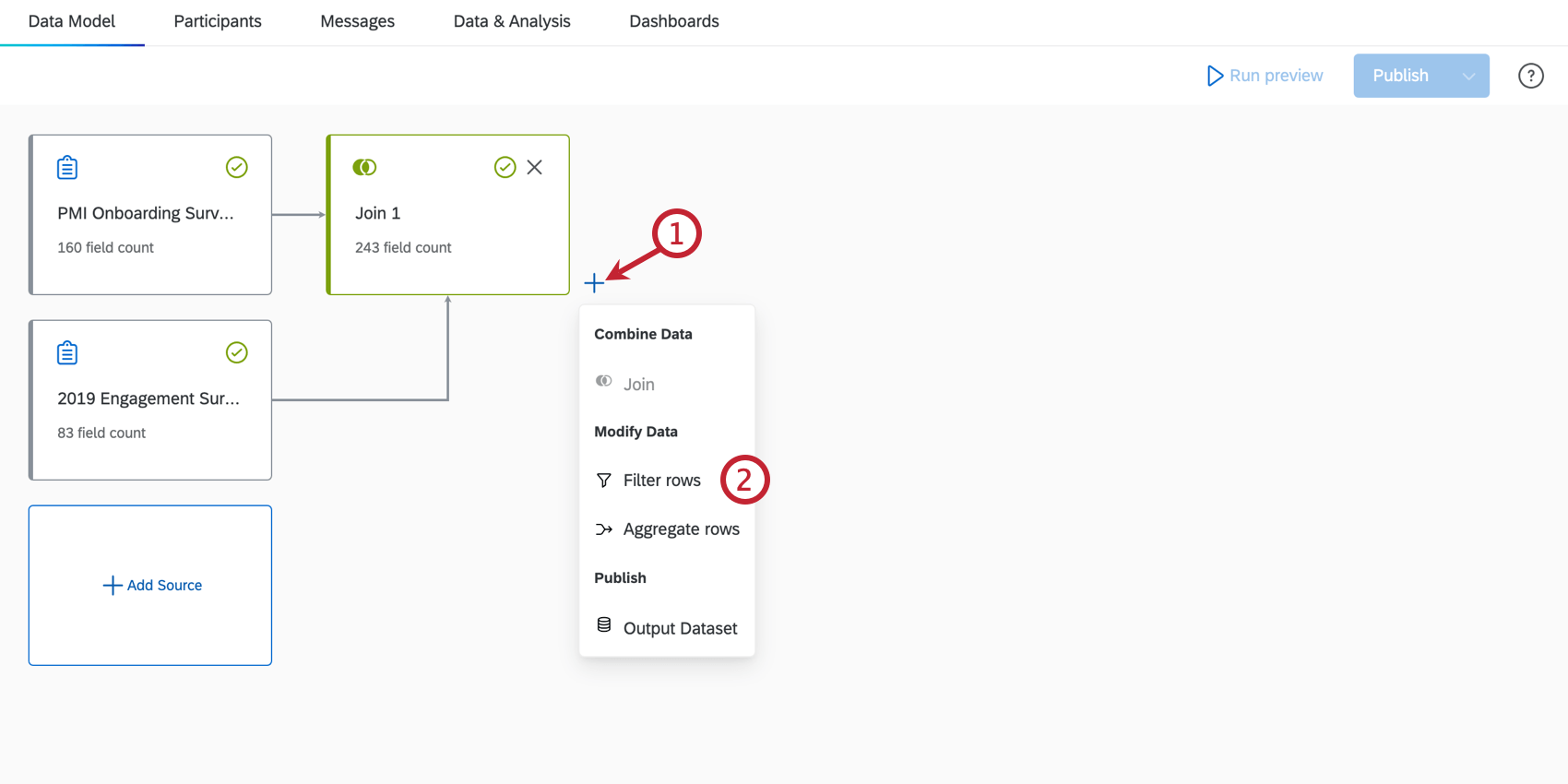
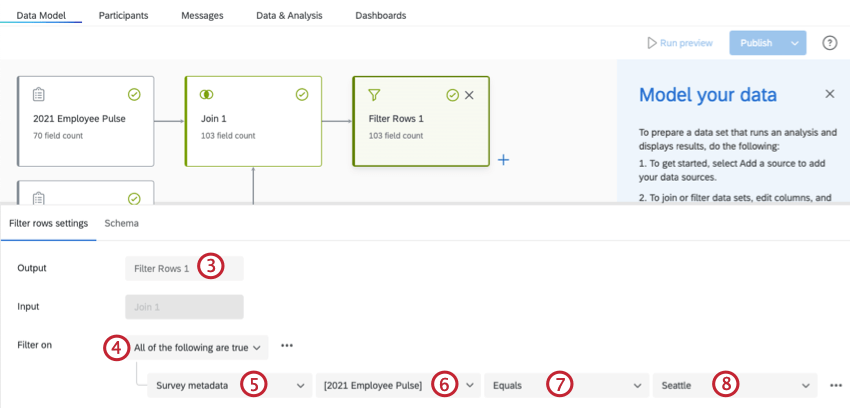
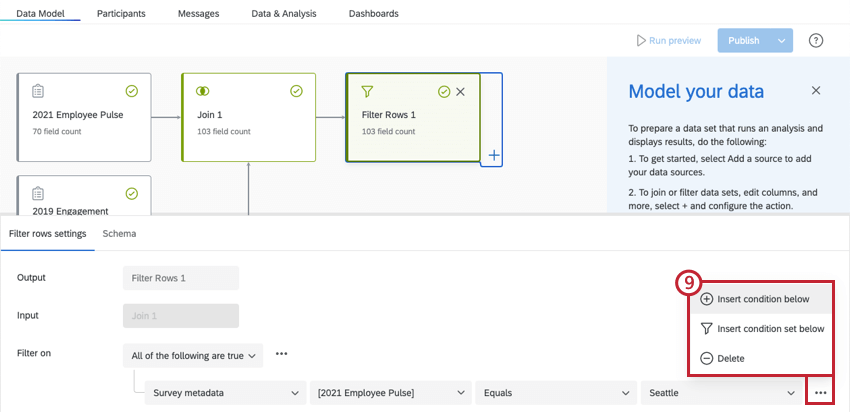
Qtip:フィールドに変更を加えるには、フィールドエディタタタブを使用してください。
フィールドの編集、削除、追加
注意: Joinおよびフィルタ変換を編集すると、現在の変換のフィールドエディタタタブで行った編集はすべてリセットされます。
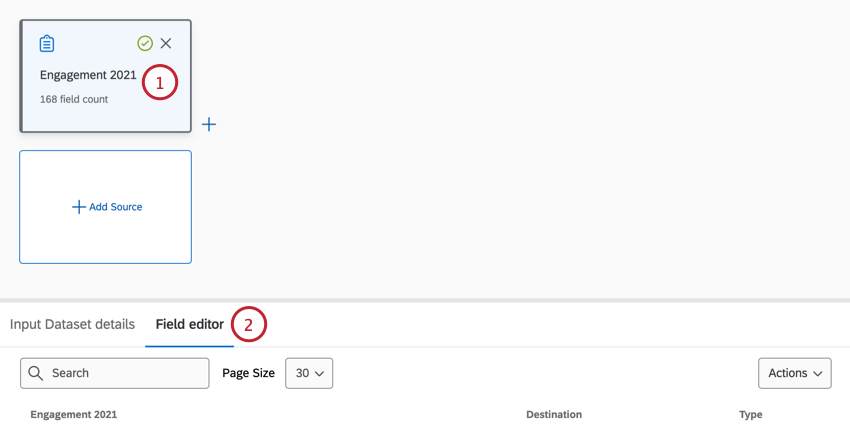
Qtip: ソースコンポーネントと集約行コンポーネントは編集できません。
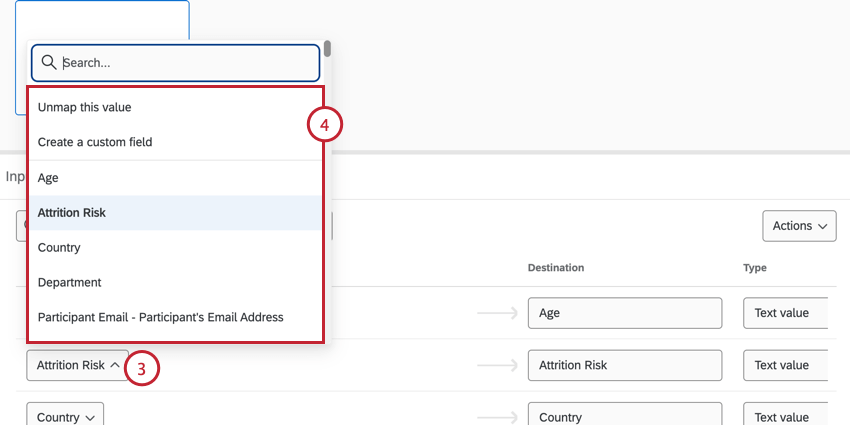
Qtip:特定のフィールドを検索するには、検索バーを使用してください。
- この値のマッピングを解除する:データセットからフィールドのマッピングを解除する。このフィールドは、必要に応じて後でリマップすることができる。
- カスタムフィールドを作成します:データセットに新しいフィールドを作成できます。
- 別のフィールドデータセットの他のフィールドがここにリストされます。代わりにどちらかを選ぶことができる
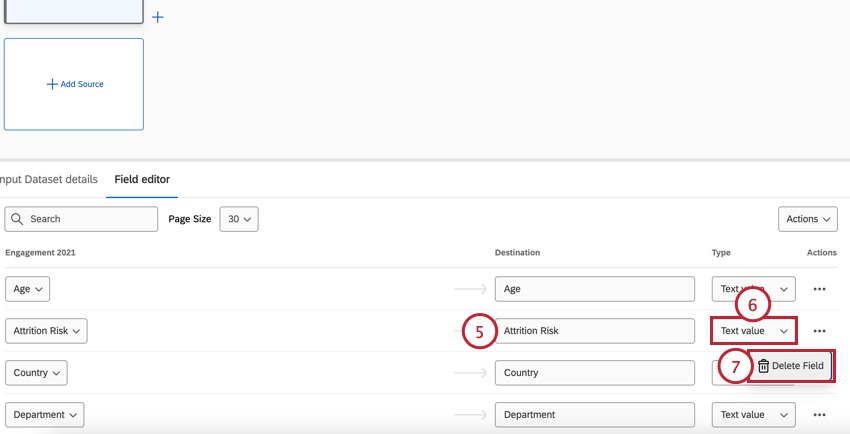
Qtip:フィールドタイプとしてDateを選択した場合、日付フォーマットを指定する必要があります。ドロップダウンからフォーマットを選択し、適用をクリックします。詳しくは「日付書式構文」を参照のこと。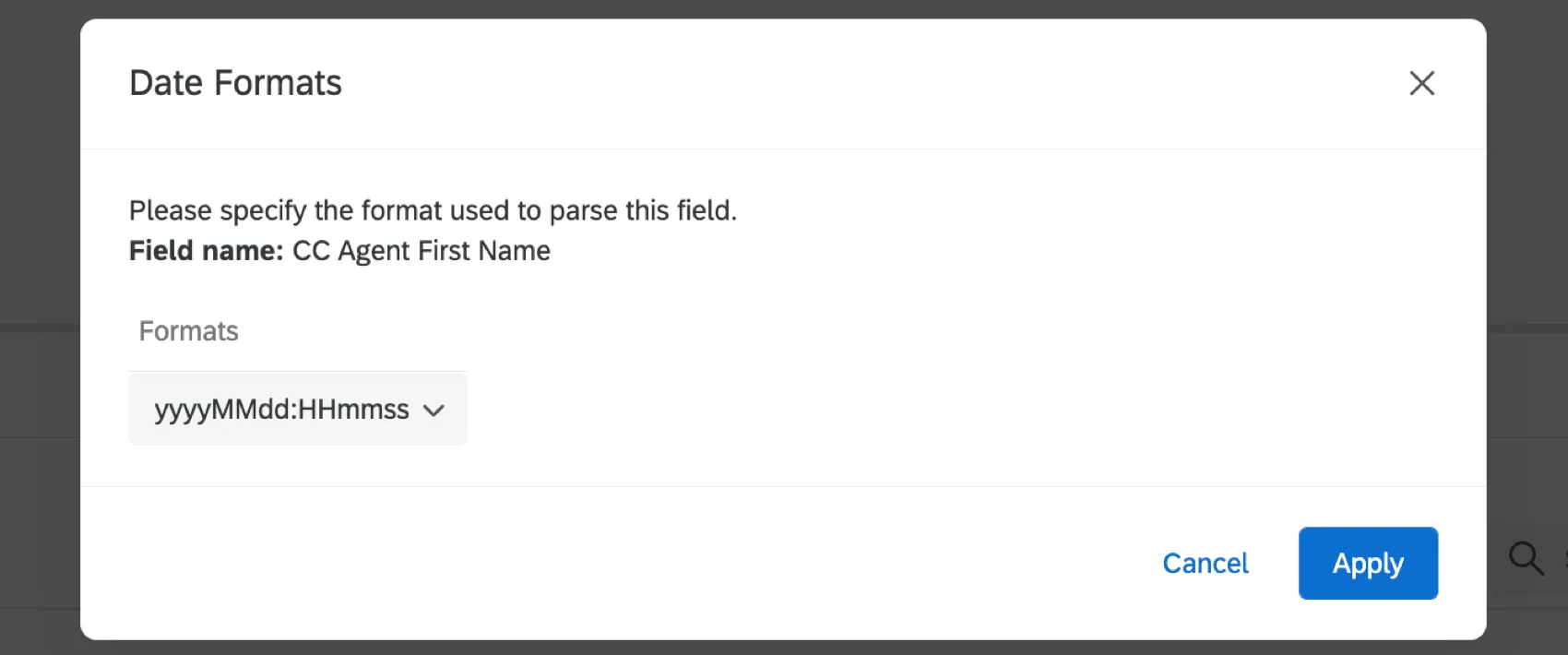
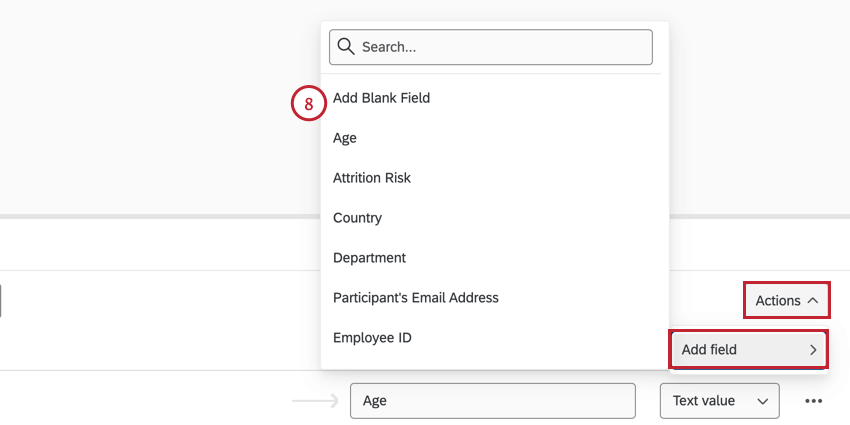
データソースの結合
データ・モデルに少なくとも2つのソースを追加したら、それらの結合を開始できます。
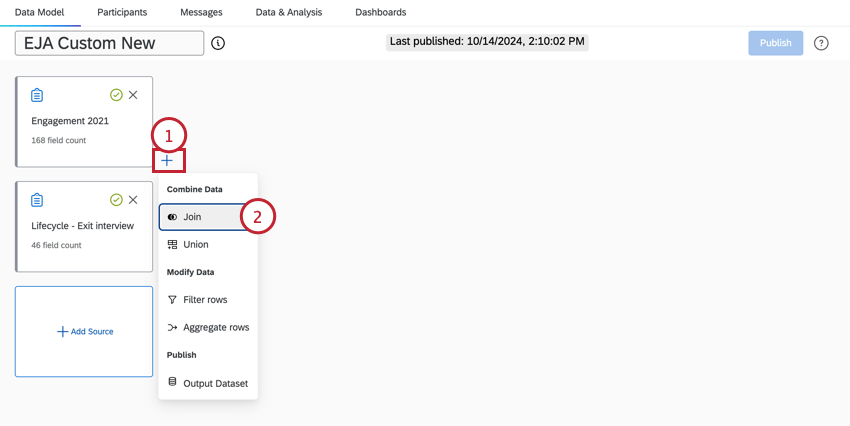
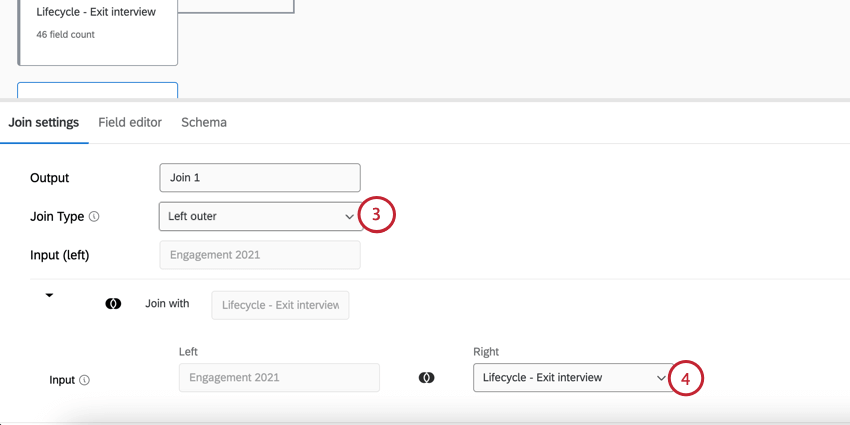
デフォルトでは、データモデリングツールは左外部結合を使用します。つまり、マージされたデータセットには、左の入力のすべての行と、右の入力で見つかった一致する行が含まれることになる。
注意: インナーおよびフルアウタージョインは現在育成中であり、すべてのお客様にご利用いただけるわけではありません。クアルトリクスは、自らの裁量により責任を負うことなく、あらゆる製品機能のロールアウトのタイミングの変更、プレビュー段階または開発段階の製品機能の変更、何らかの理由により、または理由なく製品の機能をリリースしないことを選択する場合があります。この機能にご興味のある方は、アカウントサービスまでご連絡ください。
Qtip:ジョインを設定すると、以前のジョインでまだ選択されていないデータソースだけがドロップダウンに表示されます。
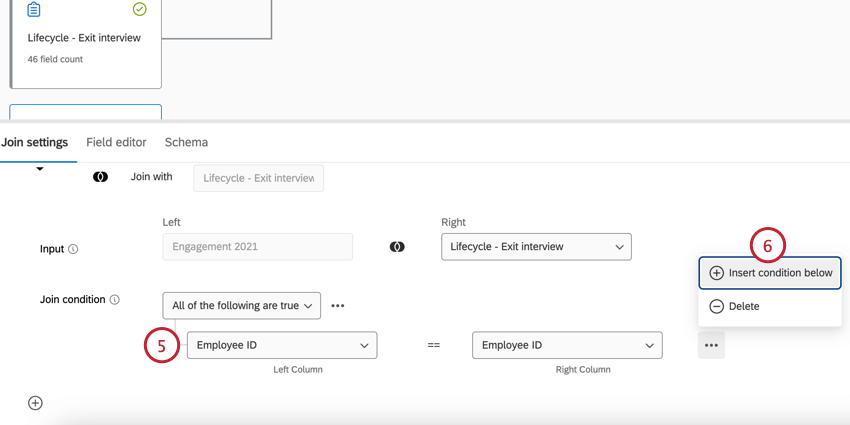
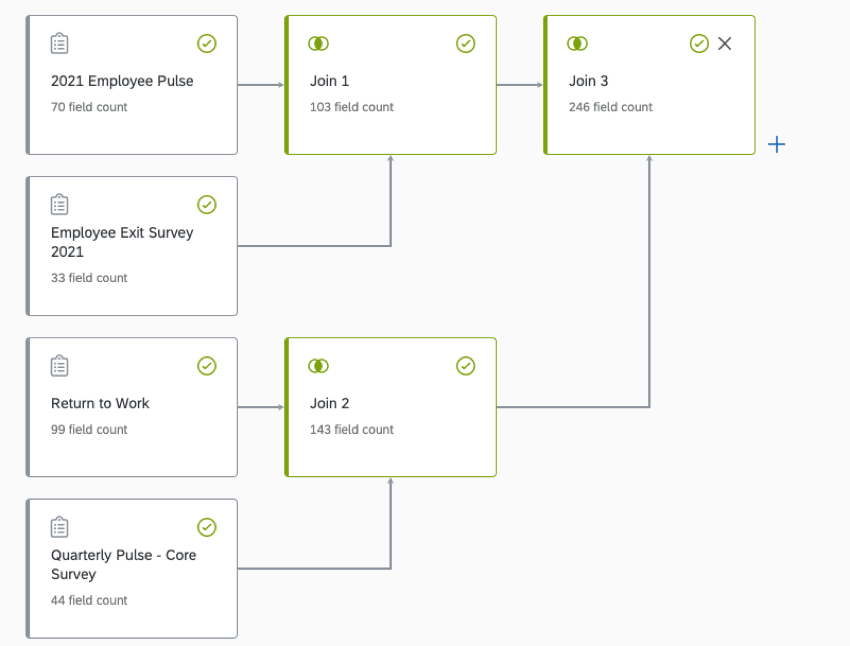
追加のデータセットを組み合わせるには、上記の手順を繰り返す。以下のように、結合したデータセットを組み合わせて、より大きな出力データセットを作成し続けることもできる。

複数の参加者の回答の結合
ソースプロジェクトによっては、参加者がプロジェクト内で同じ一意の識別子に関連付けられた複数の回答を持っている可能性があります(複数の回答が有効になっているライフサイクルプロジェクトなど)。これらの回答がデータモデルで処理される方法は、ソースの結合順序に基づいている。
正しい」ソースに複製結合キー(一意識別子ごとに複数の回答)がある場合、データモデルは1つの回答に結合し、他の回答を削除します。しかし、”left “ソースに重複した結合キーがある場合、”right “ソースの値は、一致する結合キーを持つ “left “ソースの値間で複製されます。
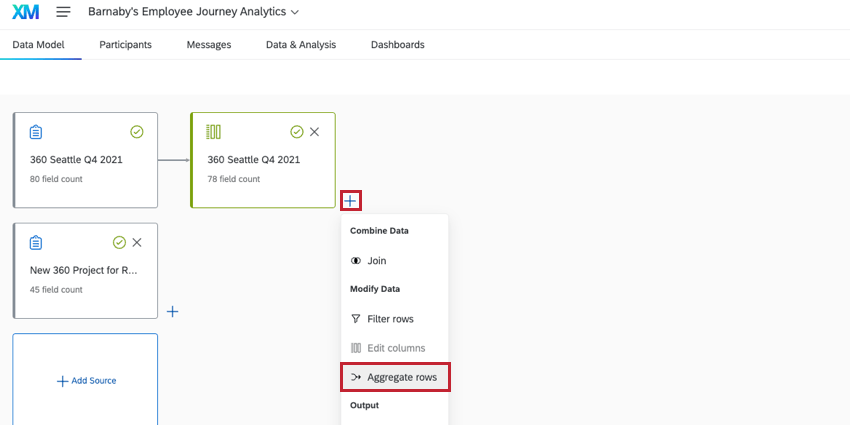
行の集約
データ・モデルの行を集約することで、両方のデータ・セットの変数をレポートすることができます。これは、プロジェクト内に、同じデータを表しながら異なる名前で呼ばれているフィールドがある場合に特に便利です。

行の集約のステップバイステップの手順については、データ・モデリング行の集約を参照してください。リンク先のページではEX + CXレポート機能について説明していますが、従業員ジャーニー分析プロジェクトでデータを集計する手順は同じです(1つのEXと1つのCXではなく、2つのEXプロジェクトを使用します)。
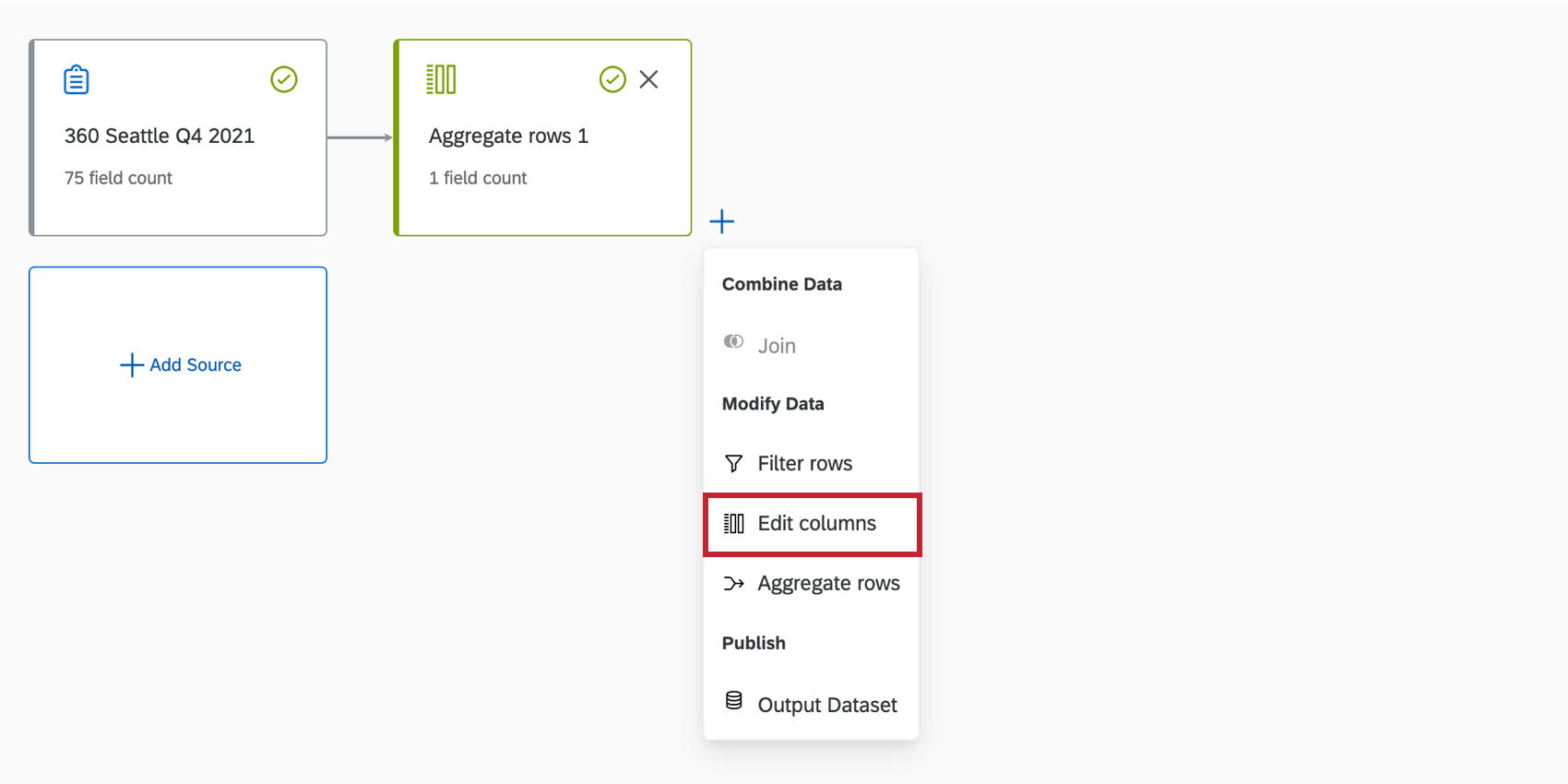
Qtip: 集計行を持つフィールドを編集するには、Edit Columnsコンポーネントを追加し、Field editorタブでフィールドを編集します。

{kind=link}
{kind=link}
{kind=link}
出力データセットの追加
データの結合と修正が終わったら、今度は出力データセットを追加します。
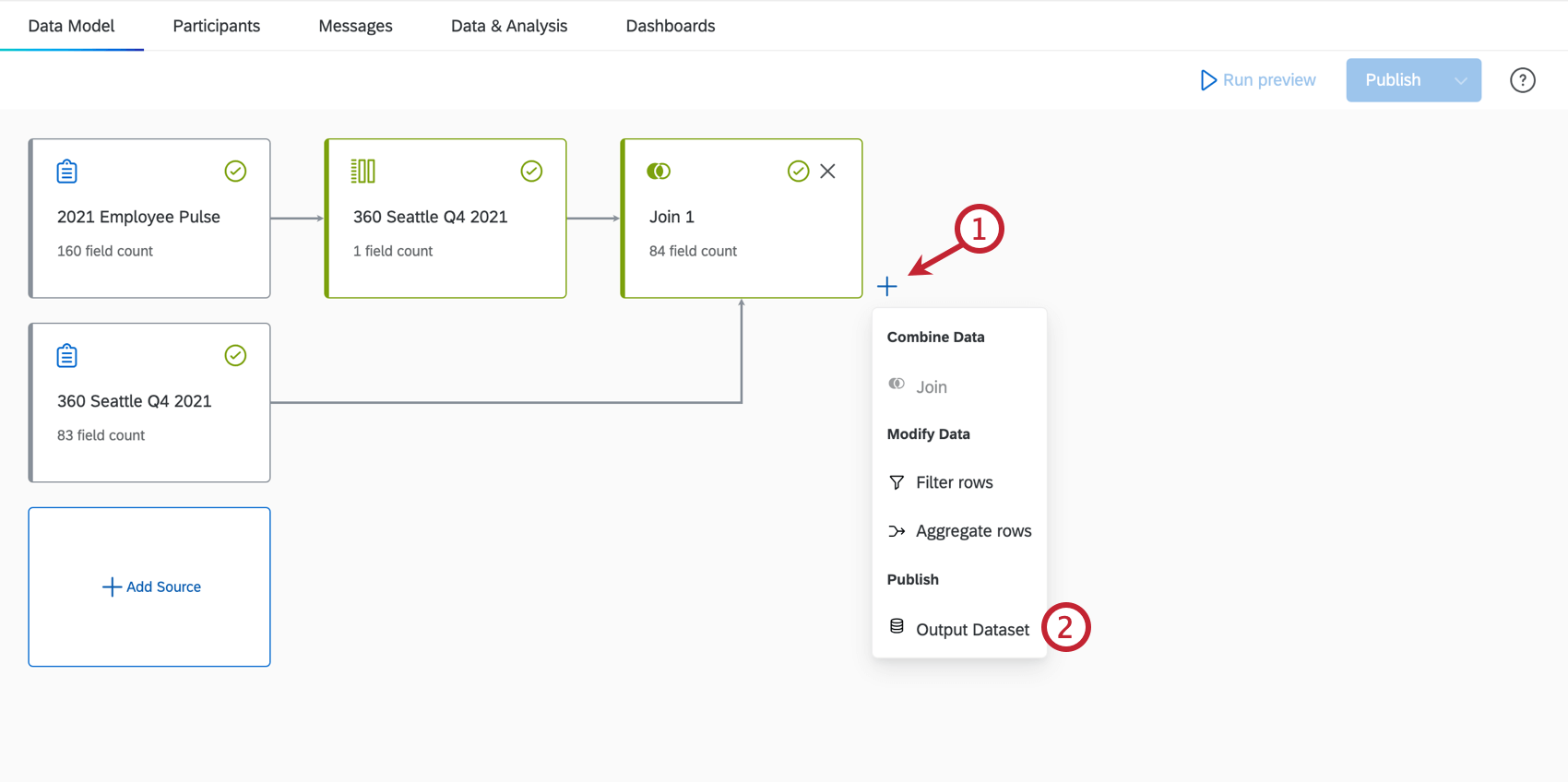
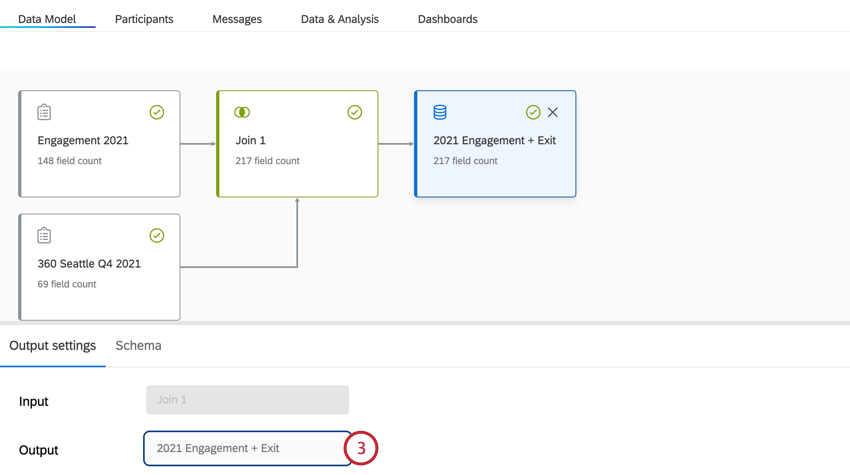
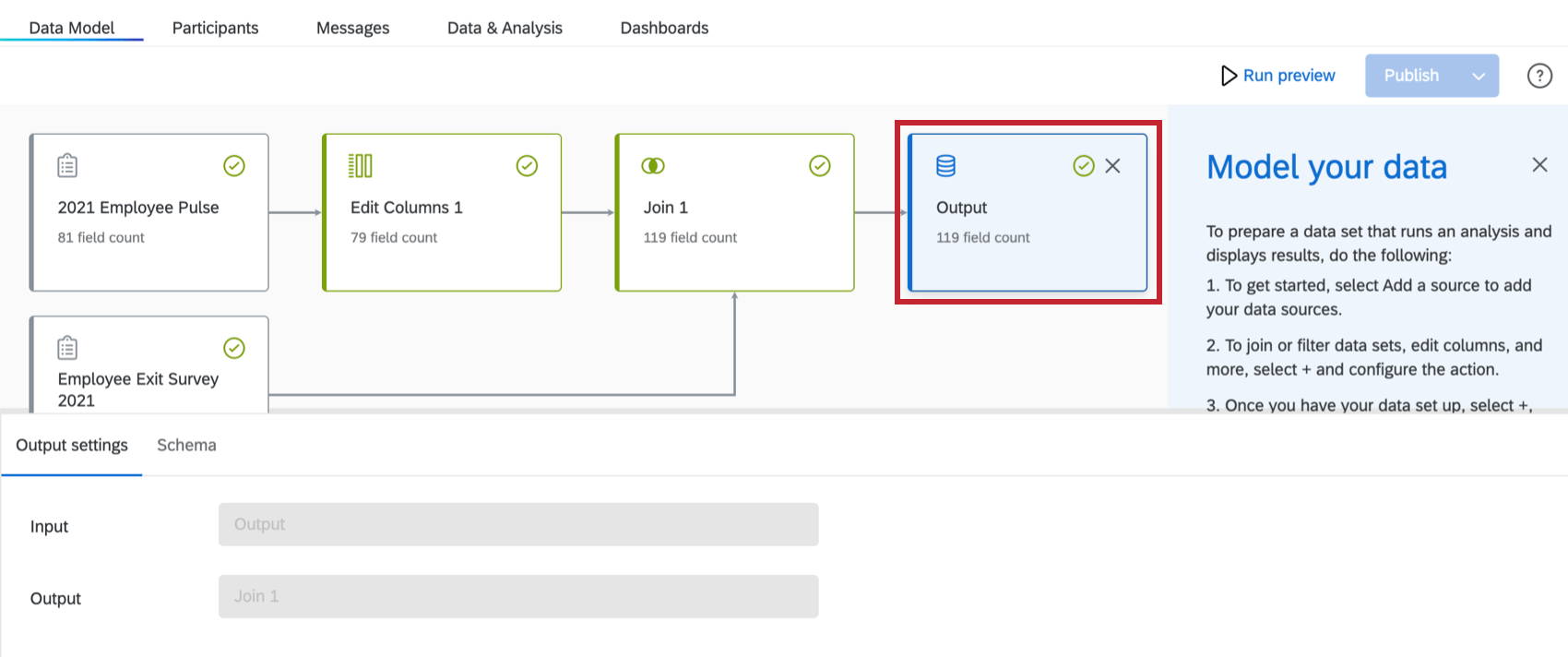
注意: 出力データセットには1,000列の制限があります。
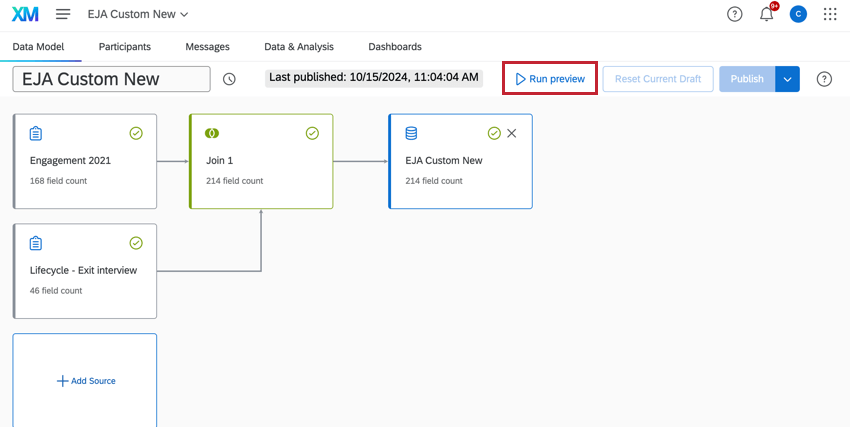
データ・モデリングのプレビュー
データ・モデリングを作成したら、Run previewをクリックして出力データ・セットを生成します。
{kind=link}

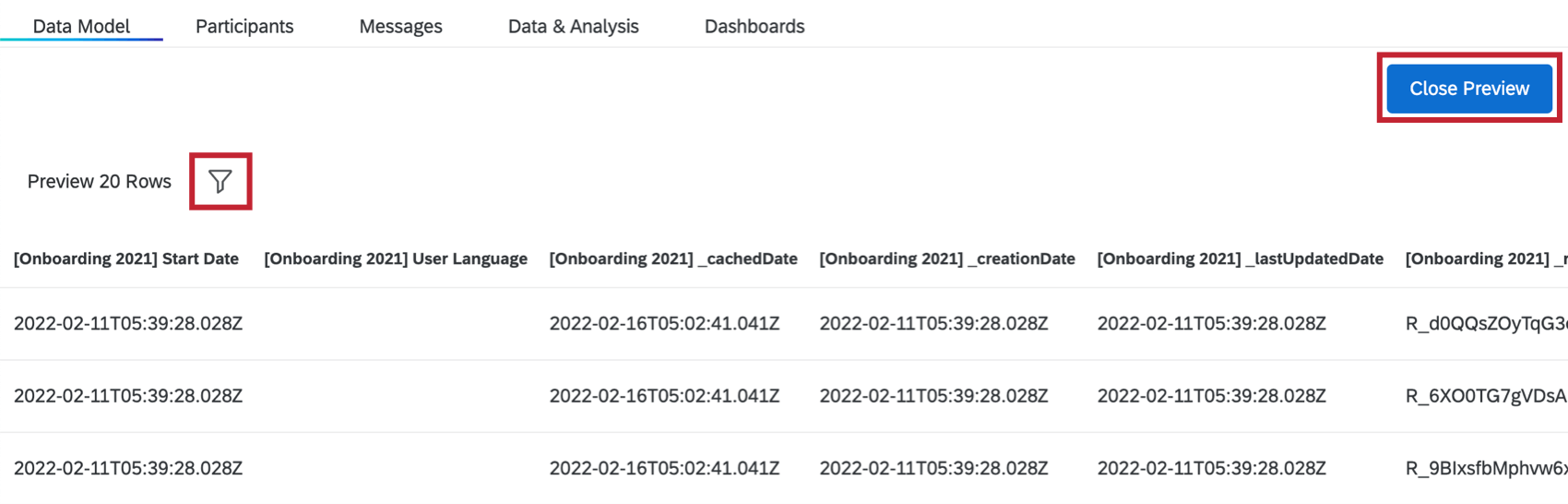
プレビューが完了すると、データセットのプレビューが表示されます。
ご注意: データセットのロードに数時間以上かかる場合は、クアルトリクスサポートにお問い合わせください。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!