-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Attributi Panoramica di base
Informazioni sugli attributi Panoramica di base
Un attributo è una proprietà di un documento che lo caratterizza in qualche modo. Esempi comuni di attributi sono il nome dell’autore e la data di creazione.
È possibile creare attributi personalizzati per i progetti. È inoltre possibile utilizzare una serie di attributi di sistema. È inoltre possibile impostare entità intelligenti che rilevano automaticamente gli attributi in base al testo del documento (ad esempio, quando un brand o un prodotto viene menzionato nel feedback di un cliente).
Dopo aver aggiunto gli attributi, è possibile creare ulteriori attributi derivati per comprendere meglio i dati. È inoltre possibile organizzare gli attributi in set di attributi, facilitando la stesura di rapporti su tali attributi.
Tipi di campo dell’attributo
Per gli attributi sono supportati i seguenti tipi di campo:
- Testo
- Numero
- Data
Accedere agli attributi
Gli attributi sono gestiti a livello di progetto. Per accedere agli attributi di un progetto:
- In Designer, andate nella scheda Amministrazione e trovate il progetto che vi interessa.
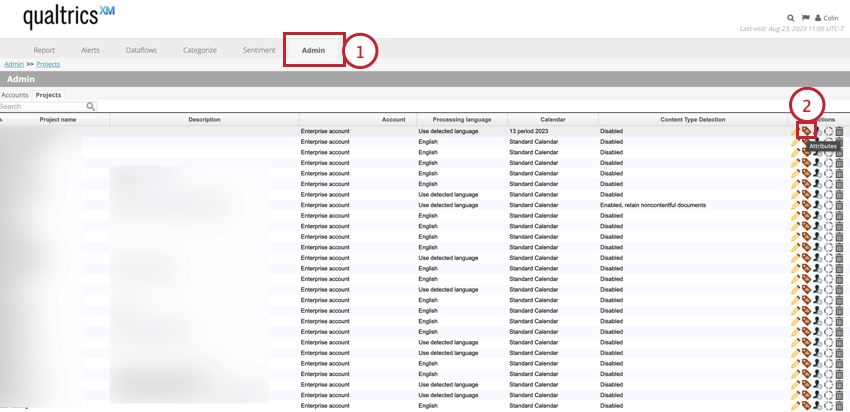
- Fare clic sull’opzione Attributi nella colonna Azioni.
Si apre la tabella degli attributi che contiene le seguenti informazioni su ogni attributo del progetto: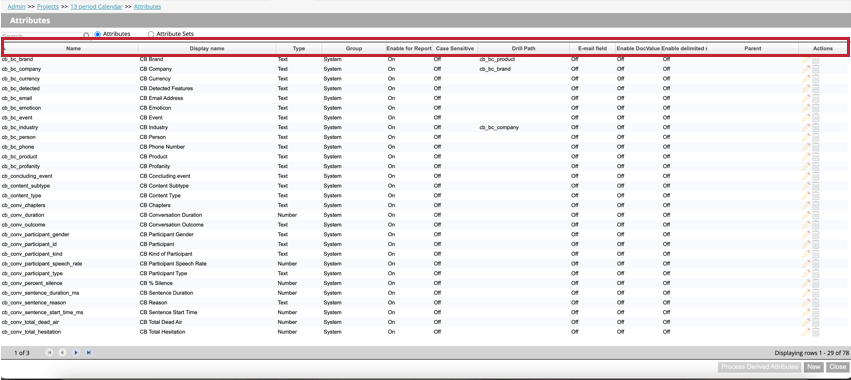
- Nome: Nome di sistema dell’attributo. Per i requisiti di denominazione, vedere Nomi degli attributi.
- Nome visualizzato: il nome visualizzato dell’attributo, che appare nei rapporti, nei filtri, ecc. Per i requisiti di denominazione, vedere Nomi degli attributi.
- Tipo: Il tipo di attributo. Per gli attributi standard, i valori possono essere Testo, Numero o Data. Per gli attributi derivati, i valori possono essere Lookup dimensionale, Range Rollup, Punteggio di soddisfazione o Derivato da categoria.
- Gruppo: Gruppo dell’attributo che ne rappresenta l’origine e l’uso previsto. I valori sono uno dei seguenti:
- Derivati da categorie: attributi derivati da modelli o categorie.
- Sistema: attributi di sistema.
- Definiti dal cliente: tutti gli attributi personalizzati disponibili dall’origine dati di vostra scelta (compresi lookup dimensionali, roll-up degli intervalli e punteggi di soddisfazione).
- Scheda punteggi: attributi utilizzati nel punteggio intelligente.
- Abilita per i Rapporti: Indica se un attributo è abilitato alla segnalazione (On) o meno (Off).
- Sensibile alle maiuscole: Mostra se un attributo è contrassegnato come sensibile alle maiuscole e minuscole quando si visualizzano i valori in Esplora documenti, Evidenzia testo, Esportazione personalizzata e Anteprima di esportazione delle frasi.
- Percorso di perforazione: Mostra il percorso di perforazione personalizzato, se è stato definito. Se non esiste un percorso di perforazione personalizzato, questo campo sarà vuoto.
- Campo e-mail: Mostra se un attributo contiene un indirizzo e-mail.
- Abilita DocValue: Mostra se i valori doc di ElasticSearch sono usati per questo attributo.
- Abilita valori multipli delimitati: Mostra se sono abilitati valori multipli per questo attributo.
- Genitore: se l’attributo è un attributo derivato, questo campo visualizzerà “genitore” Questo campo sarà vuoto per gli attributi personalizzati e standard.
- Azioni: Eseguire le seguenti performance sull’attributo:
- Modifica dell’attributo
- Creazione di un attributo derivato
- Eliminare l’attributo
Manager degli insiemi di attributi
Per visualizzare i set di attributi, utilizzare la levetta Set di attributi nella parte superiore della pagina. Ciò consente di creare nuovi set di attributi e di eliminare quelli esistenti. Selezionare Attributi per visualizzare i singoli attributi. 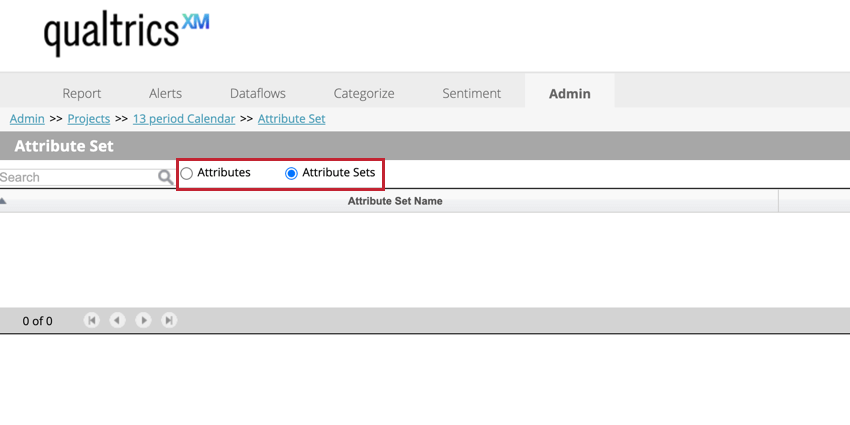
Attributi del sistema
Esiste una serie di attributi di sistema, come la data del documento e l’ID della fonte, che vengono applicati automaticamente a ogni documento caricato su XM Discover. Questi attributi aiutano a gestire i feedback all’interno di XM Discover e ad arricchirli con i dati XM derivati dal motore NLP.
Di seguito è riportata una tabella dei diversi attributi del sistema, raggruppati per le diverse categorie di attributi. Questa tabella contiene le seguenti informazioni su ciascun attributo:
- Nome: Il nome dell’attributo che appare nei rapporti, nei filtri, ecc.
- Nome del sistema: Nome del sistema dell’attributo che si usa per interrogare o filtrare i dati.
- Tipo: Il tipo di attributo.
- Descrizione: Breve descrizione del significato e dello scopo dell’attributo.
- Granularità: Livello di granularità dei dati associato a un attributo. Ad esempio, Sentence Word Count è rilevante solo a livello di frase, mentre Document Date è disponibile sia per un documento che per ogni frase di quel documento.
ID e riferimenti
| Nome | Nome del sistema | Tipo | Descrizione | Granularità |
| ID documento | _id_document | numero | L’ID univoco del sistema del documento. A differenza dell’ID naturale, l’ID documento viene generato automaticamente da XM Discover. | documento e frase |
| ID naturale | natural_id | testo | L’ID naturale univoco del documento. A differenza dell’ID documento, l’ID naturale viene generato dai campi specificati quando si carica un documento. L’ID naturale viene utilizzato per il rilevamento dei duplicati e può essere utile anche per risalire alla fonte del documento al di fuori di XM Discover. | documento e frase |
| ID sentenza | _id_sentence | numero | L’ID univoco della frase. Questo ID viene generato automaticamente.
|
frase |
| ID sessione | _id_batch | numero | L’ID univoco della sessione di upload durante la quale il documento è stato caricato in XM Discover. Questo ID viene generato automaticamente. | documento e frase |
| Fonte ID | _id_source | testo | Il nome dell’origine dati. A seconda dell’origine dati, può essere generato automaticamente o dai campi specificati al momento del caricamento del documento. | documento e frase |
| ID Verbatim | _id_verbatim | numero | L’ID univoco del verbatim. Questo ID viene generato automaticamente. | frase e verbatim |
| Tipo Verbatim | _verbatimtype | testo | Il nome del campo verbatim. Questo attributo consente di distinguere le frasi in base ai diversi campi verbali dei dati. | frase e verbatim |
Data e ora
| Nome | Nome del sistema | Tipo | Descrizione | Granularità |
| CB Data di creazione | cb_date_created_utc | data, tempo dell’epoca in millisecondi | La data in cui il documento è stato aggiunto a XM Discover. Questa data viene generata automaticamente. | documento e frase |
| Data di aggiornamento CB | cb_date_updated | data, tempo dell’epoca in millisecondi | La data dell’ultimo aggiornamento del documento. Gli aggiornamenti non comprendono le modifiche alla categorizzazione. Questa data viene generata automaticamente. | documento |
| Data del documento | _doc_time | data, ISO 8601 in secondi | La data primaria del documento. La data del documento viene utilizzata nei rapporti, nelle relazioni di tendenza, negli avvisi, ecc. Questa data viene generata dai campi specificati al momento del caricamento del documento. | documento e frase |
| Data del documento senza orario | _doc_date | data, formato aaaa-mm-gg | La data del documento senza il timestamp.
Questa data viene generata dai campi specificati al momento del caricamento del documento. |
documento e frase |
| Timing del giorno | time_of_day | testo, formato hh:mm | L’ora del documento, arrotolata all’unità oraria. Ad esempio, i commenti postati alle 9:09 e alle 9:59 saranno entrambi arrotolati alle 9:00. Questo attributo viene generato automaticamente. | documento e frase |
Conteggio delle parole e posizione
| Nome | Nome del sistema | Tipo | Descrizione | Granularità |
| Conteggio parole del documento CB | cb_document_word_count | numero | Il numero di parole in un documento. Il conteggio delle parole del documento è la somma di tutti i conteggi delle parole delle frasi.
|
documento e frase |
| CB Sentenza Quartile | cb_sentence_quartile | numero | La parte del verbo in cui rientra una frase. Questo attributo può avere 1 dei seguenti valori: 1, 2, 3 o 4. Ogni sezione rappresenta il 25% dell’intera lunghezza del testo. | frase |
| CB Frasi Conteggio parole | cb_sentence_word_count | numero | Il numero di parole in una frase. | frase |