-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
MaxDiffクラスタリング
MaxDiffクラスタリングについて
アンケート調査回答者の集団の中には、志を同じくする人々のグループがある。これらのグループ(「クラスタ」)は、各回答者の最も好む機能がどの程度似ているかによって決定することができる。各属性に対する個々の効用に基づいて回答者をクラスタ化することで、サブポピュレーションと、そのサブポピュレーションを構成する属性を決定することができる。
クラスタ化のためのアンケート調査の準備
MaxDiffクラスタリングを使用する前に、MaxDiffプロジェクトのアンケート調査が正しい質問であることを確認する必要があります。つまり、データを収集する前に特定の機能を設定する必要がある。
アンケート調査タブで、Maxdiff 以外のブロックに質問が追加されていることを確認します。以下の例では、Demographicsブロックに年齢、回答者の世帯人数などの質問があります。
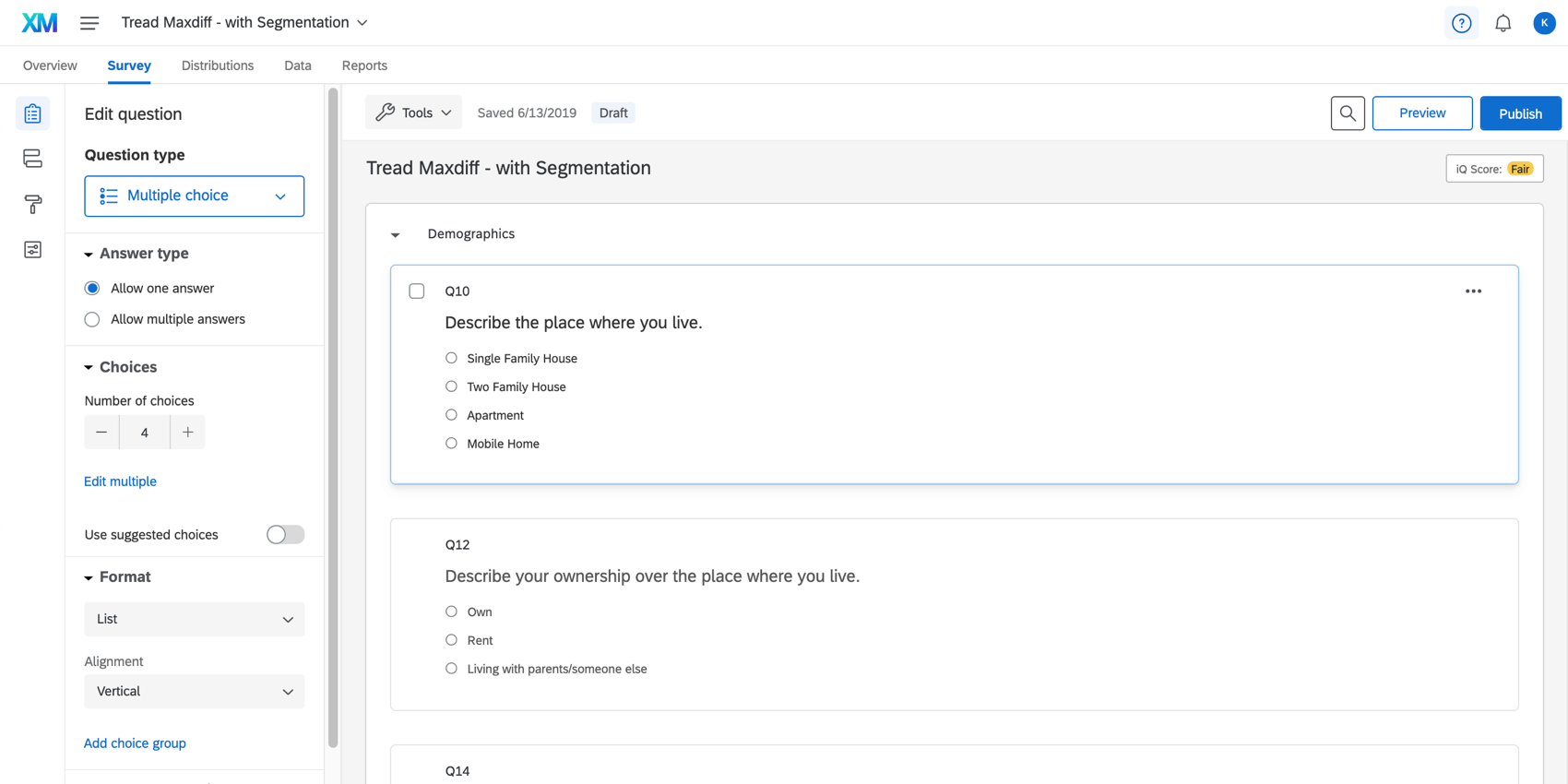
DemographicsブロックはMaxDiffブロックのすぐ上に配置されているが、必要に応じて移動させることができる。
質問のフォーマット
MaxDiffクラスタリングは、単一選択の多肢選択式問題のみを使用して実施することができます。それは、簡単に分析できる選択肢を提供しているからである。
- 人口統計:年齢、所得層、人種、性別など、基本的な記述情報を尋ねる。
- 行動:顧客のブランドや製品への接し方、あるいは購買実態に関連する行動を尋ねる。例えば、顧客が買い物に行く頻度を尋ねることができる。
- 運用 データ:これは、ウェブサイトでの滞在時間や従業員の勤続年数などの情報です。
- 質問の形式: 質問の動作や信念を尺度として書式化する。Yes/Noや単一選択の質問は、クラスタ分析にはあまり役に立ちません。
例あなたはどのような買い物をしますか?”と質問し、”ショッピングモールで買い物をするのが好き”、”オンラインで買い物をするのが好き”、”ブティックで買い物をするのが好き “という選択肢を与えた場合、クラスタリングアルゴリズムは回答者を3つのグループに分け、それぞれの回答に対して1つのグループとします。例えば、”ショッピングモールで買い物をするのが好きですか?”といったように、1~7までの回答で質問すれば、クラスタリング・アルゴリズムは、買い物客同士を区別するポイントをより的確に見極めることができるだろう。
クラスタを可能にする
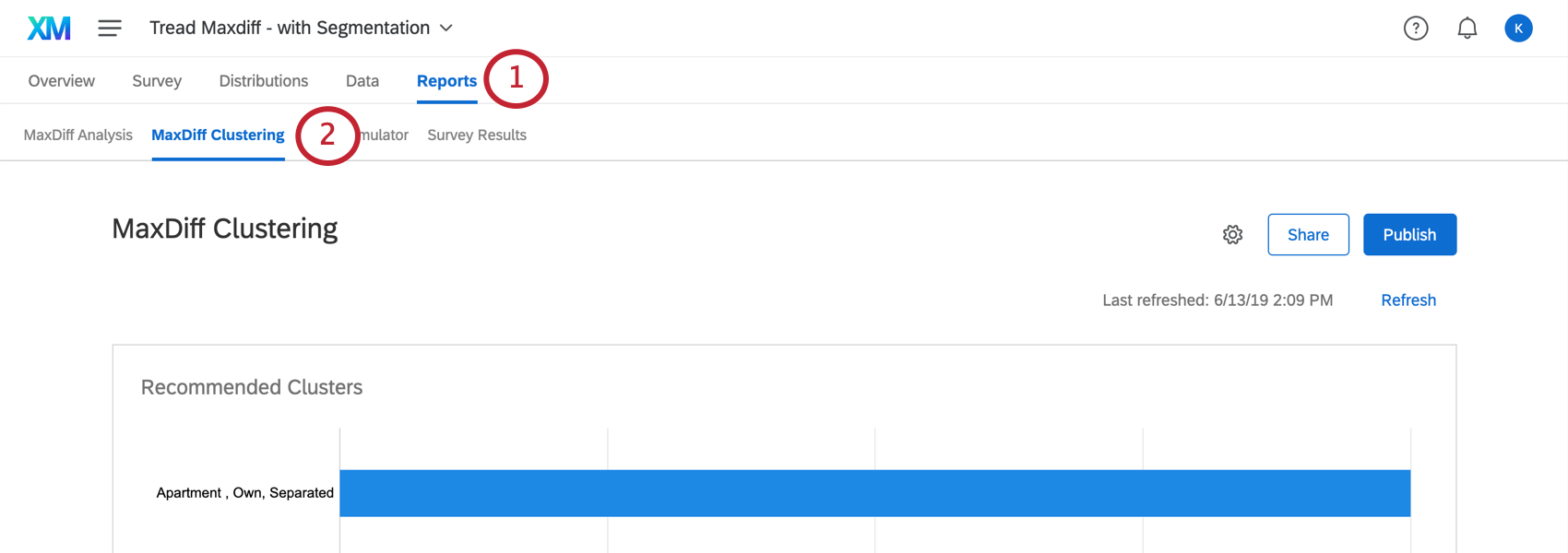
クラスタリングは、レポート タブのMaxDiffクラスタリングセクションにあります。
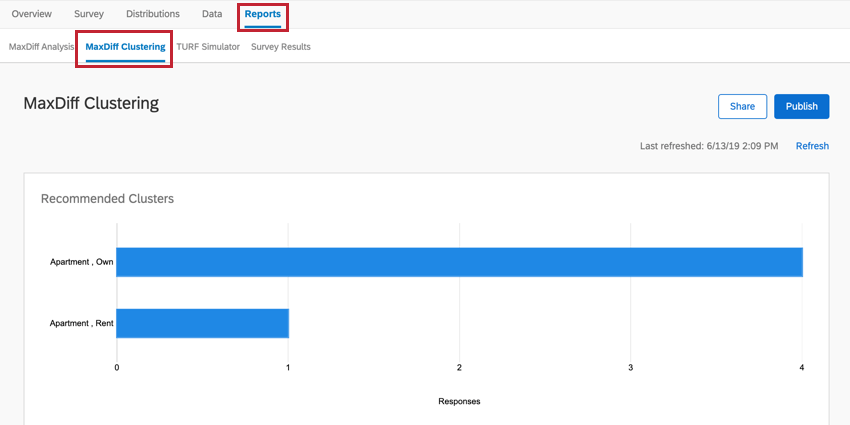
データを最初に表示させるためには、MaxDiff分析 セクションの「Refresh」をクリックする必要があるかもしれません。
クラスタに使用される人口統計の調整
デフォルトでは、MaxDiffクラスタリングは、作成した多肢選択式アンケートの全ての質問を使用します。しかし、使いたくなければすべての質問を使う必要はなく、コンテンツを追加したり削除したりして、この機能があなたにどのような異なるクラスタを勧めるかを確認することができる。
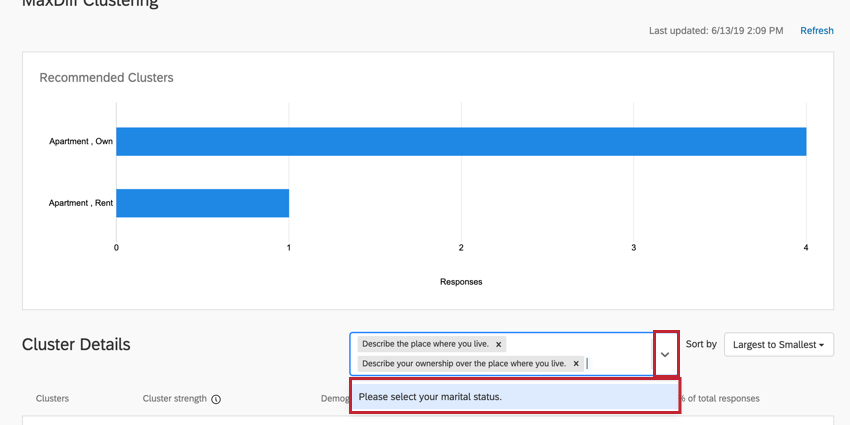
人口統計の削除
クラスタの詳細ヘッダの右側のボックスで、質問のXをクリックしてクラスタ分析から削除します。質問を削除してもクラスタは再計算されません。
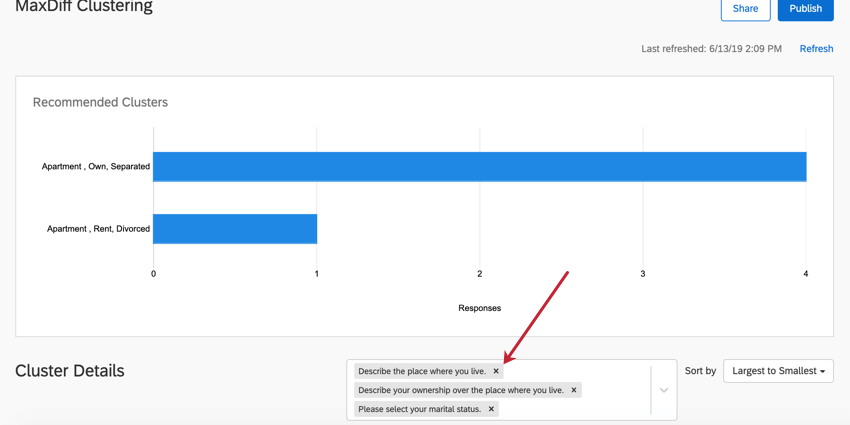
人口統計の追加
クラスタの詳細ヘッダの右側のボックスで、ドロップダウン矢印をクリックします。次に、クラスタに追加したい質問を選択します。
推奨されるクラスタ
十分なデータを収集し、Maxdiffクラスタリングページをリフレッシュすると、この機能はクラスタを推奨します。これらのクラスタは、回答者が最も好む機能がどの程度似ているかに基づいて決定される。 各属性に対する個々のユーティリティが計算され、これらのクラスタに共通する属性が強調表示されるため、異なる集団がどのように製品を好むかをより深く理解することができます。
上のグラフでクラスタを強調表示すると、そのクラスタの詳細を見ることができます。クラスタをクリックすると、以下のクラスタの詳細が表示されます。
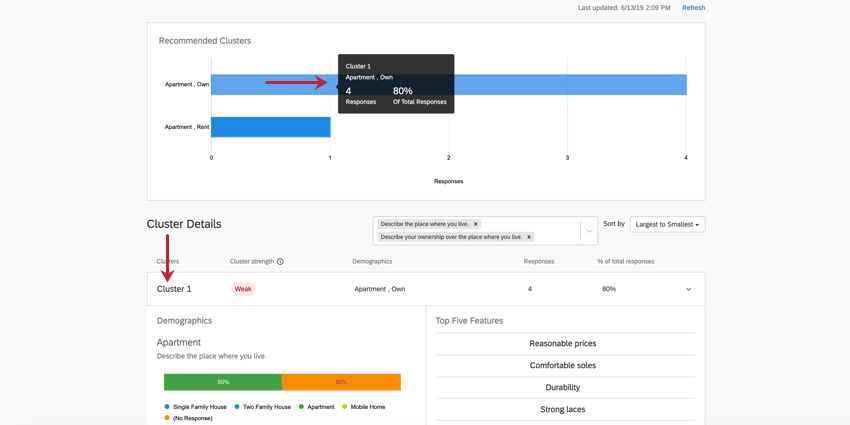
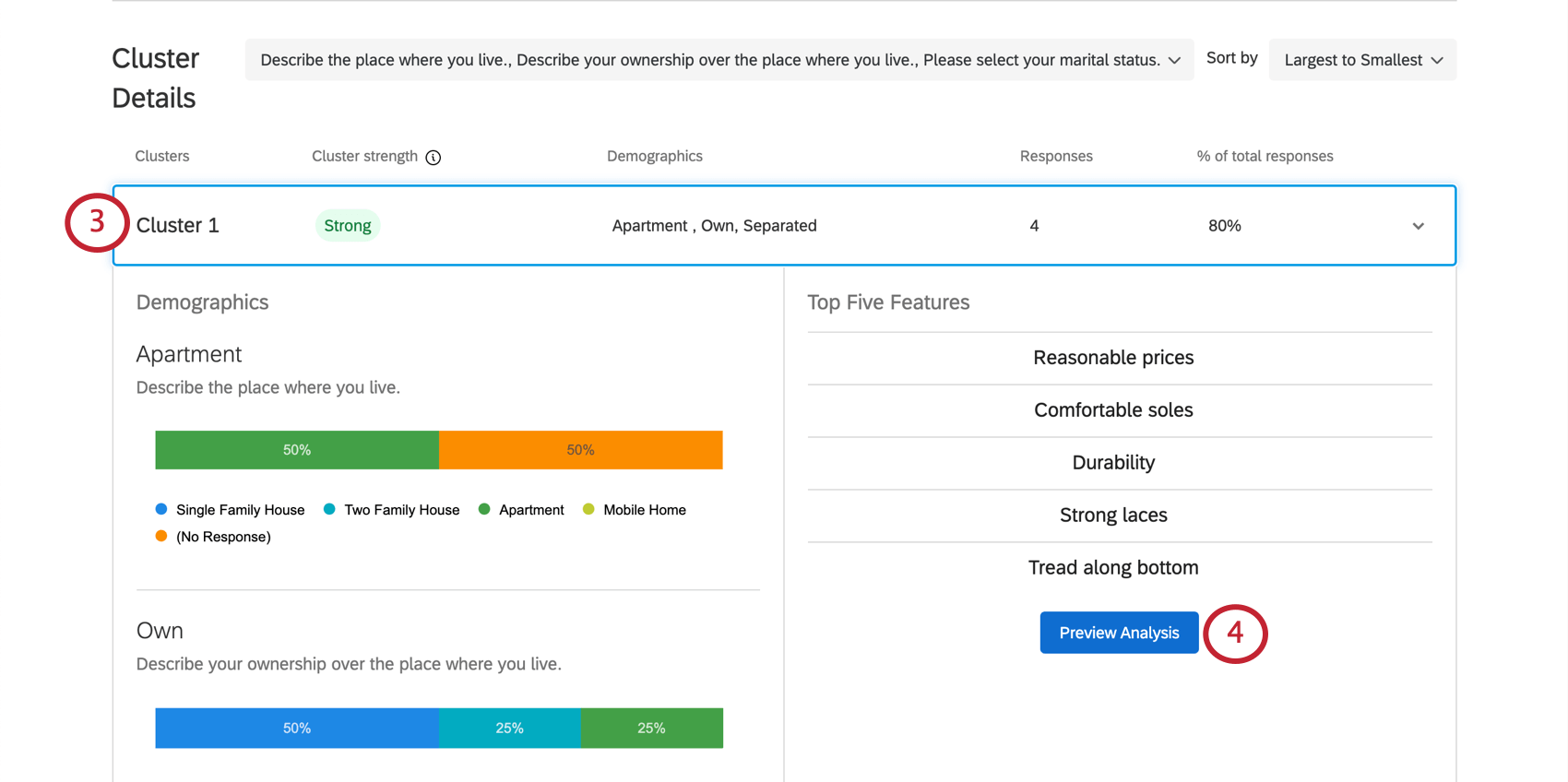
クラスタの詳細
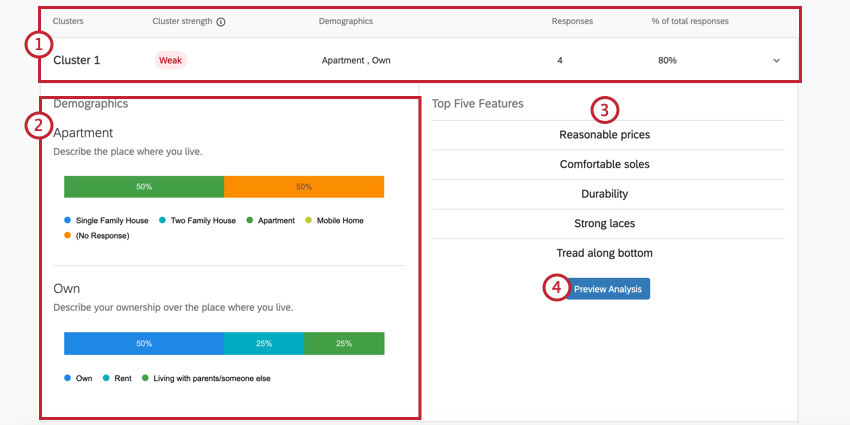
- サマリー:クラスタの詳細の一番上のバーには、どのクラスタであるか、クラスタの統計的有意性、回答者が一般的にどのように人口統計学的質問に回答したか、このクラスタに含まれる回答の数、このクラスタに適用される回答の割合など、最も重要な詳細が簡単に要約されています。また、この部分をクリックすると、RESTの残りの情報を展開したり折りたたんだりすることができる。
例写真のクラスタ1では、自分のアパートを所有している人の回答が多い。一般的に4人の回答者がこのパターンに当てはまり、これはデータセット全体の80%にあたります。これは非常に小さなデータセットであるため、この結果に基づいて決定を下すべきでないと思われる。これはクラスタの力が弱いことにも表れている。
- 人口統計: このクラスタのメンバーが人口統計学的質問にどのように回答したかを示す一連の内訳棒グラフ。各内訳棒グラフは、最も好まれる機能のユーティリティスコアと最も相関の高い回答によってラベル付けされていますが、クラスタ内の人々の回答方法はさまざまであることがわかります。
例クラスタ1の年収は”$20,000 – $29,000 “とリストされている。しかし、これはこのクラスタで最も一般的な年収ではない。末尾の「70,000~79,000ドル」のバーがもっと長いのがわかる。それは、年収の低い人たちは、年収の高いクラスタに比べ、単純に「リーズナブルな価格」「耐久性」などを評価している可能性が高いからである。
- 上位5機能:これは、クラスタのメンバーがリストから機能を選択する際に、最も好ましいと回答した可能性の高い5つの機能である。強調表示された属性は、ここで選ばれた属性に対して高いユーティリティスコアを持っている。
- 分析のプレビューこのボタンをクリックすると、このクラスタのデータのMaxDiff分析レポートのみが表示されます。
クラスタ強度の決定
クアルトリクスは、シルエットスコアリングと呼ばれる指標を使用して、各クラスタの強さを決定します。このスコアは、回答者がどの程度クラスタ化されているかを決定する0から1の間の値を生成します。シルエットスコアからクラスタ強度への変換には以下の表を使用する:
| 相関スコア | 関係の強さ | クラスタ強度ラベル |
| 0.71 から 1.0 | 非常に強い関係 | 強い |
| 0.51から0.70 | やや強い関係 | やや強い |
| 0.26 から 0.50 | やや弱い関係 | やや弱い |
| 0~0.25 | 有意な関係なし | 週 |
レポートへのクラスタ適用
クラスタをMaxDiff分析レポートに適用することで、このクラスタの回答者が提示された属性をどのように評価したかについて、より具体的な詳細を見ることができます。
レポートタブのMaxDiff分析セクションで、左上の細分化ドロップダウンからクラスタを選択します。
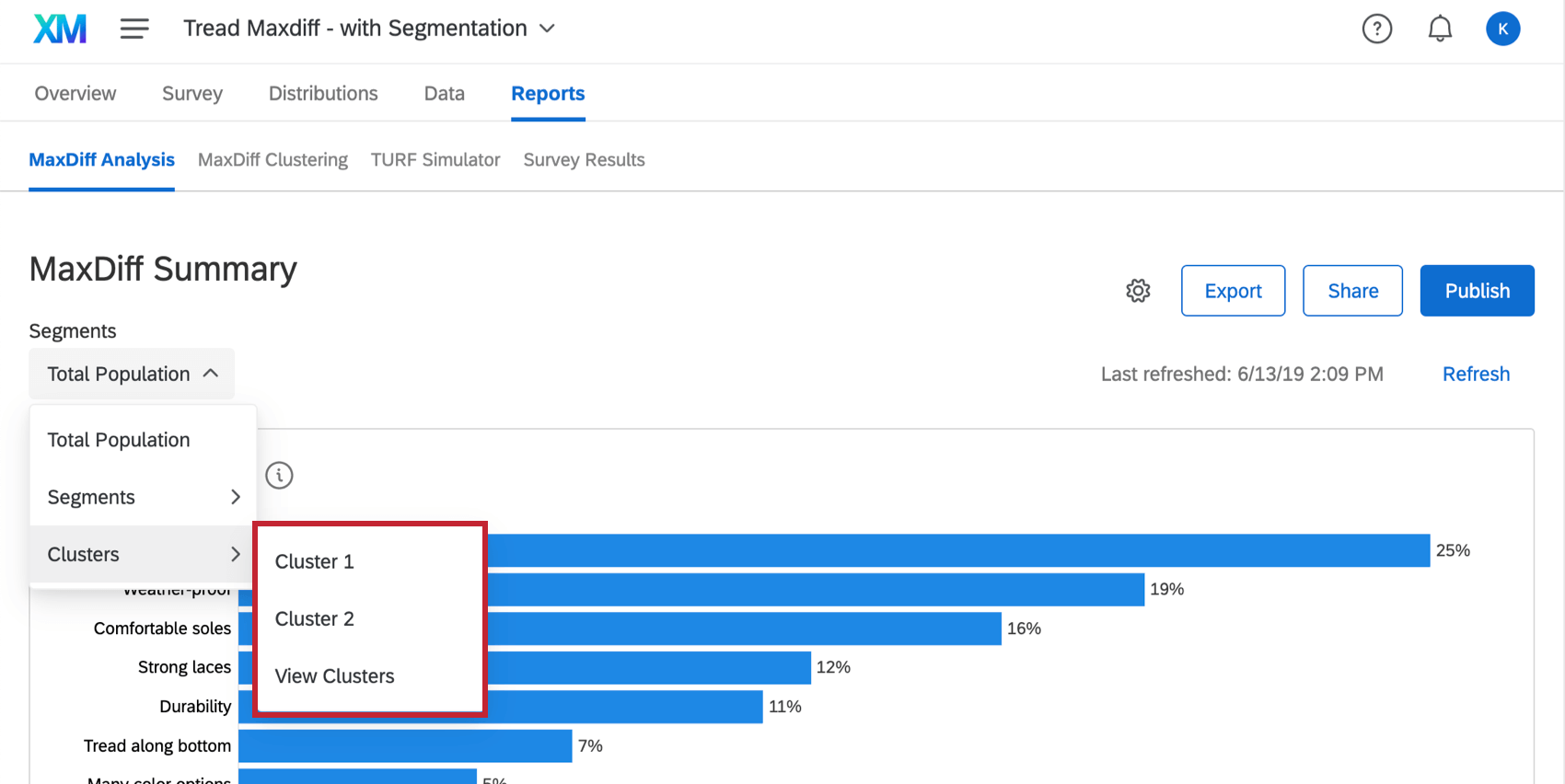
レポート」タブの「MaxDiffクラスタリング」セクションでクラスタを選択しているときに、「プレ ビュー分析」を選択することもできます。