Filtro per dati strutturati (Designer)
Cosa puoi trovare in questa pagina
Informazioni sul filtro in base ai dati strutturati
Utilizzate gli attributi dei dati strutturati per filtrare il feedback in modelli che categorizzano e visualizzano le informazioni più rilevanti del vostro set di dati. Per informazioni sulla creazione e la modifica dei filtri, vedere Filtro dei dati (Designer).
Consiglio Q: La maggior parte dei filtri strutturati viene creata usando gli attributi. Per ulteriori informazioni sulla creazione e la modifica degli attributi in XM Discover, vedere Attributi.
FILTRO in base all’analisi del sentiment
XM DISCOVER utilizza l’analisi del sentiment per determinare l’analisi complessiva del sentiment dei feedback. L’analisi del sentiment è disponibile come attributo di sistema con bande predefinite:
- Analisi del sentiment negativo: Feedback con un punteggio di analisi del sentiment da -5.0 a -1.0
- Analisi del sentiment neutrale: Feedback con un punteggio di analisi del sentiment da -0.99 a 0.99
- Analisi del sentiment positivo: Feedback con un punteggio di analisi del sentiment da 1 a 5.0
Consiglio Q: È possibile creare intervalli di sentiment personalizzati utilizzando l’attributo Sistema di sentiment. Ad esempio, _degreesentimentindex:[2.51 TO 5].
Filtro per lingua
Per filtrare in base al tipo di dati, utilizzare i seguenti attributi del sistema discover:
- CB Lingua rilevata automaticamente ( _languagedetected ): Il feedback sulla lingua è stato inviato se il progetto utilizza il rilevamento automatico della lingua.
- Lingua elaborata da CB ( _language ): Il feedback sulla lingua è stato inviato in. Se la lingua non è supportata da XM Discover, sarà contrassegnata come “ALTRO”.
XM Discover è in grado di riconoscere ed etichettare i dati in oltre 150 lingue grazie alla funzione Automatic Language Detection. Senza il rilevamento automatico della lingua, sono disponibili le seguenti lingue:
- Arabo
- Bengali
- Cinese (semplificato e tradizionale)
- Olandese
- Inglese
- Francese
- Tedesco
- Hindi
- Bahasa Indonesia
- Italiano
- Giapponese
- Coreano
- Polacco
- Portoghese
- Rumeno
- Russo
- Spagnolo
- Svedese
- Tagalog
- Thai
- Turca
- Vietnamita
Attenzione: I verbi con meno di 10 caratteri sono etichettati come inglesi.
Filtro in base al tipo di dati
Per filtrare i feedback in base al tipo di dati inviati, utilizzare i seguenti attributi del sistema:
- ID fonte ( _id_source ): L’origine dati delle frasi.
- Tipo verbatim ( _verbatimtype ): Il nome del campo verbatim in base al quale si desidera filtrare. È utile se si hanno più colonne verbali.
Esempio: Supponiamo di avere due colonne verbali: Valutatore e Risposte. Creare una regola per _verbatimtype:reviewper restituire un modello che visualizzi solo i dati della colonna Verbatim del valutatore.
FILTRO per tipo di contenuto
Per i progetti con il rilevamento del tipo di contenuto abilitato, utilizzare i seguenti attributi di sistema per filtrare i feedback da annunci, spam e altri dati non utilizzabili:
- Tipo di contenuto CB ( cb_content_type ): Se i documenti sono contrassegnati come contentful, cioè contenenti contenuto, o non contentful.
- Sottotipo di contenuto CB ( cb_content_subtype ): Raggruppa i documenti contrassegnati come non contenutistici in annunci, coupon, link ad articoli o “non definiti”.
Esempio: Se si desidera creare un modello che categorizzi solo i dati contentful, creare una regola utilizzando l’attributo di sistema CB Content Type: cb_content_type:contentful.
Filtro per tipo di frase
XM Discover utilizza l’analisi semantica per identificare gli intenti rilevanti per le vostre analisi. Queste categorie sono utilizzate nell’attributo di sistema a livello di frase: CB Sentence Type ( cb_sentence_type ). L’analisi del tipo di intento utilizzato nei dati può aiutare a capire come migliorare l’esperienza dei clienti.
Fare clic sui seguenti tipi di frasi per vedere cosa viene identificato con l’attributo “tipo di frase”:
Consiglio Q: le frasi che non corrispondono a nessuno dei tipi di frase sono etichettate come NON DEFINITE.
Filtro in base al conteggio delle parole
Utilizzare gli attributi Conteggio parole frase o Conteggio parole documento per filtrare i dati in base al numero di parole presenti nella frase o nel record. L’intervallo impostato in questi attributi è comprensivo di valori. Se il conteggio delle parole è pari a zero, la frase/registrazione è priva di testo o è stata caricata prima che la funzione fosse abilitata.
- CB Sentence Word Count ( cb_sentence_word_count ): Attributo a livello di frase che consente di filtrare i dati in base al numero di parole contenute in una frase. Consiglio Q: per visualizzare le frasi con 10 parole o meno, utilizzare l’intervallo cb_sentence_word_count: [DA 1 A 10].

- CB Document Word Count ( cb_document_word_count ): Attributo a livello di record che consente di filtrare i dati in base al numero di parole contenute in un record. È anche la somma di tutti i conteggi delle parole delle frasi. Consiglio Q: Per visualizzare i record con 50 o più parole, utilizzare cb_document_word_count: [DA 50 A 200].
Filtro in base al quartile della frase
L’attributo CB Sentence Quartile ( cb_sentence_quartile ) identifica la parte del testo che segue una frase. I valori sono da 1 a 4, con ogni sezione che rappresenta il 25% della lunghezza del verbatim. Se un record ha più verbali, ci saranno quartili per ogni verbale del record.
Consiglio Q: Questo attributo può essere utile se si desidera concentrarsi sul motivo per cui i clienti chiamano, che di solito viene discusso nel primo quartile ( 1 ) del verbatim. In alternativa, se siete interessati al modo in cui i rappresentanti terminano le loro chiamate, potete limitare i rapporti all’ultimo quartile ( 4 ).
Applicare il quartile delle sentenze
Se nei dati storici mancano i dati del quartile della frase, è possibile aggiungerli ai dati.
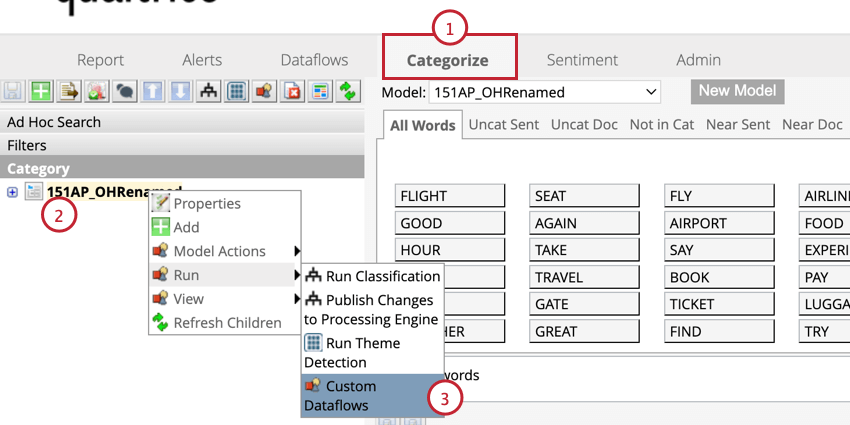
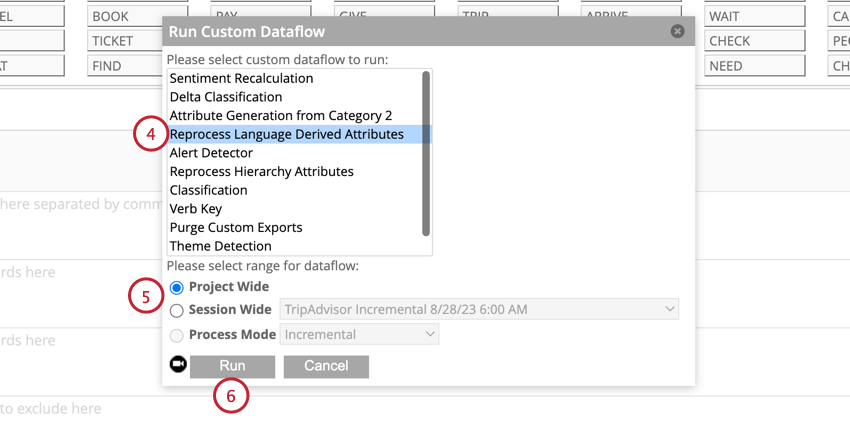
Filtro in base all’impegno
CB Effort misura il livello di impegno espresso dai clienti durante la loro esperienza. Questo attributo è disponibile a livello di frase su una scala da -5 a 5, dove -5 indica l’esperienza più difficile e 5 quella più facile. L’intervallo è comprensivo dei valori.
Consiglio Q: Per visualizzare le frasi in cui il livello di sforzo espresso è molto alto, è possibile utilizzare l’intervallo: cb_sentence_ease_score:[-5 to -3].
Consiglio Q: CB Effort è compatibile solo con i numeri interi.
Filtro in base alla durata della fidelizzazione
CB Loyalty Tenure consente di filtrare i dati in base al periodo di tempo in anni in cui un cliente ha utilizzato un servizio o posseduto un prodotto. Questo attributo è disponibile a livello di frase nelle frasi con il tipo di frase Tenure. L’intervallo è comprensivo dei valori.
Esempio: La frase “Sono un cliente da 10 anni” restituirà un valore di Fedeltà pari a 10. Per visualizzare le sentenze con durata fino a 10 anni, utilizzare il seguente intervallo: cb_loyalty_tenure:[1 TO 10].
FILTRO per tipo di interazione
CB Interaction Type ( cb_interaction_type ) definisce i dati in base al tipo di interazione XM, che consente di distinguere i feedback regolari dai dati di conversazione. Questo attributo è disponibile a livello di documento, di testo e di frase.
Il tipo di interazione può avere i seguenti valori:
- Chat: Dati di conversazione dai canali digitali.
- Feedback: Dati di feedback regolari (come menzioni online, valutatori e così via).
- SONDAGGI: Dati di risposta di un sondaggio.
- Voce: Dati conversazionali da conversazioni trascritte su audio.
È fantastico! Grazie per il tuo feedback!
Grazie per il tuo feedback!