-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Connettore in entrata XM DISCOVER Link
Informazioni sul connettore in entrata XM DISCO Discover Link
È possibile utilizzare XM Discover Link Inbound Connector per inviare i dati XM a XM Discover tramite un endpoint API REST, sfruttando tutte le funzionalità offerte dal framework Connectors, come la mappatura dei campi, le trasformazioni, i filtri, il job watching e così via.
Formati di dati supportati
I seguenti tipi di dati sono supportati solo in formato JSON:
Prima di impostare il connettore, creare un file campione che rappresenti i campi che si desidera importare in XM Discover. Per ulteriori informazioni sui campi obbligatori e sui formati dei file, consultare le pagine collegate sopra.
All’interno del connettore sono disponibili anche file modello da scaricare per formati di dati specifici:
- Chat
- Chat (predefinito): Utilizzare per i dati delle interazioni digitali standard.
- Amazon Connect: Da utilizzare per le interazioni digitali specifiche di Amazon Connect Chat.
- Chiamata
- Chiamata (predefinito): Utilizzare per i dati di trascrizione delle chiamate standard.
- Verint: Da utilizzare per le trascrizioni delle chiamate specifiche di Verint.
- Feedback
- Dynamics 365: Utilizzare per i dati di Microsoft Dynamics.
Creazione di un lavoro del connettore in entrata XM Discover Link
- Nella scheda Lavori, fare clic su Nuovo lavoro.
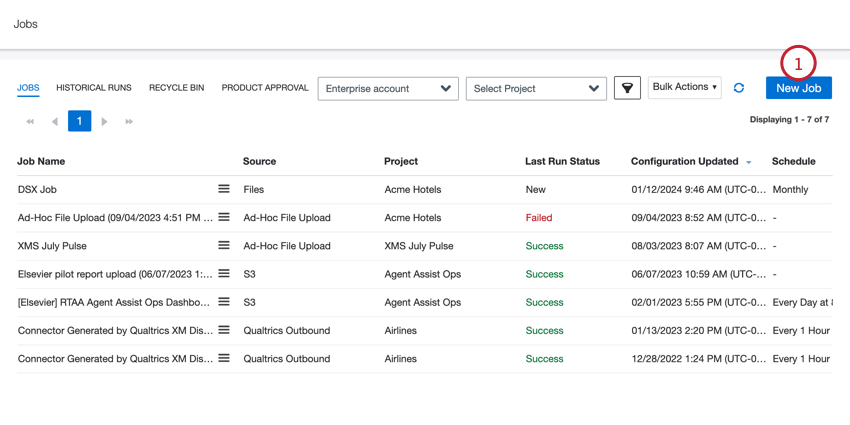
- Fare clic sul lavoro XM Discover Link.

- Date un nome al vostro lavoro per poterlo identificare.
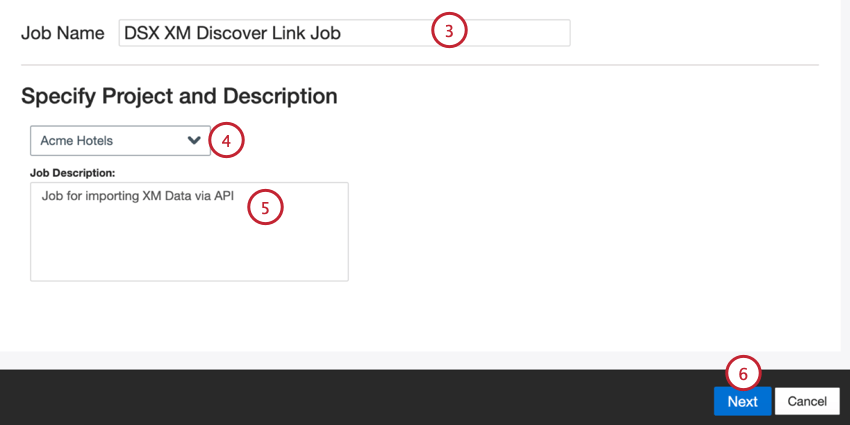
- Scegliere il progetto in cui caricare i dati.
- Date al vostro lavoro una descrizione, in modo da conoscerne lo scopo.
- Fare clic su Successivo.
- Scegliete la modalità di autorizzazione o il modo in cui vi connetterete a XM Discover:
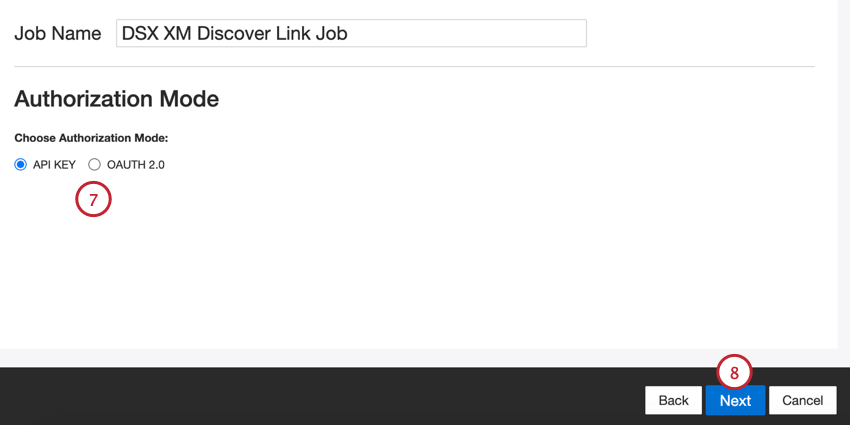
- Chiave API: Connettersi utilizzando un token API di XM Discover.
- OAuth 2.0: Connettersi utilizzando un Client ID e un Client Secret forniti dal servizio di autenticazione XM Discover. Contattate il vostro Discover Representative per richiedere questo metodo.
Consiglio Q: Potete contattare il vostro Rappresentante Discover direttamente via e-mail. Se non si dispone dei loro recapiti, è possibile contattare il team di assistenza Discover.
- Fare clic su Successivo.
- Scegliete il formato dei dati: chat (digitale), chiamata o feedback.
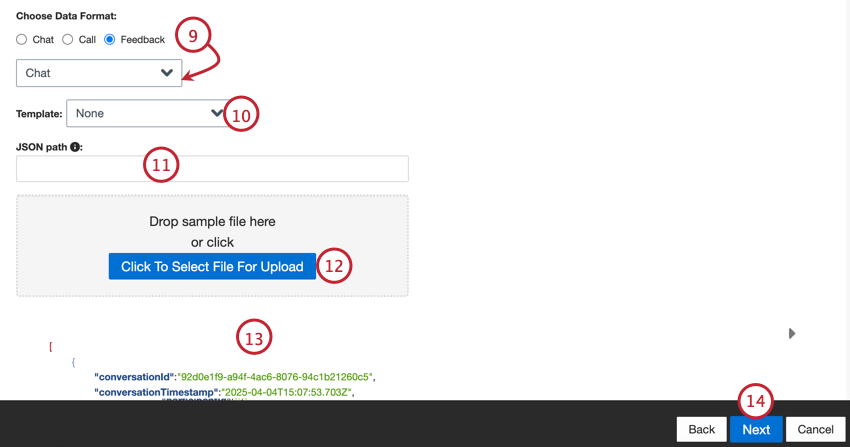 Consiglio Q: se si è selezionato “Feedback”, apparirà un secondo menu per scegliere il tipo di dati di interazione inclusi nel feedback. Le opzioni comprendono chiamata, chat, e-mail, recensione, social e sondaggio.
Consiglio Q: se si è selezionato “Feedback”, apparirà un secondo menu per scegliere il tipo di dati di interazione inclusi nel feedback. Le opzioni comprendono chiamata, chat, e-mail, recensione, social e sondaggio. - Se si desidera, scegliere un modello e fare clic sul link qui per scaricare il file del modello.
- Inserire il percorso JSON di un sottoinsieme di JSON che contiene i nodi del documento. Lasciare questo campo vuoto se i documenti si trovano a livello del nodo radice.
- Fate clic sul pulsante Seleziona file per il caricamento e scegliete il file campione sul vostro computer.
- Viene visualizzata un’anteprima del file. Se al posto dell’anteprima viene visualizzato un messaggio di errore o il contenuto del file grezzo, è possibile che ci sia un problema con le opzioni di formato dei dati selezionate. Vedere Errori del file di Campione per la risoluzione dei problemi del file.
- Fare clic su Successivo.
- Se necessario, modificare le mappature dei dati. Per informazioni dettagliate sulla mappatura dei campi in XM Discover, consultare la pagina di supporto Data Mapping. La sezione Mappatura dati predefinita contiene indicazioni specifiche per questo connettore.
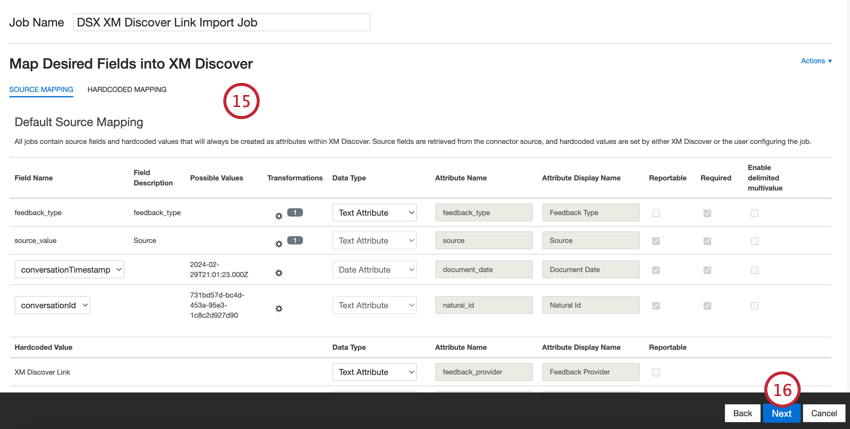
- Fare clic su Successivo.
- Se lo si desidera, è possibile aggiungere regole di sostituzione e di eliminazione dei dati per nascondere i dati sensibili o sostituire automaticamente determinate parole e frasi nei feedback e nelle interazioni dei clienti. Per ulteriori informazioni, consultare la pagina di supporto Data Substitution and Redaction.
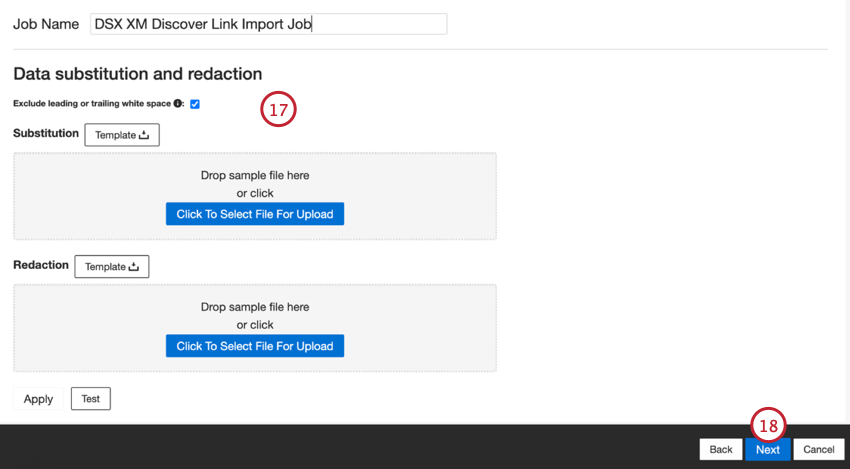
- Fare clic su Successivo.
- Se si desidera, è possibile aggiungere un filtro al connettore per filtrare i dati in entrata e limitare i dati importati.
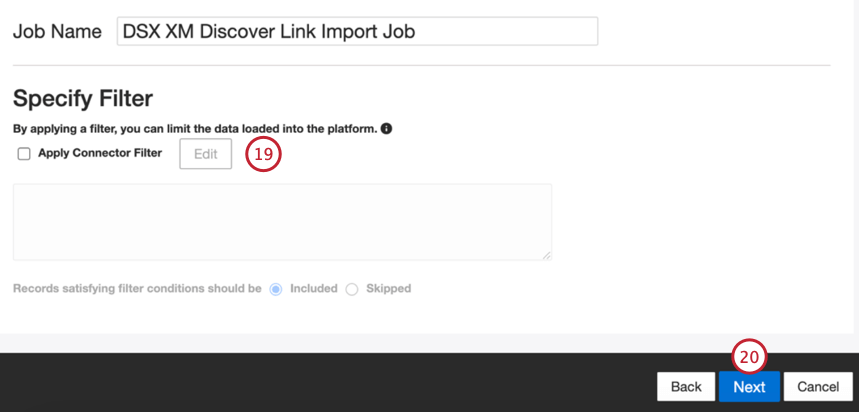
- Fare clic su Successivo.
- Scegliere come gestire i documenti duplicati. Per ulteriori informazioni, vedere Gestione dei duplicati.
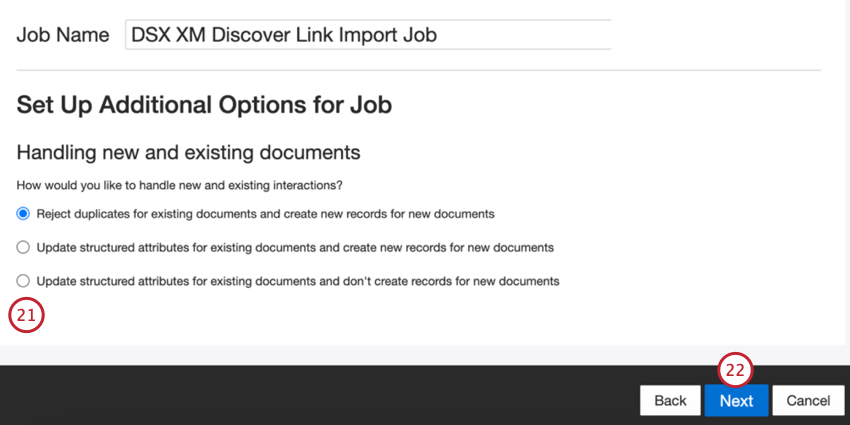
- Fare clic su Successivo.
- Valutate la vostra configurazione. Se è necessario modificare un’impostazione specifica, fare clic sul pulsante Modifica per accedere alla fase di impostazione del connettore.
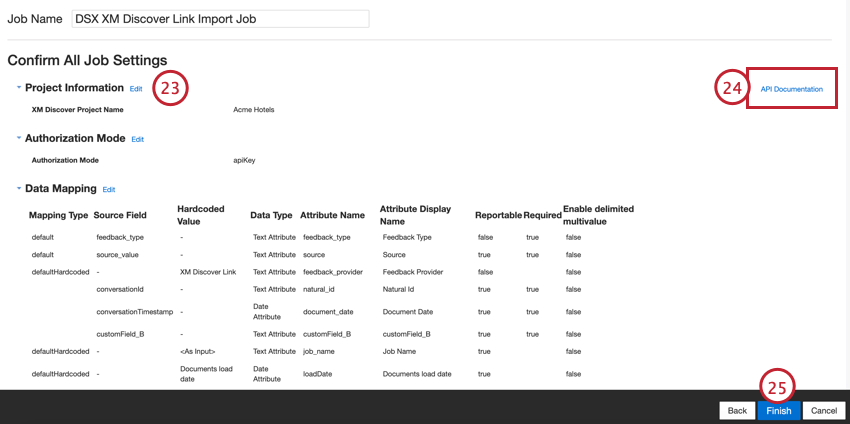
- Il link Documentazione API contiene l’endpoint API che verrà utilizzato per inviare i dati a XM Discover. Per ulteriori informazioni, vedere Accessibilità dell’endpoint API.
- Fare clic su Fine per salvare l’impostazione.
Mappatura dei dati predefinita
Questa sezione contiene informazioni sui campi predefiniti per i lavori XM Discover Inbound Link.
Quando si mappano i campi, sono disponibili i seguenti campi predefiniti:
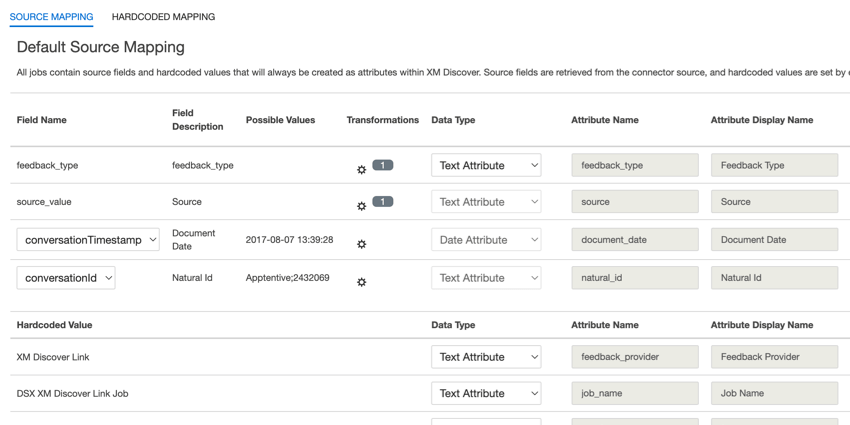
- tipo_di_feedback: Il tipo di feedback aiuta a identificare i dati in base al loro tipo. Questo è utile per i rapporti quando il progetto contiene diversi tipi di dati (ad esempio, sondaggi e feedback sui social media). Questo campo è modificabile. Per impostazione predefinita, il valore di questo attributo è impostato su:
- “call” per le trascrizioni delle chiamate
- “chat” per le interazioni digitali
- “feedback” per il feedback individuale
- È possibile utilizzare le trasformazioni personalizzate per impostare un valore personalizzato.
- fonte: Origine aiuta a identificare i dati ottenuti da un’origine specifica. Può essere qualsiasi cosa che descriva l’origine dei dati, come il nome di un sondaggio o di una campagna di marketing mobile. Questo campo è modificabile. Per impostazione predefinita, il valore di questo attributo è impostato su “XM Discover Link” È possibile utilizzare la trasformazione personalizzata per impostare un valore personalizzato.
- richVerbatim: Questo campo è utilizzato per i dati di conversazione (come le trascrizioni di chiamate e chat) e non è modificabile. XM DISCOVER utilizza un formato verbatim conversazionale per il campo richVerbatim. Questo formato supporta l’ingestione di metadati specifici del dialogo necessari per sbloccare la visualizzazione delle conversazioni (turni dei parlanti, silenzio, eventi conversazionali e così via) e gli arricchimenti (ora di inizio, durata e così via). Questo campo verbatim include campi “figli” per tracciare il lato della conversazione del cliente e del rappresentante:
- clientVerbatim tiene traccia dell’aspetto della conversazione del cliente.
- agentVerbatim tiene traccia della parte di conversazione del rappresentante (agente).
- sconosciuto traccia il lato sconosciuto della conversazione.
-
Consiglio Q: Le trasformazioni non sono supportate per i campi verbatim conversazionali. Non è possibile utilizzare lo stesso verbatim per diversi tipi di dati conversazionali. Se si desidera che il progetto ospiti diversi tipi di conversazione, utilizzare coppie di verbali di conversazione separate per ogni tipo di conversazione.
- clientVerbatim: Questo campo è utilizzato per i dati di conversazione ed è modificabile. Questo campo tiene traccia dell’aspetto della conversazione del cliente nelle interazioni di chiamata e di chat. Per impostazione predefinita, questo campo è mappato su:
- clientVerbatimChat per le interazioni digitali.
- clientVerbatimCall per le interazioni di chiamata.
- agenteVerbatim: Questo campo è utilizzato per i dati relativi alla conversazione ed è modificabile. Questo campo tiene traccia della parte di conversazione del rappresentante nelle interazioni di chiamata e di chat. Per impostazione predefinita, questo campo è mappato su:
- agenteVerbatimChat per le interazioni digitali.
- agentVerbatimCall per le interazioni di chiamata.
- sconosciuto: questo campo è utilizzato per i dati di conversazione ed è modificabile. Questo campo tiene traccia dell’aspetto sconosciuto della conversazione nelle interazioni di chiamata e chat.Per impostazione predefinita questo campo è mappato su:
- unknownVerbatimChat per le interazioni digitali.
- unknownVerbatimCall per le interazioni di chiamata.
- data_documento: la data del documento è il campo data primario associato a un documento. Questa data viene utilizzata nei rapporti di XM Discover, nelle tendenze, negli avvisi e così via. Per la data del documento, scegliere una delle seguenti opzioni:
- conversationTimestamp (per i dati di conversazione): Data e ora dell’intera conversazione.
- Se i dati di origine contengono altri campi data, è possibile impostarne uno come data del documento selezionandolo dal menu a discesa in Nome campo.
- È anche possibile impostare una data specifica aggiungendo un campo personalizzato.
- natural_id: L’ID naturale serve come identificatore unico di un documento e consente di elaborare correttamente i duplicati. Per l’ID naturale, scegliere una delle seguenti opzioni:
- conversationId (per i dati di conversazione): Un ID univoco per l’intera conversazione.
- Selezionare un campo di testo o numerico dai propri dati nel NOME CAMPO.
- Generare automaticamente gli ID aggiungendo un campo personalizzato.
- fornitore_di_feedback: Feedback provider aiuta a identificare i dati ottenuti da uno specifico provider. Per i caricamenti XM Discover Link, il valore di questo attributo è impostato su “XM Discover Link” e non può essere modificato.
- nome_lavoro: il nome del lavoro aiuta a identificare i dati in base al nome del lavoro utilizzato per caricarli. È possibile modificare il valore di questo attributo nel riquadro Nome del lavoro nella parte superiore della pagina o utilizzando il menu delle opzioni del lavoro.
- loadDate: La data di caricamento indica quando un documento è stato caricato in XM Discover. Questo campo è impostato automaticamente e non può essere modificato.
Oltre ai campi di cui sopra, è possibile mappare qualsiasi campo personalizzato che si desidera importare. Per ulteriori informazioni sui campi personalizzati, consultare la pagina di supporto Data Mapping.
Accessibilità all’endpoint dell’API
L’endpoint API viene utilizzato per caricare i dati su XM DISCOVER inviandoli tramite una richiesta API REST in formato JSON.
È possibile accedere all’endpoint dalla pagina Lavori:
- Selezionate Riepilogo nel menu delle opzioni del lavoro per il vostro lavoro.
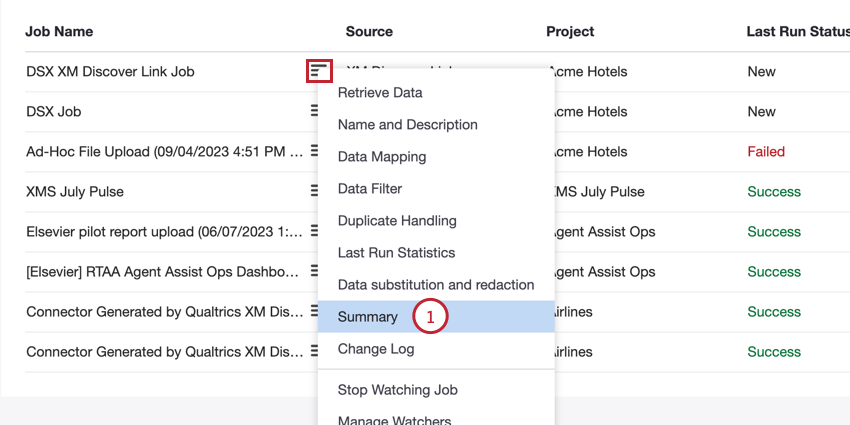
- Fare clic sul link Documentazione API.

- Fare clic sul pulsante Stampa per scaricare tutte le informazioni contenute in questa finestra come PDF stampabile.
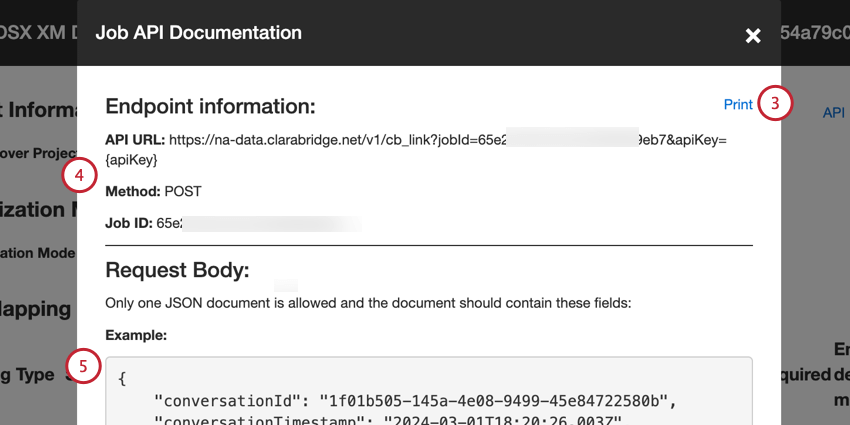
- Le informazioni sull’endpoint includono:
- URL API: L’URL utilizzato per la richiesta API.
- Metodo: Utilizzare il metodo POST per caricare i dati in XM Discover.
- ID lavoro: L’ID del lavoro attualmente selezionato.
- Un esempio di payload JSON è incluso nella sezione Corpo della richiesta. Una richiesta API deve contenere solo 1 documento e includere solo i campi del payload di esempio.
- La sezione RISPOSTE elenca le possibili risposte di successo e di errore della richiesta API.
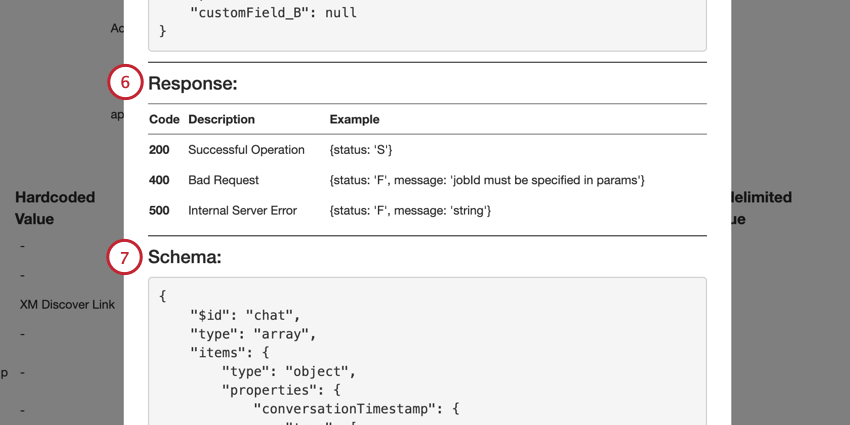
- La sezione Schema visualizza lo schema dei dati. I campi obbligatori sono nell’array obbligatorio.
Monitoraggio di un lavoro XM Discover Link tramite API
È possibile monitorare lo stato dei lavori XM Discover Link senza accedere a XM Discover chiamando l’endpoint API di stato. Consente di ottenere lo stato più recente dell’esecuzione del lavoro, le metriche per un’esecuzione specifica o le metriche accumulate per un periodo di tempo specifico.
Stato Informazioni sull’endpoint
Per chiamare l’endpoint di stato, è necessario quanto segue:
- URL API: https://na-data.clarabridge.net/v1/public/job/status/<jobID>?apiKey=<apiKey>
- <jobId> è l’ID del lavoro XM Discover Link che si desidera monitorare.
- <apiKey> è il token API.
- Tipo: Utilizzare il protocollo REST HTTP
- Metodo HTTP: Utilizzare il metodo GET per recuperare i dati.
Elementi di ingresso
I seguenti elementi di input opzionali possono essere utilizzati per recuperare ulteriori metriche sul lavoro:
- historicalRunId: L’ID della sessione di caricamento specifica. Se questo elemento viene omesso e non viene fornito alcun intervallo di date, la chiamata API restituisce l’ultimo stato di esecuzione del lavoro. Se questo elemento viene omesso e viene fornito un intervallo di date, la chiamata API restituisce le metriche accumulate per il periodo di tempo specificato.
- startDate: Definisce la data di inizio da cui restituire i dati.
- endDate: Definire la data di fine per restituire i dati in base all’ultimo caricamento. Se questo elemento viene omesso e viene fornita la data di inizio, la data di fine viene impostata automaticamente sulla data corrente.
Elementi di uscita
Se sono stati immessi gli elementi di input richiesti, verranno restituiti i seguenti elementi di output:
- stato_lavoro: Lo stato del lavoro.
- job_failure_reason: se il lavoro non è riuscito, il motivo del fallimento.
- run_metrics: Informazioni sui documenti elaborati dal lavoro. Sono incluse le seguenti metriche:
- CREATO_CON SUCCESSO: Il numero di documenti creati con successo.
- AGGIORNATO CON SUCCESSO: Il numero di documenti aggiornati con successo.
- SALTATI_COME_DUPLICATI: Il numero di documenti saltati come duplicati.
- FILTERED_OUT: Numero di documenti filtrati da un filtro specifico della fonte o da un filtro del connettore.
- BAD_RECORD: Numero di interazioni digitali inviate per l’elaborazione che non corrispondevano al formato di conversazione di Qualtrics.
- SKIPPED_NO_ACTION: il numero di documenti saltati come non duplicati.
- FAILED_TO_LOAD: Il numero di documenti che non sono stati caricati.
- TOTALE: il numero totale di documenti elaborati durante l’esecuzione di questo lavoro.
Messaggi di errore
Per la richiesta API di stato sono possibili i seguenti messaggi di errore:
- 401 Non autorizzato: Autenticità fallita. Utilizzare una chiave API diversa.
- 404 Non trovato: Un lavoro con l’ID specificato non esiste. Utilizzare un ID lavoro diverso.
Campione richiesto
Di seguito è riportato un esempio di richiesta per ottenere lo stato di un lavoro
:curl --location --request GET 'https://na-data.clarabridge.net/v1/public/job/status/62da736987c9788b830918e0?apiKey=02e7a0e26b592632dd50f623e974fff6'
Campione di risposte
Di seguito è riportato un campione di risposte a un lavoro fallito
:{
"job_status": "Failed",
"job_failure_reason": "Problema":[{"requestId": "RQ-MOB-f339aa58-71b6-4a1d-a67c-12b8d3439321", "severity": "ERROR", "description": "Il limite di lunghezza di 900 caratteri per l'attributo supportexperienceresp è stato superato, la lunghezza è 1043\"}],\"status":\"ERROR\"}",
"run_metrics": {
"successfully_created": 10,
"failed_to_load": 1,
"total": 11
}
}
Esempi di carico utile
Questa sezione contiene 1 esempio di payload JSON per ogni tipo di dati strutturati supportati (feedback, chat, chiamata).
- Fare clic qui per visualizzare l’esempio di carico di feedback.
curl --location --request POST 'https://na-data.clarabridge.net/v1/cb_link?apiKey=887fc11663c456f9f34844a8a8bdff64&jobId=5f4e583f9142ae48a1090a76' \
--header 'Content-Type: application/json' \
--data-raw '
"dataSource": "Standard JSON",
"Row_ID": "id43682",
"store_number": "226,1,1,0,0",
"address": "5916 W Loop 289 Lubbock, TX 79424",
"phone_number": "806-791-4384",
"nome_recensore": "Mariposa",
"review_rating": 2,
"Review_Date": "03.03.2019",
"Employee_Knowledge": 2,
"Price_value": 3,
"Checkout_process": 1,
"Commenti": "Una delle migliori esperienze che ho avuto da Best Buy da molto tempo a questa parte. Continuate a lavorare bene",
"LTR": 10,
"state": "TX",
"Rewards_Member": "MyBestBuy"
}'
- Fare clic qui per visualizzare il payload di esempio della chat.
curl --location --request POST 'https://na-data.clarabridge.net/v1/cb_link?apiKey=887fc11663c456f9f34844a8a8bdff64&jobId=5f4d77656afa99b0396ef959' \
--header 'Content-Type: application/json' \
--data-raw '{
"conversationId": "37854",
"conversationTimestamp": "2020-07-30T12:42:15.000Z",
"content": {
"contentType": "CHAT",
"participants": [
{
"participantId": "1",
"participantType": "AGENT",
"is_bot": true
},
{
"participantId": "2",
"participantType": "CLIENT",
"is_bot": false
}
],
"conversationContent": [
{
"participantId": "1",
"text": "Salve, come posso aiutarla?",
"timestamp": "2020-07-30T12:42:15.000Z",
"id": "3785201"
},
{
"participantId": "2",
"text": "Ciao, sei aperto oggi?",
"timestamp": "2020-07-30T12:42:15.000Z",
"id": "3785202"
},
{
"participantId": "1",
"text": "Siamo aperti dalle 17:00 alle 23:00",
"timestamp": "2020-07-30T12:42:15.000Z",
"id": "3785203"
},
{
"participantId": "2",
"text": "Vorrei effettuare una prenotazione",
"timestamp": "2020-07-30T12:42:15.000Z",
"id": "3785204"
},
{
"participantId": "1",
"text": "Assolutamente! Che nome posso usare?",
"timestamp": "2020-07-30T12:42:15.000Z",
"id": "3785205"
}
]
},
"city": "Boston",
"fonte": "Facebook"
}'
- Fare clic qui per visualizzare il payload di esempio della chiamata.
curl --location --request POST 'https://na-data.clarabridge.net/v1/cb_link?apiKey=887fc11663c456f9f34844a8a8bdff64&jobId=5f4e564d9242ae6e6308ff04' \
--header 'Content-Type: application/json' \
--data-raw '{
"conversationId": "462896",
"conversationTimestamp": "2020-07-30T10:15:45.000Z",
"content": {
"contentType": "CALL",
"partecipante": [
{
"participant_id": "1",
"type": "AGENT",
"is_ivr": false
},
{
"participant_id": "2",
"type": "CLIENT",
"is_ivr": false
}
],
"conversationContent": [
{
"participant_id": "1",
"text": "Sono Emily, come posso aiutarla?",
"start": 22000,
"end": 32000
},
{
"participant_id": "2",
"text": "Salve, ho un paio di domande",
"inizio": 32000,
"end": 42000
}
],
"contentSegmentType": "TURN"
},
"city": "Boston",
"source": "Call Center"
}'