-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Connettore in entrata Sprinklr
Informazioni sul connettore in entrata di Sprinklr
È possibile utilizzare il connettore in entrata di Sprinklr per caricare i dati dei social media da Sprinklr a XM Discover.
Impostazione di un lavoro in entrata di Sprinklr
Consiglio Q: per utilizzare questa funzione è necessaria l’autorizzazione “Manage Jobs”.
- Nella pagina Lavori, fare clic su Nuovo lavoro.
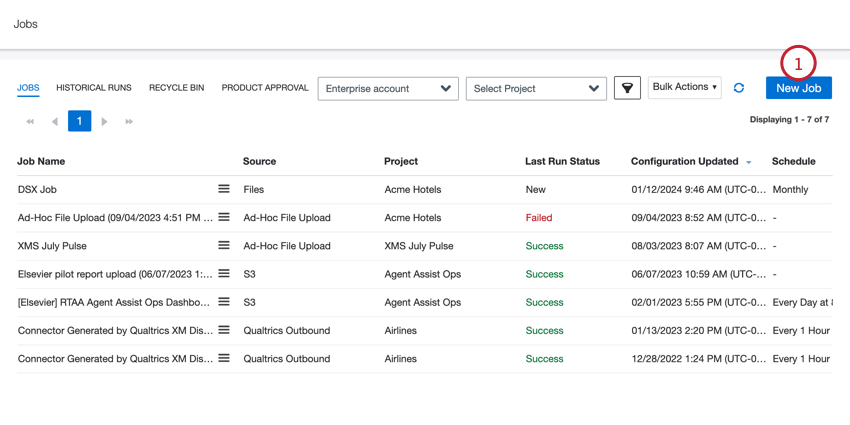
- Selezionare Sprinklr.

- Date un nome al vostro lavoro per poterlo identificare.
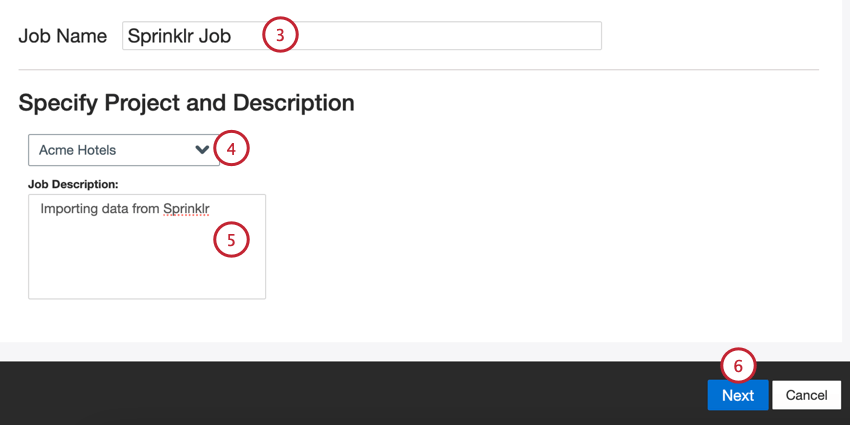
- Scegliere il progetto in cui caricare i dati.
- Date al vostro lavoro una descrizione, in modo da conoscerne lo scopo.
- Fare clic su Successivo.
- Scegliete l’account Sprinklr da utilizzare o selezionate Aggiungi nuovo per aggiungerne uno nuovo.

- Se si aggiunge un nuovo account, inserire le seguenti informazioni sull’account Sprinklr:
- Nome della connessione: Assegnare un nome alla connessione per poterla identificare.
- Chiave cliente Sprinklr: La chiave client del vostro account Sprinklr.
- Segreto del cliente Sprinklr: il segreto del cliente del vostro account Sprinklr.
- Ambiente Sprinklr: L’URL dell’ambiente Sprinklr.
- SSO: se si desidera effettuare il login tramite SSO, attivare questa casella e inserire l’URL di produzione Sprinklr dell’organizzazione nel nome di dominio Sprinklr.
Consiglio Q: Per ulteriori informazioni sull’utilizzo di SSO per Sprinklr, consultare la pagina di supporto di Sprinklr.
- Fare clic su Autorizza.
- Se si desidera che le credenziali scadano, configurare le seguenti opzioni:
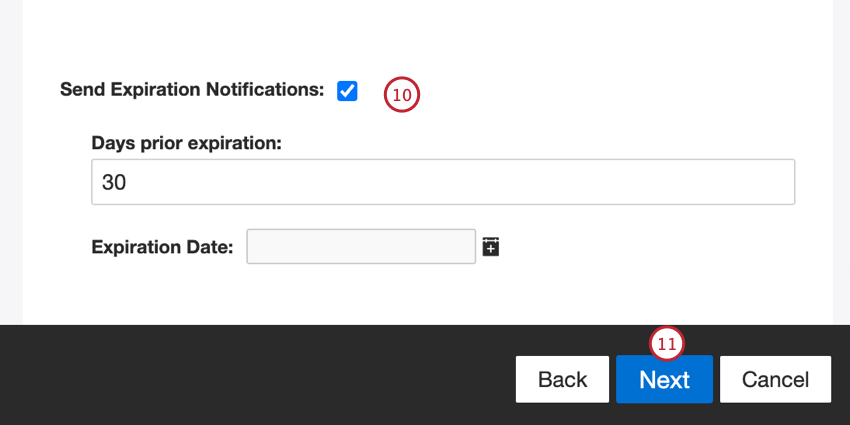
- Invia notifiche di scadenza: Selezionare questa opzione per consentire la scadenza delle credenziali.
- Giorni prima della scadenza: Se si attivano le notifiche di scadenza, inserire quanti giorni si desidera ricevere la notifica prima della scadenza. È possibile inserire un valore compreso tra 1 e 100 giorni.
- Data di scadenza: Impostare la data di scadenza delle credenziali. Fare clic sulla casella per aprire un calendario e scegliere la data.
- Fare clic su Successivo.
- Selezionare 1 o più flussi configurati dal proprio account Sprinklr. Selezionando un dashboard si selezionano tutti i flussi associati a quel dashboard.
Consiglio Q: Dopo la creazione del lavoro, è possibile modificare i flussi selezionati con il menu delle opzioni del lavoro.
- Fare clic su Successivo.
- Se necessario, modificare le mappature dei dati. Per informazioni dettagliate sulla mappatura dei campi in XM Discover, consultare la pagina di supporto Data Mapping. La sezione Mappatura dei dati predefiniti contiene informazioni sui campi specifici di questo connettore, mentre la sezione Mappatura dei campi di conversazione spiega come mappare i dati per i dati di conversazione.
- Fare clic su AVANTI.
- Se lo si desidera, è possibile aggiungere regole di sostituzione e di eliminazione dei dati per nascondere i dati sensibili o sostituire automaticamente determinate parole e frasi nei feedback e nelle interazioni dei clienti. Vedere la pagina di supporto Sostituzione e riduzione dei dati.
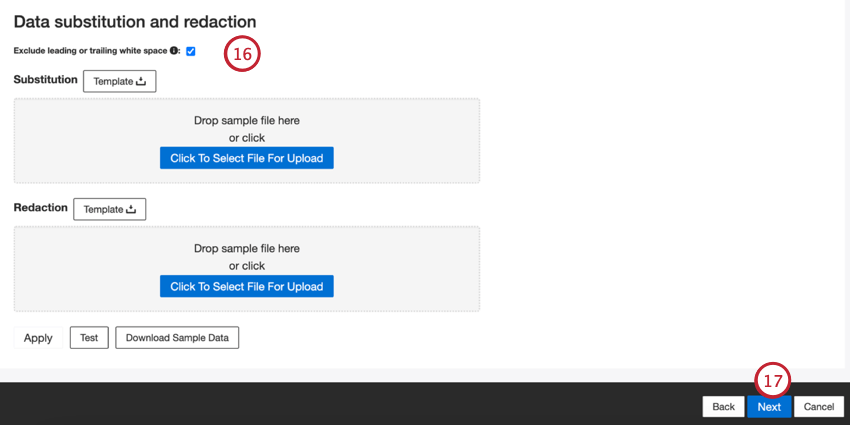 Consiglio Q: fare clic su Scarica dati di Campione per scaricare sul computer un file Excel con dati di campione.
Consiglio Q: fare clic su Scarica dati di Campione per scaricare sul computer un file Excel con dati di campione. - Fare clic su Successivo.
- Se si desidera, è possibile aggiungere un filtro al connettore per filtrare i dati in entrata e limitare i dati importati.
- È anche possibile limitare il numero di record importati in un singolo lavoro inserendo un numero nella casella Specifica limite record. Inserire “Tutti” se si desidera importare tutti i record.
Consiglio Q: Per i dati delle conversazioni, il limite si applica in base alle conversazioni anziché alle righe.
- Fare clic su Successivo.
- Scegliete quando volete essere avvisati. Per ulteriori informazioni, vedere Notifiche di lavoro.

- Fare clic su Successivo.
- Scegliere come gestire i documenti duplicati. Per ulteriori informazioni, vedere Gestione dei duplicati.
- Scegliere Pianifica esecuzioni incrementali se si desidera che il lavoro venga eseguito periodicamente in base a una pianificazione, oppure Imposta un’estrazione una tantum se si desidera che il lavoro venga eseguito una sola volta. Per ulteriori informazioni, vedere Pianificazione dei lavori.
- Fare clic su Successivo.
- Valutate la vostra configurazione. Se è necessario modificare un’impostazione specifica, fare clic sul pulsante Modifica per accedere alla fase di impostazione del connettore.
- Fare clic su Fine per salvare il lavoro.
Mappatura dei dati predefinita
Questa sezione contiene informazioni sui campi predefiniti per i lavori in entrata di Sprinklr.
- natural_id: Identificatore univoco di un documento. Si raccomanda vivamente di avere un ID unico per ogni documento per elaborare correttamente i duplicati. Per ID naturale, è possibile selezionare qualsiasi campo di testo o numerico dai dati. In alternativa, è possibile generare automaticamente gli ID aggiungendo un campo personalizzato. Per impostazione predefinita, XM Discover utilizza gli ID sorgente preceduti dal nome del connettore tramite una trasformazione personalizzata: ID naturale = Nome connettore; ID sorgente.
- data_documento: il campo data primario associato a un documento. Questa data viene utilizzata nei rapporti di XM Discover, nelle tendenze, negli avvisi e così via. Per impostazione predefinita, viene mappato al campo data selezionato dopo aver specificato la query SOQL. È possibile scegliere una delle seguenti opzioni:
- responseTime (predefinito): La data e l’ora in cui è stato inviato il feedback
- Se i dati di origine contengono altri campi data, è possibile sceglierne uno.
- È anche possibile impostare una data specifica per il documento.
- feedback_provider: Identifica i dati ottenuti da un fornitore specifico. Per i caricamenti Sprinklr, il valore di questo attributo è impostato su “Sprinklr” e non può essere modificato.
- valore_fonte: Identifica i dati ottenuti da un’origine specifica. Può essere qualsiasi cosa che descriva l’origine dei dati, come il nome di un sondaggio o di una campagna di marketing mobile. Per impostazione predefinita, il valore di questo attributo è impostato su “Sprinklr” Utilizzare le trasformazioni personalizzate per impostare un valore personalizzato, definire un’espressione o mapparlo su un altro campo.
- tipo_di_feedback: Identifica i dati in base al loro tipo. Questo è utile per i rapporti quando il progetto contiene diversi tipi di dati (ad esempio, sondaggi e feedback sui social media). Per impostazione predefinita, il valore di questo attributo è impostato su “Sondaggio”. Utilizzare le trasformazioni personalizzate per impostare un valore personalizzato, definire un’espressione o mapparlo su un altro campo.
- job_name: identifica i dati in base al nome del lavoro utilizzato per caricarli. È possibile modificare il valore di questo attributo durante l’impostazione tramite il campo NOME CAMPO, visualizzato nella parte superiore di ogni pagina durante l’impostazione.
- loadDate: indica quando un documento è stato caricato in XM Discover. Questo campo viene impostato automaticamente e non può essere modificato.
Consiglio Q: per informazioni sulla mappatura dei campi dati delle conversazioni, vedere Mappatura dei campi dati delle conversazioni.