Caricatore di dati (Designer)
Cosa puoi trovare in questa pagina
Informazioni su Data Loader
Il caricatore di dati viene utilizzato per importare dati nei progetti in XM Discover tramite un servizio API in tempo reale. Per accedere al caricatore di dati, accedere alla pagina di amministrazione, selezionare il progetto e andare alla scheda Caricatore di dati.
Attenzione: Il vostro consulente tecnico di Qualtrics imposterà il caricatore di dati per importare i dati nel vostro progetto. Non modificate le impostazioni del caricatore di dati senza averne prima parlato con il vostro consulente tecnico. Le impostazioni errate del caricatore di dati possono causare la mancata importazione dei dati in XM Discover.
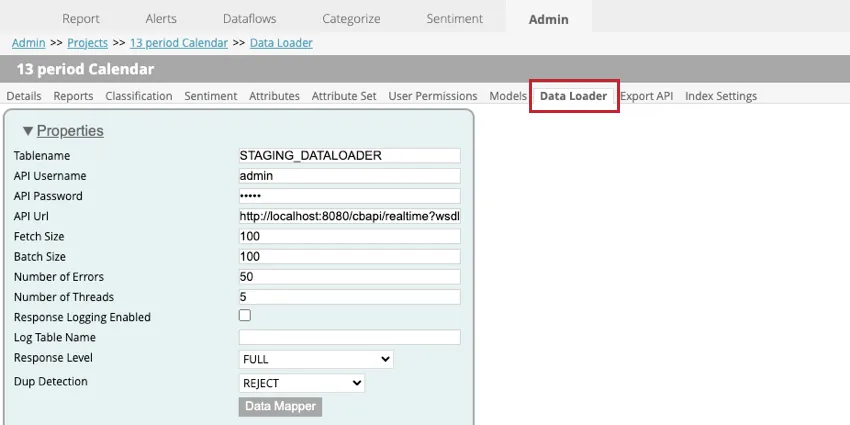
Impostazioni del caricatore di dati
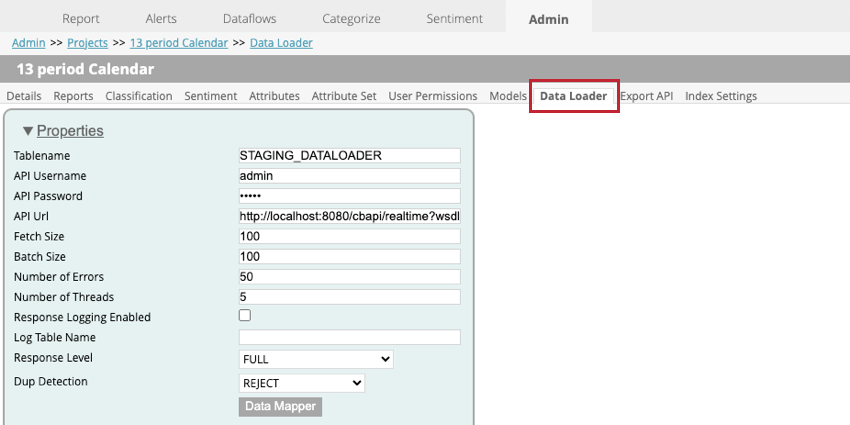
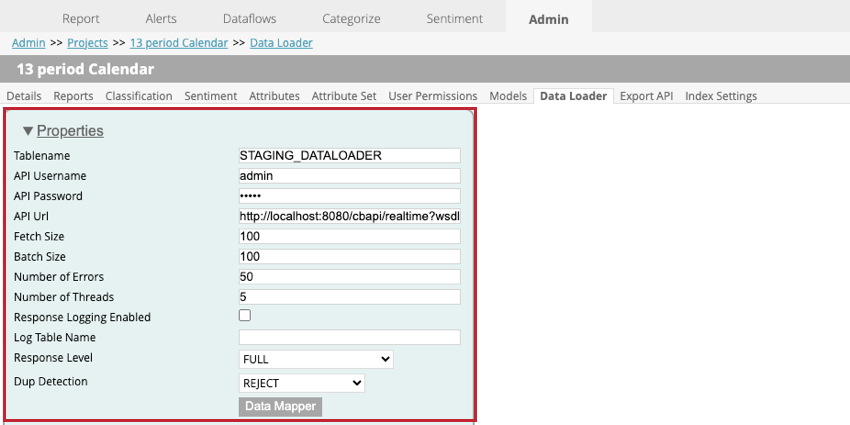
Quando si imposta il caricatore di dati all’interno di un progetto, sono disponibili le seguenti impostazioni:
- Nome tabella: inserire il nome della tabella di staging che contiene i dati da importare in XM Discover.
- Nome utente API: inserire il nome utente dell’utente API che può eseguire la chiamata API.
- Password API. Inserire il nome utente dell’utente API.
- URL API: Inserire l’URL del servizio API utilizzato per recuperare i dati.
- Dimensione del recupero: Specificare il numero di righe da importare.
- Dimensione batch: Specificare il numero di righe da importare in un lotto. Se la dimensione del batch è maggiore della dimensione del fetch, verranno eseguite più chiamate finché non saranno importati tutti i dati.
- Numero di errori: Se l’importazione fallisce a causa di errori, è possibile specificare quante volte la chiamata viene ritentata.
- Numero di thread: Inserire il numero massimo di thread da eseguire su una singola istanza del trasformatore.
- Registrazione risposte abilitata: Se attivata, questa opzione consente di creare un registro dei risultati dell’elaborazione dei documenti.
- Nome della tabella di log: Se si registrano i risultati, verrà creata una nuova tabella. Inserire in questo campo un nome per la tabella. Consiglio Q: È necessario specificare qualcosa per questo campo solo se è selezionata l’opzione Registrazione risposte attivata.

- LIVELLO DI RISPOSTA: Questa opzione deve essere impostata su SOLO SALVA.
- Rilevamento dei duplicati: Scegliere come gestire i duplicati. Le opzioni comprendono:
- NESSUNO: I duplicati vengono importati.
- RIFIUTO: I duplicati vengono rifiutati.
- AGGIORNARE GLI ATTRIBUTI: Per i duplicati vengono aggiornati solo gli attributi strutturati.
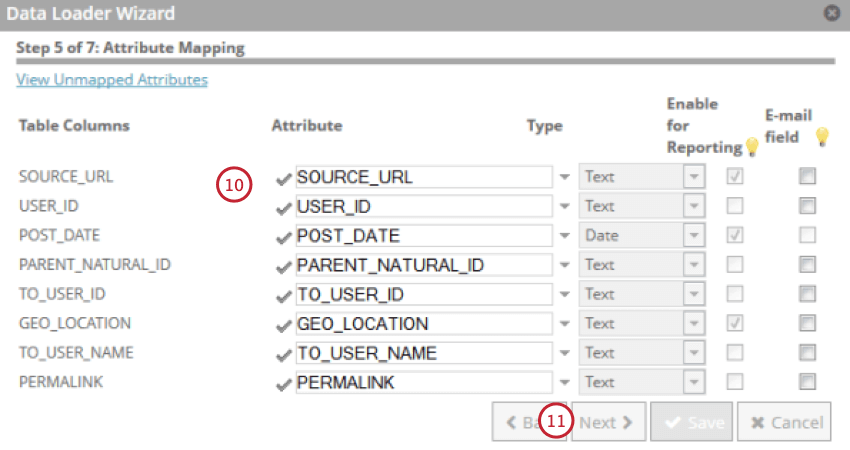
- Mappatura dati: La mappatura dati serve a scegliere quali campi estrarre dalla tabella di staging per utilizzarli in XM Discover. Per ulteriori informazioni, vedere la sottosezione Mappatura dati.
Mappatura dati
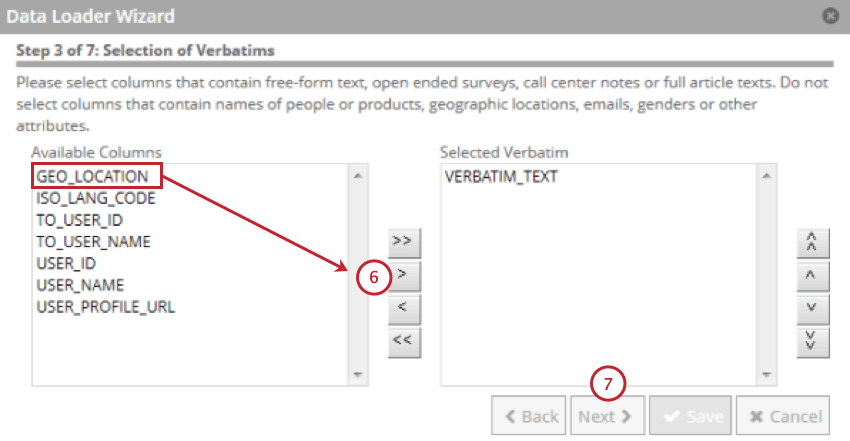
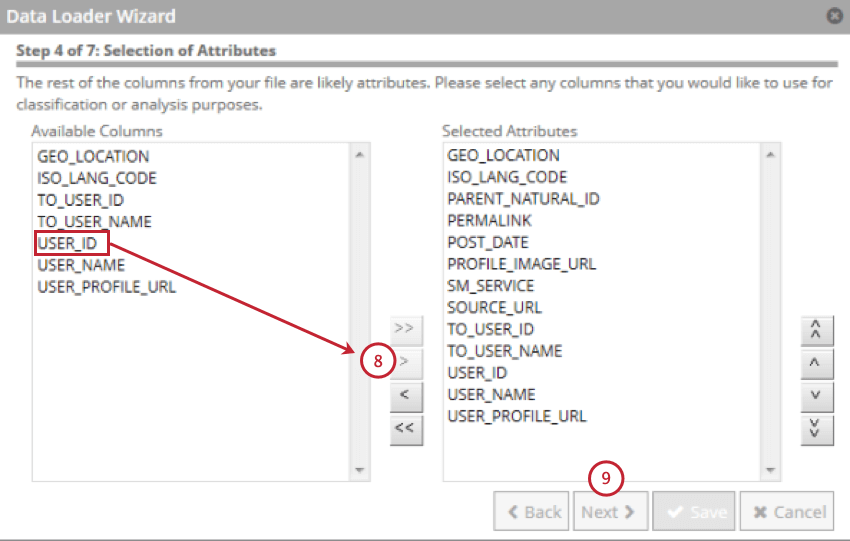
La mappatura dati viene utilizzata per estrarre i dati dalla tabella di staging e utilizzarli in XM Discover. La mappatura dati includerà solo i campi presenti nella tabella di staging.
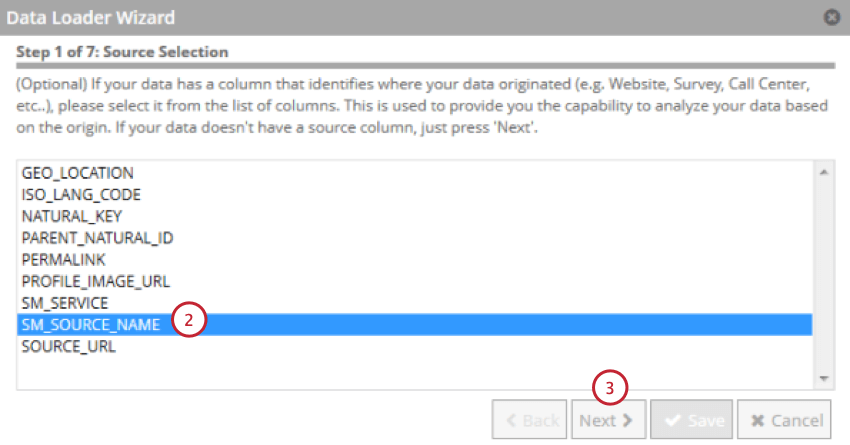
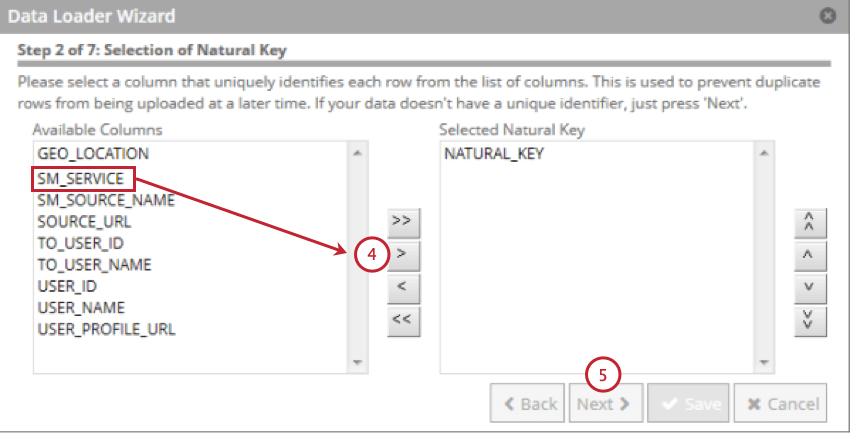
Consiglio Q: i campi più lunghi di 256 caratteri sono esclusi. Le chiavi naturali sono troncate a 256 caratteri.
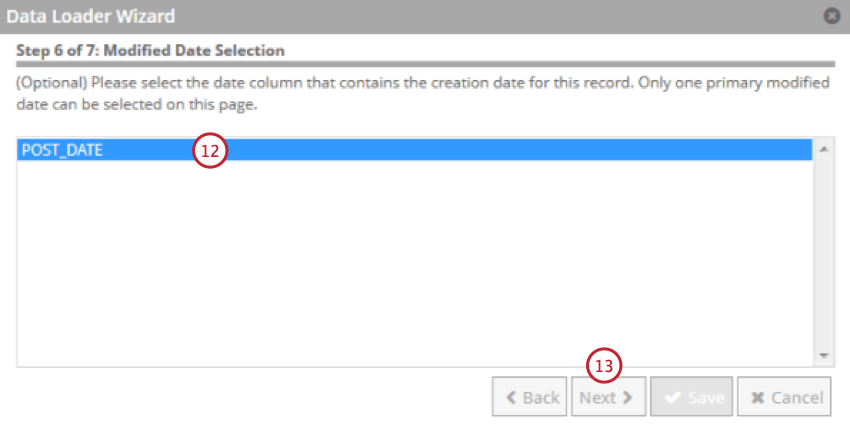
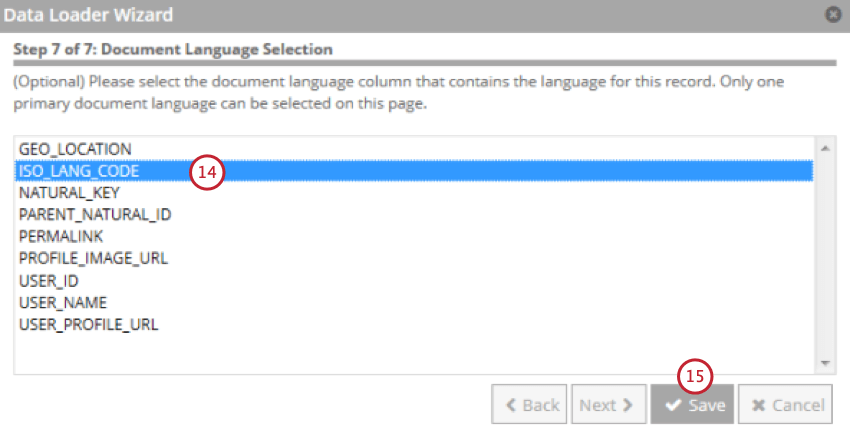
Importare i dati con il Data Loader
Dopo aver caricato i dati in una tabella dati tramite il caricatore di dati, è possibile elaborarli per utilizzarli in XM Discover. Questa sezione spiega come impostare un processo di caricamento automatico dei dati per mantenerli aggiornati.
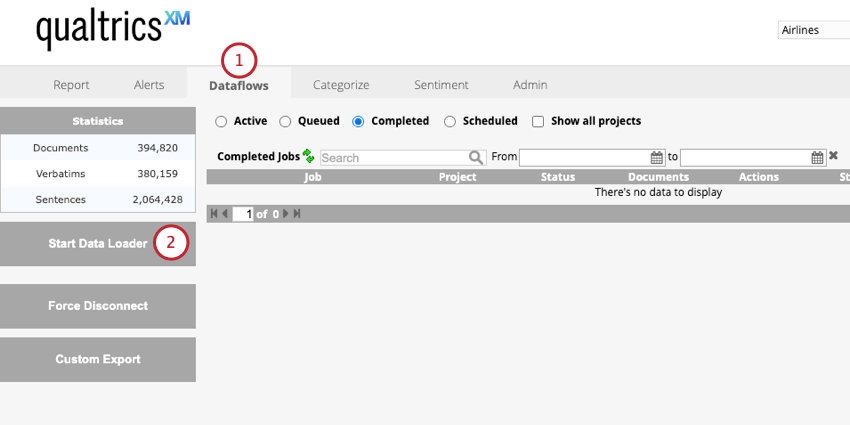
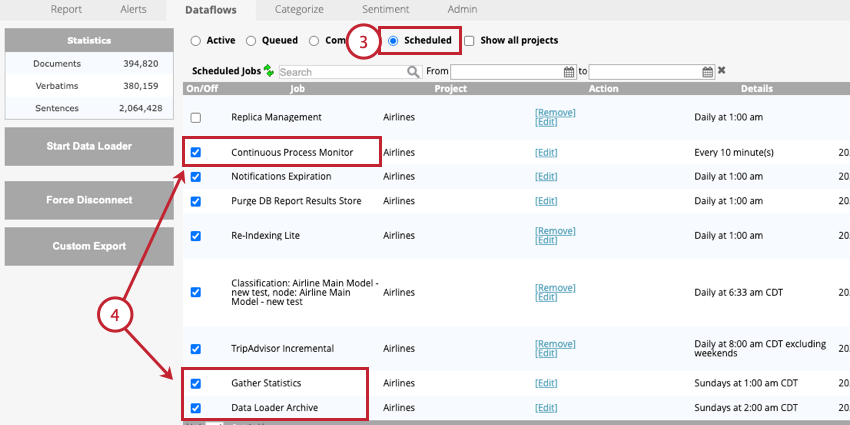
- Monitoraggio continuo del processo: Questo lavoro è richiesto. Questo flusso di dati esegue periodicamente il downstream in tempo reale per finalizzare l’elaborazione dei dati.
- Archivio del caricatore di dati: Questo lavoro è facoltativo, ma fortemente consigliato. Questo flusso di dati archivia i record che vengono elaborati dal caricatore di dati. È necessario aggiornare la frequenza di questo lavoro in modo che corrisponda alla frequenza del caricatore di dati.
- Raccogliere le statistiche: Questo lavoro è facoltativo. Si consiglia di eseguire questo lavoro una volta alla settimana. Questo flusso di dati aggiorna le seguenti statistiche del progetto:
- Il numero totale di documenti, verbali e frasi visualizzati nella scheda Flussi di dati.
- Il numero totale di occorrenze delle parole visualizzate nella scheda Analisi del sentiment.
Opzioni del caricatore di dati
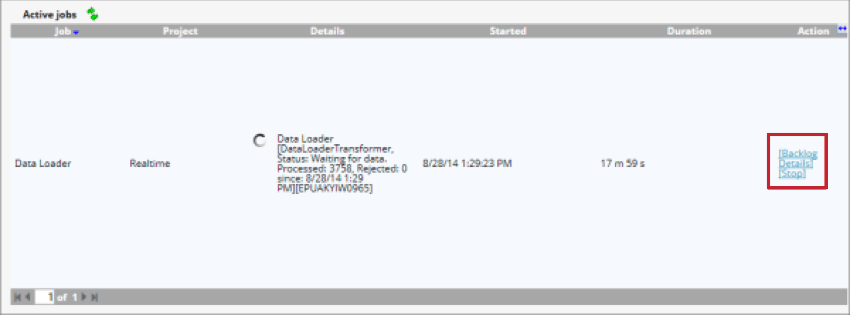
Una volta avviato il caricatore di dati, è possibile gestire il lavoro con le seguenti opzioni:

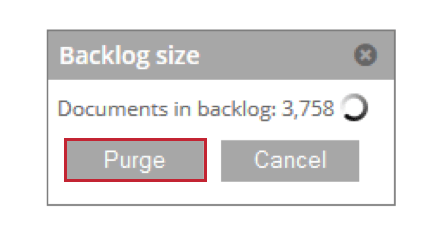
- Arretrati: Mostra il numero di documenti in attesa di essere elaborati. È possibile fare clic su Elimina per rimuovere questi documenti dalla tabella di staging.
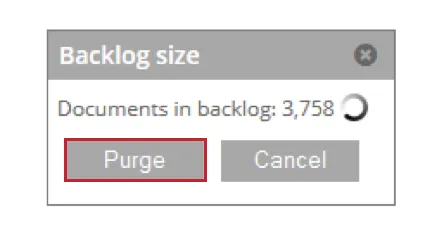
- Dettagli: Visualizza i dettagli dei documenti saltati a causa delle impostazioni di duplica.
- Interrompi: interrompe l’elaborazione dei dati con il caricatore di dati.
{kind=link}
{kind=link}
{kind=link}
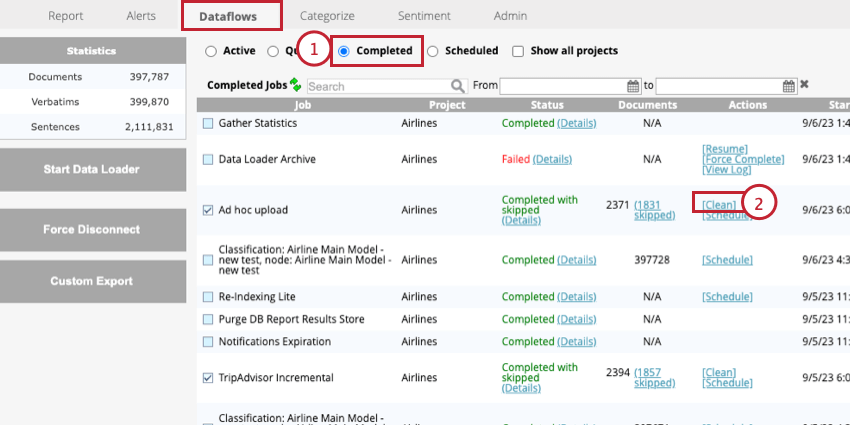
Eliminazione dei dati del progetto
È possibile eliminare i dati del progetto. Ciò include i verbali e i valori strutturati degli attributi. Quando si eliminano i dati del progetto, si possono eliminare tutti i dati caricati durante una particolare sessione o tutti i dati del progetto.
Consiglio Q: l’ eliminazione dei dati si chiama anche pulizia dei dati.
{kind=link}

In questo modo si cancellano tutti i dati aggiunti durante il caricamento selezionato.
È fantastico! Grazie per il tuo feedback!
Grazie per il tuo feedback!