Raggruppare i dati (Studio)
Cosa puoi trovare in questa pagina
Informazioni sul raggruppamento dei dati in Studio
Quando si crea un dashboard in Studio, è possibile specificare quali dati includere nel dashboard. È possibile limitare i dati di un rapporto raggruppando, ordinando o filtrando i dati.
I dati possono essere raggruppati in vari modi. Questa pagina spiega come raggruppare i dati in base a questi diversi raggruppamenti.
Raggruppare i dati in un widget
Consiglio Q: non è possibile raggruppare i dati nei widget metrici o di feedback.
È possibile raggruppare i dati nei tipi di widget supportati. Per raggruppare i dati nel widget:
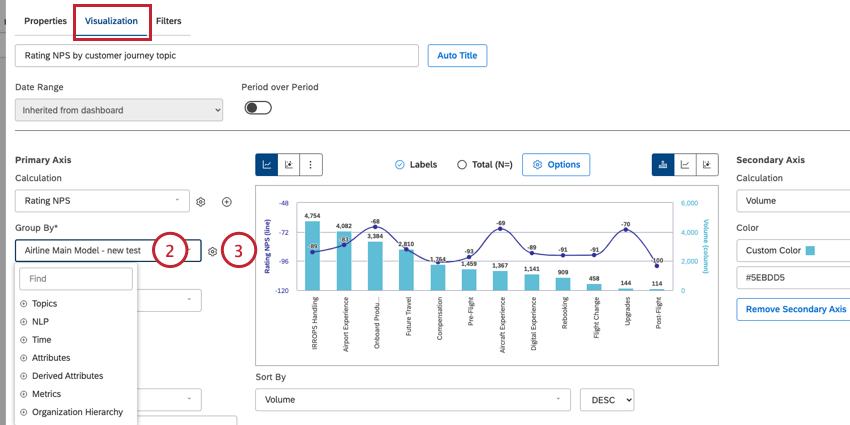
Consiglio Q: se si utilizza un widget tabella, questa opzione si chiama invece “Raggruppamenti”. Se si utilizza un widget heatmap, questa opzione si chiama invece “Riquadri”. Se si utilizza un widget di rete, questa opzione si chiama invece “Nodi”.
Argomenti
Selezionando gli Argomenti si possono raggruppare i dati in base alle categorie derivate dal feedback dei clienti. In questo modo è possibile avere una visione d’insieme di ciò di cui parlano i clienti.
Dopo aver scelto il modello di categoria, aprire le impostazioni di raggruppamento per selezionare gli argomenti da includere nel widget. Per ulteriori informazioni, vedere Raggruppamenti di modelli di categoria personalizzati.
Quando si raggruppano i dati per argomenti, è possibile scegliere di eseguire i rapporti su livelli diversi del modello di categoria. Per avere una panoramica di alto livello su ciò di cui parlano i vostri clienti, raggruppate i dati per argomenti di Livello 1. Per monitorare temi più specifici nei feedback dei clienti, raggruppate i dati in base ai temi di Livello 2 o inferiore (a seconda del vostro modello). Per ottenere un rapporto più granulare su tutti i livelli, raggruppare i dati utilizzando l’opzione Foglia, che consente di concentrarsi sulle foglie degli argomenti o sulle categorie che non hanno sottocategorie.
PNL
Selezionando NLP è possibile raggruppare i dati in base a criteri creati automaticamente dal motore di elaborazione del linguaggio naturale di XM Discover. Questi criteri sono creati da feedback non strutturati elaborati da XM Discover. Sono disponibili diversi sottogruppi tra cui scegliere:
Parole
I raggruppamenti NLP Parole consentono di raggruppare i dati in base alle parole o a specifici tipi di parole citate nei feedback dei clienti. Sono disponibili i seguenti raggruppamenti:
- Tutte le parole: Raggruppa i dati per parole regolari. Questo vi darà un’idea dei termini più comuni che i clienti utilizzano quando parlano del vostro prodotto o servizio.
- BRAND: Raggruppa i dati in base alle menzioni del brand.
- Azienda CB: Dati del gruppo per menzioni aziendali.
- Indirizzo e-mail CB: Raggruppa i dati in base agli indirizzi e-mail menzionati nei feedback.
- CB Emoticon: Raggruppa i dati in base alle emoji e alle emoticon utilizzate nei feedback.
- Evento CB: Raggruppa i dati in base alle festività standard (come Capodanno o Halloween), agli eventi della vita (come un matrimonio o una laurea) e agli eventi culturali comuni (come il Super Bowl) menzionati nei feedback.
- Settore CB: Raggruppa i dati in base al settore di appartenenza.
- Persona CB: Raggruppa i dati in base ai nomi delle persone citate nei feedback.
- Numero di telefono CB: Raggruppa i dati in base ai numeri di telefono menzionati nei feedback.
- CB Prodotto: Raggruppa i dati in base alle menzioni dei prodotti.
- CB Profanità: Raggruppa i dati in base alle parole blasfeme di un set predeterminato.
Parole associate
Il raggruppamento Parole associate consente di raggruppare i dati in base a coppie di parole che vengono citate in relazione tra loro nei feedback dei clienti. Ciò consente di vedere i temi e gli argomenti più comuni nei feedback dei clienti, indipendentemente dalla categorizzazione dei temi.
Le parole associate sono presentate nel formato seguente: parola 1 → parola 2.
Esempio: Se il feedback di un cliente è stato “Il negozio era sporco” e si raggruppa per parole associate, nel widget verrà visualizzato “negozio → sporco”.
Hashtag
Il raggruppamento Hashtag consente di raggruppare i dati per frasi hashtag (parole o frasi precedute dal simbolo # ). Gli hashtag vengono solitamente utilizzati nei post sui social media per aiutare a identificare e categorizzare il soggetto di valutazione del post.
Arricchimento
I raggruppamenti di arricchimento consentono di raggruppare i dati in base ai tipi di contenuti inclusi nei feedback dei clienti. Sono disponibili i seguenti raggruppamenti:
- Capitoli CB: Raggruppa i dati per capitoli di conversazione che rappresentano segmenti semanticamente correlati della conversazione (come Apertura, Necessità, Verifica, Fase della soluzione e Chiusura).
- Sottotipo di contenuto CB: Raggruppa ulteriormente i dati non contentful in base ai loro sottotipi (come annunci, coupon, link ad articoli o tipo “non definito”). Si noti che per i record contentful, anche il sottotipo è sempre contentful.
- Tipo di contenuto CB: Raggruppa i dati in base al loro contenuto o non contenuto, come identificato automaticamente da XM Discover.
- FUNZIONI RILEVATE CB: Raggruppa i dati in base alle funzioni NLP rilevate (ad esempio, dati contenenti menzioni di industrie o brand).
- Emozione CB: Raggruppa i dati in base ai tipi di emozione rilevati dal motore NLP (come Rabbia, Confusione, Delusione, Imbarazzo, Paura, Frustrazione, Gelosia, Gioia, Amore, Tristezza, Sorpresa, Gratitudine, Fiducia o Altro).
- CB Condizione medica: Raggruppa i dati in base alle condizioni mediche menzionate nel testo (ad esempio, “covid” o “meningite”).
- CB Procedura medica: Raggruppa i dati in base alle procedure mediche menzionate nel testo (ad esempio, “mammografia” o “intervento alla schiena”).
- Punteggio empatia PARTECIPANTE CB: Raggruppa i dati delle conversazioni in base al fatto che i rappresentanti abbiano mostrato o meno empatia nelle loro interazioni con i clienti. 0 significa che il rappresentante non ha mostrato empatia, mentre 1 significa che il rappresentante ha mostrato empatia.
- Motivo CB: Raggruppa i dati in base ai motivi di un particolare evento di conversazione (ad esempio, motivo del contatto o motivo dell’empatia).
- CB Rx: raggruppare i dati in base ai nomi dei farmaci citati nel testo (ad esempio, “acetaminofene” o “tylenol”).
- CB Tipo di frase: Raggruppa i dati in base al tipo di frase o all’intenzione (ad esempio, “richiesta di aiuto” o “suggerimento”).
Lingua
I raggruppamenti Lingua consentono di raggruppare i dati in base alla lingua in cui è stato lasciato il feedback. Sono disponibili i seguenti raggruppamenti:
- CB Lingua rilevata automaticamente: Raggruppa i dati in base alle lingue rilevate automaticamente (se il rilevamento automatico della lingua è abilitato per un progetto).
- CB Lingua elaborata: Raggruppa i dati in base alle lingue in cui il feedback è stato effettivamente elaborato. Le lingue non supportate dal rilevamento della lingua di XM Discover sono contrassegnate come “altro”
Conversazione
I raggruppamenti di conversazione consentono di raggruppare i dati in base a diversi arricchimenti conversazionali. Si noti che questi raggruppamenti sono disponibili solo per i dati conversazionali (chiamate e chat elaborate con il formato conversazionale di QUALTRrics). Sono disponibili i seguenti raggruppamenti:
- CB % Silenzio: Raggruppa i dati in base alla percentuale di silenzio in una chiamata.
- CB Durata della conversazione: Raggruppa i dati in base alla durata di una conversazione in millisecondi. Per le chiamate, si tratta del tempo che intercorre tra l’inizio della prima frase e la fine dell’ultima. Il silenzio iniziale e finale non viene conteggiato. Per le chat, si tratta dell’intervallo di tempo tra la prima e l’ultima frase.
- CB Tipo di partecipante: Raggruppa i dati in base al tipo di partecipante. I valori possibili includono:
- Chat_bot è un chatbot.
- IVR è un bot di risposte vocali interattive.
- Umano è una persona.
- CB Tipo di partecipante: Raggruppa i dati in base al tipo di partecipante. I valori possibili includono:
- l’agente è un rappresentante dell’azienda o un chatbot.
- il cliente è un cliente.
- type_unknown è un partecipante non identificato come agente o cliente.
- CB Durata della frase: Raggruppa i dati in base alla durata di una frase in una chiamata, in millisecondi.
- CB Ora inizio frase: raggruppa i dati in base al timestamp dell’inizio della frase. Per le chiamate, si tratta del tempo in millisecondi dall’inizio udibile della prima parola della prima frase. Per le chat, è il tempo in millisecondi trascorso dall’invio del primo messaggio. Consiglio Q: Il tempo di inizio del primo messaggio di chat sarà sempre 0 ms per questo attributo.

- CB Totale aria morta: Raggruppa i dati in base all’aria morta totale di una chiamata in millisecondi. Nelle chiamate, l’aria morta è una lunga pausa tra gli altoparlanti.
- Esitazione totale CB: Raggruppa i dati in base all’esitazione totale (dell’agente e del cliente) in una chiamata in millisecondi. Nelle chiamate, l’esitazione è una lunga pausa da parte di un interlocutore.
- CB Total Overtalk: Raggruppa i dati in base alla lunghezza accumulata delle frasi che si sovrappongono in una chiamata, in millisecondi. Nelle chiamate, l’overtalk è un momento in cui due o più parlanti stanno parlando simultaneamente e i tempi delle loro frasi si sovrappongono.
- CB Silenzio totale: Raggruppa i dati in base alla durata cumulativa di tutti i silenzi superiori o uguali a 2 secondi tra una frase e l’altra per tutti i partecipanti a una chiamata, in millisecondi.
Ora
Selezionando Timing è possibile raggruppare i dati per periodi di tempo. È possibile utilizzare i raggruppamenti di attributi temporali per creare un rapporto di tendenza, che consente di visualizzare l’andamento dei calcoli e delle metriche nel tempo.
Attributi
La selezione degli Attributi consente di raggruppare i dati in base ai valori di un attributo strutturato selezionato. Un attributo strutturato è un campo numerico o stringa presente in un record che non è un feedback testuale vero e proprio. Gli attributi strutturati contengono generalmente dati discreti con un alto grado di organizzazione (come l’età di una persona o il nome del prodotto che usa). Gli attributi disponibili per il raggruppamento dipendono dalla fonte del feedback e di solito variano da un dataset all’altro.
Esempio: Posso raggruppare in base all’attributo “Agente” per vedere i raggruppamenti delle interazioni in base ai diversi agenti che hanno gestito l’interazione.
Metriche
Selezionando Metriche si possono raggruppare i dati in base a valori discreti o a fasce di determinati calcoli standard e metriche derivate. In altre parole, è possibile organizzare i dati in base a una metrica e misurarli con una metrica diversa. Sono disponibili i seguenti raggruppamenti:
- Analisi del sentiment (3 bande): Raggruppa i dati in base a 3 bande di analisi del sentiment (Negativa, Neutrale, Positiva). Per ulteriori informazioni, vedere Raggruppamento per analisi del sentiment.
- Analisi del sentiment (5 bande): Raggruppa i dati in base a 5 bande di analisi del sentiment (Fortemente negativo, Negativo, Neutrale, Positivo, Fortemente positivo). Per ulteriori informazioni, vedere Raggruppamento per analisi del sentiment.
- Sforzo (3 fasce): Raggruppa i dati per 3 fasce di sforzo (duro, neutro, facile). Quando si raggruppa per sforzo, i valori nulli sono inclusi per impostazione predefinita.
- Sforzo (5 fasce): Raggruppa i dati per 5 fasce di sforzo (Molto duro, Duro, Neutro, Facile, Molto facile). Quando si raggruppa per sforzo, i valori nulli sono inclusi per impostazione predefinita.
- Intensità emotiva: Raggruppa i dati per 3 fasce di intensità emotiva (Bassa, Media, Alta).
- CB Conteggio parole del documento: Raggruppa i dati in base al numero di parole di un documento.
- CB Durata della fedeltà: Raggruppa i dati in base alla durata della fedeltà del cliente (in anni).
- Quartile della frase CB: raggruppare i dati in base al quartile del verbatim in cui rientra una frase (1, 2, 3 o 4). Questo può aiutare a capire quali argomenti vengono discussi in quali momenti della conversazione.
- CB Conteggio parole frasi: Raggruppa i dati in base al numero di parole presenti in una frase.
Inoltre, è possibile definire le proprie metriche di top box, bottom box e soddisfazione, in base alle quali raggruppare i dati. In questo modo è possibile determinare se il feedback proviene da un promotore, da un detrattore o da un cliente neutrale. Sono disponibili i seguenti raggruppamenti:
- Top Box: Raggruppa i dati per fasce di top box (promotori e altro).
- Box inferiore: Raggruppa i dati per fasce del riquadro inferiore (detrattori e altro).
- Soddisfazione: Raggruppare i dati per fasce di soddisfazione (detrattori, neutrali, promotori).
Fattori
Consiglio Q: è possibile utilizzare i driver solo nei widget dei grafici a dispersione.
Selezionando Driver si possono raggruppare i dati in base ai driver creati nel proprio account. È possibile utilizzare questi driver per trovare gli attributi e gli argomenti che portano a un determinato risultato.
Gerarchia aziendale
Selezionando Gerarchia dell’organizzazione si possono raggruppare i dati in base ai diversi livelli della gerarchia dell’organizzazione selezionata.
Costo del raggruppamento
Quando si eseguono rapporti con più raggruppamenti, è possibile che venga visualizzato il seguente messaggio di errore:
“Oops! Applichiamo un costo stimato a ciascun raggruppamento e la somma dei costi non può superare il budget del guardrail di [10.5]. (Rimuovere o scegliere raggruppamenti diversi in base ai costi elencati di seguito per garantire che il widget abbia un costo totale all’interno del budget: [lista di raggruppamenti e relativi costi] Costo totale attuale: [totale di tutti i costi]”
Il costo di ogni raggruppamento dipende dal numero di valori unici nel gruppo (questa misura è chiamata cardinalità). Per impostazione predefinita, la maggior parte dei widget restituisce i primi 10 articoli per volume. Se ci sono 100 elementi in totale, questo calcolo è in genere molto veloce. Se ci sono 1.000.000 di articoli, ci vuole più tempo per calcolare quali sono i 10 migliori. In generale, un numero maggiore di articoli unici risulta in un calcolo più costoso in termini di performance. Questo costo può moltiplicarsi rapidamente per i widget che restituiscono più livelli di dati e può provocare la comparsa del messaggio di errore di cui sopra.
Se si riceve l’errore di cui sopra quando si utilizzano i raggruppamenti in un rapporto, è necessario rimuovere uno o più dei raggruppamenti elencati in modo che il loro costo totale non superi il budget. Il messaggio di errore visualizzerà i costi stimati per ciascun raggruppamento, per aiutarvi a decidere quale raggruppamento rimuovere.
È fantastico! Grazie per il tuo feedback!
Grazie per il tuo feedback!