-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
匿名性(EX)
匿名性について
匿名性にはベーシックとエンハンスドという2つのレベルがある。各ダッシュボードでは、基本的な匿名性がデフォルトで有効になっており、匿名性を強化することで、さらに保護レイヤーを増やすことができます。詳しくは、Basic vs. Xmlをご覧ください。匿名性の強化.
匿名設定を変更すると、すぐにダッシュボードに適用されます。
基本対基本強化された匿名性
基本的な匿名性
基本的な匿名のしきい値は、ダッシュボードに表示する前に、指定されたデータポイントの回答数を決定します。これは従業員の回答のプライバシーを保護する素晴らしい方法です。匿名のしきい値は、メトリックス(好感度スコア、平均値など)の各データポイントに適用されますが、データのカウント(回答数のきい値)には適用されません。
基本的な匿名性は、従業員の回答を保護しながら、データの分析を柔軟に行うための簡単な方法です。
ページにフィルタを追加する際、しきい値以下の値を選択することができますが、フィルタで選択されたすべてのデータの合計値が匿名のしきい値を満たすまで、データは表示されません。詳細については、ダッシュボードのフィルタを参照してください。
単一フィールドのデータをブレイクアウトする場合、匿名のしきい値以下のメトリクスは非表示になり、カウントが表示されます。複数のフィールドのデータを分割する場合、匿名のしきい値以下のメトリクスとカウントの両方が非表示になります。
回答率のウィジェットには、匿名のしきい値以下のカウントが表示されます。
強化された匿名性
基本的な匿名性がカバーする機能に加えて、匿名性の強化は、特定のユースケースで匿名性を向上させることができるフィルタとウィジェットの詳細区分に追加のレイヤーを追加します。匿名性が強化されると、匿名しきい値は、機密フィールドのすべてのデータポイント(メトリクスとカウント)に適用されるが、そうでないフィールドのデータポイントには適用されない。
匿名性の強化は、従業員の回答を高度に保護するため、データ分析の柔軟性が低くなります。
匿名のしきい値
匿名のしきい値は、ダッシュボードに表示する前に、指定されたデータポイントまたはコメントに含まれる回答数を決定します。データ・ポイントは、ウィジェットのように広範なものから、棒グラフのように具体的なものまである。
デフォルトの匿名しきい値は、データポイントとコメントの両方で5に設定されている。
匿名のしきい値を表示および変更するには、以下の手順に従います:
- ダッシュボードを表示し、[設定]をクリックします。
- 匿名」 タブを開きます。
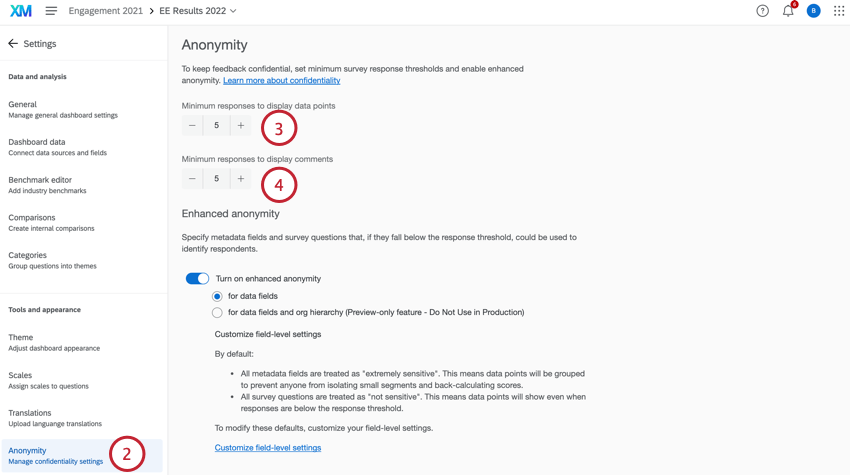
- データポイントを表示する最小回答数]で、ウィジェットにデータを表示する前に収集する回答数を決定します。この制限は、すべてのウィジェットのすべてのデータ区分に適用されます。
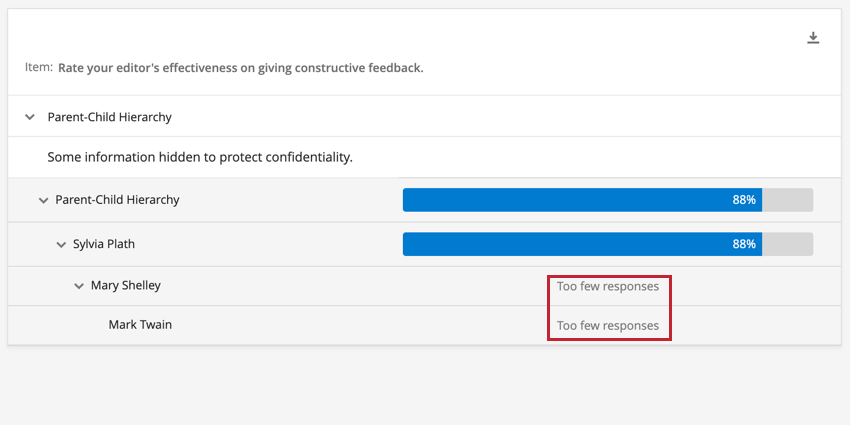
例下の画像は、アクティブな組織階層によって分割された比較ウィジェットです。回答数のしきい値が匿名のしきい値以下のユニットは、ウィジェットにデータが表示されません。回答数のしきい値が匿名のしきい値を超えているユニットは、通常通りデータを表示します。Mary Shelley および Mark Twain ユニットの回答数が匿名のしきい値を下回ったため、ウィジェットにはこれらのユニットの「回答数が少なすぎます」というメッセージが表示されます。
- コメントを表示する最小回答数] で、自由記述による回答をウィジェットに表示するまでに収集する回答数を決定します。
匿名性の強化
匿名性を高めるために、ダッシュボードのレベルで匿名性の強化をオン・オフすることができる。
例えば、バーナビーのチームが15人だとしよう。彼のチームのエンゲージメントスコアを見ても、各メンバーがマネージャーの効果に関する質問にどう答えたかはよくわからない。しかし、彼のチームに女性が2人しかいないとしよう。通常の匿名のしきい値では、女性の回答を直接見ることはできないが、性別フィルターを追加すれば、彼のチームの女性たちがそれぞれ何を言いたかったのか、かなり推測することができる。匿名性の強化は、この種の格差を感知する。匿名のしきい値を満たさないグループのデータは、次へ最小のグループと組み合わされ、データを分割したりフィルターを使用したりする際に、そのグループの回答が隠されるようにします。
- ダッシュボードを表示し、[設定]をクリックします。
- 匿名」 タブを開きます。
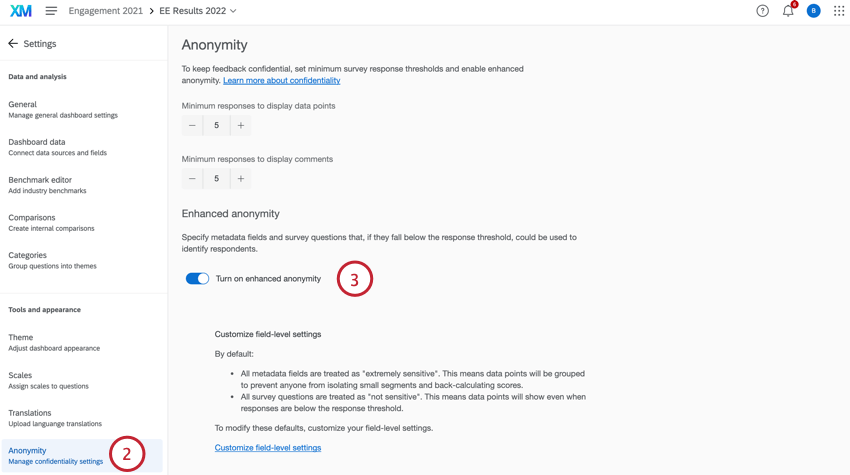
- 有効にする匿名性を強化する。
フィールドレベルの設定
匿名性の強化を有効にすると、ダッシュボードの各フィールドの匿名性のレベルを、「非常に機密性が高い」、「やや機密性が高い」、「機密性が低い」の3段階でカスタマイズできます。これにより、ウィジェットでの詳細区分の扱いと表示方法が変更され、あるフィールドでは回答しきい値以下のデータポイントをグループ化し、他のフィールドでは回答しきい値以下のデータポイントを非表示にすることができます。
参加者が識別できるダッシュボードのフィールドの中には、機微とみなされ、極度に機微またはやや機微とマークされるべきフィールドがあるかもしれない。例えば、在職期間、性別、帰属意識、所属チームなどはすべて、その人が誰であるかを知るために利用できる。しかし、従業員エクスペリエンス調査で尋ねられる質問は、言語、オフィスの所在地、年齢などの人口統計学的な質問を除いて、ほとんどの場合、敏感ではありません。
データフィールドが極端にセンシティブとマークされている場合、匿名のしきい値を満たさないグループのデータは、回答者の身元を保護するために、次へ最小のグループと結合されます。フィールドがやや敏感とマークされている場合、匿名のしきい値を満たさないグループのデータは表示されません。フィールドがセンシティブでないとマークされている場合、センシティブなフィールドでフィルタリングまたはブレイクアウトしない限り、グループ化は行われません。
どのフィールドをセンシティブにし、どのフィールドをセンシティブにしないかを編集するには、次のようにします:
- Settingsへ。
- 匿名」を選択します。
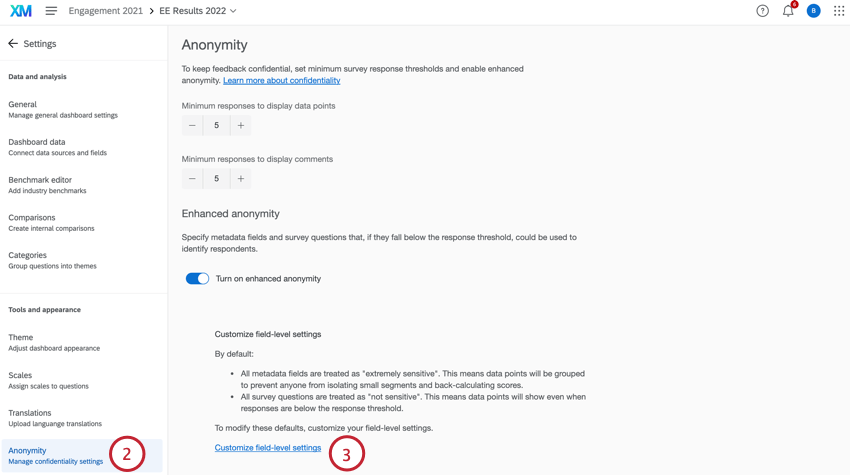
- カスタムフィールド・レベル設定を選択する。
- 各フィールドの次へドロップダウンを使用して、そのフィールドの機密性を選択します。以下のオプションから選択できる:
- 極めて機密性が高い:これらのフィールドには、参加者を特定する情報が含まれています。データポイントが回答しきい値を下回ると、匿名しきい値設定が適用され、データは次へ最小のデータポイントにグループ化されます。これらのフィールドは、以前は識別可能フィールドと呼ばれていた。
Qtip:すべてのメタデータフィールドは、デフォルトで非常に機密性が高いとマークされています。
- やや機微:これらのフィールドには、参加者を特定できる情報が含まれています。回答のしきい値を下回ったデータポイントは、基本的な匿名のしきい値の場合と同様に、表示されません。このオプションは、日付や期間などのフィールドに便利です。
Qtip:このオプションでも、どの参加者が特定の回答を提供したかを把握することは可能です; より感度を高めるには、フィールドに非常に感度が高いというマークを付ける必要があります。
- 機密ではありません:これらのフィールドには、参加者を特定できる情報は含まれていません。回答が回答閾値を下回った場合でも、すべてのデータポイントが表示される。これらのフィールドは、以前は非特定フィールドと呼ばれていた。
Qtip:すべての質問欄は、デフォルトで非感知とマークされています。
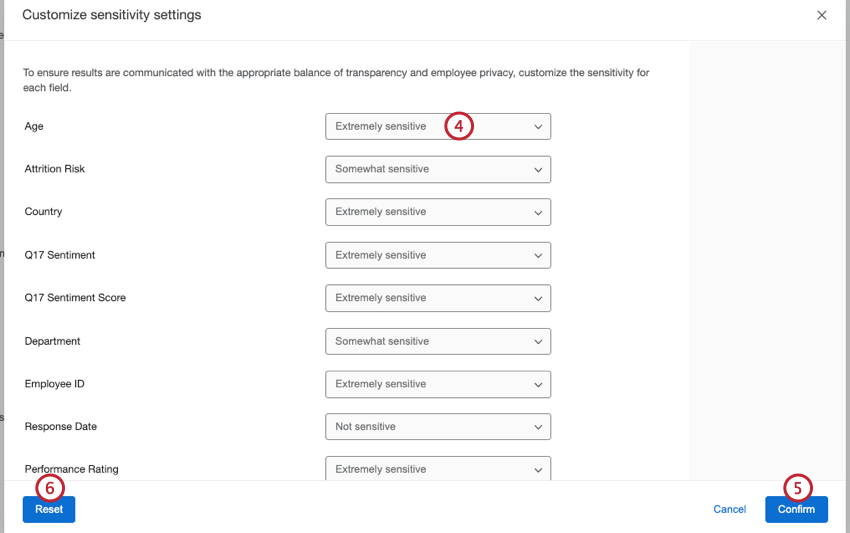
- 極めて機密性が高い:これらのフィールドには、参加者を特定する情報が含まれています。データポイントが回答しきい値を下回ると、匿名しきい値設定が適用され、データは次へ最小のデータポイントにグループ化されます。これらのフィールドは、以前は識別可能フィールドと呼ばれていた。
- 確認をクリックします。
- 元の設定に戻り、変更内容をすべて削除するには、「リセット」をクリックします。
例例: 当社のダッシュボードでは、エンゲージメントの質問は人口統計学的なものではなく、回答者を特定するために使用することはできないため、特定可能としてマークしませんでした。

ダッシュボードのしきい値が5だとします。「勤務先を人に言えることを誇りに思う」のような個人を特定できないフィールドに従業員がどのように回答したかを表示する表を作成した場合、回答はグループ化されません。回答は1つだけだが、「強く反対」がどのように表示されるかは以下を参照のこと。
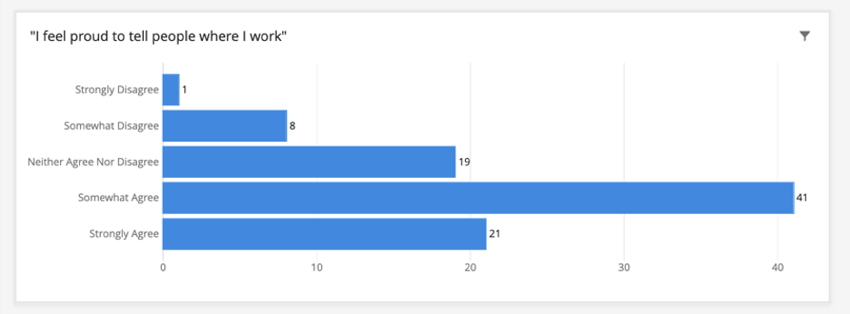
ウィジェット内の総回答数は、依然としてしきい値を満たす必要があることに注意してください。このグラフの総回答数は90である。匿名のしきい値のデフォルトの動作は、しきい値を満たさないウィジェットからのデータを非表示にすることであるため、5未満の場合、グラフは空白になる。
フィールドでの交流
極端にセンシティブなフィールドや、ややセンシティブなフィールドを、センシティブでないフィールドと一緒に表示するためにテーブルやチャートを使用している場合、データをどのように転置しても、データは同じようにグループ化されるはずです。どのフィールドが行または列として構成されていても、グループ化の論理セットはフィールドの設定に基づいて一貫して適用されます。
ダッシュボードデータソースの設定
匿名性の強化を使用する場合、ダッシュボードで過去のデータソースも使用している場合は、ダッシュボードの一般設定で、ページフィルターを現在の年のデータで制限することが重要です。
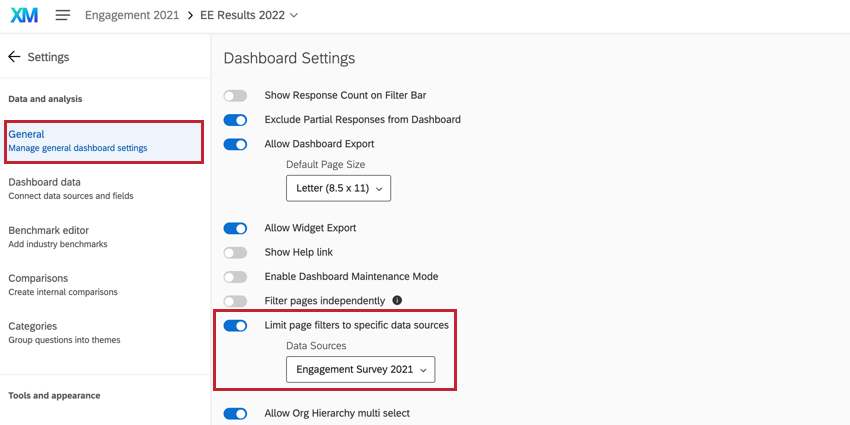
そうでない場合、組織階層フィルタを除くダッシュボード・フィルタのデフォルトはプライマリ・データソースとなり、すべてのデータソースのデータがダッシュボード・データに 含まれます。これは、過去のデータが回答数に含まれる可能性があることを意味し、匿名グループ分けを歪める可能性がある。例えば、小規模チームにおいて、今年の結果だけでなく、現在と過去の結果がカウントされる場合、小規模チームは実際よりも大きく見え、匿名のしきい値を下回らない可能性がある。フィルタをプライマリデータソース(つまり、現在のプロジェクトまたは現在の年のデータ)に限定することで、この問題は解決されます。
フィルターの動作
匿名性の強化を有効にし、ダッシュボードにフィルターを追加すると、匿名性の設定によってフィルターの動作が決まります。
ページフィルターの動作は、各フィールドのフィールドレベルの設定に依存します:
- センシティブでないフィールド:これらのフィールドでは、しきい値以下であっても、任意の値を選択することができます。
- ややセンシティブなフィールド:これらのフィールドでは、閾値を満たすか超える値のみを選択することができます。
- 極めて敏感なフィールド:これらのフィールドは、しきい値以下の値をグループ化する。しきい値以下の結果は、選択される前にフィルタの次へ最小のオプションと結合されます。しきい値を下回るグループが1つだけある場合、次へのグループがしきい値を満たすかどうかに関係なく、次へ最も小さいグループと組み合わされる。これは、たとえ1つのグループだけが閾値を満たしていなくても、そのデータが保護されるようにするためである。
フィルターが追加または削除されると、匿名性が強化され、これらのアカウントが考慮され、それに応じてグループ分けが変更されます。
例下のスクリーンショットでは、部門別にフィルターをかけようとしています。ここは小さな会社なので、財務、サポート、リソースは非常に小さなチームで、私たちが設定した匿名のしきい値以下です。
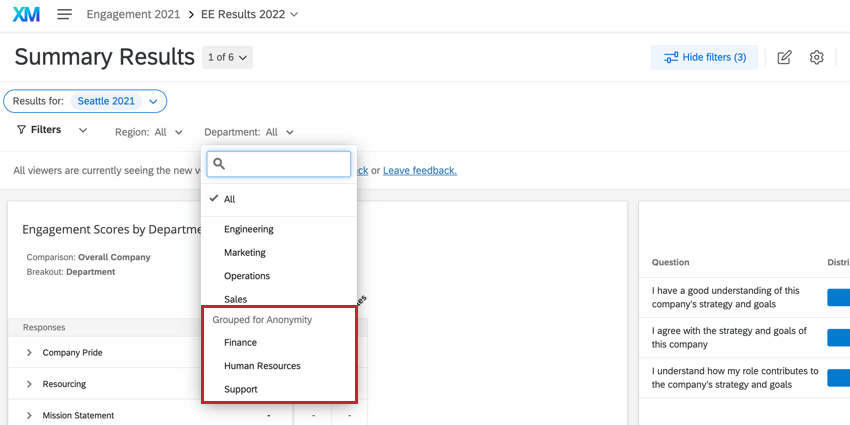
財務」、「サポート」、「リソース」が「匿名性のためにグループ化された」というヘッダーの下にあることがわかります。片方だけを選択しようとすると、自動的に両方が選択されてしまうのだ。片方を選択解除しようとすると、両方とも選択解除されてしまう。これにより、ユーザーは閾値以下のグループの値を把握することができなくなる。
組織階層フィルター
匿名のしきい値を満たさない組織階層の特定ユニットはグレーアウトし、その次へロックアイコンが表示されます。匿名のしきい値を満たさないユニットは選択できません。これは回答者の匿名性を守るためである。
![]()
詳細区分行動
匿名性の強化が有効になっている場合、各フィールドのフィールドレベルの設定は、データが特定のグループに分割されているウィジェットでデータがどのように表示されるかを決定します。これには、X軸ディメンションが定義されたラインウィジェット、比較が追加されたウィジェット、デモグラフィックの詳細区分ウィジェット、ヒートマップウィジェット、匿名のしきい値より小さいグループを分離するその他のウィジェット構成が含まれます。
- 非感知フィールド:これらのデータ・フィールドは、しきい値を下回っていても、すべてのデータ・ポイント(メトリクスとカウント)を表示します。
- ややセンシティブなフィールド:これらのフィールドには、回答数のしきい値を満たすか超えるデータ・ポイント(メトリクスとカウント)のみが表示されます。
- 非常にセンシティブなフィールド:これらのフィールドは、しきい値以下のデータ・ポイント(メトリクスとカウント)をグループ化します。
このルールの例外は、組織階層ごとに分割されたウィジェットです。一部のウィジェット(ヒートマップ、デモグラフィックの詳細区分)は、組織階層フィルターで現在選択されているユニットの各子ユニットのデータを表示するOne Level Below区分をサポートしています。他のウィジェット(回答率、比較、バブルチャート)は、階層へのドリルダウンに対応しており、各ユニットのデータを表示し、ユーザーが選択できるようになっている。組織階層別に分けられたウィジェットでは、匿名性は適用されない。つまり、匿名のためにグループ分けされることはない。
指標を平均エンゲージメントスコアやNPSに変更する場合、匿名性を強化することで、ダッシュボードユーザーがそのオフィスのデータを分離できないようにすることで、最小のオフィスのデータを把握することができなくなる。これは、例えば、最も小さな事務所の各メンバーの評価を簡単に計算させたくないような場合に便利である。
例:
次の例では、小規模オフィスの従業員からの回答を保護するために、ダッシュボードの「国」フィールドに匿名のしきい値が設定されています。下のウィジェットでは、棒グラフのY軸寸法を従業員のオフィスがある国に設定しています。オーストラリアとメキシコのオフィスは非常に小さく、我々が設定した匿名のしきい値以下だ。結果、彼らの回答は統合された。
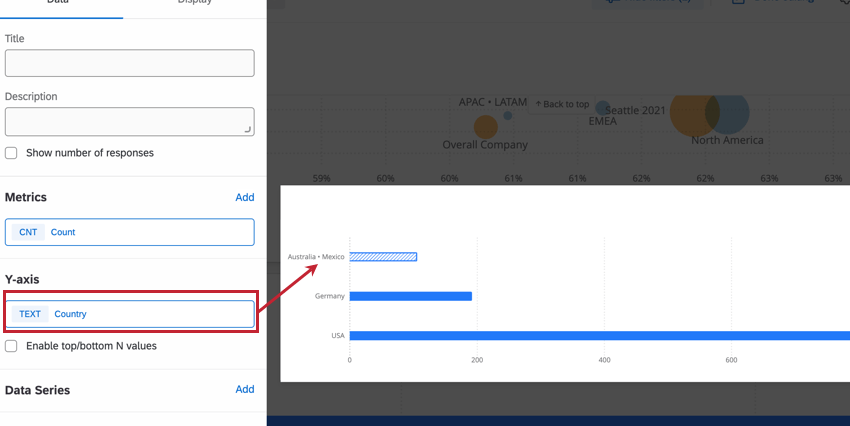
指標を平均エンゲージメントスコアやNPSに変更する場合、匿名性を強化することで、ダッシュボードユーザーがそのオフィスのデータを分離できないようにすることで、最小のオフィスのデータを把握することができなくなる。これは、例えば、最も小さな事務所の各メンバーの評価を簡単に計算させたくないような場合に便利である。
詳細区分
ウィジェットの中には、複数の次元に分かれているものもあります。例えば、線と棒のウィジェットでは、X軸の値とデータ系列の両方を追加できますし、テーブルでは行と列の両方を追加できます。
データを分割すればするほど、各カテゴリーは小さくなり、匿名性の下でグループ化されるカテゴリーが増える。また、詳細区分には2つの側面があるため、匿名性のためにグループ分けが必要な異なる区分の組み合わせがあるかもしれない。したがって、匿名性のためにグループ化されたカテゴリーには「Grouped for Anonymity」と表示され、その上にカーソルを置くことで、どのカテゴリーがグループ化されたかを確認することができる。
また、凡例では、匿名グループは複合名ではなく、Grouped for Anonymityと表示されていることにお気づきだろう。これは、複数の詳細区分がどのように影響し合うかによってグループ分けがどのように変わるかをアカウントに考慮し、長すぎるラベルを防ぐためである。
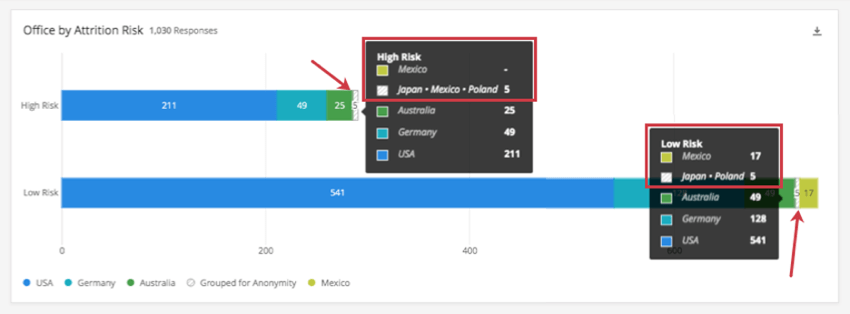
例このダッシュボードのしきい値は5です。下のグラフでは、従業員の勤務国を離職リスク別に分けています。低リスクのバーにはメキシコの薄緑色のブロックが見えるが、高リスクのバーにはない。
各バーのGrouped for Anonymityブロックを強調表示すると、違いがあることがわかる:メキシコは「高リスク」バーでは日本、ポーランドとグループ化されているが、「低リスク」バーでは日本とポーランドだけがグループ化されている。
下のスクリーンショットを見てください。ハイリスクでは、メキシコは個別のデータがない(-)が、日本+メキシコ+ポーランドは、匿名性のためにグループ化されているため、データを示している(5)。低リスクでは、メキシコはしきい値を満たしているため、グループ化する必要はなく、個別のデータを示している(17)。
基本的な匿名性
基本的な匿名性で2つ以上の詳細区分でデータを分割している場合、各詳細区分は別々に考慮される。複数のフィールドのデータを分割する場合、しきい値以下のメトリクスとカウント・データ・ポイントは非表示になります。
匿名のしきい値に対する回答数を比較する場合、基本的な匿名性は値のない回答 (空/null) をカウントしません。これは、質問に回答する資格がない可能性のあるアンケート回答者 (例: アンケートのロジックでマネージャーだけが質問に回答できる) の回答が匿名のしきい値にカウントされる場合を保護するためです。
強化された匿名性
匿名しきい値の強化により、匿名しきい値に対する回答数の比較時に、値のない回答(空/null)がカウントされるようになりました。
複数フィールドの詳細区分の動作は、関係する2つのフィールドのフィールドレベルの設定に依存する。この詳細テーブルは、異なるフィールドタイプ間のダブルブレイクアウトにおいて、データがどのように隠されるかを示している。
| 敏感ではない | やや敏感 | 極めて敏感 | |
| 敏感ではない | すべてのデータポイント(メトリクスとカウント)が表示されます。 | ややセンシティブなフィールドの値は、しきい値を下回ると非表示になる。 | 非常に敏感なフィールドからの値は、閾値以下であればグループ化される。 |
| やや敏感 | ややセンシティブなフィールドの値は、しきい値を下回ると非表示になる。 | 回答数のしきい値以下のデータ・ポイント(メトリクスとカウント)はすべて非表示になります。 | ややセンシティブなフィールドの値は、しきい値を下回ると非表示になり、非常にセンシティブなフィールドの値は、しきい値を下回るとグループ化される。 |
| 極めて敏感 | 非常に敏感なフィールドからの値は、閾値以下であればグループ化される。 | ややセンシティブなフィールドの値は、しきい値を下回ると非表示になり、非常にセンシティブなフィールドの値は、しきい値を下回るとグループ化される。 | 回答しきい値以下のデータポイントはグループ化される。 |
回答率 行動
回答率は、何件の回答があり、参加者リストの何パーセントがアンケートを完了したかを表示します。この種のデータは、参加状況の概要と回答率のウィジェットでレポートされる。
デフォルトでは、ダッシュボードは回答率を機密情報とみなします。つまり、回答率データは参加者を特定するために使用される可能性があるため、参加者を保護するために、回答率は匿名によってグループ化される件名となります。
例回答率ウィジェットを作成するときに、ウィジェットを分割するフィールドを追加できます。以下では、回答率を国別に分け、その結果、オーストラリア、ドイツ、メキシコは匿名性のためにグループ分けされている。
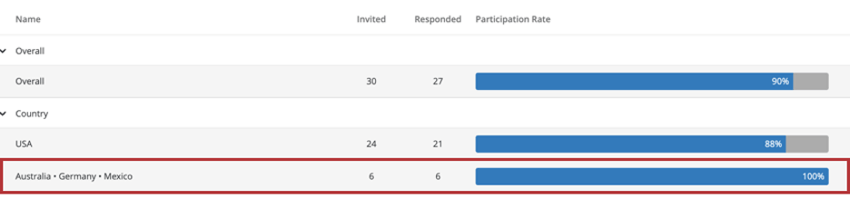
したがって、回答率ウィジェットは、他のウィジェットと同じ詳細区分を表示します。回答数のしきい値を下回ると、回答のサマリーウィジェットにはデータが表示されません。
匿名性の強化が有効な場合、回答率の動作は、各フィールドのフィールドレベルの設定に依存します:
- センシティブでないフィールド:これらのデータフィールドは、閾値以下であってもすべてのデータポイントを表示する。
- やや敏感なフィールド:これらのデータフィールドは、回答しきい値を満たすか超えるデータポイントのみを表示します。
- 極めて敏感なフィールド:これらのデータフィールドは、閾値以下のデータポイントをグループ化する。
組織全体の匿名性設定
組織全体の匿名のしきい値を設定し、すべてのEXプロジェクトが同じプライバシー基準を満たすようにすることができます。匿名回答(管理人)を参照。